项目概述
云岚到家项目是一个家政服务平台,提供在线下单、抢单、派单、上门服务等业务,平台包括四个端:用户端(小程序)、服务端(app)、机构端、运营端,采用前后端分离开发模式,服务端包括订单、派单、抢单、支付、优惠券、秒杀等微服务,项目使用了MySQL、Redis、MQ、ES、等中间件
https://mx67xggunk5.feishu.cn/wiki/C1B9wQ7m3ilY3AkkpdfcscAZnVc
nano ~/.zshrc
11.0.28 (arm64) "Microsoft" - "OpenJDK 11.0.28" /Users/xinduan/Library/Java/JavaVirtualMachines/ms-11.0.28/Contents/Home
source ~/.zshrc
brew services start redis
brew services start mysql
mq使用 docker
nacos:
sh startup.sh -m standalone
sh shutdown.sh
seata
export JVM_XSS=1024k
sh seata-server.sh
sh seata-stop.sh
canal:
startup.sh
stop.sh
es: 172.17.0.3:9200 http://81.70.76.245/:5601 es控制台
nvm use system使用16 版本的 node
npm run dev
xiaoyan
888itcast.CN764%..
执行docker start xxl-job-admin 启动xxl-job
访问:http://127.0.0.1:8088/xxl-job-admin/
账号和密码:admin/123456
lsof -i:端口号
kill -9 pid
使用到的技术栈
-
数据库mysql8
-
中间件
- Nacos(服务注册、配置中心)、XXL-JOB(任务调度)、RabbitMQ(消息队列)、~~Elasticsearch(全文检索)、Canal(数据同步)、Sentinel(熔断降级、限流)~~等
-
外部接口
- 微信支付,小程序认证,高德地图,阿里OSS
-
微服务
- 运营基础服务、客户管理服务、订单管理服务、
抢单服务、派单服务、支付服务,优惠券等。
- 运营基础服务、客户管理服务、订单管理服务、
-
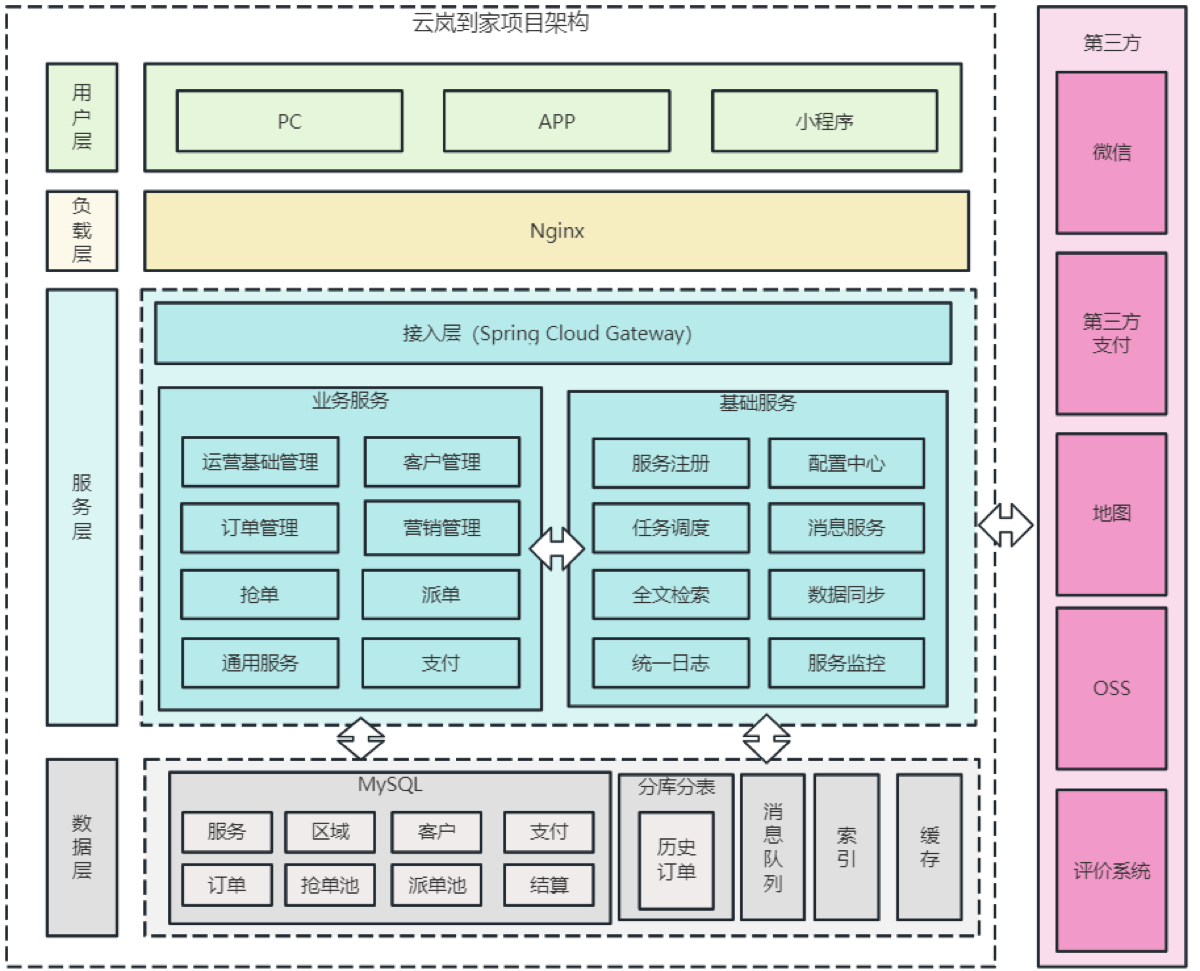
网关我们用的SpringCloudGateWay网关,最前边是Nginx进行负载均衡。
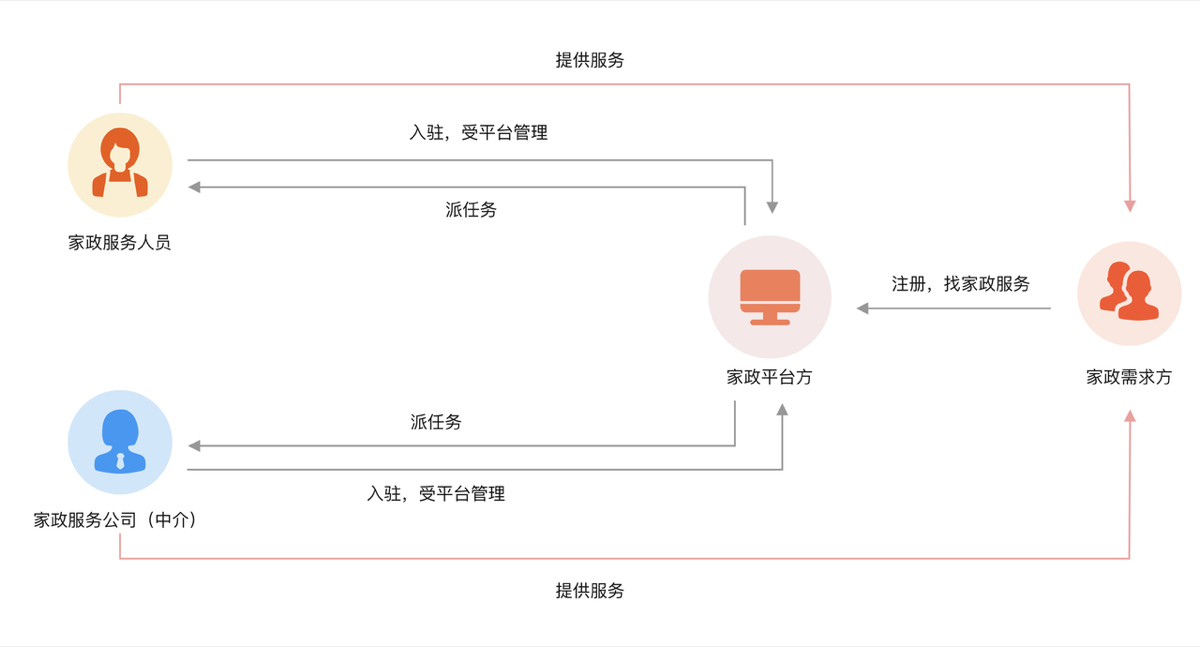
架构概览
一、整体架构概览
整个项目采用 多端分层架构(O2O模式),包含:
-
C端用户(小程序)
-
B端服务人员(APP)
-
机构端(PC)
-
平台运营管理端(PC)
-
第三方系统(提供认证、支付、地图、存储等服务)
通过线上下单、线下服务的业务闭环,构建了一个完整的家政服务O2O体系。
1️⃣ 用户端(小程序)
负责客户下单与支付,主要功能包括:
-
服务搜索与下单(城市定位、服务下单、支付)
-
优惠券领取与使用
-
订单管理(历史订单、取消、评价)
-
个人中心(基本信息、地址、评价管理)
负责用户端服务下单、支付、优惠券及订单管理模块开发,实现服务查询、在线支付与评价闭环。
2️⃣ 服务端(APP)
未做
3️⃣ 机构端(PC)
未做
4️⃣ 管理端(PC)
平台运营与数据中台:
- 服务管理(分类、项目、区域上架)
- 服务人员与机构管理(认证、信息)
-
订单管理
-
优惠券、营销活动管理
- 财务、支付、评价、地图等第三方系统对> 。
三、系统集成层(第三方系统)
-
认证系统:身份认证、验证码登录
-
支付系统:微信/支付宝支付、退款接口
-
存储服务:OSS文件上传
-
地图服务:高德定位、范围匹配 -
评价系统:评分与统计 -
财务系统:结算与抽成管理接
负责平台端运营系统开发,涵盖服务、机构、订单及营销模块;集成支付、地图、评价等第三方系统。
记忆点
O2O 是连接线上交易流程与线下服务执行的桥梁。
在“云岚到家”这种项目中,O2O能让用户获得便捷下单体验,同时帮助服务人员与机构获取订单资源。
Online to Offline(线上到线下)
项目模块
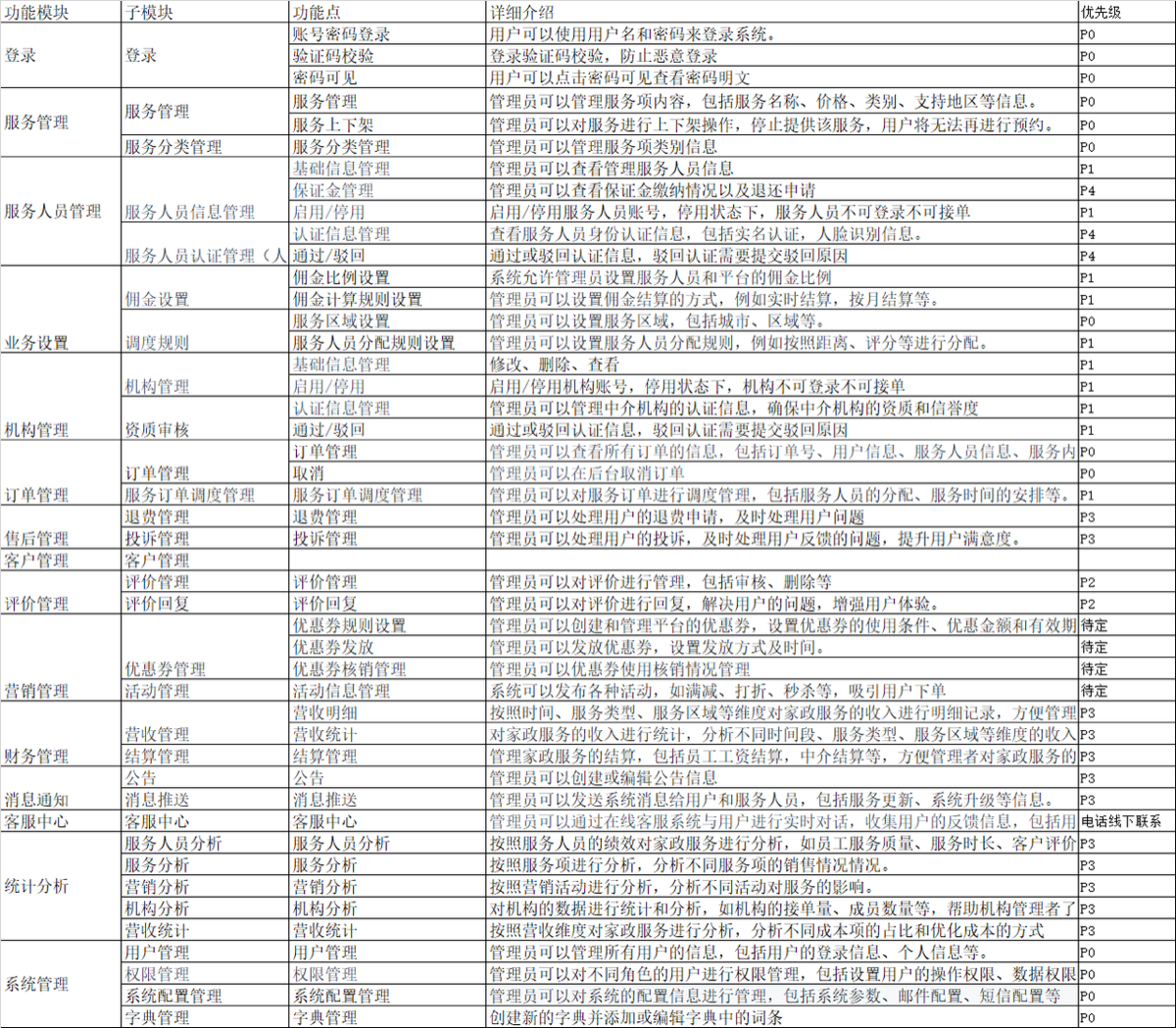
开发工具列表:
| 开发工具 | 版本号 | 安装位置 |
| IntelliJ-IDEA | 2021.x以上版本 | 个人电脑 |
| JDK | 11.x | 个人电脑 |
| Maven | 3.6.x以上版本 | 个人电脑 |
| Git | 2.37.x | 个人电脑 |
| VMware-workstation | 16.x或17.x | 个人电脑 |
| CentOS | 7.x | 虚拟机 |
| Docker | 18.09.0 | 虚拟机 |
| MySQL | 8.0.x | docker |
| Elasticsearch | 7.17.7 | docker |
| Kibana | 7.17.7 | docker |
| nacos | 2.4.0 | docker |
| rabbitmq | 3.8.26 | docker |
| redis | 6.2.7 | docker |
| xxl-job-admin | 2.3.1 | docker |
| nginx | 1.12.2 | docker |
| sentinel | 1.8.5 | docker |
| seata | 1.5.2 | docker |
| Canal | 1.15 | docker |
技术架构
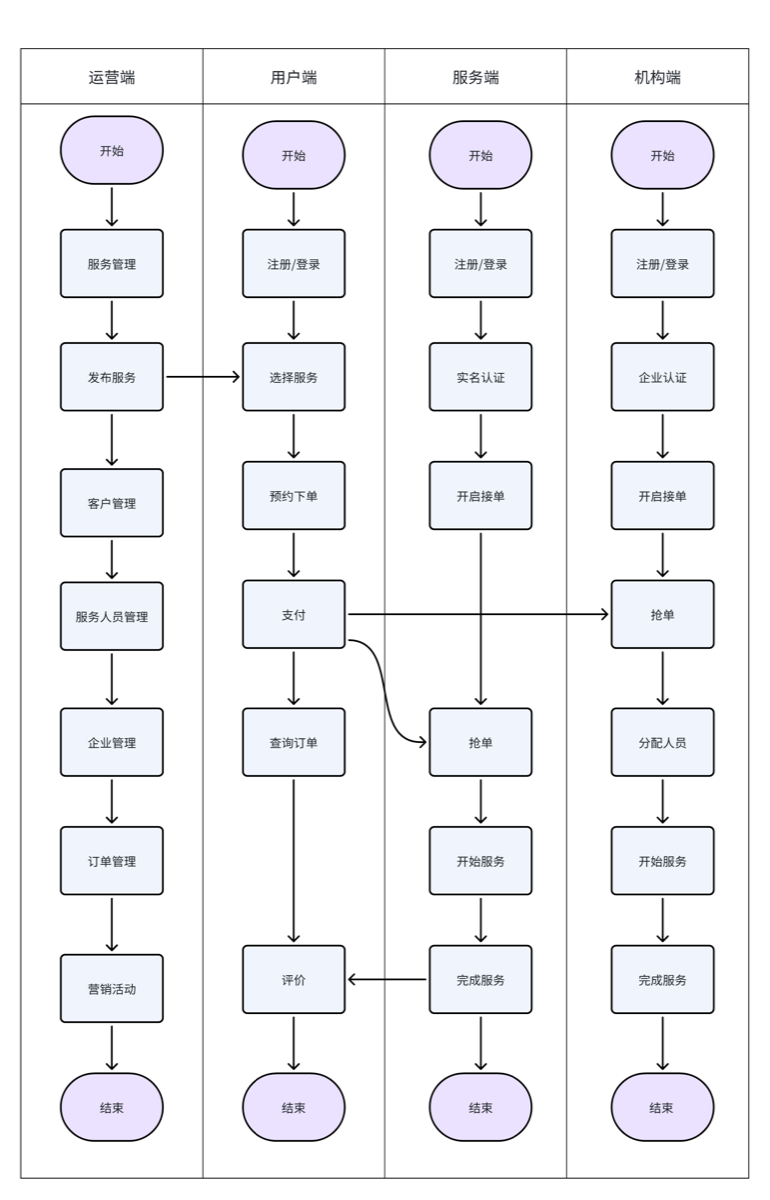
-
数据库mysql8
-
中间件
- Nacos(服务注册、配置中心)、XXL-JOB(任务调度)、RabbitMQ(消息队列)、~~Elasticsearch(全文检索)、Canal(数据同步)、Sentinel(熔断降级、限流)~~等
-
外部接口
- 微信支付,小程序认证,高德地图,阿里OSS
-
微服务
- 运营基础服务、客户管理服务、订单管理服务、
抢单服务、派单服务、支付服务,优惠券等。
- 运营基础服务、客户管理服务、订单管理服务、
-
网关我们用的SpringCloudGateWay网关,最前边是Nginx进行负载均衡。
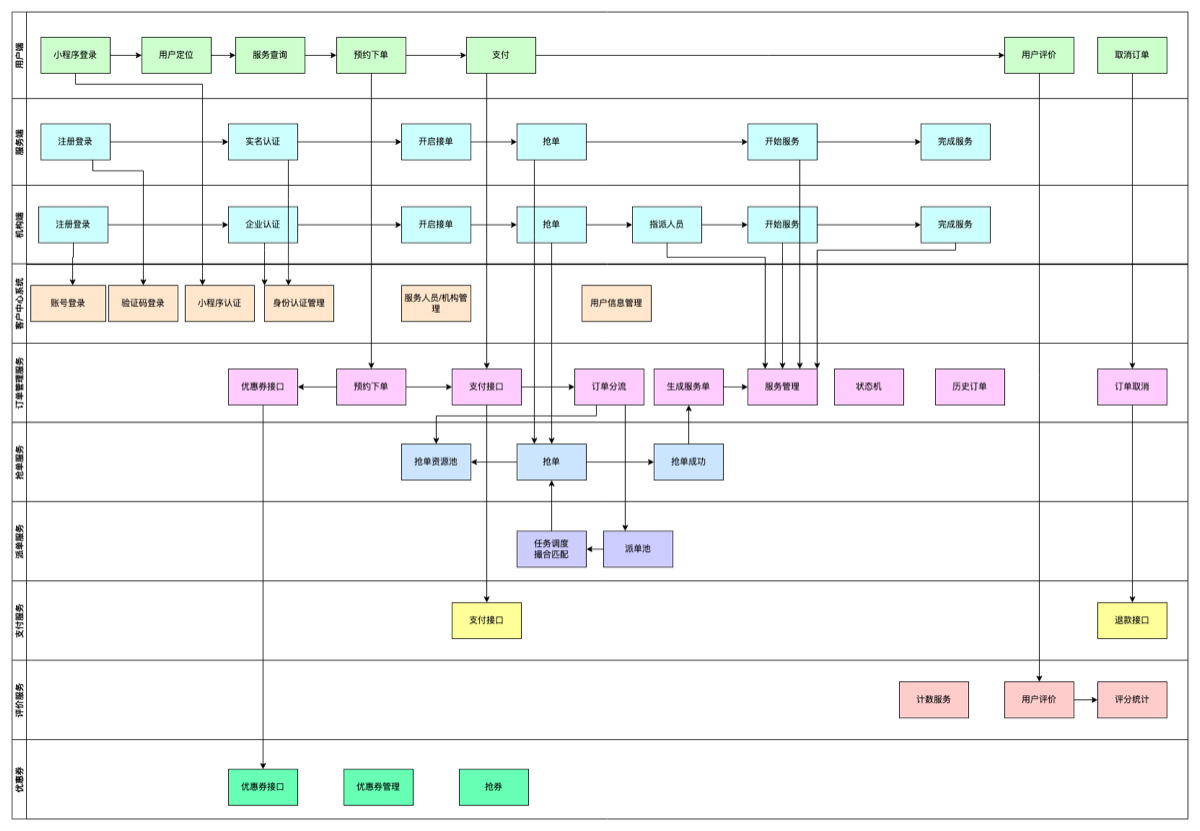
核心功能交互流程
开发模块
- 开发
- 模块定位
- 分析数据表
- 生成模型类
- 外部接口与内部接口
- 功能接口
- 如在“区域服务管理子模块中,功能列表如下
- 区域服务查询
- 添加区域服务
- 设置运营价格
- 删除区域下的服务项
- 设置热门服务
- 取消热门服务
- 上架服务
- 下架服务
mapper开发
为什么使用baseMapper
继承自ServiceImpl:
当你继承ServiceImpl<ServeMapper, Serve>时,MyBatis-Plus会自动将ServeMapper注入到父类的baseMapper字段中
baseMapper和你手动注入的serveMapper实际上指向同一个实例
代码简洁性:
使用baseMapper是MyBatis-Plus的标准做法,更加简洁
避免了额外的字段声明
一致性:
MyBatis-Plus的所有内置方法都使用baseMapper
保持代码风格一致
- 当请求参数为List对象时,for循环取出,挨个插进mapper
- 这里请求参数只有表一id和表二id,需要将表一对象插入更新,所以根据id查各自的表(mp直接查询),将表一需要的表二数据查询插入
- 更新数据库时,使用Transaction注解
- controller层下的service层可以有返回值,但调不调用看controller层自己
@Override
public void batchAdd(List<ServeUpsertReqDTO> serveUpsertReqDTOList) {
for (ServeUpsertReqDTO serveUpsertReqDTO : serveUpsertReqDTOList) {
ServeItem serveItem = serveItemMapper.selectById(serveUpsertReqDTO.getServeItemId());
if(serveItem==null || serveItem.getActiveStatus()!= FoundationStatusEnum.ENABLE.getStatus()){
throw new ForbiddenOperationException("该服务无法添加到此区域");
}
Long count = lambdaQuery()
.eq(Serve::getRegionId, serveUpsertReqDTO.getRegionId())
.eq(Serve::getServeItemId, serveUpsertReqDTO.getServeItemId())
.count();
if(count>0){
throw new ForbiddenOperationException(serveItem.getName()+"服务已存在");
}
Serve serve = BeanUtil.toBean(serveUpsertReqDTO, Serve.class);
serve.setPrice(serveItem.getReferencePrice());
Region region = regionMapper.selectById(serveUpsertReqDTO.getRegionId());
serve.setCityCode(region.getCityCode());
baseMapper.insert(serve);
}
一.运营基本管理模块
总体框架
- foundations
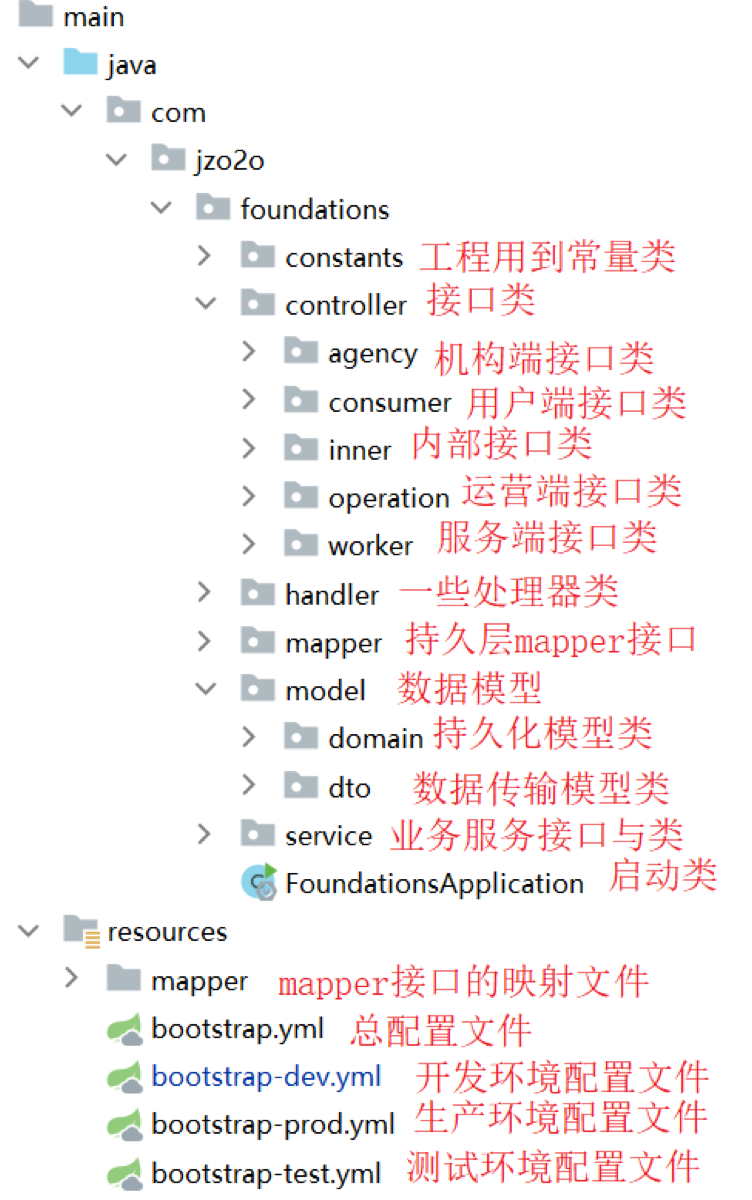
- 常量类
- 接口类(controller)
- 机构端
- 用户端
- 运营端
- 服务端
- 内部接口类
- 处理器类(handler)
- mapper层
- 数据模型类
- 持久化模型类(持久化模型类mybatis返回的数据,如serve的全部数据结构)
- 数据传输模型类
Maven依赖
持久层:MySQL数据库,mybatis-plus框架,com.github.pagehelper分页组件
中间件:Redis、Elasticsearch、xxl-job
服务层:通过Spring进行事务控制,redisson分布式锁、Spring Cache缓存框架
web层: SpringMVC框架(基于SpringBoot开发)
web容器:undertow(Undertow 是一个采用 Java 开发的灵活的高性能 Web 服务器,红帽公司的开源产品)
高并发场景下undertow的性能更好。
| 容器名称 | 特点 | 是否内嵌于 Spring Boot |
|---|---|---|
| Tomcat | 最常见、稳定、兼容性强 | ✅ 默认 |
| Jetty | 启动快、轻量、常用于微服务 | ✅ 可选 |
| Undertow | 异步 IO、高性能、低内存占用 | ✅ 可选(你的项目用的就是它) |
| 功能 | 说明 |
|---|---|
| 1️⃣ 管理 Servlet 生命周期 | 控制 Controller、Filter、Listener 等的创建与销毁 |
| 2️⃣ 请求分发 | 接收 HTTP 请求 → 匹配路径 → 调用对应接口(例如 /user/login) |
| 3️⃣ 线程池管理 | 每个请求由线程处理,容器负责调度、复用、释放线程 |
| 4️⃣ 协议支持 | 支持 HTTP/HTTPS、WebSocket 等协议通信 |
| 5️⃣ 性能优化 | 处理 IO、多线程、连接池、缓存等底层优化 |
Servlet 是底层机制
Controller 是基于 Servlet 封装的高级抽象
Servlet(Server Applet) 是一种 运行在 Web 容器(如 Tomcat、Undertow)中的 Java 程序,
它专门负责:
- 接收客户端请求(如浏览器、小程序、APP 发来的 HTTP 请求)
- 处理业务逻辑(比如查询数据库、执行业务)
- 返回响应(HTML、JSON 等)
功能开发
1.开发思路
需求分析是根据用户和产品需求,确定系统功能与设计方向的关键阶段。 主要步骤:
- 理解业务需求:与客户或产品经理沟通,明确业务流程与目标。
- 梳理功能需求:将业务需求转化为具体功能,划分核心与辅助模块。
- 整理用户操作流程:理清各端(用户端、服务端、机构端、运营端)的操作路径。
- 分析对象属性:确定涉及的业务对象及其属性。
- ~~非功能性需求:考虑性能、安全、可维护性等系统指标。~~
- 产品原型沟通:通过界面原型与客户确认需求,减少理解偏差。(比如看一个新增服务的界面来分析)
- 模块化设计:按业务逻辑划分模块与子模块,为后续开发奠定结构基础。
- 以上看页面分析
2.内外部接口
项目中,上传图片调用外部接口public服务 提供内部接口给外部,如 查询某区域下运营的服务项目 查询服务项目的详细信息等
- 如何设计一个接口?
- HTTP请求方法(post?put?)
- 接口路径
- 定义为RESTful开发规范Restful风格的路径,如:**/foundations/operation/serve/page
- @RequestMapping(“/operation/serve”) 指定本controller的根路径。
- @GetMapping(“/page”) Get请求。**
- 请求参数类型
| 类型 | Content-Type | 说明 | 典型场景 |
|---|---|---|---|
| 1️⃣ JSON格式 | application/json | 以 JSON 字符串形式传输参数;适合对象类型数据。 | 新增、修改、提交表单时(如添加服务、修改订单) |
| 2️⃣ 表单格式 | application/x-www-form-urlencoded | 以 key=value 形式拼接参数(如 ?pageNo=1&pageSize=10)。 | 查询接口、分页查询、多条件筛选 |
multipart/form-data | 支持文件上传、混合文本参数。 | 上传图片、文件、视频等 | |
| 4️⃣ 路径参数 | (在URL中) | 参数直接放在URL路径上。 | RESTful风格接口,如 /user/{id} |
| 5️⃣ 查询参数 | (URL?后拼接) | 类似表单格式,但主要用于GET请求。 | 轻量级条件查询,如 /api/list?page=1 |
4. 请求参数内容
1. 比如分页查询,定义一个通用的分页查询类,在不同业务下请求参数DTO可以继承通用的分页查询类
5. 响应结果类型
1. 本项目使用**application/json**
6. 响应结果状态码
7. 响应结果内容
1. 过滤器封装结果,见无边际
3.分页查询
第一种:mybatis-plus自带的分页方法,通过调用selectPage方法实现分页,适用于通过QueryWrapper拼装SQL。 第二种:pagehelper分页组件适用于自定义sql的分页查询。 员工分页查询同时见无边记
- 分页原理?
我们使用的是 PageHelper 分页插件,它的原理其实是基于 MyBatis 的插件机制。 当我们调用 PageHelper.startPage(pageNum, pageSize) 时,它会把分页参数存入一个 ThreadLocal。 接着,当 MyBatis 执行 Executor.query() 时,PageHelper 的拦截器会被触发: 先获取 ThreadLocal 中的分页参数; 先执行一条 count() 统计总记录数; 再在原 SQL 后拼接 limit ?, ? 实现分页查询; 最后把结果封装到 Page <T> 对象中(包含列表数据、总数、页码等信息)。 这样我们就不用手写分页 SQL 了,MyBatis 在执行时自动帮我们处理。
4.异常拦截器
它是通过 @RestControllerAdvice + @ExceptionHandler 实现的。
这两个注解属于 Spring MVC 的异常拦截机制:
@RestControllerAdvice:声明这是一个全局异常处理类;@ExceptionHandler(xxx.class):表示当程序抛出指定类型的异常时,由这个方法来处理。
记忆点 我们项目里用 @RestControllerAdvice 实现了全局异常处理。 根据异常类型(自定义异常、Feign异常、参数校验异常等)分别捕获并处理, 返回统一的响应结构,防止异常信息泄露,同时通过响应头标识是否已包装, 内部接口调用的异常也能通过 Header 传递错误信息,方便微服务链路处理。
二.用户认证模块
记忆点 认证与授权有什么区别
- 认证
- 校验用户是否合法
- 授权
- 当用操作时查看是否有权限,操作时带着token
认证流程
-
微信小程序验证:
- 前端
- 获取code返回到后端
- 携带token
- 后端
- 根据code和密钥调用官方API申请openid
- 拿到opendi取数据库查询用户表,如果查不到则写入数据库(注册)
- 根据用户信息生成token
- 返回token到前端,认证通过
- 根据code和密钥调用官方API申请openid
- 前端
-
手机号验证
- 输入手机号,发送验证码
- 系统验证验证码正确
- 判断用户是否被冻结
-
密码认证
实现要点
记忆点 token的生成,解析token,存入用户信息进http头(如何在各微服务和框架中周转) 项目整体结构,见无边记
小程序端
- customer服务调用public服务中的wechatAPIcontroller
- 获取到openid后返回customer服务,实现认证流程,返回微信小程序需要的token
APP端
- 根据手机号用户类型拼接一个key(由customer服务中的的loginController层调用public服务中的sendCodeControllerAPI)
- 生成验证码存入redis和key
- 校验时,从redis取出比较
- 密码登陆时,加密使用BCrypt方式,BCrypt是一种密码哈希函数,通常用于存储用户密码的安全性。它是基于 Blowfish 密码算法的一种单向哈希函数,输入密码成hash到数据库,校验时校验数据库hash值
用户定位
- 前端拿到经纬度坐标
- 目标:根据坐标拿对应的区域id
- 根据经纬度坐标请求高德地图的地理位置查询接口拿到citycode(这里和数据库里是一样的)
- 数据库里已有对应的关照表
- 根据citycode查询区域表,拿到系统的区域
- 见无边记
三.小程序
- 使用门户技术
- 静态资源(CDN)如ngnix
- 动态资源(通过接口访问服务器)如redis
- 对所有请求进行负载均衡
页面首页信息
- 见无边记
缓存页面实现要点
使用RedisTemplate与SpringCache
RedisTemplate 进行 Redis 操作时,实际上是通过 Lettuce 客户端与 Redis 服务器进行通信。
Spring Cache最终也是通过Lettuce 去访问redis 。
#记忆点
Jedis 是老牌同步客户端,每个线程都要单独建连接;
Lettuce 是新一代基于 Netty 的异步客户端(自动依赖),支持多线程共享连接。
Netty 是一个基于 NIO(非阻塞 I/O)的高性能网络通信框架。
它让你可以用极少的代码,快速开发出高并发的网络程序(而不用编写使用底层socket)
1.SpringCache具体用法
- SpringCache
- 提供里很多注解可以直接在方法上实现
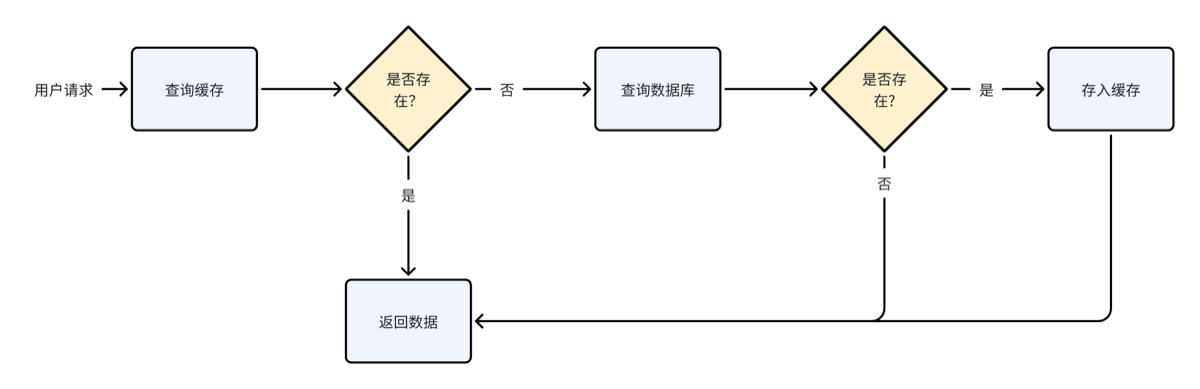
- Spring提供的,基于AOP原理(原理同一般的方式:查redis没查到→访问数据库→返回并插入缓存)
- 面向切面编程:它就是一种“拦截 + 增强”的机制。
- 1.SpringAOP的原理了解吗
- SpringCache使用方法
- 在启动类开启注解@EnableCaching
- 在接口实现类开启cache各种注解
@Override
@Cacheable(value = RedisConstants.CacheName.SERVE, key = "#id") //redis key:JZ_CACHE:SERVE_RECORD::id值
public Serve queryServeByIdCache(Long id) {
return baseMapper.selectById(id);
}- 如何自定义SpringCache注解的过期时间
- 在Cache注解加入cacheManager
- 自定义一个cacheManager方法(在framework里的reidsConfig中实现)
@Cacheable(value = RedisConstants.CacheName.SERVE, key = "#id",cacheManager = RedisConstants.CacheManager30Minnutes)
//随机数的加入防止 “缓存雪崩”:
> 如果所有缓存都在 30分钟 同时过期,
> 会导致大量请求瞬间打到数据库
> 其实就是拦截自定义RedisCacheManager,加一个配置在返回
@Bean
public RedisCacheManager cacheManager30Minutes(RedisConnectionFactory connectionFactory) {
int randomNum = new Random().nextInt(100);
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofSeconds(30 * 60L + randomNum))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(JACKSON_SERIALIZER));
//
return RedisCacheManager.builder(connectionFactory)
.cacheDefaults(config)
.transactionAware()//兼容事务在事务提交成功后进行缓存
.build();
}记忆点 下边在首页服务列表查询方法上添加Spring Cache注解实现查询缓存。 根据需求,我们需要根据方法的返回值去判断,如果结果集的长度大于0说明服务列表不空,此时缓存时间为永久缓存,否则缓存时间为30分钟。
- 首页的缓存方案
- 数据结构
- 首页大部分是String类型
- 缓存时间
- 首页头图为永久,但会由定时任务每天凌晨更新缓存使用xxl-job(framework下的工程)实现
- 缓存一致性方案
- [[黑马点评#三种经典问题|三种经典问题]]
- 为了避免缓存穿透,如果服务列表为空则向redis缓存空值,缓存时间为30分钟;不为空则进行永久缓存。
- 缓存雪崩,上面代码说了
- 缓存不一致:先更新数据库,在删除缓存
- 数据结构
2.定时任务
使用方法:在需要使用定时任务的微服务下引入xxl-job依赖→配置nacos配置文件
- 这里未完成,缺少文件,补一下定时任务Spring Task(订单状态定时处理)
- @XxlJob(value = “activeRegionCacheSync”)使用注解使用xxl-job(名字要与执行器相同)
3.高并发项目缓存常见问题
1)缓存穿透问题
什么是缓存穿透?如何解决缓存穿透? 什么是布隆过滤器?如何使用布隆过滤器? 本项目使用缓存空值或特殊值的方法去解决缓存穿透。
2)缓存击穿问题
什么是缓存击穿?如何解决缓存击穿? 本项目对热点数据定时预热,使用定时任务刷新缓存保证缓存永不过期,解决缓存穿透问题。
3) 缓存雪崩问题
什么是缓存雪崩?如何解决缓存雪崩? 本项目对key设置不同的过期时间解决缓存雪崩问题。
4)缓存不一致问题
如何保证缓存一致性?
3.查询首页信息流程
- 根据regionId入手,返回两个一级服务和下面的四个服务项
4.一对多sql语句
难点 #优化点
- 数据查询问题
- 避免n+1次查询
- 一次性将想要的数据查询出来,在内存封装
- 另一个技术点:取出列表里的前两个数据使用subList(0,2),前面的判断用三目符判断
| 环境 | 优化前 | 优化后 | 性能提升 |
|---|---|---|---|
| 单用户测试 | ~400ms | ~80ms | ⬆️ 提升约 5倍 |
| 并发 100 用户 | 查询超时频繁 | 平稳运行 | ⬆️ 吞吐量提升 3~6倍 |
| 数据库 CPU | 飙升 80%+ | 稳定 30% 以下 | ✅ 明显降低负载 |
@Caching(
cacheable = {
//result为null时,属于缓存穿透情况,缓存时间30分钟
@Cacheable(value = RedisConstants.CacheName.SERVE_ICON, key = "#regionId", unless = "#result.size() != 0", cacheManager = RedisConstants.CacheManager.THIRTY_MINUTES),
//result不为null时,永久缓存
@Cacheable(value = RedisConstants.CacheName.SERVE_ICON, key = "#regionId", unless = "#result.size() == 0", cacheManager = RedisConstants.CacheManager.FOREVER)
}
@Cacheable(value = RedisConstants.CacheName.SERVE_ICON, key = "#regionId", cacheManager = RedisConstants.CacheManager.FOREVER)
public List<ServeCategoryResDTO> queryServeIconCategoryByRegionIdCache(Long regionId) {
List<ServeCategoryResDTO> serveIconCategoryByRegionId = serveMapper.findServeIconCategoryByRegionId(regionId);
//取出前两条
List<ServeCategoryResDTO> serveCategoryResDTOS = new ArrayList<>(serveIconCategoryByRegionId.size()>=2?serveIconCategoryByRegionId.subList(0, 2):serveIconCategoryByRegionId);
//遍历列表,每个元素中的服务项目列表只取出前四个
serveCategoryResDTOS.forEach(serveCategoryResDTO -> {
List<ServeSimpleResDTO> serveResDTOList = serveCategoryResDTO.getServeResDTOList();
if(serveResDTOList.size()>=4){
serveResDTOList = new ArrayList<>(serveResDTOList.subList(0, 4));
}
serveCategoryResDTO.setServeResDTOList(serveResDTOList);
});
return serveCategoryResDTOS;<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.jzo2o.foundations.mapper.ServeMapper">
<select id="queryServeListByRegionId" resultType="com.jzo2o.foundations.model.dto.response.ServeResDTO">
SELECT
serve.id,
serve.sale_status,
serve.serve_item_id,
item.name AS serve_item_name,
item.serve_type_id,
serve.region_id,
item.reference_price,
serve.price,
serve.is_hot,
serve.create_time,
serve.update_time,
type.name AS serve_type_name
FROM
serve
inner JOIN serve_item AS item ON serve.serve_item_id = item.id
inner JOIN serve_type AS type ON item.serve_type_id = type.id
WHERE
serve.region_id = #{regionId}
</select>
<!--查询首页服务列表-->
<select id="findServeIconCategoryByRegionId" resultMap="ServeCategoryMap">
SELECT serve.id,
serve.sale_status,
serve.serve_item_id,
item.name AS serve_item_name,
item.img as serve_item_icon,
item.sort_num as serve_item_sort_num,
item.serve_type_id,
type.name AS serve_type_name,
type.img serve_type_icon,
type.sort_num as serve_type_sort_num,
serve.city_code
FROM serve
inner JOIN serve_item AS item ON serve.serve_item_id = item.id
inner JOIN serve_type AS type ON item.serve_type_id = type.id
WHERE serve.region_id = #{regionId}
and serve.sale_status = 2
order by type.sort_num, item.sort_num
</select>
<resultMap id="ServeCategoryMap" type="com.jzo2o.foundations.model.dto.response.ServeCategoryResDTO">
<id column="serve_type_id" property="serveTypeId"/>
<result column="serve_type_name" property="serveTypeName"/>
<result column="serve_type_icon" property="serveTypeIcon"/>
<result column="city_code" property="cityCode"/>
<result column="serve_type_sort_num" property="serveTypeSortNum"/>
<!--一对多映射-->
<collection property="serveResDTOList" ofType="com.jzo2o.foundations.model.dto.response.ServeSimpleResDTO">
<id column="id" property="id"/>
<result column="serve_item_id" property="serveItemId"/>
<result column="serve_item_name" property="serveItemName"/>
<result column="serve_item_icon" property="serveItemIcon"/>
<result column="serve_item_sort_num" property="serveItemSortNum"/>
</collection>
</resultMap>
</mapper>
三.优惠券系统
设计原型及流程见 无边记
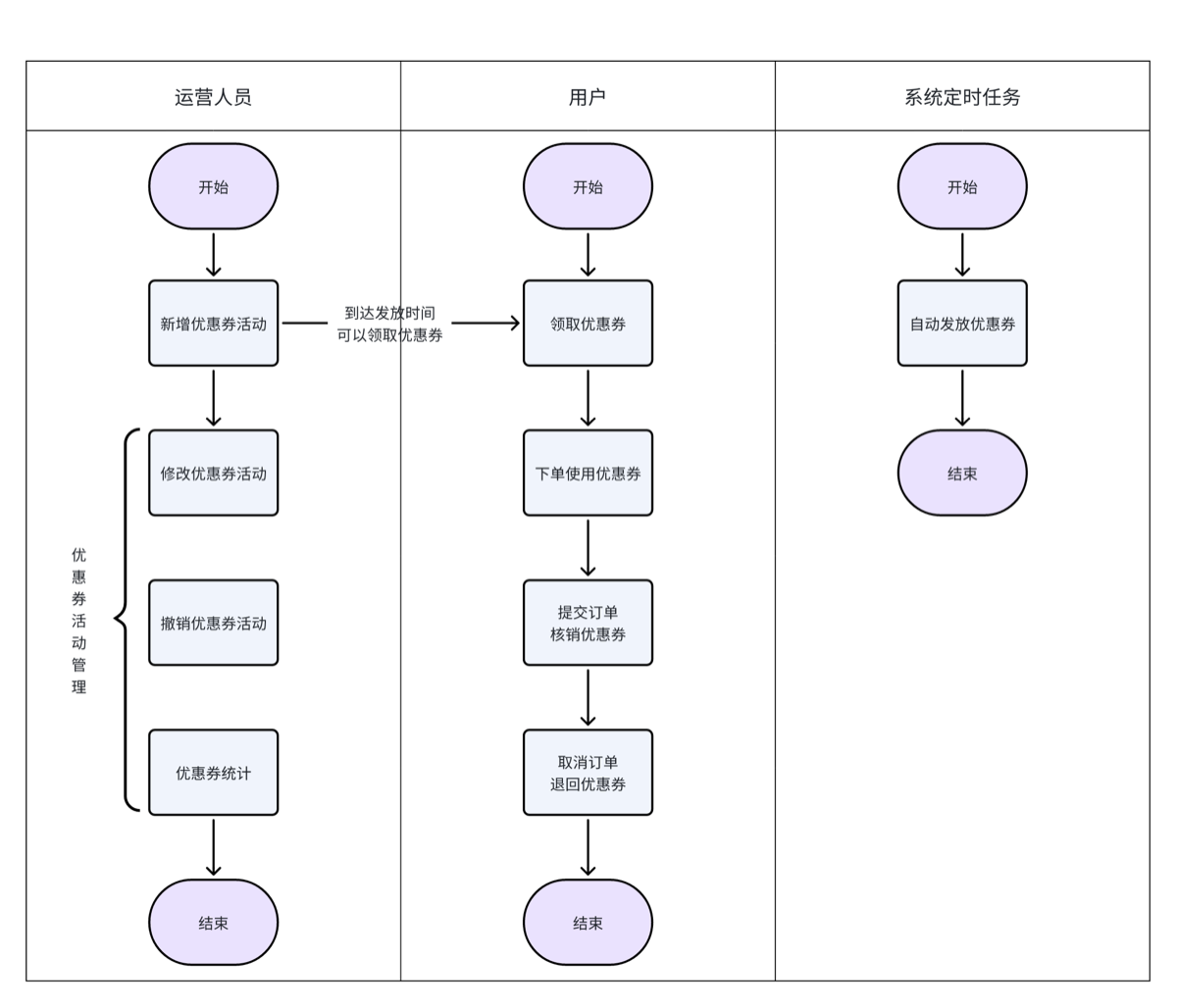
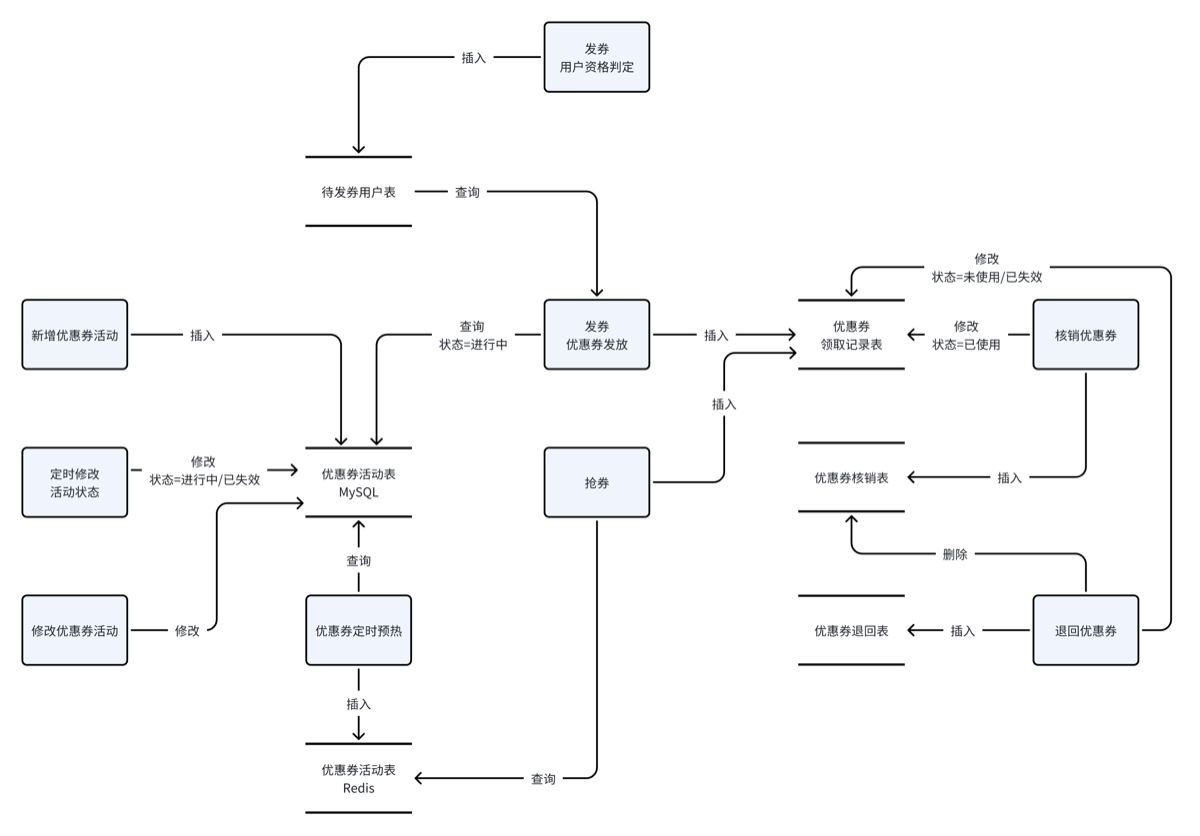
1.数据表建立
- 优惠券活动表
- 活动id、活动名称、优惠券类型、折扣、发放时间等
- 优惠券库存表
- 用户id、活动id、折扣、优惠券类型、有效期等
- 创建’用户查询我的优惠券快捷索引’
- 核销表
- 用户id、优惠券id、订单id,核销时间
- 退回表
- 如果用户取消订单,则会退回优惠券,具体操作是向优惠券退回表添加一条记录(记录用户退回优惠券的信息),并向优惠券核销表删除一条对应的记录,表示取消优惠券的核销。
- 领取记录表(就是优惠券库存表)
-
数据表中的冗余子段,例如在优惠券库存系统中,不关联查询优惠券活动表查询使用类型是满减还是折扣.因为活动会变.这时使用冗余子段“保存快照”
-
在分析创建数据库表时,根据需求分析,不必在意一对多或者多对多关系
-
体检项目实战建表
2.新增活动券
展示活动表page
- 数据的校验,如时间是否正确,由前端完成,后端指根据DTO返回VO
- 注意:与查询优惠券使用同一个/page接口
- 参数可以存在也可以不存在(无条件查询)使用动态sql或LambdaQueryWrapper查询
- 分页查询也分两种方式
- 一种为原始的返回为原始的查询出List或Page类型.return new PageResult
- 一种为使用mybatisPlus中的selectPage查询出Page类型,retrun…
保存活动表save
- 在保存优惠券信息时使用
- 与更新优惠券同用一个/save接口,先select在save
查询活动表{id}
同 下面的查询活动表{id}
说出满减与折扣及核销金额的细节
想着 pdd 优惠券就行
3.查询领取记录
- 分两部分:上半部分活动详情,,下半部分领取详情(coupon表page)
查询活动表{id}
- 这里使用/{id}传入参数,而不是像上面的活动表使用DTO(与新增更新活动表统一接口)
- 返回为活动详情信息,比如发放数量,核销数量,领取数量以展示活动信息(使用率等(由前端实现))
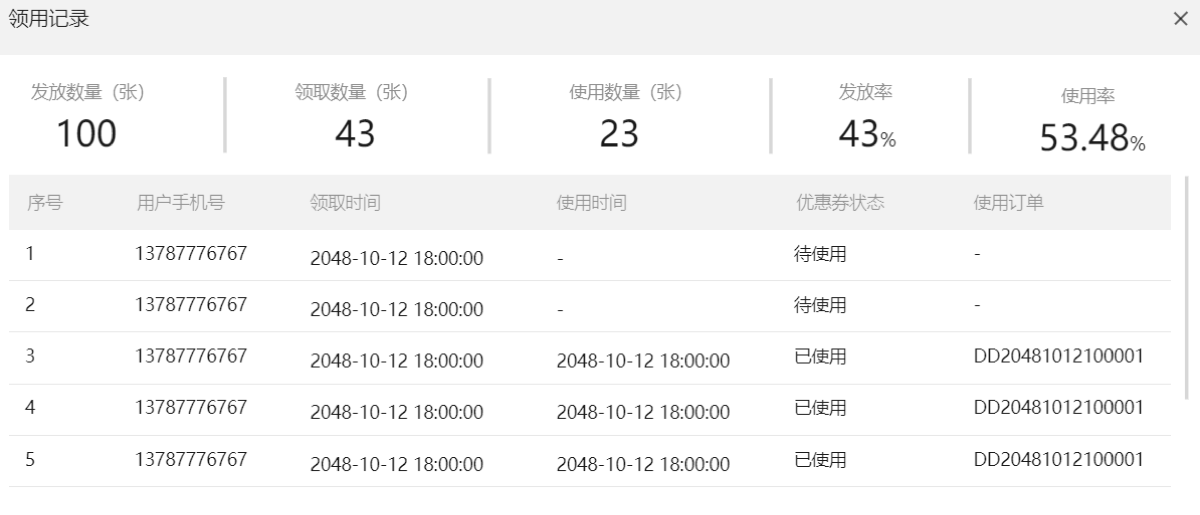
展示优惠券表page
- 同展示活动表page
- 代码中只使用DTO中的id查询,因为不需要条件查询优惠券表
4.撤销活动与定时任务
- 撤销活动仅需查询活动表将状态更改status,再将优惠券设置为作废(修改status)
- 需要校验是否为开启和待生效状态
@Transactional(rollbackFor = Exception.class)
public void revoke(Long id) {
// 1.活动作废
boolean update = lambdaUpdate()
.set(Activity::getStatus, ActivityStatusEnum.VOIDED.getStatus())
.eq(Activity::getId, id)
.in(Activity::getStatus, Arrays.asList(NO_DISTRIBUTE.getStatus(), DISTRIBUTING.getStatus()))
.update();
if(!update) {
return;
}
// 2.未使用优惠券作废
couponService.revoke(id);
}
- 定时任务每分钟使用xxjob执行更新函数如下
- 用于自动发放符合标准的用户于优惠券
- 用于自动作废优惠券
public void updateStatus() {
LocalDateTime now = DateUtils.now();
// 1.更新已经进行中的状态
lambdaUpdate()
.set(Activity::getStatus, ActivityStatusEnum.DISTRIBUTING.getStatus())//更新活动状态为进行中
.eq(Activity::getStatus, NO_DISTRIBUTE)//检索待生效的活动
.le(Activity::getDistributeStartTime, now)//活动开始时间小于等于当前时间
.gt(Activity::getDistributeEndTime,now)//活动结束时间大于当前时间
.update();
// 2.更新已经结束的
lambdaUpdate()
.set(Activity::getStatus, LOSE_EFFICACY.getStatus())//更新活动状态为已失效
.in(Activity::getStatus, Arrays.asList(DISTRIBUTING.getStatus(), NO_DISTRIBUTE.getStatus()))//检索待生效及进行中的活动
.lt(Activity::getDistributeEndTime, now)//活动结束时间小于当前时间
.update();
}
5.我的优惠券(用户端)(复杂)
在用户端
-
按领取时间降序排列
-
分三个子模块:待使用(默认显示),已使用,已过期
-
类似于page但不是page,传入参数(status,lastId)用户Id为线程中取出
-
返回为List表而不是Page表? 好像是保持性能(用户端数据量大)
-
有点复杂
public List<CouponInfoResDTO> queryForList(Long lastId, Long userId, Integer status) {
// 1.校验
if (status > 3 || status < 1) {
throw new BadRequestException("请求状态不存在");
}
// 2.查询准备
LambdaQueryWrapper<Coupon> lambdaQueryWrapper = new LambdaQueryWrapper<>();
// 查询条件
lambdaQueryWrapper.eq(Coupon::getStatus, status)
.eq(Coupon::getUserId, userId)
.lt(ObjectUtils.isNotNull(lastId), Coupon::getId, lastId);
// 查询字段
lambdaQueryWrapper.select(Coupon::getId);
// 排序
lambdaQueryWrapper.orderByDesc(Coupon::getId);
// 查询条数限制
lambdaQueryWrapper.last(" limit 10 ");
// 3.查询数据(数据中只含id)
List<Coupon> couponsOnlyId = baseMapper.selectList(lambdaQueryWrapper);
//判空
if (CollUtils.isEmpty(couponsOnlyId)) {
return new ArrayList<>();
}
// 4.获取数据且数据转换
// 优惠id列表
List<Long> ids = couponsOnlyId.stream()
.map(Coupon::getId)
.collect(Collectors.toList());
// 获取优惠券数据
List<Coupon> coupons = baseMapper.selectBatchIds(ids);
// 数据转换
return BeanUtils.copyToList(coupons, CouponInfoResDTO.class);
}
本功能是c端用户查询自己领取的优惠券,由于c端用户量大所以要保证此查询接口的性能。 实现思路类似Elasticsearch的深度分页思路(search_after)。 需要在表中找一个唯一的且有序的键作为排序字段,接口传入lastId,用排序字段和lastId比较,类似下边的SQL:
降序:Select * from 表名 where 排序字段<lastId limit 10
- 使用 (create_time, id) 组成的复合索引。如果
create_time重复,用id来打破平局(Tie-breaker)。 -
- 这种方式只适用于**“瀑布流”或“加载更多”**(点击“下一页”)的场景。无法直接跳转第 20 页
传统分页(Offset 分页)的痛点
通常我们分页会用 LIMIT offset, size,例如 LIMIT 10000, 10。
- 逻辑: 数据库必须先扫描出前 10,010 条数据,然后丢弃前 10,000 条,只保留最后 10 条。
- 性能: 随着页码越往后(深度分页),扫描的数据量越大,性能呈指数级下降。对于 C 端高并发接口,这会导致数据库慢查询,甚至拖垮服务。
6.获取可用优惠券
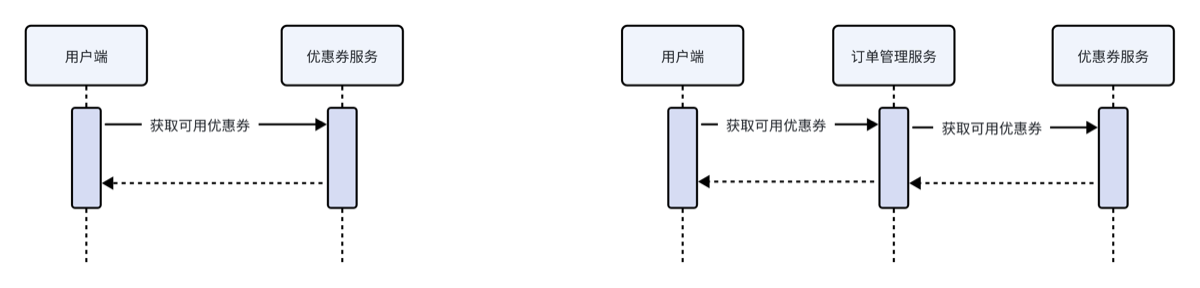
记忆点 使用右方的方案
- 用户端与优惠券端之间由订单管理系统负责交互
- 就比如用户购买vip会员时,在使用优惠券时,由会员系统负责决定去优惠券系统取优惠券
- 代码中把获取优惠券的服务定义为API接口(Interface) 用于微服务之间的调用,
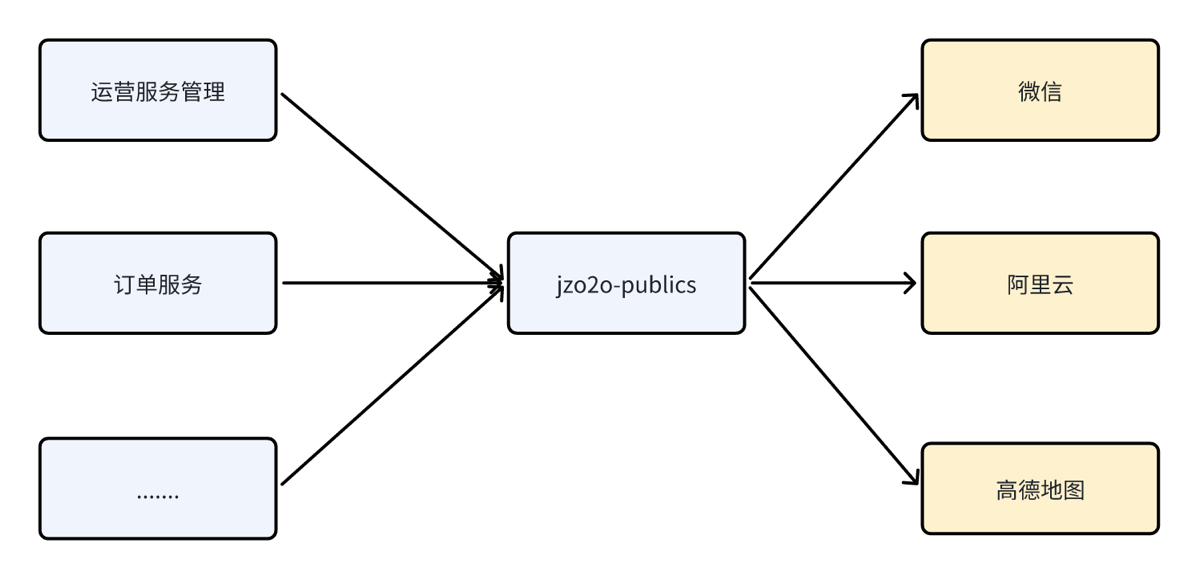
- 其他服务可以通过Feign调用这些接口(使用Resoce注解注入API)(好像是上传到maven仓库中使用)来使用优惠券功能Feign
这段代码通常放在一个公共的 jar 包里(比如 jzo2o-api),所有的微服务都能看到它。
“install” 的作用: 它执行了 编译 class → 打包 jar → 放入 .m2 本地仓库 这一整套流程。
假设有一个 “订单服务” 想要查询优惠券:
-
订单服务(调用方): 引入
CouponApi,直接调用:couponApi.getAvailable(1001L, new BigDecimal("100.00")); -
Feign(中间人): 拦截这个调用,自动组装 HTTP 请求:
- 方法:
GET - URL:
http://jzo2o-market/market/inner/coupon/getAvailable?userId=1001&totalAmount=100
- 方法:
-
网络传输: 请求发送到 Nacos/Eureka 注册中心找到的
jzo2o-market服务实例。 -
优惠券服务(接收方): Spring MVC 接收到请求,路由到
CouponController的getAvailable方法。 -
执行逻辑: 运行你即将编写的业务代码,返回
List。 -
Feign(中间人): 收到 JSON 响应,自动转换回
List<AvailableCouponsResDTO>对象给订单服务。
获取过滤可用的优惠券
@Override
public List<AvailableCouponsResDTO> getAvailable(Long userId,BigDecimal totalAmount) {
// 1.查询优惠券
List<Coupon> coupons = lambdaQuery()
.eq(Coupon::getStatus, CouponStatusEnum.NO_USE.getStatus())
.gt(Coupon::getValidityTime, DateUtils.now())
.le(Coupon::getAmountCondition, totalAmount)
.eq(Coupon::getUserId, userId)
.list();
// 判空
if (CollUtils.isEmpty(coupons)) {
return new ArrayList<>();
}
// 2.组装数据计数优惠金额
return coupons.stream()
//先计算优惠金额
.peek(coupon -> coupon.setDiscountAmount(CouponUtils.calDiscountAmount(coupon, totalAmount)))
//过滤优惠金额小于订单金额的优惠券
.filter(coupon -> coupon.getDiscountAmount().compareTo(totalAmount)<0)
// 计算金额
.map(coupon -> BeanUtils.copyBean(coupon, AvailableCouponsResDTO.class))
//按优惠金额降序排
.sorted(Comparator.comparing(AvailableCouponsResDTO::getDiscountAmount).reversed())
.collect(Collectors.toList());
}
7.优惠券核销与退回表
- 核销逻辑代码
@Transactional(rollbackFor = Exception.class)
public CouponUseResDTO use(CouponUseReqDTO couponUseReqDTO) {
// 1.校验优惠券
// 1.1.获取优惠券
Coupon coupon = baseMapper.selectById(couponUseReqDTO.getId());
// 1.2.优惠券判空
if (coupon == null) {
throw new BadRequestException("优惠券不存在");
}
// 2.使用优惠券
boolean update = lambdaUpdate()
.set(Coupon::getStatus, CouponStatusEnum.USED.getStatus())
.set(Coupon::getUseTime, DateUtils.now())
.set(Coupon::getOrdersId, couponUseReqDTO.getOrdersId())
.eq(Coupon::getId, couponUseReqDTO.getId())
.eq(Coupon::getStatus, CouponStatusEnum.NO_USE.getStatus())
.ge(Coupon::getValidityTime, DateUtils.now())
.le(Coupon::getAmountCondition, couponUseReqDTO.getTotalAmount())
.update();
if (!update) {
throw new DBException("优惠券已失效");
}
// 3.添加核销记录
CouponWriteOff couponWriteOff = CouponWriteOff.builder()
.id(IdUtils.getSnowflakeNextId())
.couponId(couponUseReqDTO.getId())
.userId(coupon.getUserId())
.ordersId(couponUseReqDTO.getOrdersId())
.activityId(coupon.getActivityId())
.writeOffTime(DateUtils.now())
.writeOffManName(coupon.getUserName())
.writeOffManPhone(coupon.getUserPhone())
.build();
if(!couponWriteOffService.save(couponWriteOff)){
throw new DBException("操作失败");
}
// 4.计算优惠金额
BigDecimal discountAmount = CouponUtils.calDiscountAmount(coupon, couponUseReqDTO.getTotalAmount());
CouponUseResDTO couponUseResDTO = new CouponUseResDTO();
couponUseResDTO.setDiscountAmount(discountAmount);
return couponUseResDTO;
}
- 取消订单逻辑代码
@Transactional(rollbackFor = Exception.class)
public void useBack(CouponUseBackReqDTO couponUseBackReqDTO) {
// 1.校验是否可以回退
CouponWriteOff couponWriteOff = couponWriteOffService.queryByUserIdIdAndOrdersId(couponUseBackReqDTO.getUserId(), couponUseBackReqDTO.getOrdersId());
// 未查询到无需回滚
if (couponWriteOff == null) {
return;
}
Coupon coupon = baseMapper.selectById(couponWriteOff.getCouponId());
if(coupon == null){
return;
}
Activity activity = activityService.getById(couponWriteOff.getActivityId());
// 2.回退记录
couponUseBackService.add(couponWriteOff.getCouponId(), couponUseBackReqDTO.getUserId(), couponWriteOff.getWriteOffTime());
// 3.回滚优惠券
CouponStatusEnum couponStatusEnum = coupon.getValidityTime().isAfter(DateUtils.now())
? CouponStatusEnum.NO_USE : CouponStatusEnum.INVALID;
if (ActivityStatusEnum.VOIDED.equals(activity.getStatus())) {
// 活动作废
couponStatusEnum = CouponStatusEnum.VOIDED;
}
boolean update = lambdaUpdate()
.set(Coupon::getStatus, couponStatusEnum.getStatus())
.set(Coupon::getOrdersId, null)
.set(Coupon::getUseTime, null)
.eq(Coupon::getId, coupon.getId())
.update();
if (!update) {
throw new RuntimeException("优惠券回退失败");
}
// 4.删除核销记录
couponWriteOffService.removeById(couponWriteOff.getId());
}
9.发放优惠券
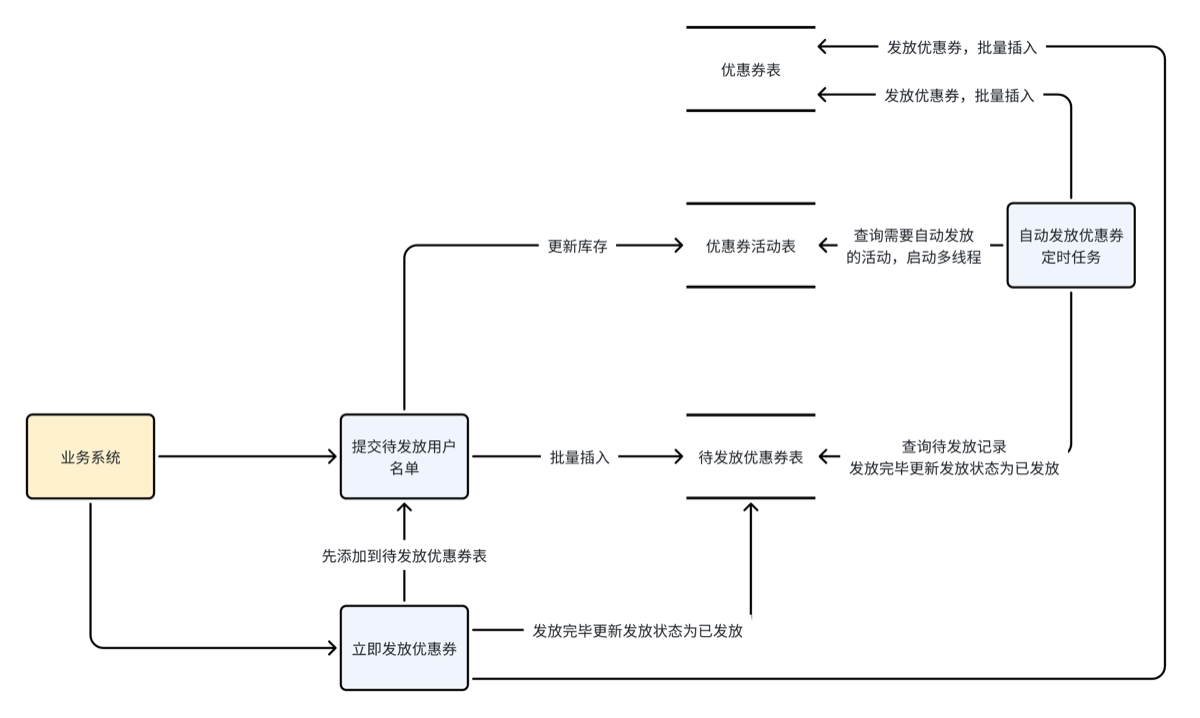
自动发放逻辑
记忆点 自动发放优惠券任务:
通过任务调度在凌晨执行自动发放任务,先去优惠券活动表查询需要自动发放的活动,每个活动的优惠券发放任务由一个线程去执行,首先去待发放优惠券表查询待发放记录,然后将其插入优惠券发放记录表(即优惠券表,插入时将待发放优惠券表的主键作为优惠券表的主键),发放成功需要更新待发放记录的状态为已发放。
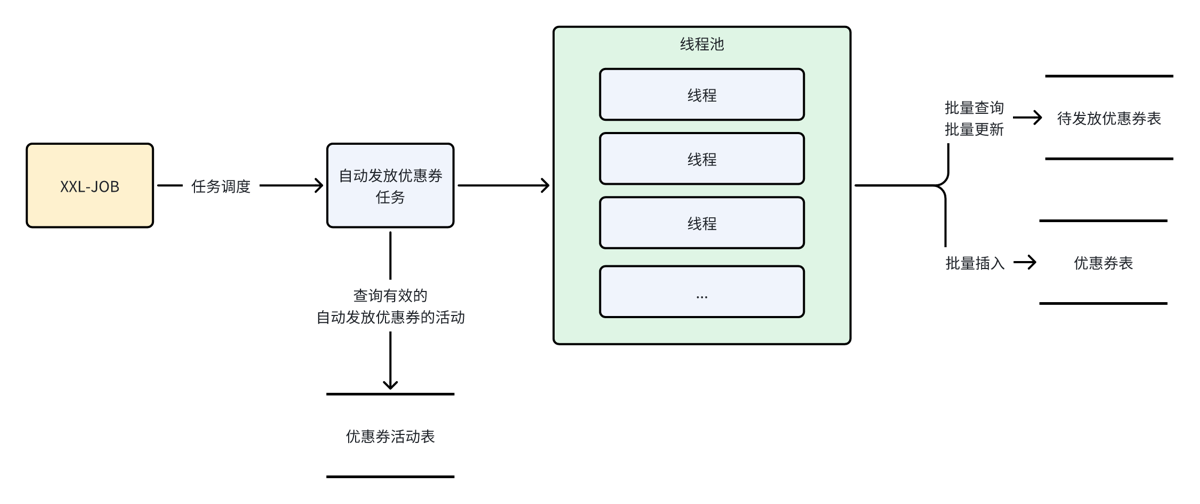
自动发放优惠券
- 涉及大量线程池
- 涉及定时任务
- 涉及分布式锁
@Component
public class XxlJobHandler {
@Resource
private SyncManager syncManager;
@Resource
private IActivityService activityService;
@Resource
private ICouponService couponService;
@Resource
private IssuedCouponHandlerJob issuedCouponHandlerJob;
....
/**
* 自动发放优惠券
*/
@XxlJob("issueCouponJob")
public void issueCouponJob() {
issuedCouponHandlerJob.start();
}
}- 自定义线程池,而不是Executors.newFixedThreadPool(n)
public class IssuedCouponHandlerJob {
//定义线程池
private static ThreadPoolExecutor threadPoolExecutor;
@Resource
private ICouponIssueService couponIssueService;
@Resource
private IActivityService activityService;
@Resource
private RedissonClient redissonClient;
static {
threadPoolExecutor = new ThreadPoolExecutor(0, 20, 60, TimeUnit.SECONDS, new ArrayBlockingQueue<>(100));
}
public void start() {
log.info("自动发放优惠券任务开始");
//从活动表查询还未结束的活动。
List<Activity> activityList = activityService.list(new LambdaQueryWrapper<Activity>()
.in(Activity::getStatus, List.of(0,1)));
//以活动id为单位创建优惠券发放任务,并加入线程池
activityList.stream().forEach(activity -> {
//创建IssuedCouponHandler对象
IssuedCouponHandler issuedCouponHandler = new IssuedCouponHandler(activity.getId(), couponIssueService,redissonClient);
//将任务加入线程池
threadPoolExecutor.execute(issuedCouponHandler);
});
}
}
public class IssuedCouponHandler implements Runnable {
//优惠券发放service
private ICouponIssueService couponIssueService;
//分布式锁
private RedissonClient redissonClient;
//活动id
private Long activityId;
//构造方法
public IssuedCouponHandler(Long activityId,ICouponIssueService couponIssueService,RedissonClient redissonClient) {
this.activityId = activityId;
this.couponIssueService = couponIssueService;
this.redissonClient = redissonClient;
}
public void run() {
//获取锁
String lockKey = "activity:issued:lock:" + activityId;
log.info("获取锁:{}", lockKey);
RLock lock = redissonClient.getLock(lockKey);
//尝试获取锁
try {
boolean tryLock = lock.tryLock(1,-1, TimeUnit.SECONDS);
if(!tryLock){
log.info("获取锁失败:{}", lockKey);
return;
}
try {
//开始发放优惠券
log.info("开始发放优惠券:{}", activityId);
//批量发放优惠券
couponIssueService.autoIssue(activityId);
} catch (Exception e) {
log.error("发放优惠券失败:{}", e.getMessage());
}finally {
lock.unlock();
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}ublic class CouponIssueServiceImpl extends ServiceImpl<CouponIssueMapper, CouponIssue> implements ICouponIssueService {
//批量处理记录数
private static final int BATCH_SIZE = 1000;
//注入优惠券service
@Resource
private ICouponService couponService;
//注入优惠券活动service
@Resource
private IActivityService activityService;
@Resource
private CouponIssueServiceImpl owner;
@Override
@Transactional
public void autoIssue(Long activityId) {
while (true){
//获取待发放记录
List<CouponIssue> couponIssueList = list(new LambdaQueryWrapper<CouponIssue>()
.eq(CouponIssue::getActivityId, activityId)
.eq(CouponIssue::getStatus, 0)
.last("limit " + BATCH_SIZE));
//如果待发放记录为空,则退出
if (CollectionUtils.isEmpty(couponIssueList)) {
break;
}
log.info("待发放记录:{}", couponIssueList);
//准备发放优惠券,创建CouponIssueReqDTO对象
CouponIssueReqDTO couponIssueReqDTO = new CouponIssueReqDTO();
couponIssueReqDTO.setActivityId(activityId);
List<Long> userIds = couponIssueList.stream().map(CouponIssue::getUserId).collect(Collectors.toList());
//将userIds转成字符串,中间用逗号分隔
String userIds = StringUtils.join(",",userIds);
couponIssueReqDTO.setUserIds(userIds);
log.info("准备发放优惠券:{}", couponIssueReqDTO);
try {
owner.issue(couponIssueReqDTO);
} catch (Exception e) {
log.info("发放优惠券:{}异常", couponIssueReqDTO);
e.printStackTrace();
throw e;
}
//休眠1秒
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}在同一个类里面,方法 A 调用方法 B(this.issue()),方法 B 的事务注解是不生效的(因为绕过了 Spring 的代理对象)。 #代理对象 解决: 注入自己(owner),然后通过 owner.issue() 调用。这就相当于告诉 Spring:“请通过代理对象来调用这个方法”,这样事务就能正常开启和提交了。
-
XXL-JOB 触发
issueCouponJob(比如 10:00:00)。 -
JobHandler 查出 3 个正在进行的活动(A, B, C)。
-
线程池 分配 3 个线程。
- 线程 1 处理活动 A。
- 线程 2 处理活动 B。
- 线程 3 处理活动 C。
-
线程 1(以活动 A 为例):
- 尝试去 Redis 抢锁(防止别的服务器也在处理活动 A)。
- 抢到了!调用
autoIssue(activityA)。
-
Service 层:
- 查询活动 A 前 1000 个没发券的用户。
- 调用
owner.issue给这 1000 人发券(写库、改状态)。 - 休息 1 秒。
- 再查下 1000 个…
- 直到没数据了,方法结束。
-
线程 1 释放 Redis 锁。任务结束。
为什么要使用线程和锁?
分配工人:如果不使用线程池,代码就是串行的。系统必须先发完“双11”的几万张券,才能去发“新用户”的券。 用了线程池,“双11”和“新用户”两个活动是同时(并发)开始发券的,互不耽误,效率倍增。
A. 防止重复执行(幂等性保护)
在微服务架构中,为了高可用,服务通常会部署多个实例。如果不加锁,当定时任务触发时,所有实例都会同时执行 autoIssue
- 后果: 多个线程同时查询数据库,拿到同一批“未发放”的用户记录,然后同时调用发券接口。导致用户瞬间收到多张优惠券。
B. 避免数据库“惊群效应” 即使你的业务逻辑写得很完美(比如在数据库层面加了乐观锁),如果 10 台服务器同时去查询数据库里的待发放记录:
- 后果: 数据库瞬间承受 10 倍的查询压力(QPS 飙升),但实际上只有 1 台服务器的操作是有效的,其他 9 台都在做无用功。
提交待发放优惠券
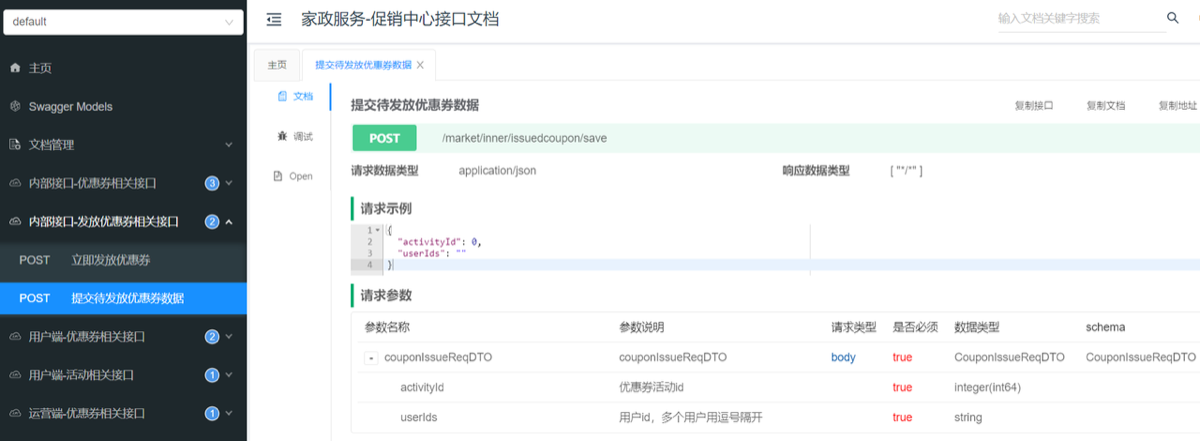
- 涉及大量stream流的各种用法
- 涉及大量lambdaQuery用法
@Transactional(rollbackFor = Exception.class)
public List<CouponIssue> save(CouponIssueReqDTO couponIssueReqDTO) {
//活动id
Long activityId = couponIssueReqDTO.getActivityId();
//拿到用户id,中间逗号分隔
String userIds = couponIssueReqDTO.getUserIds();
//如果为空或空字符串,直接返回
if (StringUtils.isEmpty(userIds)) {
return new ArrayList<>();
}
//将用户id转成List<long>
List<Long> userIdList = Arrays.stream(userIds.split(",")).map(Long::parseLong).collect(Collectors.toList());
//找到名单中在待发放表不存在记录 select * from coupon_issue where activity_id=? and user_id not in (?,?) List<CouponIssue> list = lambdaQuery().eq(CouponIssue::getActivityId, activityId)
.in(CouponIssue::getUserId, userIdList)
.list();
//从list提取出userId
List<Long> userIdList2 = list.stream().map(CouponIssue::getUserId).collect(Collectors.toList());
//找到userIdList中不存在userIdList2的用户id
List<Long> userIdList3 = userIdList.stream().filter(userId -> !userIdList2.contains(userId)).collect(Collectors.toList());
//如果列表为空直接返回
if (CollUtils.isEmpty(userIdList3)) {
return new ArrayList<>();
}
//根据userIdList3组装List<CouponIssue>
List<CouponIssue> couponIssueList = userIdList3.stream().map(userId -> {
CouponIssue couponIssue = new CouponIssue();
//主键用雪花算法
couponIssue.setId(IdWorker.getId());
//活动id
couponIssue.setActivityId(activityId);
//用户id
couponIssue.setUserId(userId);
//状态,默认为未发放
couponIssue.setStatus(0);
return couponIssue;
}).collect(Collectors.toList());
//向待发放优惠券表批量插入
boolean b = saveBatch(couponIssueList);
if (!b) {
//抛出异常
throw new DBException("批量插入待发放优惠券失败");
}
int size = couponIssueList.size();
//更新活动表的库存,因为只要将名单 插入待发放表 一定能发放,这里更新库存,避免库存不足,导致优惠券发放失败
// update activity set stock_num=stock_num-? where id=? and stock_num>=?
LambdaUpdateWrapper<Activity> updateWrapper = new LambdaUpdateWrapper<Activity>()
.eq(Activity::getId, activityId)
.setSql("stock_num=stock_num-" + size)
.gt(Activity::getStockNum, size);
int update = activityMapper.update(null, updateWrapper);
//如果更新失败
if (update <= 0) {
//抛出异常
throw new BadRequestException("库存不足,提交待发放优惠券记录失败");
}
return couponIssueList;
}
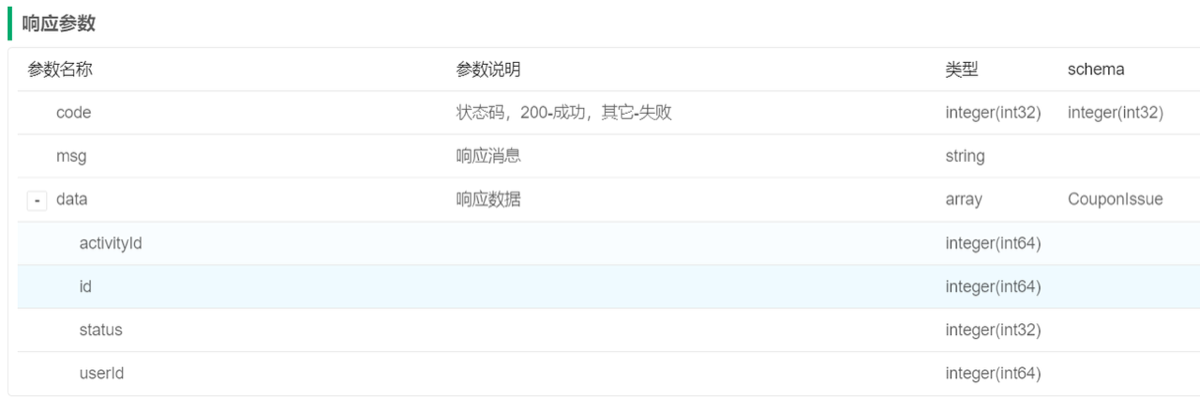
立即发放优惠券
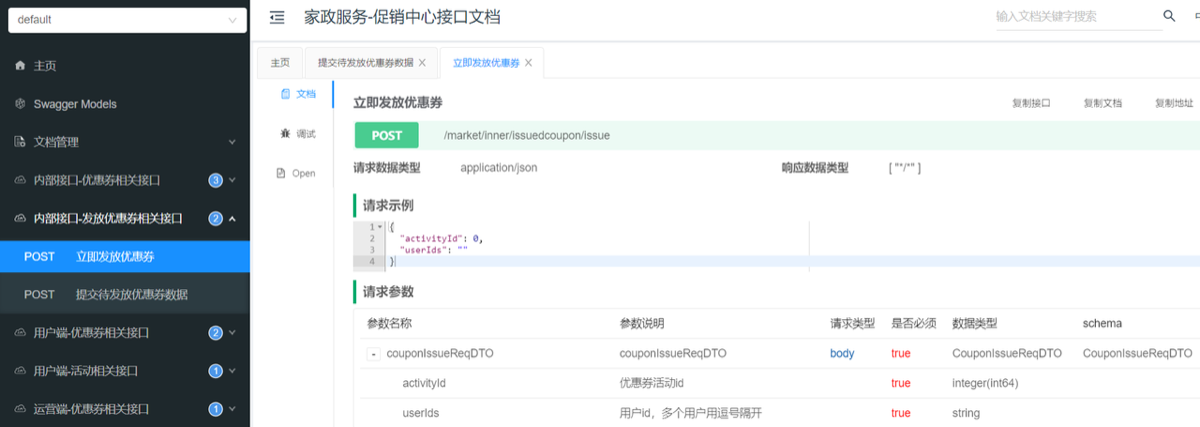
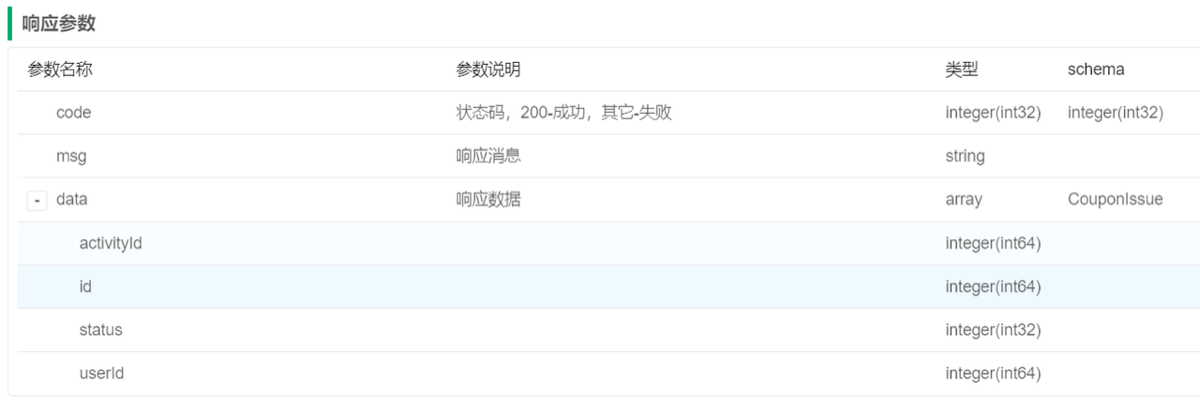
@Transactional
public List<CouponIssue> issue(CouponIssueReqDTO couponIssueReqDTO) {
//活动id
Long activityId = couponIssueReqDTO.getActivityId();
//查询活动信息
Activity activity = activityMapper.selectById(activityId);
//todo 校验活动是否有效
//将名单插入到待发放优惠券表
save(couponIssueReqDTO);
//拿到用户id,中间逗号分隔
String userIds = couponIssueReqDTO.getUserIds();
//将用户id转成List<long>
List<Long> userIdList = Arrays.stream(userIds.split(",")).map(Long::parseLong).collect(Collectors.toList());
//根据名单从待发放优惠券表发到没有发放的名单
//select * from coupon_issue where activity_id=? and user_id in (?,?) and status=0
List<CouponIssue> list = lambdaQuery().eq(CouponIssue::getActivityId, couponIssueReqDTO.getActivityId())
.in(CouponIssue::getUserId, userIdList)
.eq(CouponIssue::getStatus, 0)
.list();
if (CollUtils.isEmpty(list)) {
return new ArrayList<>();
}
//从list中提取出userId
List<Long> userIdList2 = list.stream().map(CouponIssue::getUserId).collect(Collectors.toList());
//根据名单 从优惠券表找没有领取优惠券的名单
LambdaQueryWrapper<Coupon> queryWrapper = new LambdaQueryWrapper<Coupon>()
.eq(Coupon::getActivityId, couponIssueReqDTO.getActivityId())
.in(Coupon::getUserId, userIdList2);
List<Coupon> couponList = couponMapper.selectList(queryWrapper);
//从couponList提取出userid
List<Long> userIdList3 = couponList.stream().map(Coupon::getUserId).collect(Collectors.toList());
//找到userIdList2中在userIdList3中不存在记录
List<Long> userIdList4 = userIdList2.stream().filter(userId -> !userIdList3.contains(userId)).collect(Collectors.toList());
//如果名单为空直接返回
//根据userIdList4组装List<Coupon>
List<Coupon> couponList2 = userIdList4.stream().map(userId -> {
Coupon coupon = new Coupon();
//主键
coupon.setId(IdWorker.getId());
//活动id
coupon.setActivityId(activity.getId());
//userid
coupon.setUserId(userId);
//活动名称
coupon.setName(activity.getName());
//优惠类型
coupon.setType(activity.getType());
coupon.setDiscountRate(activity.getDiscountRate());
coupon.setDiscountAmount(activity.getDiscountAmount());
coupon.setAmountCondition(activity.getAmountCondition());
coupon.setValidityTime(LocalDateTime.now().plusDays(activity.getValidityDays()));//优惠券有效期
//状态默认为未使用
coupon.setStatus(1);
return coupon;
}).collect(Collectors.toList());
//向优惠券表批量插入
boolean b = couponService.saveBatch(couponList2);
//批量失败
if (!b) {
//抛出异常
throw new DBException("优惠券发放失败");
}
//遍历list将待发放状态改为1
list.forEach(couponIssue -> couponIssue.setStatus(1));
//批量更新
boolean updateBatchById = updateBatchById(list);
//更新失败
if (!updateBatchById) {
//抛出异常
throw new DBException("优惠券发放失败");
}
return list;
}
四.订单系统
1.创建订单
需求分析
- 需要用户信息,优惠券,价格,地址等信息
服务流程
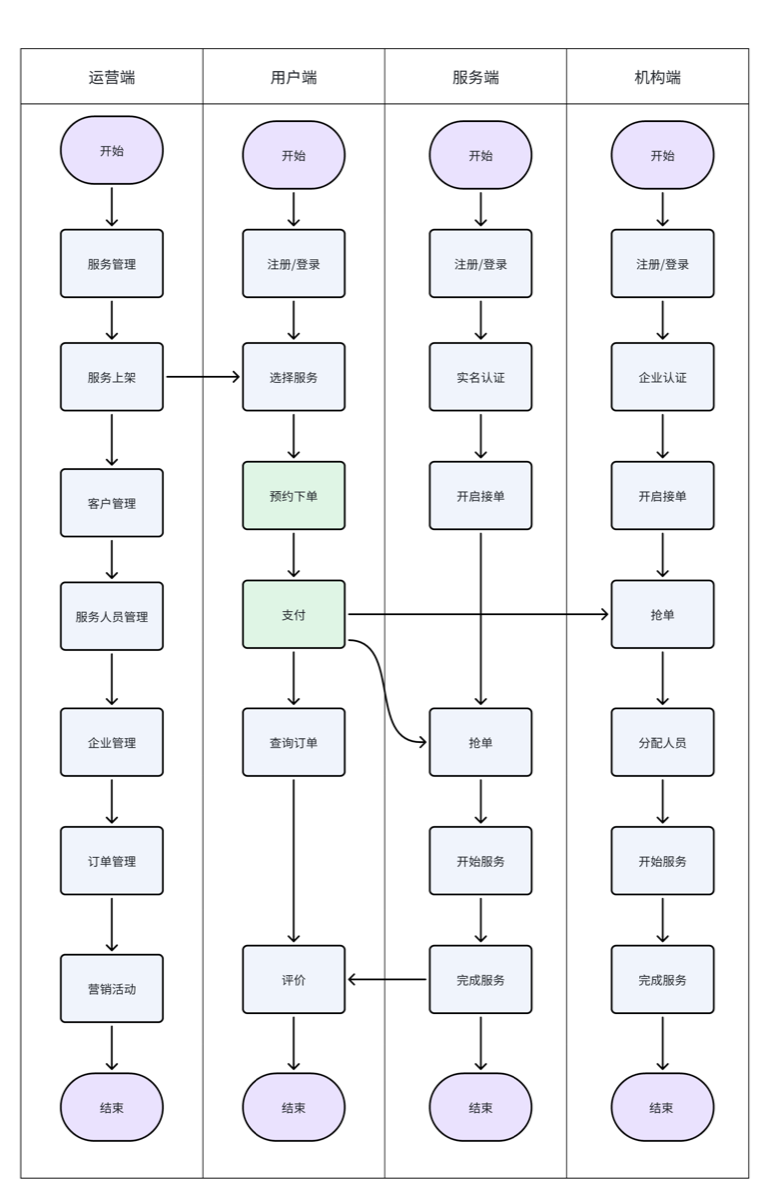
界面原型
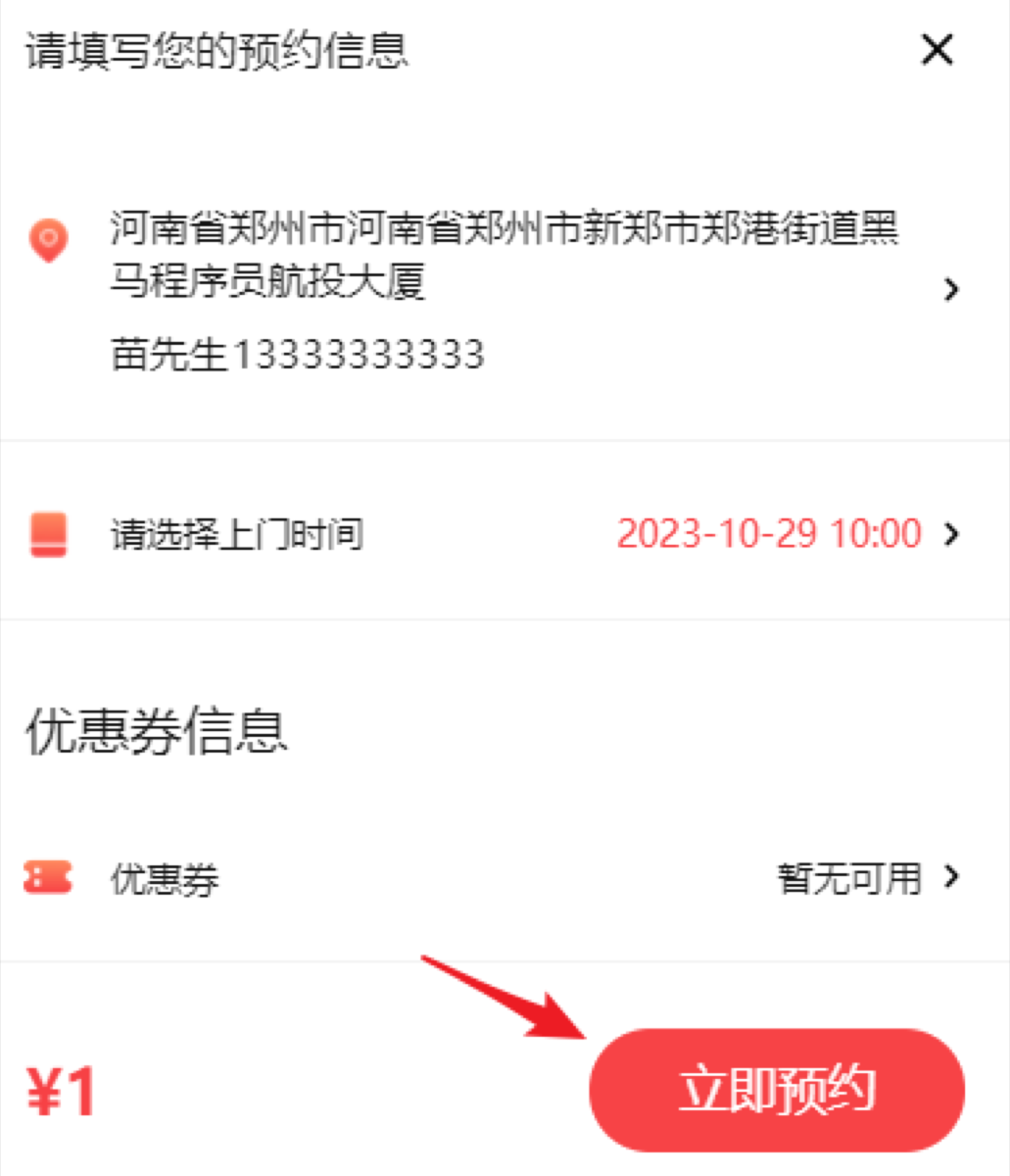
订单状态
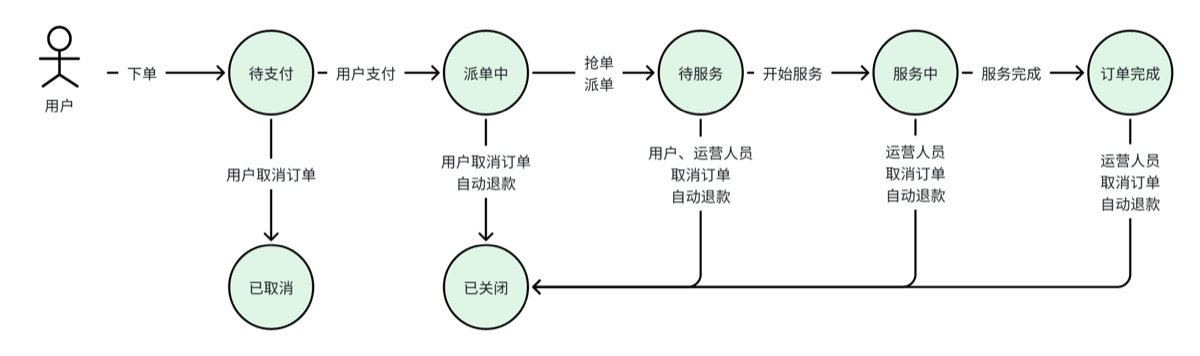
记忆点 能说出订单状态流程
订单表设计
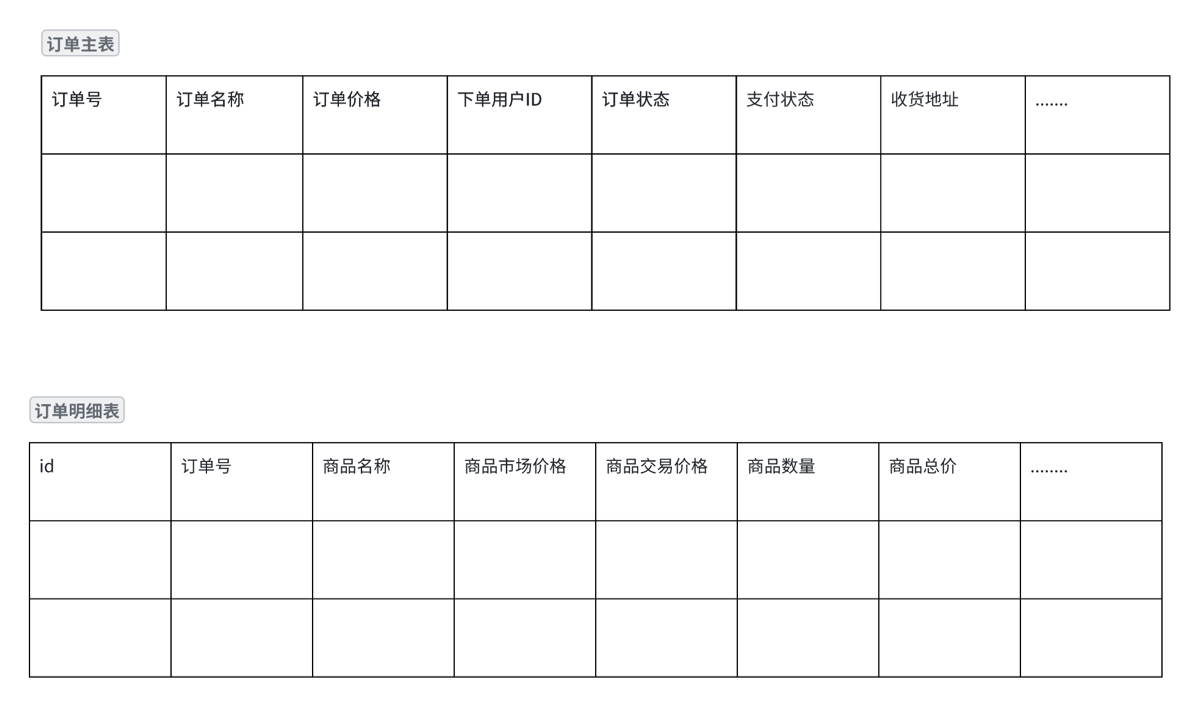
订单基础信息:订单号、订单状态、排序字段、是否显示标记等。 价格信息:单价、购买数量、优惠金额、订单总金额等。 下单人信息:下单人ID、联系方式、位置信息(相当于收货地址)等。 服务(商品)相关信息:服务类型名称、服务项名称、服务单价、价格单位、购买数量等
- 电商项目下,订单包含多个商品,使用订单表和订单明细表
- 在家政服务下,使用订单表即可
| 工程名 | 服务名 | 职责 |
| jzo2o-orders-base | 订单模块基础工程 | 提供数据模型、数据访问基础mapper,供其它工程通过maven依赖。 |
| jzo2o-orders-manager | 订单管理服务 | 预约下单、服务管理、取消订单等订单管理相关的接口。 |
| jzo2o-orders-seize | 抢单服务 | 为服务人员和机构抢单提供服务。 |
| jzo2o-orders-dispatch | 派单服务 | 根据派单规则自动为服务人员、机构派送订单。 |
| jzo2o-orders-history | 历史订单服务 | 订单冷热分离,历史订单查询接口。 |
开发知识点
- 订单号的生成规则
- 自增
- 时间戳+随机数
- 订单类型+日期+序号(本项目使用日期➕序号)
- 时间戳+redis INCR实现
- 分布式唯一ID生成器(雪花算法)
| 规则类型 | 格式示例 | 优点 | 缺点 |
|---|---|---|---|
| 自增数字 | 1, 2, 3… | 简单,节省空间,查询快(B+树友好)。 | 不安全(容易被爬虫猜测出订单量);分库分表困难;ID 不含业务信息。 |
| UUID | 32位长字符串 | 简单,本地生成,性能极高,无网络交互。 | 太长(不适合做索引);无序(导致数据库页分裂,插入慢);不易读。 |
| 时间戳+随机数 | 20231028 + 随机数 | 包含时间信息,便于按天统计。 | 有碰撞风险(高并发下随机数可能重复)。 |
| 雪花算法 (Snowflake) | 64位 Long 类型 | 全局唯一;趋势递增(索引友好);高性能(本地生成)。 | 依赖系统时钟(时钟回拨会报错);长度固定,不一定包含业务含义。 |
| 业务规则组合 | 业务码+时间+Redis自增 | 包含业务属性(如VIP、地区),方便客服和排查。 | 依赖中间件(Redis),实现稍复杂。 |
优化问题
1.创建订单的优化
-
创建订单的优化
2. 批量向对象批量插入数据时
使用orders.builder方法批量插入
- 优势:可读性更强 也可使用buffer,虽然线程安全,适合多线程环境,但性能略低 同时,地址的字符串拼接也使用StringBuilder方法
StringBuilder addressBuilder = new StringBuilder();
addressBuilder.append(detail.getProvince())
.append(detail.getCity())
.append(detail.getCounty())
.append(detail.getAddress());
String serveAddress = addressBuilder.toString();
3. Spring中的循环依赖
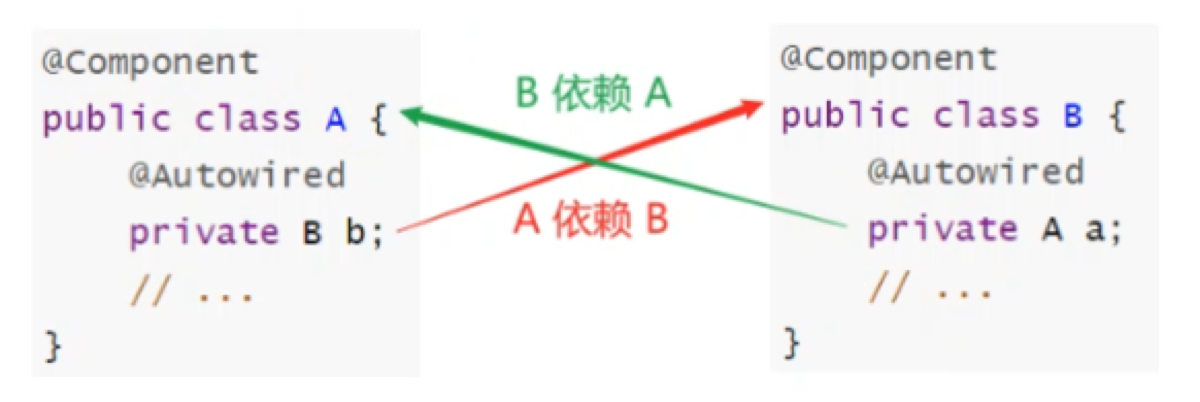
-
Bean延迟初始化,先创建半成品,在注入对方依赖
-
使用三级缓存实现(具体的缓存在文档中)
-
也可用构造方法实现(但引发的问题更难解决@Lazy,不推荐)

4. 防止重复提交订单
- 前端:按钮变灰
- 后端:
- 判断token,比较麻烦
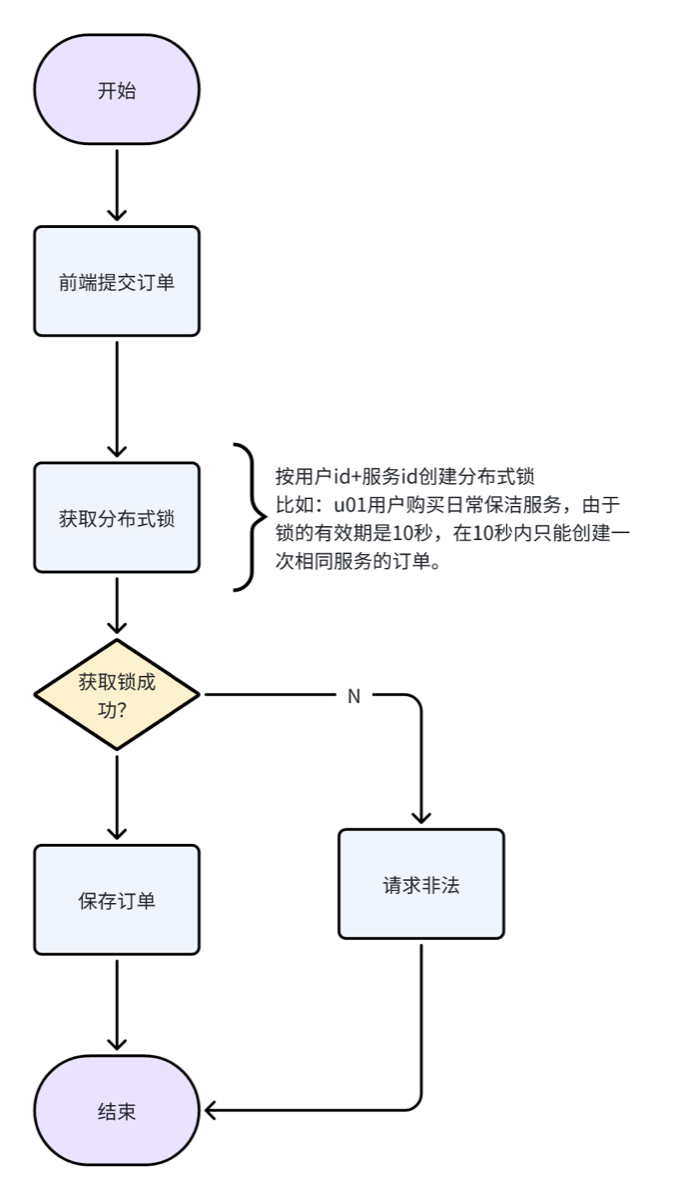
- 分布式锁🔒 难点
- (锁的粒度)基于用户的名称+服务id为🔒的名称,在20s内下一次单
- 先封装一个Lock注解(Java注解(Annotation),来保存上面的锁的名称与其他过期时间等配置
- 基于此注解编写一个AOP切面类,通过代理对象实现加锁与释放锁的功能
- 以上代码在freamworke.Reids.中封装
 #AOP
AOP
#AOP
AOP
package com.jzo2o.redis.annotations;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
import java.util.concurrent.TimeUnit;
// 注解文件的关键标识
@Retention(RetentionPolicy.RUNTIME) // 运行时保留
@Target(ElementType.METHOD) // 应用目标
public @interface Lock { // @interface关键字.
//`@interface` 是 Java 的关键字,专门用来定义注解。它本质上是一个继承了 `java.lang.annotation.Annotation` 接口的特殊接口。
// 注解属性定义
String formatter();
long time() default 5;
/**
* @author Mr.M
* @version 1.0
* @description 分布式锁工具类
* @date 2023/7/23 22:48
*/
- **翻译**:保留策略 = 运行时。
- **作用**:这非常关键!它表示这个注解**一直保留到程序运行的时候**。
- **为什么必须是 RUNTIME?** 因为你的 AOP 切面(`LockAspect`)是在程序**运行**过程中,通过反射去读取注解里的内容的。如果选了 `SOURCE`(只在源码保留)或 `CLASS`,程序一跑起来,这个注解就“消失”了,AOP 就抓瞎了。
@Retention(RetentionPolicy.RUNTIME)
**`@Target(ElementType.METHOD)`**
- **翻译**:目标 = 方法。
- **作用**:规定这个贴纸**只能贴在方法上**。如果你试图把它贴在类(Class)或者字段(Field)上,编译器会直接划红线报错。
@Target(ElementType.METHOD)
public @interface Lock {
/**
* 加锁key的表达式,支持表达式
*/
String formatter();
/**
* 加锁时长
*/
long time() default 5;
/**
* 阻塞超时时间,默认2分钟,当block为true的时候生效
*/
long waitTime() default 120;
/**
* 加锁时间单位
*/
TimeUnit unit() default TimeUnit.SECONDS;
/**
* 方法访问完后要不要解锁,默认自动解锁
*/
boolean unlock() default true;
/**
* 如果设定了true将在获取锁时阻塞等待waitTime时间
*/
boolean block() default false;
/**
* 是否启用自动续期,如果使用自动续期则unlock必须设置为true
*/
boolean startDog() default false;
}
/**
* @author Mr.M
* @version 1.0
* @description 分布式锁工具类
* @date 2023/7/23 22:56
*/
@Aspect
public class LockAspect {
//redis的客户端,用来操作分布式锁
private final RedissonClient redissonClient;
public LockAspect(RedissonClient redissonClient) {
this.redissonClient = redissonClient;
}
@Around("@annotation(lock)") //pjp是拦截的方法,可以 调用process 放行。lock 是使用注解时里面的各种参数
public Object handleLock(ProceedingJoinPoint pjp, Lock lock) throws Throwable {
//锁key的格式化字符,此字符串中有spEL表达式.
//用了 Spring 的 **SpEL (Spring Expression Language)**。通过解析注解里的 `#userId` 字符串,结合反射拿到的方法参数值,动态拼装出 Redis Key。这比写死 Key 要灵活得多。
String formatter = lock.formatter();
Method method = AspectUtils.getMethod(pjp);
Object[] args = pjp.getArgs();
//得到锁的key
String redisKey = AspectUtils.parse(formatter, method, args);
//获取锁阻塞等待的时间,如果是0表示去尝试获取锁,如果获取不到则结束
long waitTime = 0;
//阻塞等待获取锁
if (lock.block()) {
//根据时间单位转换成ms
waitTime = lock.waitTime();
}
//加锁时长
long time = lock.time();
//启动看门狗自动续期
if(lock.startDog()){
time = -1;
//如果设置自动续期必须在方法执行后释放锁
if(!lock.unlock()){
throw new BadRequestException(ErrorInfo.Msg.REQUEST_PARAM_ILLEGAL);
}
}
//得到锁对象
RLock rLock = redissonClient.getLock(redisKey);
//尝试加锁
boolean success = rLock.tryLock(waitTime,time, lock.unit());
if (!success && !lock.block()) {
//未阻塞要求的情况下未得到锁
throw new BadRequestException(ErrorInfo.Msg.REQUEST_OPERATE_FREQUENTLY);
}
if (!success) {
//阻塞情况下未得到锁,请求超时
throw new RequestTimeoutException(ErrorInfo.Msg.REQUEST_TIME_OUT);
}
try {
return pjp.proceed();
} finally {
if (lock.unlock()) {
rLock.unlock();
}
}
}- 关于 block 字段
| 模式 | block() 值 | 典型场景 | 业务话术 |
|---|---|---|---|
| 快速失败 | false | 防重复提交、用户点赞、抢红包 | “手慢了,红包派完了!” / “请勿重复点击!” |
| 阻塞等待 | true | 库存扣减、资金转账、核心数据修改 | “系统处理中…” (用户虽然在转圈圈,但后台在排队处理,保证一定能执行) |
- 关于看门狗字段
你可能会问:“为什么要把时间设为 -1?时间怎么能是负数呢?”
这是 Redisson 的内部约定(暗号)。 在 Redisson 的 tryLock(waitTime, leaseTime, unit) 方法中:
-
如果 leaseTime > 0(比如 10秒):Redisson 会告诉 Redis “这个锁 10秒后必须自动删除”,不管你业务跑完没有。这叫硬过期。
-
如果 leaseTime = -1:Redisson 不会给 Redis 设置过期时间,而是开启一个后台线程(看门狗)。
看门狗的作用: 它默认每隔 10 秒(lockWatchdogTimeout 的 1/3)就会去查看一下:“哎,那个线程还在跑吗?还在跑啊?那行,我给锁再续命 30 秒。” 只要业务线程还在,锁就永远不会过期。
在这里写了一个防御性判断:想用看门狗?行,但你必须保证用完要还(unlock=true)。如果你想由调用者手动解锁(unlock=false),那就不许用看门狗,必须设个固定过期时间。
“在使用 Redisson 解锁时,我特意加了一个多重校验的逻辑。
并不是直接 unlock 就可以的。因为在高并发或网络波动场景下,业务执行时间一旦超过了锁的过期时间(LeaseTime),锁就会自动释放,甚至可能被其他线程抢占。
如果不加判断直接解锁,当前线程会试图释放‘不属于自己的锁’。虽然 Redisson 底层脚本会阻止误删(不会删掉别人的锁),但它会在 Java 层抛出 IllegalMonitorStateException 异常。
这会导致一个严重的 UX 问题:明明业务逻辑执行成功了,但因为 finally 里的异常,导致接口给前端返回了失败。
所以我加上了 isHeldByCurrentThread() 的判断,确保只有锁还在我手里的时候,我才去执行解锁操作,这样大大提高了系统的健壮性。”
finally {
// 1. 业务层面允许解锁
// 2. 锁确实存在(没过期)
// 3. 锁确实是我自己的(没被别人抢走)
if (lock.unlock() && rLock.isLocked() && rLock.isHeldByCurrentThread()) {
rLock.unlock();
}
}@Lock需要userId来拼 Key,但入口方法里没有userId参数(在UserContext里)。所以写了个重载方法,把userId显式传进去,方便 SpEL 读取。- 如果在
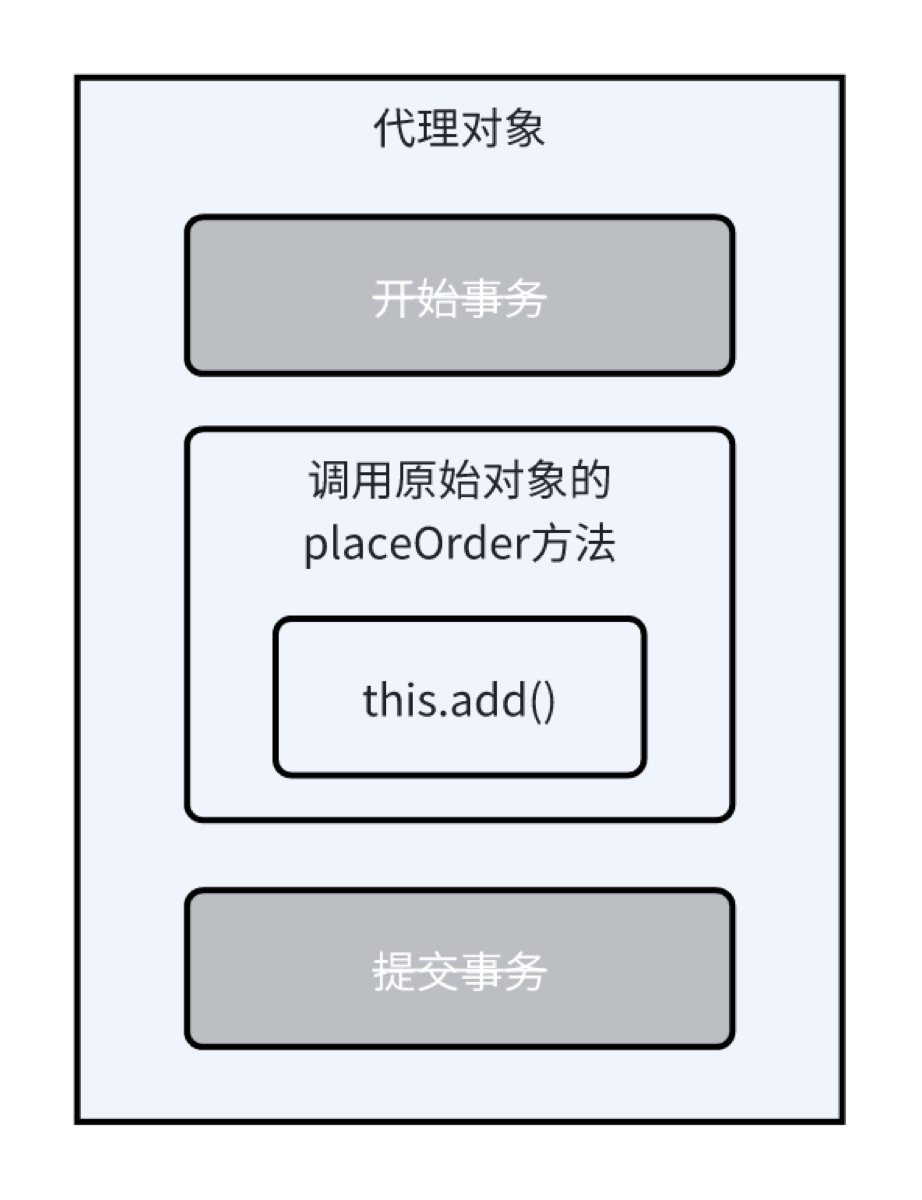
方法1里直接写placeOrder(...)(即this.placeOrder),属于类内部调用,不经过 Spring 代理。AOP 切面拦截不到,@Lock注解会失效! - Redisson:屏蔽了底层复杂的 Redis 命令和多线程同步细节。
- redissonClient.getLock(redisKey);
- rLock.tryLock(waitTime, time, lock.unit());
@Override
public PlaceOrderResDTO placeOrder(PlaceOrderReqDTO placeOrderReqDTO) {
Long userId = UserContext.currentUserId();
// ★★★ 重点:没有直接调用 this.placeOrder(...),而是用了 owner ★★★
return owner.placeOrder(userId,placeOrderReqDTO);
}
@Lock(formatter = "ORDERS:CREATE:LOCK:#{userId}:#{placeOrderReqDTO.serveId}", time = 30, waitTime = 1,unlock=false)
public PlaceOrderResDTO placeOrder(Long userId,PlaceOrderReqDTO placeOrderReqDTO) {
// 1.数据校验
// 校验服务地址
'''
'''
//保存订单
owner.add(orders);
return new PlaceOrderResDTO(orderId);
}
@Transactional(rollbackFor = Exception.class)
public void add(Orders orders) {
boolean save = this.save(orders);
if (!save) {
throw new DbRuntimeException("下单失败");
}
}项目中有用到AOP吗,怎么用的?
- SpringCache,会进去查缓存书否命中
- 上面的事务控制,用自己的代理对象
- 分布式锁中的Lock注解与LockAspect切面类
2.优惠券核销
订单管理调用服务券服务:传入服务Id与数量,先由调用serveApi取出serve单价,在调用couponApi传入单价和用户id的得出优惠券列表
public List<AvailableCouponsResDTO> getAvailableCoupons(Long serveId, Integer purNum) {
// 1.获取服务
ServeAggregationResDTO serveResDTO = serveApi.findById(serveId);
if (serveResDTO == null || serveResDTO.getSaleStatus() != 2) {
throw new BadRequestException("服务不可用");
}
CurrentUser currentUser = UserContext.currentUser();
Long userId = currentUser.getId();
// 2.计算订单总金额
BigDecimal totalAmount = serveResDTO.getPrice().multiply(new BigDecimal(purNum));
// 3.获取可用优惠券,并返回优惠券列表
List<AvailableCouponsResDTO> available = couponApi.getAvailable(userId,totalAmount);
return available;
}分布式事务
下单时核销优惠券,创建订单和核销优惠券需要保证事务一致性,要么两者都成功,要么两者都失败。
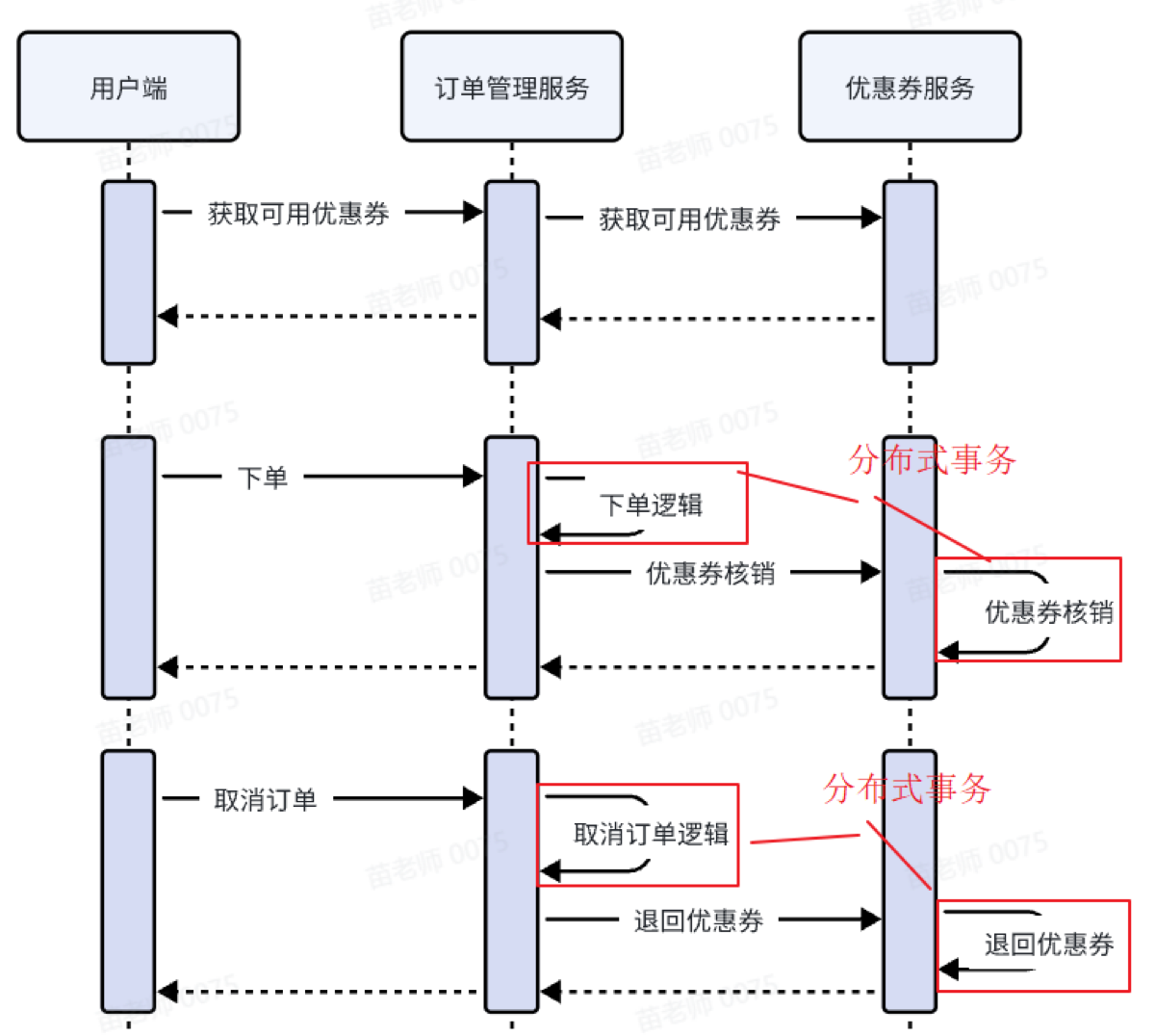
配置seata
seata 配置按着文档没问题,
在订单的数据库和优惠券数据库中创建undo_log表,此表记录每个分支事务的undo_log信息。
在addWithCoupon方法上,添加全局事务注解
@Override
public PlaceOrderResDTO placeOrder(PlaceOrderReqDTO placeOrderReqDTO) {
...
//保存订单
// owner.add(orders);
// 使用优惠券下单
if (ObjectUtils.isNotNull(placeOrderReqDTO.getCouponId())) {
// 使用优惠券
owner.addWithCoupon(orders, placeOrderReqDTO.getCouponId());
} else {
// 无优惠券下单,走本地事务
owner.add(orders);
}
return new PlaceOrderResDTO(orders.getId());
}开启全局事务
- 不经过代理调用的带@Global Transaction的方法,seata根本无法拦截事务入口,所以不会产生xid,更不会与TC交互
- 带有@Global Transaction的方法必须是public且被Spirng容器管理的bean,调用时,必须通过spring注入的对象,不能是this.add,只能是类似createService.add这种形式也就是自己调自己1.创建订单的优化
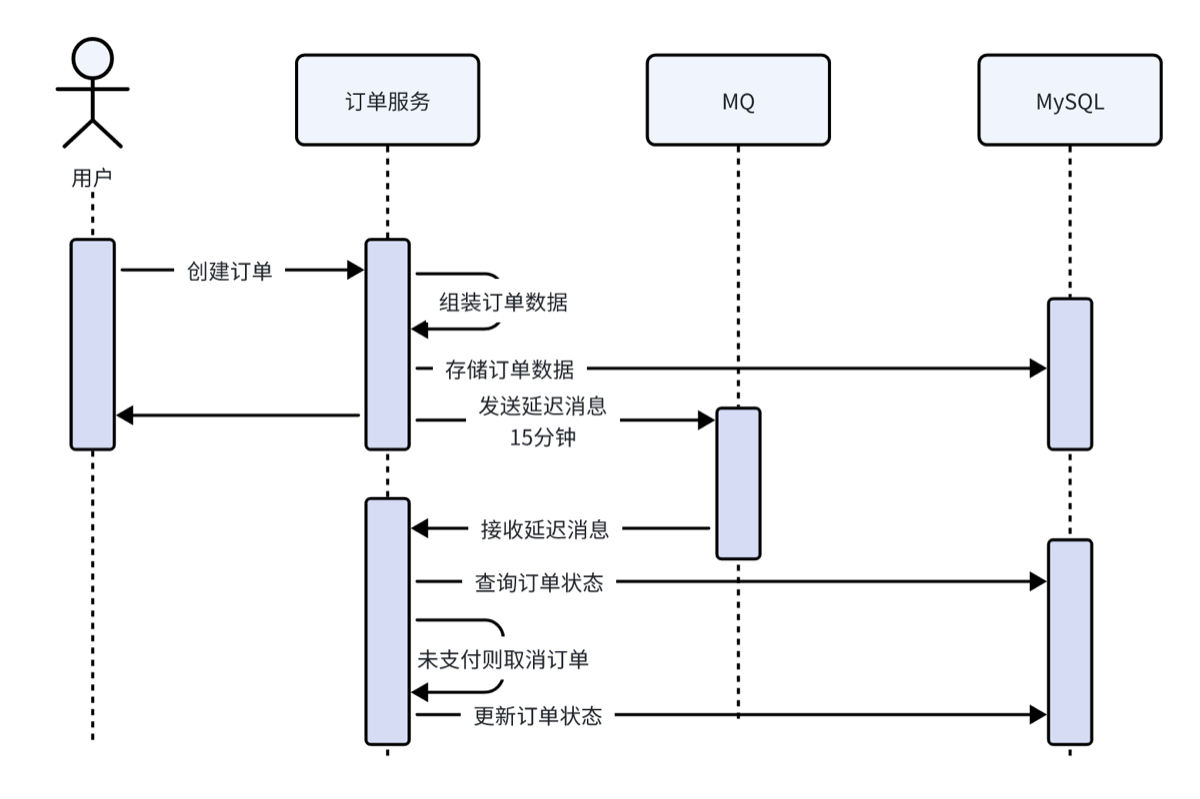
3.取消超时订单
技术方案
- 1.延迟消息(使用 MQ,这里本项目使用第二种方法)
- 2.定时任务+懒加载
- 定时任务方式
- 下单时记录超时时间,开启超时任务查询状态为待支付且达到超时时间,执行取消操作
- 为提高效率,将超过时间字段与状态字段加索引,查询时仅查询id
- 懒加载
- 不能及时取消,解决方法是,当用户打开订单页面是,让程序判断是否到达超时时间,如果到达,则用户看到的就是取消订单的画面
- 定时任务方式
- 3.取消订单时,如果用户使用优惠券,则须进行分布式事务控制
- 4.支付成功订单却自动取消(进入支付页面加时间)
五.支付系统
- 已完成
- 支付系统插入后需要添加退款中操作和已退款操作(定时任务)
- 使用策略模式优化取消订单操作(在下一章节中)
1.接收支付通知
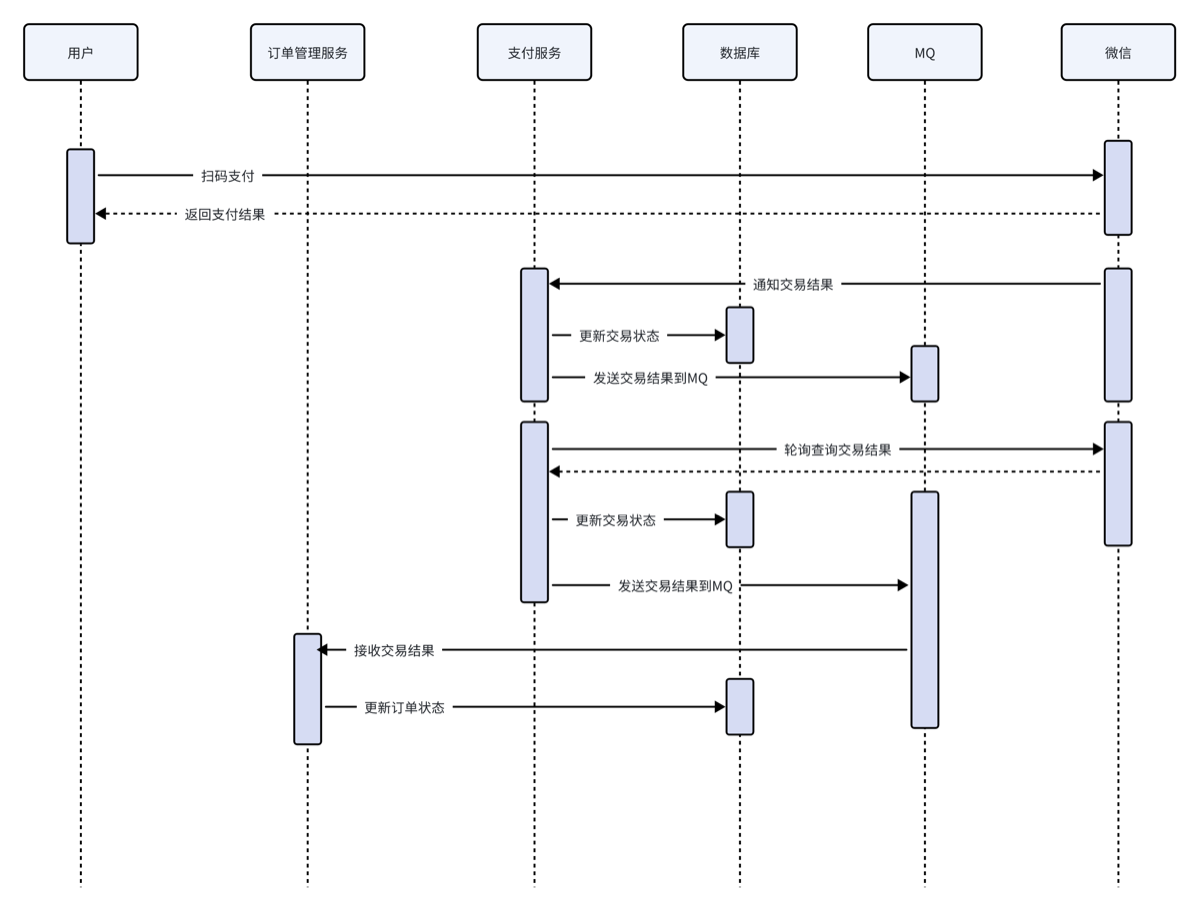
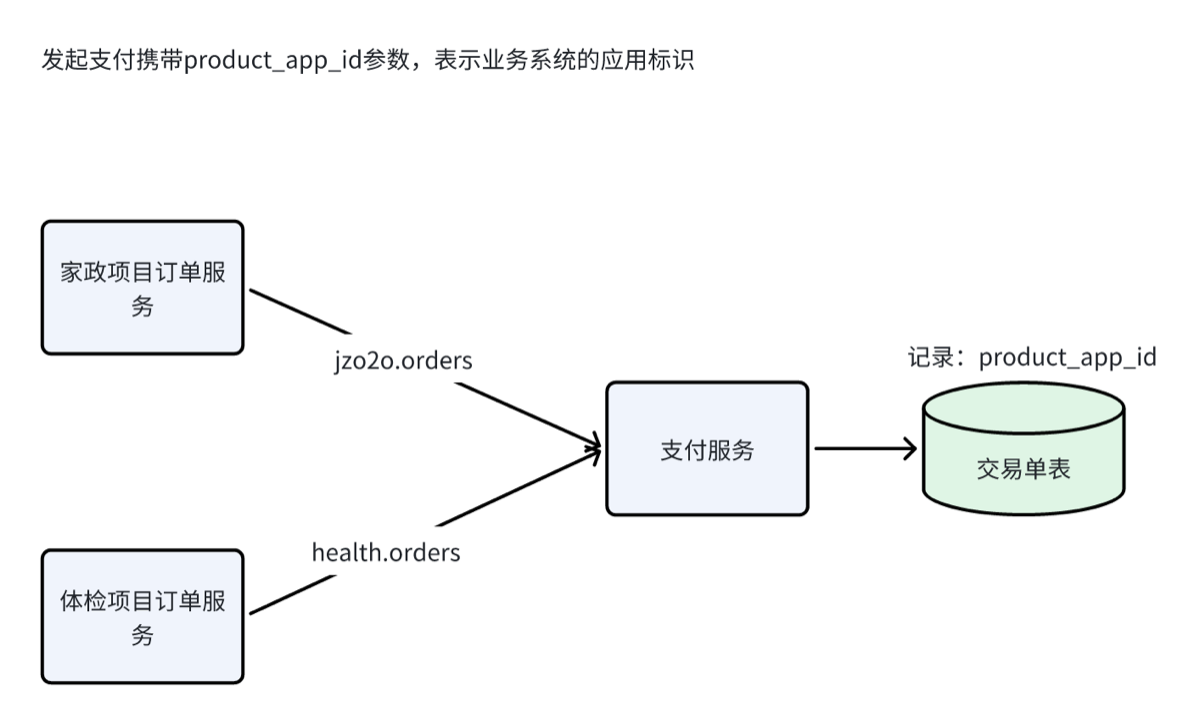
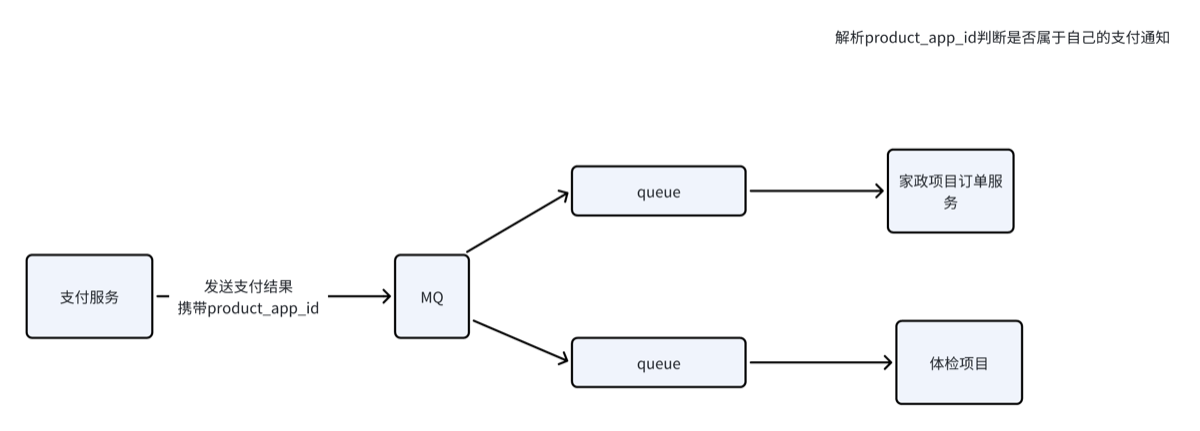
支付服务将支付结果发送到MQ,订单管理服务监听MQ,收到支付结果,更新订单表的支付状态。 这里有个问题是:支付服务作为项目的公共支付服务,对接支付服务的可能不止家政服务订单还可能有其它收费订单,比如:体检项目订单服务等等,支付服务如何将属于每个收费订单的支付结果通知给它们呢?
-
首先在请求支付服务支付接口中需要传入product_app_id,它表示请求支付业务系统的应用标识,此应用标识会存储到支付服务的交易单表
-
支付服务通知支付结果时将交易单中的product_app_id一起发给各个监听MQ的微服务。
具体的方法是:
支付服务向jzo2o.exchange.topic.trade交换机发送消息,Routing Key=UPDATE_STATUS
绑定此交换机的有多个队列,每个队列是不同的收费订单支付通知队列,如下图:
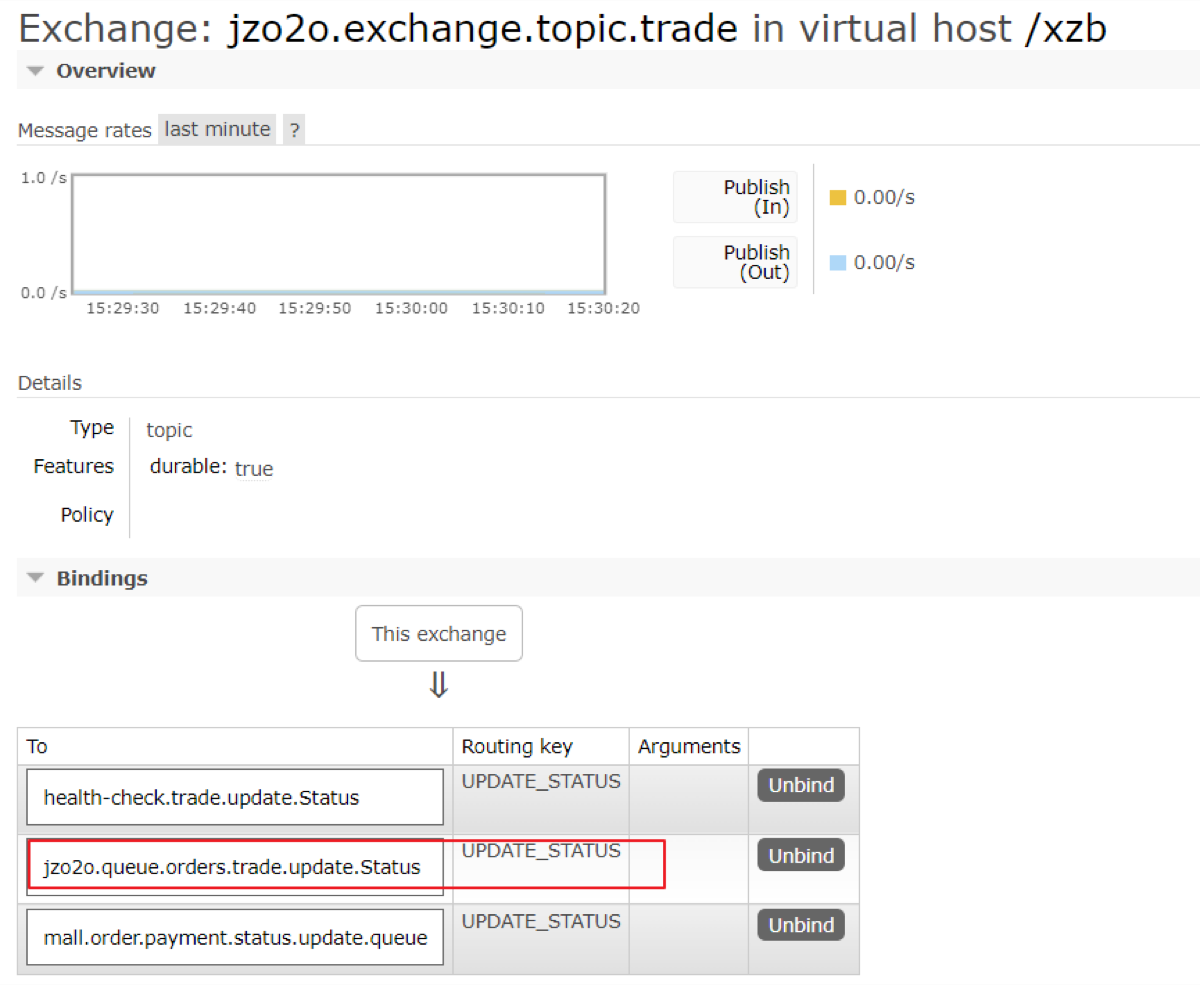
当支付服务向jzo2o.exchange.topic.trade交换机发送一条支付通知消息,所有绑定此交换机的队列且Routing Key=UPDATE_STATUS都会收到支付通知。
业务系统收到支付结果后解析出product_app_id,判断是否属于自己的支付结果通知,如果是则进行处理。
整体交互流程如下:
@Slf4j
@Component
public class TradeStatusListener {
@Resource
private IOrdersCreateService ordersCreateService;
/**
* 更新支付结果
* 支付成功
*
* @param msg 消息
*/
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = MqConstants.Queues.ORDERS_TRADE_UPDATE_STATUS),
exchange = @Exchange(name = MqConstants.Exchanges.TRADE, type = ExchangeTypes.TOPIC),
key = MqConstants.RoutingKeys.TRADE_UPDATE_STATUS
))
public void listenTradeUpdatePayStatusMsg(String msg) {
log.info("接收到支付结果状态的消息 ({})-> {}", MqConstants.Queues.ORDERS_TRADE_UPDATE_STATUS, msg);
//将msg转为java对象
List<TradeStatusMsg> tradeStatusMsgList= JSON.parseArray(msg, TradeStatusMsg.class);
// 只处理家政服务的订单且是支付成功的
List<TradeStatusMsg> msgList = tradeStatusMsgList.stream().filter(v -> v.getStatusCode().equals(TradingStateEnum.YJS.getCode()) && "jzo2o.orders".equals(v.getProductAppId())).collect(Collectors.toList());
if (CollUtil.isEmpty(msgList)) {
return;
}
//修改订单状态
msgList.forEach(m -> ordersCreateService.paySuccess(m));
}
}六.系统优化
1.策略模式
根据需求:
- 订单的状态不同则取消订单执行的逻辑可能不同
- 如以下两个部分,一个涉及不退款,一个涉及退款
-
取消待支付的订单: 最终的结果是更改订单状态为已取消,因为没有支付所以不涉及退款。
-
取消派单中的订单: 用户和运营人员都可以取消订单,订单状态改为已关闭。 到达服务时间还没有派单成功系统自动取消。 取消订单后自动退款。 删除抢单池记录。
- 操作用户不同其权限也不同
- 普通用户:可取消待支付、派单中、待服务的订单。
- 运营人员:可取消除待支付状态下的所有订单
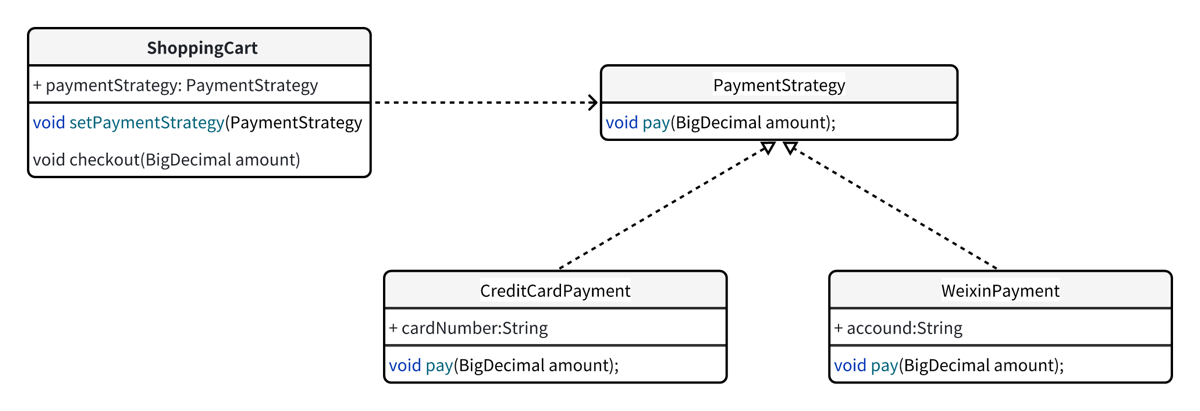
策略模式 = 把“多态”封装成业务组件,让用户在运行时随意换算法。
- 同状态机,属于一种设计模式,针对不同场景执行取消订单的逻辑不同来选择不同的策略(算法)
- 由以下组成
- 抽象策略角色:策略类,通常由一个接口或者抽象类实现(类似下面的订单状态机类^6c1d14)
- 具体策略角色:包装了相关算法和行为(类似下面的)
- 环境角色:持有一个策略类的引用,最中给客户端调用
策略模式与多态
// 1. 抽象角色:员工
interface Employee {
void leaveWork(); // 同样一个动作:下班
}
// 2. 具体角色:不同人不同实现
class Programmer implements Employee {
public void leaveWork() {
System.out.println("程序员:关机、戴耳机、跑路!");
}
}
class ProductManager implements Employee {
public void leaveWork() {
System.out.println("产品经理:微信继续催进度~");
}
}
class Cleaner implements Employee {
public void leaveWork() {
System.out.println("保洁阿姨:开始打扫卫生。");
}
}
// 3. 老板类:只管喊,不管细节
class Boss {
// 注意:参数是“员工”接口,具体传谁运行时才决定
public void announceLeave(Employee e) {
System.out.print("老板喊:大家下班! --> ");
e.leaveWork(); // 多态!实际动作由真实对象决定
}
}
// 4. 客户端:今晚谁加班、谁早走,随便换
public class Office {
public static void main(String[] args) {
Boss boss = new Boss();
boss.announceLeave(new Programmer());
boss.announceLeave(new ProductManager());
boss.announceLeave(new Cleaner());
}
}- 多态的核心三要素(背下来)
- 继承/实现:
Programmer、ProductManager都实现了Employee接口。 - 重写:它们都重写了
leaveWork()方法。 - 向上转型:老板的方法只认
Employee类型,实际传进去的是子类对象。
本项目中的代码
Boss类:OrderCancelStrategyManager
接口:OrderCancelStrategy
员工类:CommonUserNoPayOrderCancelStrategy,CommonUserDispatchingOrderCanscelStategy
实现细节
- 三个类,包括boss类,都使用@Component注解@Component
- 其中,两个员工类需要在Component注解后加名字,如
@Component("1:DISPATCHING"),以便在Manager代码中取出用户的类型+订单的状态,以确定是否存在权限取消订单.如果员工类中有符合这种状态的,则进入此员工类,执行最终的业务代码.- 在Boss类中需要使用@PostConstruct,用来初始化strategyMap
- SpringUtil.getBeansOfType —— “一键抓光” Map<String, OrderCancelStrategy> strategies = SpringUtil.getBeansOfType(OrderCancelStrategy.class); SpringUtil 是 hutool 的工具类(也可用自己写的 ApplicationContextAware)。 getBeansOfType 会返回 Spring 容器里所有实现 OrderCancelStrategy 接口的 bean,key 是 beanName,value 是 bean 实例。 不管有多少个实现类,只要打了 @Component(或 @Service)都能被扫到。
- 最后通过从StrategyMap中取出符合条件的策略,来调用此策略来执行取消订单操作
唯一的前提条件
为了让这一套流程生效,DefaultLogicFactory 类本身必须被注册为 Spring 的 Bean。通常有以下两种方式之一,你可以检查一下:
- 类名上面加了
@Component,@Service或@Configuration等注解。 - 在某个
@Configuration配置类里通过@Bean定义了它。
只要满足这个前提,它就是在启动时装配的。
抽奖系统中的构造器注入 vs @PostConstruct
回到你刚才发的截图(DefaultLogicFactory),我们来对比一下:
-
你截图里的写法(构造器中写逻辑):
-
如果改成
@PostConstruct写法:- 当你使用字段注入,或者你想把初始化逻辑和构造逻辑分离开时,就用
@PostConstruct。
- 当你使用字段注入,或者你想把初始化逻辑和构造逻辑分离开时,就用
@Component
public class DefaultLogicFactory {
// 注入进来,先不着急用
@Autowired
private List<ILogicFilter<?>> logicFilters;
private Map<String, ILogicFilter<?>> logicFilterMap = new ConcurrentHashMap<>();
// 构造器保持干净
public DefaultLogicFactory() {
}
// 等装配好了再干活
@PostConstruct
public void init() {
logicFilters.forEach(logic -> {
// 原来的那堆 forEach put map 逻辑搬到这里
});
}
}public interface OrderCancelStrategy {
/**
* 订单取消
*
* @param orderCancelDTO 订单取消模型
*/
void cancel(OrderCancelDTO orderCancelDTO);
}```
```java
@Component("1:NO_PAY")
public class CommonUserNoPayOrderCancelStrategy implements OrderCancelStrategy {
@Resource
private IOrdersCanceledService ordersCanceledService;
@Resource
private IOrdersCommonService ordersCommonService;
/**
* 订单取消
*
* @param orderCancelDTO 订单取消模型
*/
@Override
public void cancel(OrderCancelDTO orderCancelDTO) {
//保存取消订单记录
...
...- 策略的环境类
@Slf4j
@Component
public class OrderCancelStrategyManager{
@Resource
private IOrdersManagerService ordersManagerService;
//key格式:userType+":"+orderStatusEnum,例:1:NO_PAY
private final Map<String, OrderCancelStrategy> strategyMap = new HashMap<>();
@PostConstruct
public void init() {
Map<String, OrderCancelStrategy> strategies = SpringUtil.getBeansOfType(OrderCancelStrategy.class);
strategyMap.putAll(strategies);
log.debug("订单取消策略类初始化到map完成!");
}
/**
* 获取策略实现
*
* @param userType 用户类型
* @param orderStatus 订单状态
* @return 策略实现类
*/
public OrderCancelStrategy getStrategy(Integer userType, Integer orderStatus) {
String key = userType + ":" + OrderStatusEnum.codeOf(orderStatus).toString();
return strategyMap.get(key);
}
/**
* 订单取消
*
* @param orderCancelDTO 订单取消模型
*/
public void cancel(OrderCancelDTO orderCancelDTO) {
Orders orders = ordersManagerService.queryById(orderCancelDTO.getId());
OrderCancelStrategy strategy = getStrategy(orderCancelDTO.getCurrentUserType(), orders.getOrdersStatus());
if (ObjectUtil.isEmpty(strategy)) {
throw new ForbiddenOperationException("不被许可的操作");
}
orderCancelDTO.setId(orders.getId());
orderCancelDTO.setCurrentUserId(orders.getUserId());
orderCancelDTO.setServeStartTime(orders.getServeStartTime());
orderCancelDTO.setCityCode(orders.getCityCode());
orderCancelDTO.setRealPayAmount(orders.getRealPayAmount());
orderCancelDTO.setTradingOrderNo(orders.getTradingOrderNo());
strategy.cancel(orderCancelDTO);
}
}具体逻辑
修改具体的取消订单方法
@Override
public void cancel(OrderCancelDTO orderCancelDTO) {
//订单id
Long id = orderCancelDTO.getId();
//查询订单
Orders orders = queryById(id);
//如果订单为空则抛出异常
if (ObjectUtils.isNull(orders)) {
throw new CommonException("订单不存在");
}
//填充数据
orderCancelDTO.setTradingOrderNo(orders.getTradingOrderNo());
orderCancelDTO.setRealPayAmount(orders.getRealPayAmount());
if (ObjectUtils.isNotNull(orders.getDiscountAmount()) && orders.getDiscountAmount().compareTo(new BigDecimal(0)) > 0) {
owner.cancelWithCoupon(orderCancelDTO);
}else{
//取消待支付订单
owner.cancelWithoutCoupon(orderCancelDTO);
}
}
@GlobalTransactional
public void cancelWithCoupon(OrderCancelDTO orderCancelDTO) {
//退回优惠券
CouponUseBackReqDTO couponUseBackReqDTO = new CouponUseBackReqDTO();
couponUseBackReqDTO.setUserId(orderCancelDTO.getCurrentUserId());
couponUseBackReqDTO.setOrdersId(orderCancelDTO.getId());
couponApi.useBack(couponUseBackReqDTO);
//使用策略模式取消订单
orderCancelStrategyManager.cancel(orderCancelDTO);
}
@Transactional
public void cancelWithoutCoupon(OrderCancelDTO orderCancelDTO) {
orderCancelStrategyManager.cancel(orderCancelDTO);
}
...2.状态机
- 随着开发的深入,关于状态的判断与更新越来越多,多为硬编码,如果更改状态码,则需改多处代码
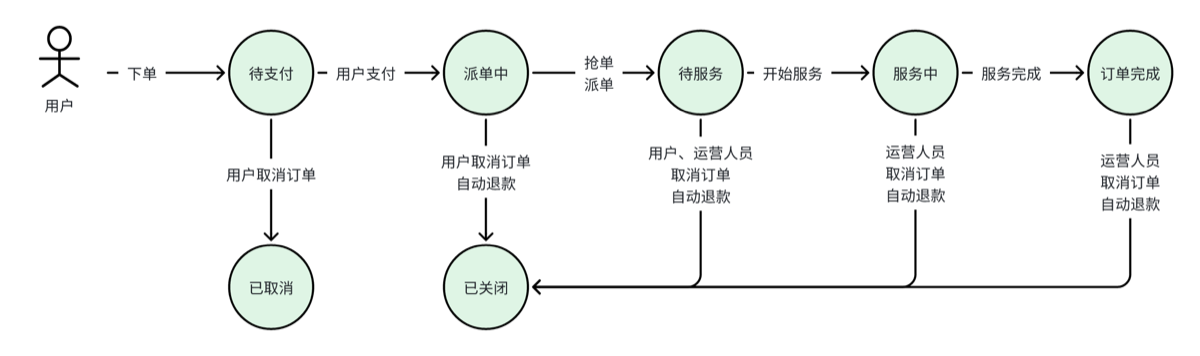
什么是状态机?
虽然“状态机”严格来说是一个数学模型,但在软件设计模式中,状态模式就是它的落地实现。而在企业级开发中,通常会封装得更高级,称之为“状态机组件”。
理解状态机设计模式需要理解四个要素:现态、事件、动作、次态。
(参考地址:https://baike.baidu.com/item/%E7%8A%B6%E6%80%81%E6%9C%BA/6548513?fr=ge_ala )
1、现态:是指当前所处的状态。 2、次态:条件满足后要迁往的新状态。 3、事件:当一个条件被满足,状态会由现态变为新的状态,事件发生会触发一个动作,或者执行一次状态的迁移。 4、动作:发生事件执行的动作,动作执行完毕后,可以迁移到新的状态,也可以仍旧保持原状态。动作不是必需的,当条件满足后,也可以不执行任何动作,直接迁移到新状态。
使用状态机优化代码:
使用状态机之后对代码进行以下优化。 支付成功更改订单状态的代码优化如下:
if(支付状态==支付成功){
//调用状态机执行支付成功事件
orderStateMachine.changeStatus(id,支付成功事件);
}订单取消的代码优化如下:
orderStateMachine.changeStatus(id,订单完成时取消订单事件);我们发现使用状态机的代码并没有对订单状态进行硬编码,只是指定了订单id和事件名称,执行changeStatus方法后自动更改订单的状态。
3.实现订单状态机
https://ai.feishu.cn/wiki/TJy6waEa4irPZ1kQZR4cfZc5nad
- 订单状态用枚举类定义出来
- 将订单状态变更的事件定义出来
- 事件名称
- 关联订单的原始状态和目标状态
- 事件绑定的动作,执行动作后更新订单状态
- 定义订单快照模型类
- 定义订单状态机类(对用户,则为用户订单状态机)(继承下面所说的抽象类)
- 在service方法中更替相关更改状态的代码
- 一个完整的“支付成功”执行流程
假设用户支付了一笔订单(ID: 1001),代码调用了 orderStateMachine.changeStatus("1001", OrderStatusChangeEventEnum.PAYED),后台发生了什么?
-
锁定与检查:
-
状态机先去
state_persister表查 ID 1001 的当前状态。 -
校验:检查当前状态是否为
NO_PAY(我们在枚举里定义的源状态)。如果不是(比如已经是“已取消”),直接抛异常,流程结束。
-
-
路由分发:
- 校验通过后,状态机根据事件名
payed,在 Spring 容器里找到了OrderPayedHandler这个 Bean。
- 校验通过后,状态机根据事件名
-
执行业务逻辑:
-
执行
OrderPayedHandler.handler()方法。 -
这一步更新了
orders业务表,把支付时间、支付流水号写进去。
-
-
状态持久化(这是抽象父类自动做的):
-
更新
state_persister表:将状态由NO_PAY改为DISPATCHING。 -
插入
biz_snapshot表:将当前的OrderSnapshotDTO转成 JSON 存进去,留作历史记录。
-
-
后置处理:
- 调用
postProcessor(如果有定义),比如发个MQ通知下游系统。
- 调用
- 将状态,事件,快照抽离出来
- 编写一个抽象类,提供启动状态机和更新状态的方法
- 启动状态机将在状态机表记录订单的初始方法
- 更新状态,根据事件拿到的原状态,和状态机表中的当前状态做对比,一致之后才可进行更改状态操作
- 支付成功时保存状态机快照和状态机持久化表
进入jzo2o-framework下的jzo2o-statemachine工程,阅读AbstractStateMachine类的源码,通过阅读代码理解状态机组件的运行过程。
阅读启动状态机方法:
首先判断该订单是否启动状态,如果没有启动则向状态机表插入记录,否则抛出异常”已存在状态,不可初始化”.
接下来保存订单快照。
/**
* 状态机初始化,不保存快照
*
* @param bizId 业务id
* @return 初始化状态代码
*/
public String start(String bizId) {
return start(null, bizId, initState, null);
}
/**
* 启动状态机,并设置当前状态和保存业务快照,快照分库分表
*
* @param dbShardId 分库键
* @param bizId 业务id
* @param statusDefine 当前状态
* @param bizSnapshot 快照
* @return 当前状态代码
*/
public String start(Long dbShardId, String bizId, StatusDefine statusDefine, T bizSnapshot) {
//1.初始化状态机状态
String currentState = stateMachinePersister.getCurrentState(name, bizId);
if (ObjectUtil.isEmpty(currentState)) {
stateMachinePersister.init(name, bizId, statusDefine);
} else {
throw new IllegalStateException("已存在状态,不可初始化");
}
//2.保存业务快照
if (bizSnapshot == null) {
bizSnapshot = ReflectUtil.newInstance(getSnapshotClass());
}
//设置快照id
bizSnapshot.setSnapshotId(bizId);
//设置快照状态
bizSnapshot.setSnapshotStatus(statusDefine.getStatus());
//快照转json
String bizSnapshotString = JSONUtil.toJsonStr(bizSnapshot);
if (ObjectUtil.isNotEmpty(bizSnapshot)) {
bizSnapshotService.save(dbShardId, name, bizId, statusDefine, bizSnapshotString);
}
//执行后处理方法
postProcessor(bizSnapshot);
return statusDefine.getCode();
}阅读状态变更方法:
状态变更前会判断订单的当前状态是否和事件定义的源状态一致,如果不一致则说明当前订单的状态不能通过该事件去更新状态,此时将终止状态变更,否则将通过状态变更处理器去更新订单的状态。
/**
* 变更状态并保存快照,快照不进行分库
*
* @param bizId 业务id
* @param statusChangeEventEnum 状态变换事件
*/
public void changeStatus(String bizId, StatusChangeEvent statusChangeEventEnum) {
changeStatus(null, bizId, statusChangeEventEnum, null);
}
/**
* 变更状态并保存快照,快照分库分表
*
* @param dbShardId 分库键
* @param bizId 业务id
* @param statusChangeEventEnum 状态变换事件
* @param bizSnapshot 业务数据快照(json格式)
*/
public void changeStatus(Long dbShardId, String bizId, StatusChangeEvent statusChangeEventEnum, T bizSnapshot) {
//1.查询当前状态
String statusCode = getCurrentState(bizId);
//2.校验起止状态是否与事件匹配
if (ObjectUtil.isNotEmpty(statusChangeEventEnum.getSourceStatus()) && ObjectUtil.notEqual(statusChangeEventEnum.getSourceStatus().getCode(), statusCode)) {
throw new CommonException(HTTP_INTERNAL_ERROR, "状态机起止状态与事件不匹配");
}
//3.获取状态处理程序bean
//事件代码
String eventCode = statusChangeEventEnum.getCode();
StatusChangeHandler bean = null;
try {
bean = SpringUtil.getBean(name + "_" + eventCode, StatusChangeHandler.class);
} catch (Exception e) {
log.info("不存在‘{}’StatusChangeHandler", name + "_" + eventCode);
}
if (bizSnapshot == null) {
bizSnapshot = ReflectUtil.newInstance(getSnapshotClass());
}
//设置快照id
bizSnapshot.setSnapshotId(bizId);
//设置目标状态
bizSnapshot.setSnapshotStatus(statusChangeEventEnum.getTargetStatus().getStatus());
if (ObjectUtil.isNotNull(bean)) {
//4.执行状态变更
bean.handler(bizId, statusChangeEventEnum, bizSnapshot);
}
//5.状态持久化
stateMachinePersister.persist(name, bizId, statusChangeEventEnum.getTargetStatus());
//6、存储快照
if (ObjectUtil.isNotEmpty(bizSnapshot)) {
//构建新的快照信息
bizSnapshot = buildNewSnapshot(bizId, bizSnapshot, statusChangeEventEnum.getSourceStatus());
String newBizSnapShotString = JSONUtil.toJsonStr(bizSnapshot);
bizSnapshotService.save(dbShardId, name, bizId, statusChangeEventEnum.getTargetStatus(), newBizSnapShotString);
}
//7.清理快照缓存
String key = "JZ_STATE_MACHINE:" + name + ":" + bizId;
redisTemplate.delete(key);
//执行后处理方法
postProcessor(bizSnapshot);
}1. 启动状态机 (start):从 0 到 1
这个方法通常在创建订单时调用。它的核心任务是“注册户口”,把这个订单纳入状态机的管理。
核心步骤拆解:
-
防重校验(幂等性):
-
代码:
stateMachinePersister.getCurrentState(...) -
逻辑:先去数据库(
state_persister表)查一下这个 ID 是不是已经有状态了。 -
目的:防止重复启动。如果订单已经存在状态,抛出“已存在状态”异常。
-
-
初始化状态:
-
代码:
stateMachinePersister.init(...) -
逻辑:向
state_persister表插入一条记录,记录biz_id(订单号)和init_state(待支付)。
-
-
保存快照:
-
代码:
bizSnapshotService.save(...) -
逻辑:把订单创建时的详细信息(Snapshot)转成 JSON,存入
biz_snapshot历史表。这相当于记录了订单的“出生证明”。
-
-
后置处理:
- 调用
postProcessor,留给子类扩展用。
- 调用
2. 状态变更 (changeStatus):核心流转引擎
这个方法是状态机的心脏,处理所有的状态跃迁(如:支付成功、取消订单)。
核心步骤深度解析:
第一步:严查“通行证” (Guard Clause)
-
代码:
Java
String statusCode = getCurrentState(bizId); if (ObjectUtil.notEqual(statusChangeEventEnum.getSourceStatus().getCode(), statusCode)) { throw ... "状态机起止状态与事件不匹配"; } -
逻辑:这是最关键的安全机制。
-
假设当前数据库里状态是 “已取消”。
-
传入的事件是 “支付成功”(定义源状态必须是 “待支付”)。
-
判定:“已取消” != “待支付”,直接报错。
-
-
作用:防止非法的状态跳转(防止由于并发或逻辑错误导致的业务数据混乱)。
第二步:动态寻找“办事员” (Route & Strategy)
-
代码:
Java
String eventCode = statusChangeEventEnum.getCode(); bean = SpringUtil.getBean(name + "_" + eventCode, StatusChangeHandler.class); -
逻辑:
-
拼接 Bean 名称:
状态机名_事件名(例如order_payed)。 -
Spring 容器查找:利用 Spring 上下文去寻找对应的 Bean。
-
-
设计精髓:完全解耦。状态机引擎不需要知道具体的业务逻辑写在哪里,它只管按名字找人干活。你只需要写好
OrderPayedHandler并注册进 Spring 即可。
第三步:执行业务逻辑 (Action)
-
代码:
bean.handler(...) -
逻辑:调用具体的 Handler(例如更新订单表
orders的状态、扣减库存等)。 -
注意:这里是先执行业务逻辑,后更新状态机状态。
第四步:更新状态机与记录历史 (Persist)
-
代码:
-
stateMachinePersister.persist(...):更新state_persister表中的状态到目标状态。 -
bizSnapshotService.save(...):将变更后的数据拍一张“快照”,存入biz_snapshot表。
-
-
作用:确保状态机的状态和业务表的状态最终一致,并留下审计痕迹。
第五步:清理缓存 (Cache Eviction)
-
代码:
redisTemplate.delete(...) -
逻辑:删除 Redis 中该订单的状态缓存,确保下次查询时能读到最新的数据库状态。
3. 总结:这个组件牛在哪里?
-
标准化了“后悔药”:强制在每次变状态时记录
Snapshot,无论业务怎么变,历史数据永远可追溯。 -
极强的扩展性:使用了 策略模式 + Spring Bean 命名约定。新增业务状态时,不需要修改
AbstractStateMachine的一行代码,只需要新增一个 Handler 类即可(符合开闭原则)。 -
安全性:将状态流转的判断逻辑(Source Status Check)收敛在组件内部,避免了开发者在业务代码里到处写
if-else判断状态是否合法。
基于设计模式构建通用状态机组件,重构订单生命周期管理:
-
问题解决:针对订单状态流转逻辑复杂、硬编码严重的问题,设计并实现了一套基于 Spring 容器 + 策略模式 + 模板方法模式的通用状态机组件。
-
架构设计:采用事件驱动模型,将状态流转规则(枚举)与业务逻辑(Handler)完全解耦。通过
AbstractStateMachine定义标准流转骨架,实现了状态校验、业务执行、状态持久化的一体化处理。 -
技术深度:利用 Spring ApplicationContext 实现策略类的动态查找(Bean Name 路由);利用 Java 泛型 实现组件的通用性,不仅支持订单,也支持服务单等其他业务。
-
数据价值:设计了全链路状态快照(Snapshot)机制,在状态变更原子操作中自动记录业务数据快照,实现了订单全生命周期的可追溯、可审计。
“为了解决这个问题,我没有选择简单的修补,而是设计了一个通用的状态机组件。 我主要运用了三个设计模式:
-
首先是模板方法模式,我写了一个抽象类
AbstractStateMachine,把‘状态校验’、‘寻找处理器’、‘持久化’这些通用逻辑锁死在父类里,保证流程不出错。 -
其次是策略模式,我定义了 Handler 接口,把‘支付成功’、‘取消’这些具体的业务逻辑拆分成一个个独立的 Bean。
-
利用 Spring 的特性,我通过 Bean 的命名规则(如
order_payed)动态去容器里捞对应的处理器,实现了完全解耦。只要加新状态,写个新类就行,不用动老代码。”
“这个组件还有两个我很满意的设计:
严苛的守门员机制:在执行业务前,组件会自动校验‘当前状态’是否允许流转,比如‘已取消’绝对不能响应‘支付’事件,从根源上杜绝了数据脏读写。
数据时光机:我引入了**快照(Snapshot)**机制。每次状态变化,组件会自动把当时的订单详情序列化成 JSON 存进历史表。这样如果客诉说‘我当时明明有优惠券’,我们可以直接调出那一刻的快照进行还原,非常方便排查问题。”
4.订单数据库优化
分库分表
1️⃣目的
为什么要进行分库分表?
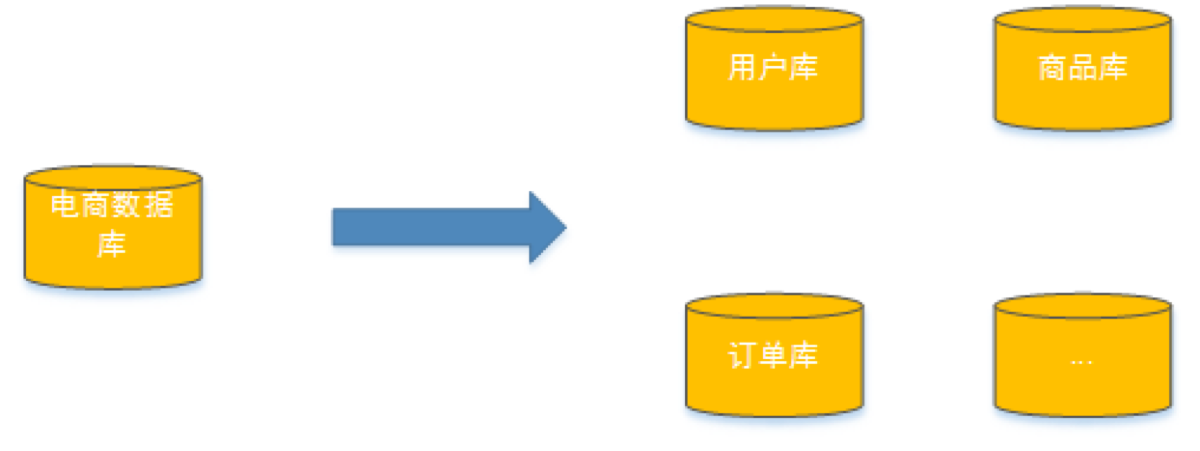
- 我们知道为了提高表的查询性能会增加索引,MySQL在使用索引时会将索引加入内存,如果数据量非常大内存肯定装不下,此时就会从磁盘去查询索引就会产生很多的磁盘IO,从而影响性能,这些和表的设计及服务器的硬件配置都有关
我们可以把数据分散在不同的数据库中,使得单一数据库的数据量变小来缓解单一数据库的性能问题,从而达到提升数据库性能的目的,如下图:将电商数据库拆分为若干独立的数据库,并且对于大表也拆分为若干小表,通过这种数据库 拆分的方法来解决数据库的性能问题
精简
- 垂直
- 垂直分表是将一个表按照字段分成多表,每个表存储其中一部分字段,比如按冷热字段进行拆分。充分发挥热门数据的操作效率,商品信息的操作的高效率不会被商品描述的低效率所拖累。
- 垂直分库是指按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上,它的核心理念 是专库专用,微服务架构下通常会对数据库进行垂直分为,不同业务数据放在单独的数据库中,比如:客户信息数据库、订单数据库等。
- 水平
- 水平分表解决单张表数据量过大导致的查询性能下降,比如按奇偶订单 id 存入统一数据库的不同表
- 水平分库是把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上,比如:单数订单在db_orders_0数据库,偶数订单在db_orders_1数据库。性能解决,磁盘空间不够
- 表拆开没用,因为所有表还在同一台机器上,资源还是不够用。你需要的是加机器
2️⃣分库分表后产生的问题
1)事务一致性问题
由于分库分表把数据分布在不同库甚至不同服务器,不可避免会带来分布式事务问题。
2)跨节点关联查询
在没有分库前,我们检索商品时可以通过以下SQL对店铺信息进行关联查询:
SELECT p.*,r.[地理区域名称],s.[店铺名称],s.[信誉]
FROM [商品信息] p
LEFT JOIN [地理区域] r ON p.[产地] = r.[地理区域编码]
LEFT JOIN [店铺信息] s ON s.id = p.[所属店铺]
WHERE...ORDER BY...LIMIT...但垂直分库后**[商品信息]和[店铺信息]**不在一个数据库,甚至不在一台服务器,无法进行关联查询。
可将原关联查询分为两次查询,第一次查询的结果集中找出关联数据id,然后根据id发起第二次请求得到关联数据,最后将获得到的数据进行拼装。
3)跨节点分页、排序函数
跨节点多库进行查询时,limit分页、order by排序等问题,就变得比较复杂了。需要先在不同的分片节点中将数据进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序。
4)主键避重
主键值平时使用的自增长将无用武之地,某个分区数据库生成的ID无法保证全局唯一。因此需要单独设计全局主键
3️⃣解决方案
- ShardingSphere(Apache ShardingSphere)
- MyCat
- 手工编码实现
- 云服务提供的解决方案:
4️⃣此项目分库分表方案
使用步骤
- 添加依赖
- 更改为Sharding-sphere的jdbc驱动
- 配置分库分表策略
- 配置数据源(哪几个库?)
- 配置分表策略
- 指定逻辑表
- 指定分表键
- 配置分表策略表达式
- 配置分库策略
- 指定分库键
- 配置分表策略表达式
- Hash方式,将id%2,数据均匀但迁移困难
- range方式,按范围分表,数据不均匀,初期都在一张表上,但无迁移困哪
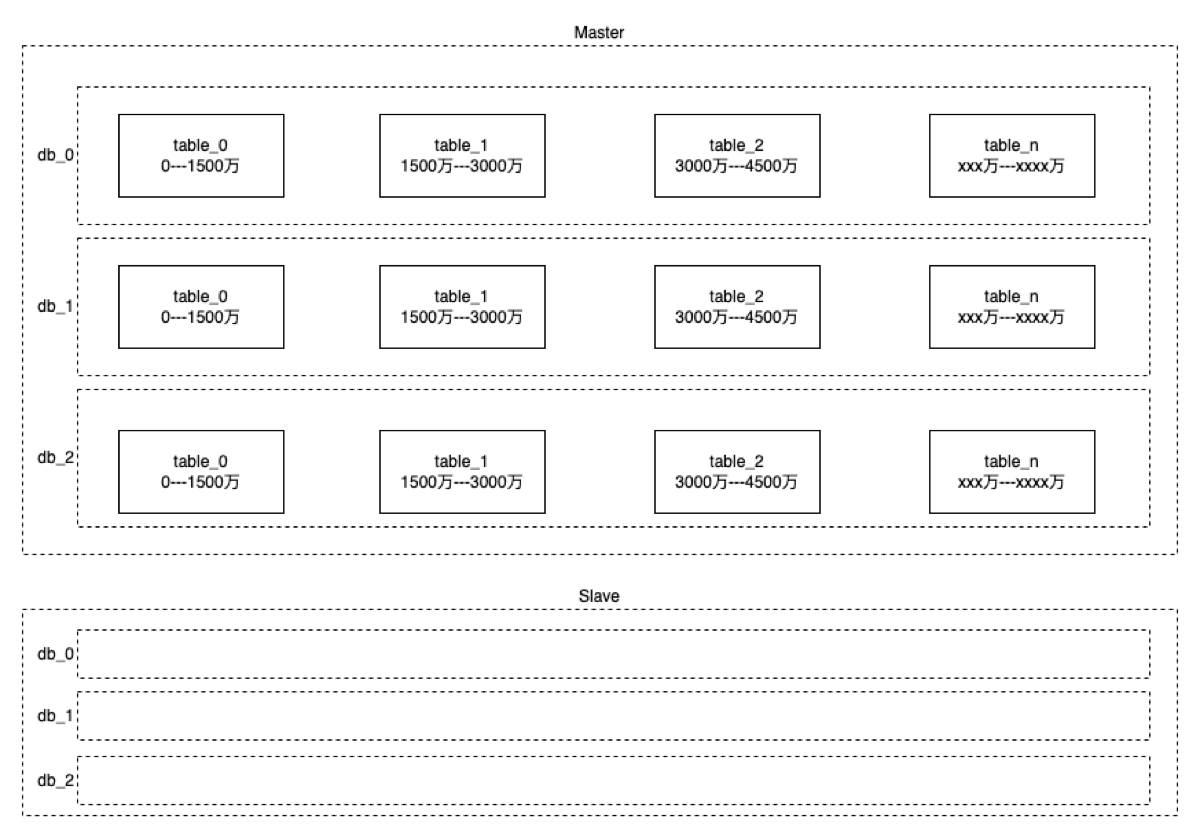
- 分库采用hash,根据userI➗3取余
- 分表采用rang,以1500万为单位分开(理论数值)
5.订单查询优化
订单详情查询
1) 为什么要优化订单查询?
1)订单查询是一个高频接口,并且订单表数据量大。
2)面向C端用户的订单查询接口其访问量非常大。
3)对于运营端的订单查询接口虽然访问量不大但由于订单数据较多也需要进行优化,提高查询性能。
2)订单详情优化
- 从订单快照中去查
- 快照在(参考状态机组件)实现了一个快照查询订单接口
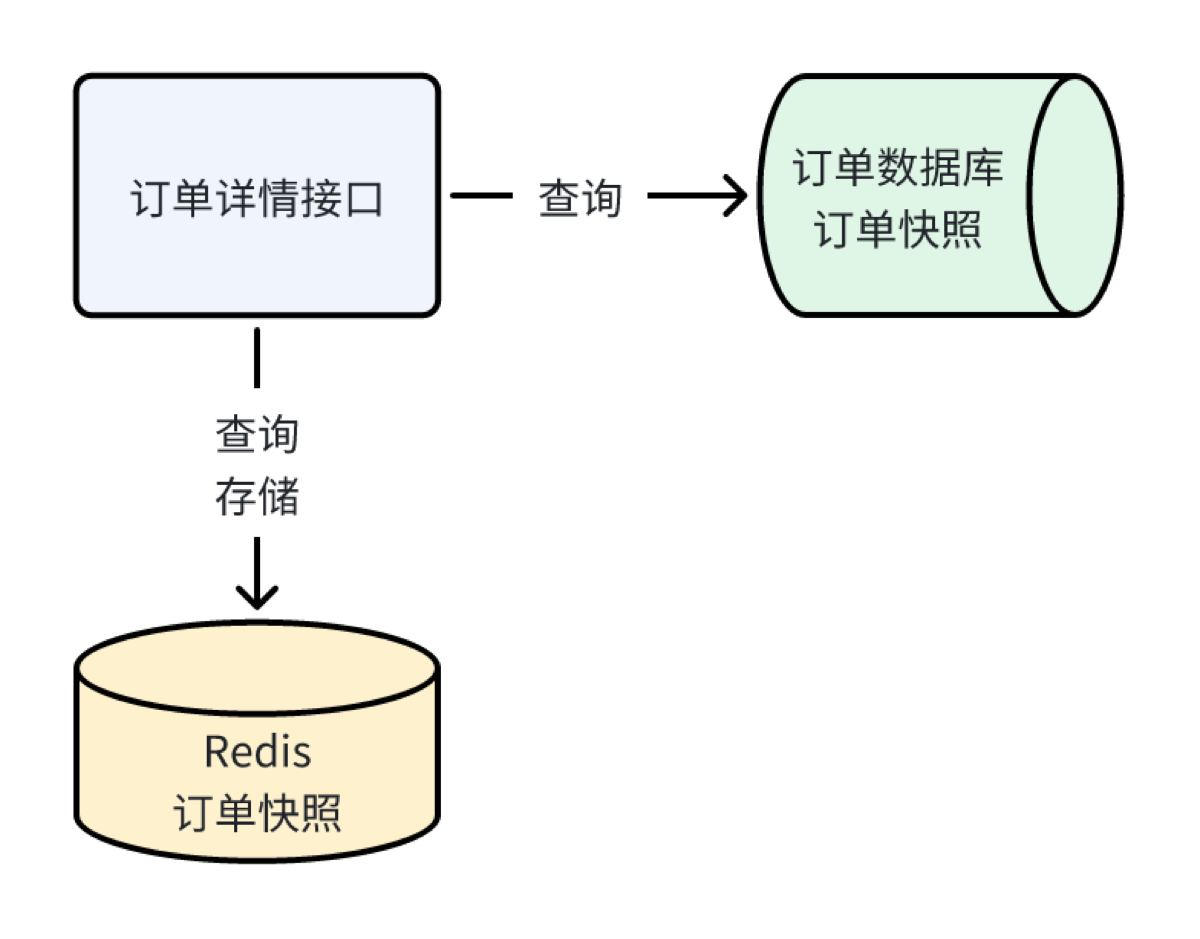
- 查询快照后将快照信息保存到Redis中(如果没有时)(缓存时间 30min)
- 当订单状态修改时,将快照信息从Redis中删除
- 将订单快照放入Redis缓存
3) 用户端(C端)订单列表查询优化
- 特点:表数据有几百万,要实现分页查询
聚集索引:查询条件只有主键的情况会通过聚集索引查询。
非聚集索引:查询条件有多个,此时为了提高查询效率可以创建多个字段的联合索引,根据非聚集索引找到符合条件主键,如果要查询的列只有索引字段则通过非聚集索引直接拿到字段值返回,如果要查询列有一部分在索引之外此时会进行回表查询聚集索引最终拿到数据。 3 索引分类 示例:
user表(id、name、 age、address) 对name、age创建联合索引。 sql1: select id、name、age from user where name=? and age =? 该查询直接从索引中拿到符合条件的数据,不存在回表查询。
sql2: select * from user where name=? and age =? 该查询列是select * ,address没有包含在索引中,where条件通过联合索引找到符合条件的主键,再通过主键回表查询聚集索引,最终拿到数据。
覆盖索引是什么呢? 覆盖索引是一种优化手段,上边的sql1就是实现了覆盖索引。
**覆盖索引(covering index)**指一个查询语句的执行只需要从非聚集索引中就可以得到查询记录,而不需要回表去查询聚集索引,可以称之为实现了索引覆盖。 24.什么是覆盖索引?
根据上边的需求,我们根据查询条件建立联合索引,通过联合索引找到符合条件的订单ID(主键),从索引中找到的符合条件的订单ID无需回表查询聚集索引。
第一个点
- 小程序没有分页查询按钮,使用滚动查询,如下图
- 这种滚动分页(Scroll/Cursor)方式只适用于‘无限加载/瀑布流’的场景(如下一页)。它不支持随机跳转
第二个点
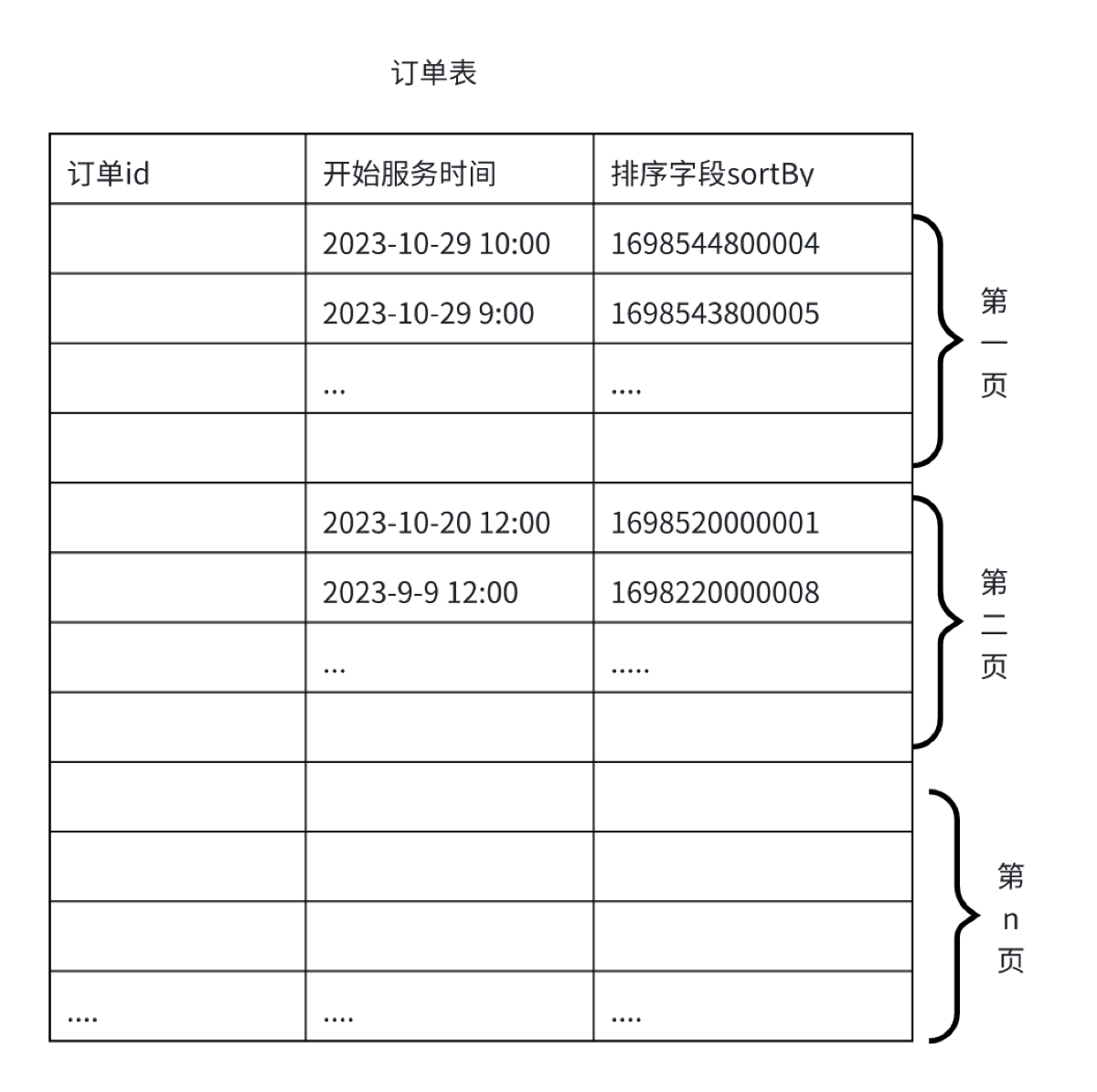
- 向此表添加一个排序字段sortby(唯一且有序,为索引)(服务预约时间+订单号后5位。)
- 将查询条件(如订单状态,sortby,isDisplay等)添加为非聚集索引(普通字段的联合索引)来避免回表(?最左前缀法则?)
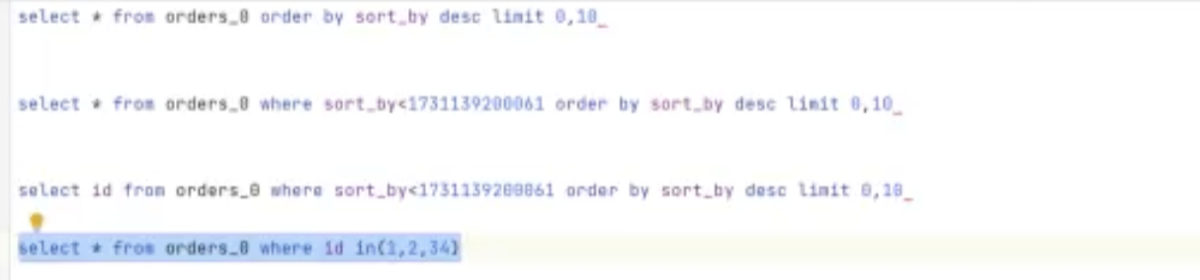
- 通过覆盖索引的方式,只从非聚集索引拿到id主键值
- 指根据多个id主键值查询聚集索引拿订单信息
“针对C端用户订单列表这种高频且数据量大的场景,我主要解决了**深度分页(Deep Pagination)**带来的性能问题。
我采用了**‘游标分页 + 覆盖索引’的组合方案。 具体来说,就是废弃了传统的
LIMIT offset, size,改用一个由‘服务时间+主键后缀’生成的唯一滚动ID(sort_by)作为锚点进行定位。 同时,我建立了联合索引**,利用 MySQL 的覆盖索引特性,先只查询出 ID 列表,避免回表;拿到 ID 后再去批量查询详情或走缓存。这使得查询性能从 O(N) 优化到了 O(1) 级别。”
1. 关于“滚动ID(Cursor)”的设计
“首先,传统分页在翻到第1万页时,数据库要扫描前1万条数据再丢弃,非常慢。 所以我设计了一个全局唯一的滚动ID(sort_by)。 规则是:服务开始时间毫秒级时间戳 + 订单ID后5位。 查询时,我传入上一页最后一条数据的 sort_by,SQL 语句变成 WHERE sort_by < 上次锚点 ORDER BY sort_by DESC LIMIT 10。这样无论滑到第几页,数据库都只需要扫描10条数据。”
2. 关于“联合索引”与“最左前缀”
“配合滚动ID,我建立了联合索引,例如 (user_id, display, sort_by)。 这里有两点考虑: 第一,符合最左前缀法则,快速过滤出该用户的有效订单。 第二,利用索引天然有序的特性。因为索引里 sort_by 已经是排好序的,所以查询时避免了 MySQL 进行 Using filesort(文件排序),大大降低了 CPU 消耗。”
28.怎么对订单查询优化的?
3. 关于“覆盖索引”与“两阶段查询”
“这是性能提升最大的点。我发现如果直接 SELECT *,虽然走了索引,但因为索引叶子节点没有所有字段,MySQL 还是会回表(Back to table)去查聚簇索引,IO 开销很大。 所以我把查询拆成了两步: 第一步: SELECT id FROM table ...。因为 ID 就在联合索引树上,触发了覆盖索引(Using index),完全不需要回表,速度极快。 第二步: 拿到这 10 个 ID 后,再去批量查询订单详情(或者优先查 Redis 缓存)。 虽然多了一次请求,但避免了大量无效数据的 IO 读取,整体性能提升非常明显。”
Q: 你是怎么验证优化效果的?
A: “我通过
EXPLAIN命令查看了执行计划。 优化前,Extra 显示Using filesort和普通的Using where。 优化后,Extra 显示Using index,证明触发了覆盖索引,且没有文件排序。压测下来,深分页的响应时间从几秒降低到了毫秒级。”
6.数据冷热分离
- 历史数据库选型
- 固态硬盘
- 云服务,如OSS
- 分布式数据库(贵)
- 有统计分析需求的话,可以使用mysql的分库分表,按年分表(只有百万条)
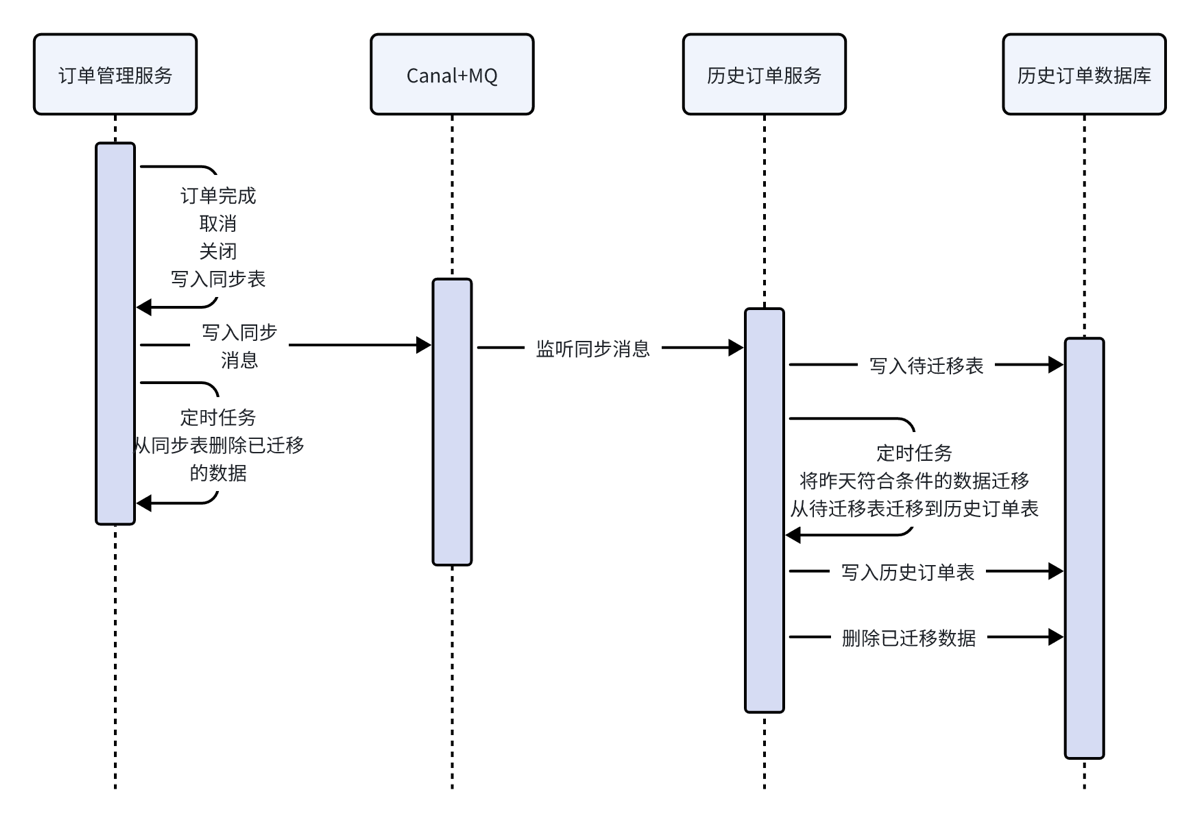
- 冷数据存储在mysql中,按年对历史订单表进行分表
- 迁移方式
- 当订单完成,取消,关闭时,将数据由订单数据库的同步表中迁移到历史订单数据库的同步表中
- 在历史订单服务中启动一个定时任务,每天凌晨从历史订单数据库的同步表中找截止昨天订单完成时间大于等于15天的数据从同步表迁移到历史订单表
7.统计分析
未完成
七.秒杀系统
常用方案
-
缓存Redis
-
队列MQ
- 当用户成功秒杀后,将抢购信息发送到队列,然后由消费者多线程异步处理订单,减轻系统的实时压力,使用Redis、RabbitMQ等技术都可以实现队列。
-
限流
-
CDN加载静态资源
-
防止超卖
-
数据库优化
- 索引,sql 语句,数据库连接池
-
负载均衡Nginx
-
安全性处理 确保系统的安全性,防止SQL注入、XSS攻击(跨站脚本攻击)等,同时在后端实现防刷、验证码等安全措施,保护系统免受恶意攻击。
1.查券服务
活动查询
-
由于时间集中,使用预热程序存入redis(进行中,未开始)
-
先从缓存中查询上一步的预热活动信息
-
根据传入参数进行过滤
-
解决活动状态实时生效:用java程序去判断活动的开始时间,如果一开始将活动的状态一开始,返回给前端
-
这里指判断时间问题,库存问题在后面解决
redis数据结构
-
数据流
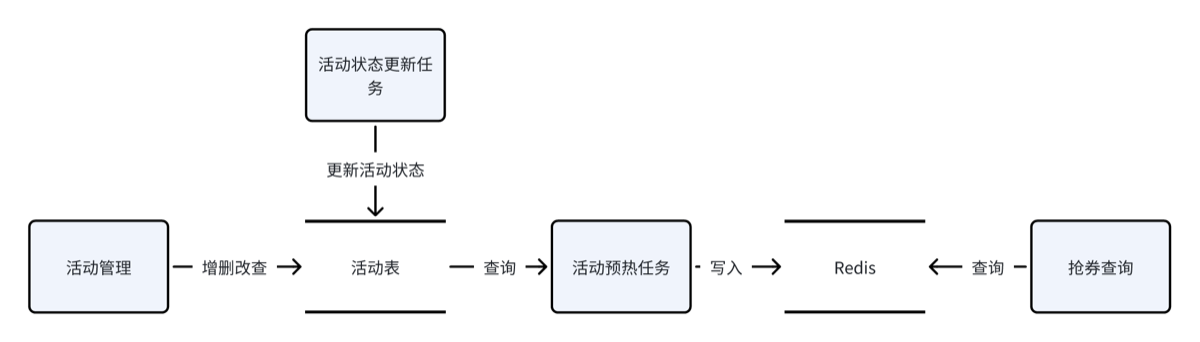
-
将活动表的数据(进行中,已开始)定时更新到缓存中
-
redis结构使用String,
-
key:固定的字符串.
-
value:符合优惠券活动列表的json数据
-
永不过期
-
通过预热程序保证缓存一致性(定时任务)
如何保证状态实时更新
如果通过 xxl-job 每分钟更新状态,也会产生一分钟的状态延迟
如何实现在页面到达活动开始时间立即变更活动状态?
- 在前端进行控制,根据活动开始时间进行倒计时,达到开始时间将活动移到进行中界面。
- 请求后端查询数据,根据当前时间和活动开始、活动结束时间判断活动的状态。判断当前时间是否在活动区间内
自动任务预热的是即将开始和进行中的活动
活动查询接口
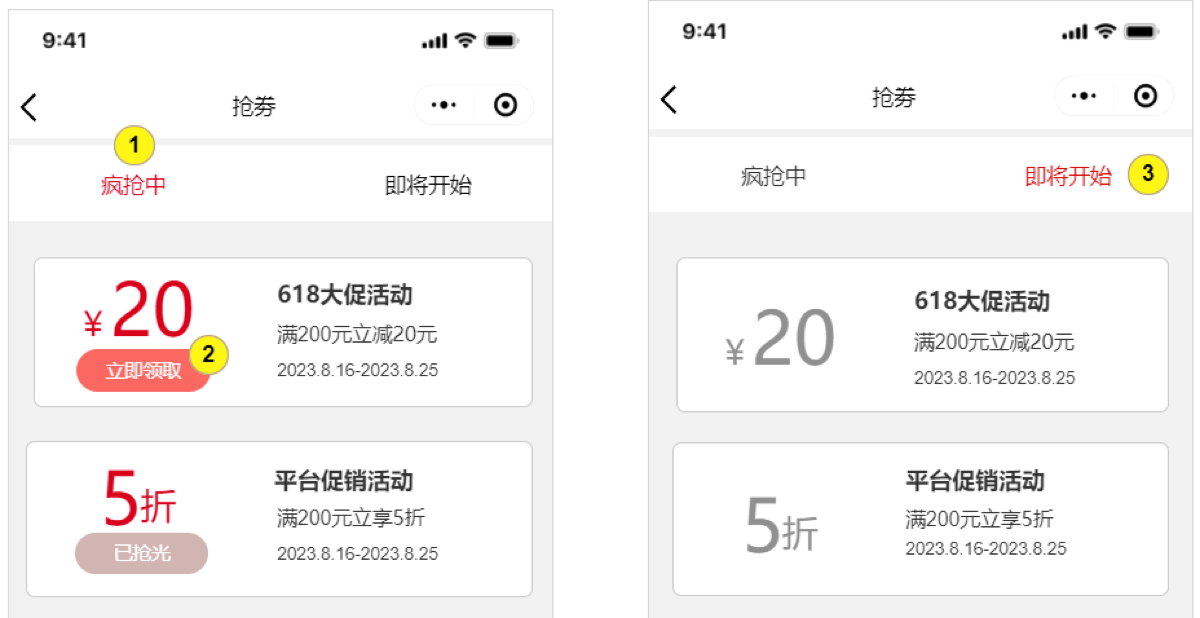 界面有两个tab,疯抢中和即将开始,前端传入后端一个参数标记是查询进行中的活动还是即将开始的活动。
后端需要给前端返回具体的优惠券数据:
界面有两个tab,疯抢中和即将开始,前端传入后端一个参数标记是查询进行中的活动还是即将开始的活动。
后端需要给前端返回具体的优惠券数据:
- 这些信息在预热的活动信息缓存中都存在,但是有两个字段不够实时:活动状态,优惠券剩余数量。
- 活动状态已在上面的小节实现
- 其实就是 redis 和前端页面有延迟,不能相信其中的状态字段。所以在实际抢券时再次校验一下redis 中的时间范围(只能在用户 8:00 后进入页面或者前端设置 8:00 自动刷新页面生效)
2.抢券服务
1.服务需求
- 提高并发吞吐量
- 解决超卖问题(在高并发场景下对库存这个共享资源进行操作存在线程不安全所导致。)
2.锁的选择
悲观锁synchronized和ReentrantLock 乐观锁CAS即Compare And Swap 数据库行锁(乐观,悲观) 见八股:2.锁
- 这里考虑到是微服务架构,且有高并发需求,而 syn 和 Reen 都是对于JVM 本身的线程争抢一个锁,
- 这里考虑redis 分布式锁 或利用 redis 的操作原子性 来实现
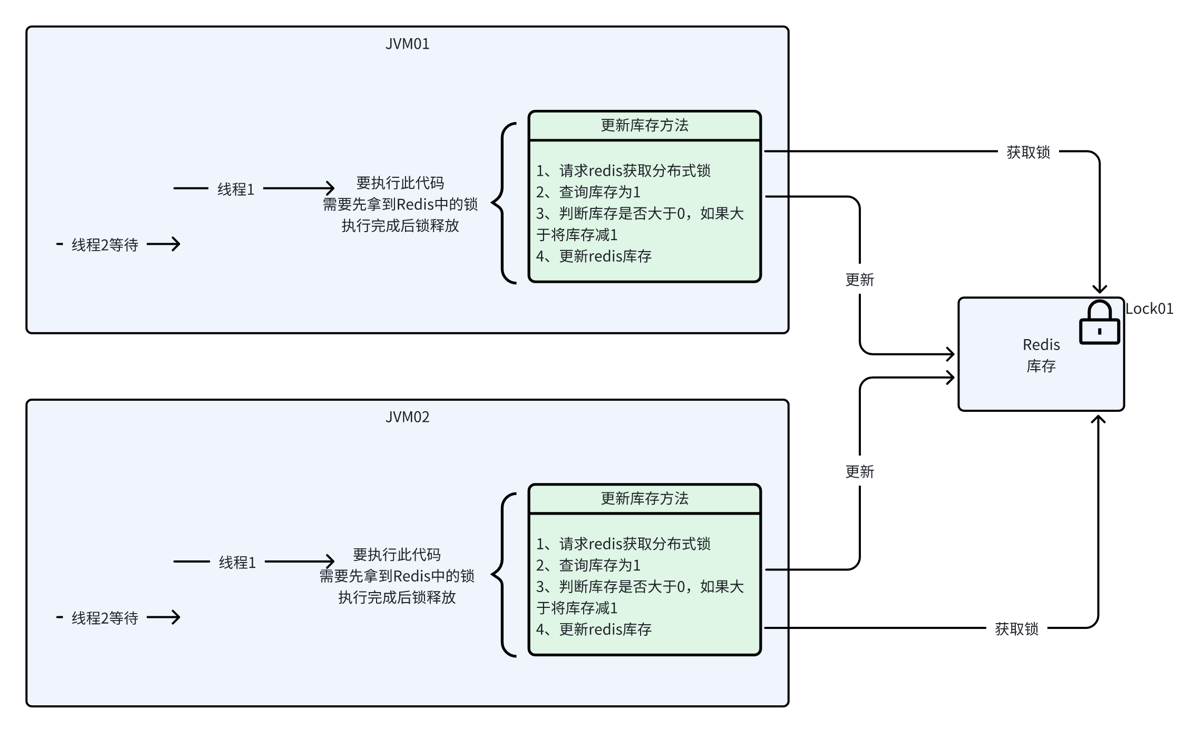
方案一:redis分布式锁
 方案一:Redis 分布式锁(第五节的内容)
方案一:Redis 分布式锁(第五节的内容)
比喻: 只有一个 “写字间”,必须拿到钥匙才能进去。
-
抢锁: 很多人(JVM线程)都在抢一把钥匙(Redis
SETNX)。 -
进屋: 抢到钥匙的人(线程A),打开门进屋。
-
干活: 线程A 看看账本(
GET库存),拿出计算器算一下(JVM 内存减库存),把新数字写回账本(SET库存)。 -
还锁: 线程A 出来,把钥匙放回去(
DEL锁)。
-
特点: 真正的计算逻辑是在 “人”(JVM内存内) 的脑子里算的。Redis 只是负责管钥匙和存账本。
-
缺点: 进进出出很慢,而且如果在屋里算太久(GC卡顿),钥匙超时自动归还了,别人闯进来就会出事。
方案二:Redis原子操作方案
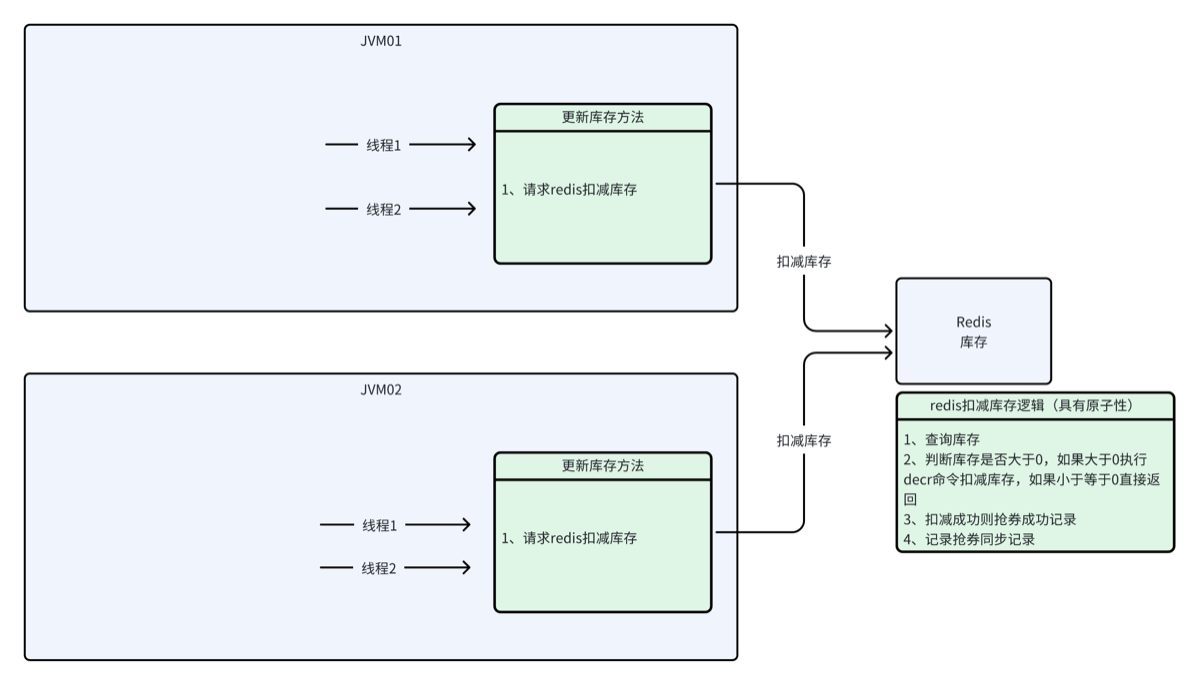
方案二:Redis 原子操作/Lua脚本(第六节及后续内容)
比喻: 这是一个 “全自动存取款机”。
-
指令: 很多人(JVM线程)不需要抢钥匙,大家只是排队把一张写着“取100块”的纸条塞进机器(发送
DECR命令或 Lua 脚本)。 -
执行: 机器(Redis)内部自己处理。它读取余额、判断够不够、减钱、记录流水。在这个过程中,机器是全封闭的,谁也插不进队。
-
结果: 机器吐出一张条子告诉你“成功”还是“余额不足”。
-
特点: 计算逻辑是在 “机器”(Redis) 肚子里完成的。
-
优点: 极快,没有网络来回传输的开销,没有“锁”的概念(不需要
lock/unlock)。
3.方案二的具体细节问答
核心回答(30秒版本:直接亮出观点)
“针对这种需要同时执行多个 Redis 命令,且涉及业务逻辑判断(如扣库存前要先查库存、判断用户是否重复抢购)的场景,我选择了 Redis + Lua 脚本 的方案。
虽然
MULTI/EXEC也能保证原子性,但它只能批量执行命令,无法在命令之间插入逻辑判断(比如‘如果库存不够就直接中断返回’)。而 Lua 脚本不仅能保证原子性,还能在 Redis 服务端直接处理复杂的业务逻辑,减少了网络交互次数,性能和灵活性都更好。”
详细回答(展开讲解技术细节与取舍)
如果面试官追问“为什么不用 MULTI?”或者“Lua 脚本有什么优势?”,你可以按以下逻辑展开:
- MULTI 事务方案的局限性
“最开始我也考虑过 Redis 的 MULTI/EXEC 事务。
-
机制:它先把命令放入队列,最后一次性执行。
-
痛点:它最大的问题是没有‘逻辑判断’能力。比如我要‘先查库存,如果大于0再扣减’。在
MULTI块里,所有命令是一起发过去的,我没办法根据第一条GET的结果决定是否执行第二条DECR。这在处理复杂业务(如防超卖、防重抢)时非常受限。”
- Redis + Lua 方案的优势
“相比之下,Lua 脚本完美解决了这个问题:
-
原子性保证:Redis 执行 Lua 脚本时,会把它当成一个整体,中间绝对不会插入其他客户端的命令,天然保证了并发安全。
-
支持复杂逻辑:我可以在脚本里写
if-else。例如:先GET库存,if stock <= 0直接return 0;否则再DECR并写入抢购记录。这把业务逻辑下沉到了 Redis 端。 -
性能更高:原本需要 Java 和 Redis 交互多次(查库存→判断→扣库存),现在只需要发送一次脚本,减少了网络 RTT(往返时间)开销。”
- 为什么不用 Pipeline?
“我也对比过 Pipeline,虽然它也快,但 Pipeline 只是批量发送命令,不保证原子性。如果中间某条命令失败了,其他命令还是会执行,这在涉及资金或库存的场景下是不可接受的,所以 Pipeline 这里不适用。”
总结关键词(面试小抄)
-
MULTI/EXEC:原子性,但缺乏逻辑控制(无法根据上一步结果决定下一步)。
-
Pipeline:高性能批量执行,但无原子性。
-
Lua 脚本:原子性 + 逻辑控制 + 高性能(减少网络交互)。
-
选择结论:因为抢券涉及“查库存 → 判断 → 扣减 → 记录”的依赖逻辑,必须用 Lua 脚本。
4.集群下的 redis Lua 脚本
-- 抢券Lua实现
-- key: 抢券同步队列,资源库存,抢券成功列表
-- argv:活动id,用户id
--优惠券是否已经抢过
local couponNum = redis.call("HGET", KEYS[3], ARGV[2])
-- hget 获取不到数据返回false而不是nil
if couponNum ~= false and tonumber(couponNum) >= 1
then
return "-1";
end
-- --库存是否充足校验
local stockNum = redis.call("HGET",KEYS[2], ARGV[1])
if stockNum == false or tonumber(stockNum) < 1
then
return "-2";
end
--抢券列表
local listNum = redis.call("HSET",KEYS[3], ARGV[2], 1)
if listNum == false or tonumber(listNum) < 1
then
return "-3";
end
--减库存
stockNum = redis.call("HINCRBY",KEYS[2], ARGV[1], -1)
if tonumber(stockNum) < 0
then
return "-4"
end
-- 抢单结果写入同步队列
local result = redis.call("HSETNX", KEYS[1], ARGV[2],ARGV[1])
if result > 0
then
return ARGV[1] ..""
end
return "-5"“在脚本编写中,我利用 Lua 的逻辑判断能力,前置了拦截逻辑。比如先检查 HGET 用户是否抢过,再检查 HGET 库存是否足够。如果不满足条件直接返回错误码,避免了无效的库存扣减操作(相比 MULTI/EXEC 事务无法做条件判断,这是巨大的优势)。”
“这里我遇到了一个棘手的问题:生产环境是 Redis Cluster 集群。 最开始执行脚本时报错 CROSSSLOT,因为脚本里涉及‘库存Key’、‘用户记录Key’等多个 Key,它们计算出的哈希槽(Slot)不一样,分布在不同节点上,导致无法原子执行。
解决方案是: 我利用了 Redis 的 Hash Tag(哈希标签) 机制。我在设计 Key 的时候,强制加上了 {活动ID} 作为后缀(比如 stock:{1001} 和 record:{1001})。这样 Redis 在计算哈希时,只会用 {} 里的活动 ID 计算,确保了同一个活动的所有相关 Key 必定落在同一个哈希槽(Slot)里,完美解决了集群下的 Lua 执行问题。”
5.抢券整体方案
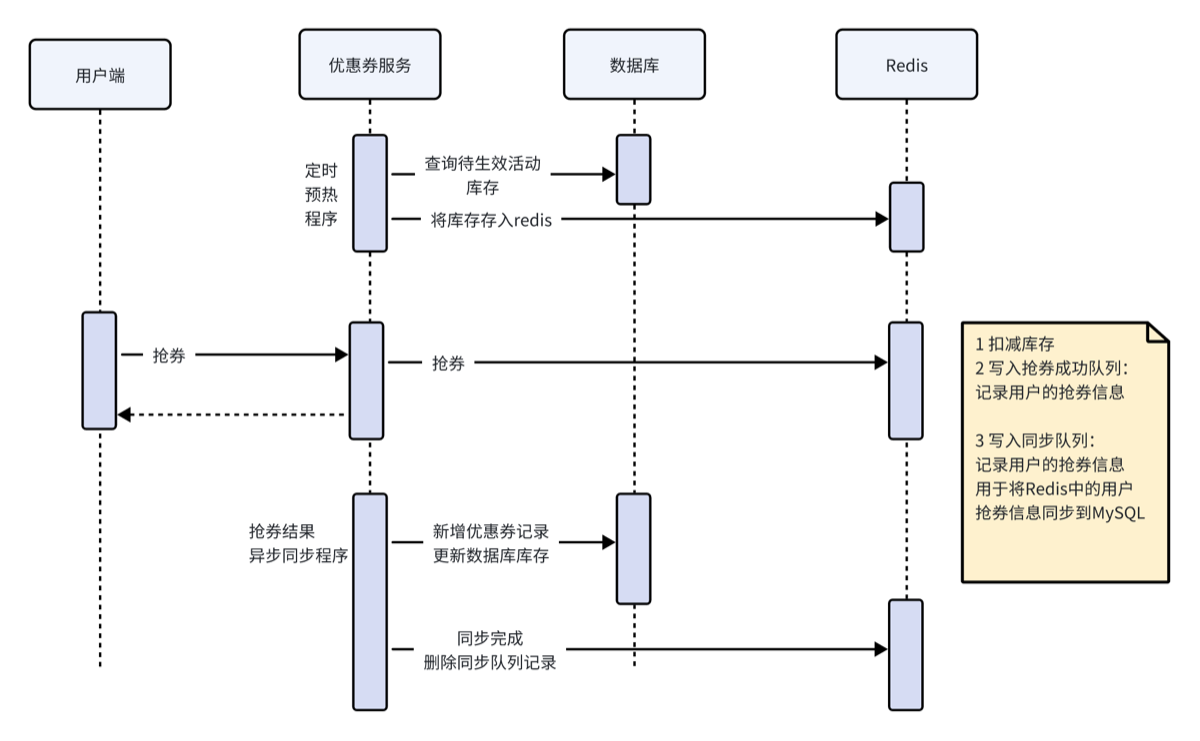
-
全链路异步化:抢券动作只在 Redis 层完成,完全不操作数据库,将 TPS(吞吐量)提升到 Redis 级别(万级甚至十万级)。
-
读写分离:
-
读:通过预热将活动信息和库存加载到 Redis,前端查询走缓存。(第一第二 redis 表)
-
写:抢券时的写操作全部在 Redis,通过异步任务(MQ/定时任务)慢慢同步到 MySQL。
-
-
分片减压:Redis Key 使用
{活动id%10}进行哈希分片,避免单点热点(Hot Key)打挂某一个 Redis 节点。 -
写入成功队列:标记该用户已抢到(用于步骤1的校验)。(用于 lua 脚本内部查看是否这个队列中是否有这个用户,如果有返回-1 结束,java 根据错误码提示限购一张。如果没有这个用户,则继续下面的判断,如库存,扣减,同步队列)(第三 redis 表)
-
写入同步队列:记录
{用户ID, 活动ID},用于后续异步写入数据库。(第四 redis 表)
6.库存同步
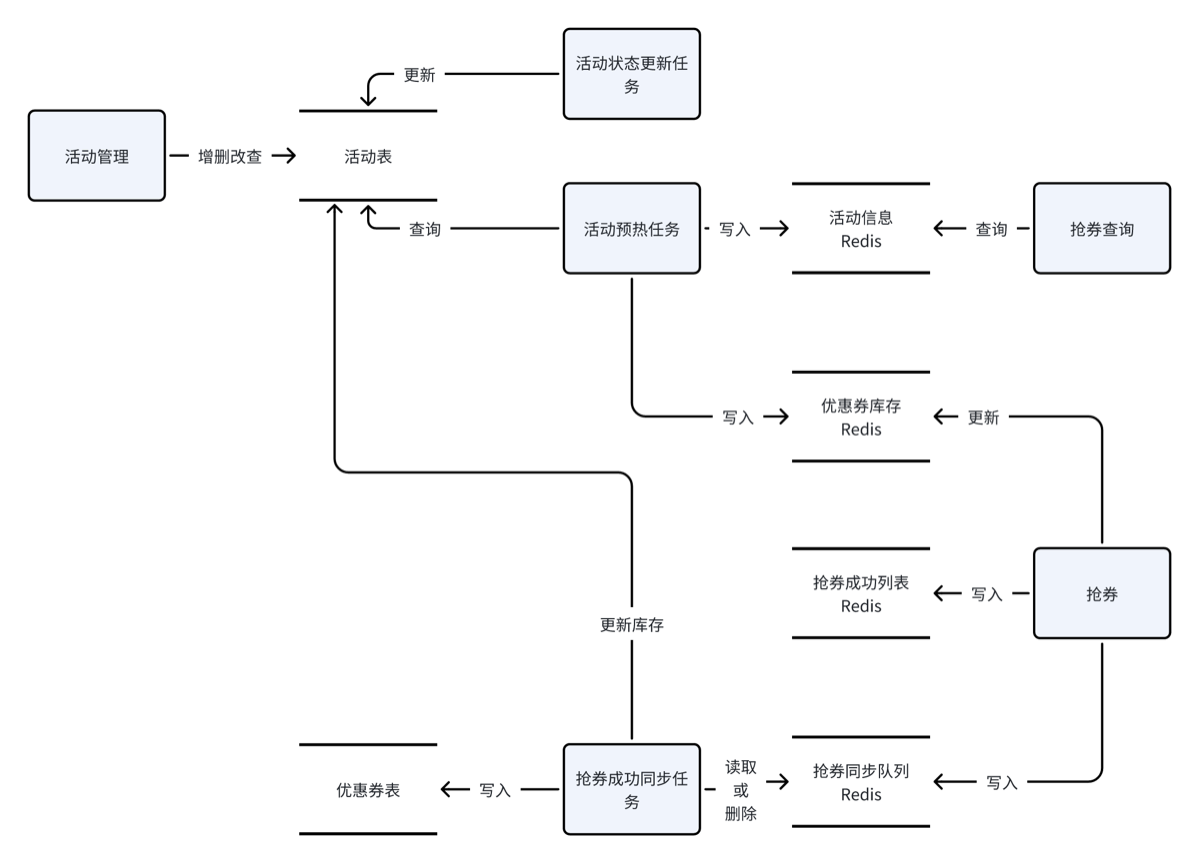
- 用户抢券要在Redis扣减库存,所以需要提前将优惠券活动的库存同步到Redis。 可以通过定时预热程序中将优惠券活动的库存同步到Redis,同步规则如下:
-
对于待生效的活动更新库存。
-
对于已生效的活动如果库存已经同步则不再同步,只更新没有同步库存的活动。
-
待生效(未开始):随便改,用
put保证数据是最新的(运营可能改了库存)。 -
已生效(进行中):Redis 里的数据才是权威的(因为有人在抢),数据库里的数据是滞后的。所以绝对不能用数据库的旧值去覆盖 Redis 的新值,只能做“查漏补缺”(
putIfAbsent)。
- 将 redis 库存同步在 mysql 中
7.抢券结果同步(redis到 mysql)
高性能的异步同步策略(分片多线程 + 游标扫描)
面试官问: “Redis 里的数据怎么同步回 MySQL?量大了会卡吗?”
你的回答:
“为了保证同步的高效性和数据的一致性,我设计了一个基于分片的多线程同步组件:
分片多线程:因为我们在 Redis 里将同步队列分成了 10 个分片(Shard),在同步时,我配合使用了 ThreadPoolExecutor 线程池。每个线程利用分布式锁绑定处理一个分片队列,实现了真正的并行同步,互不阻塞。
非阻塞取数:在从 Redis 取数据时,我没有用
HGETALL这种可能阻塞主线程的命令,而是使用了HSCAN(游标扫描)。每次只拉取 100 条数据进行批量落库,既保证了同步速度,又保护了 Redis 的稳定性。事务一致性:在落库阶段,我开启了本地事务,保证‘插入优惠券表’和‘扣减数据库库存’要么同时成功,要么同时回滚。只有事务提交成功后,才会删除 Redis 里的同步记录,保证了消息的At-least-once(至少一次) 投递。”
| 步骤 | 涉及类/方法 | 作用 |
|---|---|---|
| 调度 | XxlJobHandler.seizeCouponSyncJob | 定时触发同步入口 |
| 多线程 | SeizeCouponHandlerJob.start | 按照队列分片数量创建线程,并发处理 |
| 加锁 | SeizeCouponHandler.run (Redisson) | 保证同一时间只有一个线程处理同一个队列 |
| 取数 | opsForHash().scan | 使用游标分批从 Redis Hash 中读取数据 |
| 落库 | ICouponService.seizeCouponSync | 开启事务:插入优惠券表 + 扣减活动表库存 |
| 确认 | opsForHash().delete | 同步成功后,删除 Redis 中的记录 |
- 这里的线程池看[[云岚到家#自动发放优惠券|自动发放优惠券]]
- 36.讲一下项目中的基于分片的多线程同步组件
/**
* @author Mr.M
* @version 1.0
* @description 抢券结果处理器
* @date 2024/9/23 18:43
*/
@Slf4j
public class SeizeCouponHandler implements Runnable {
//hashkey
private String hashKey;
//分布式锁
private RedissonClient redissonClient;
private RedisTemplate redisTemplate;
private ICouponService couponService;
//构造方法
public SeizeCouponHandler(String hashKey, ICouponService couponService,RedissonClient redissonClient, RedisTemplate redisTemplate) {
this.hashKey = hashKey;
this.couponService = couponService;
this.redissonClient = redissonClient;
this.redisTemplate = redisTemplate;
}
@Override
public void run() {
String lockKey = "LOCK:" + hashKey;
log.info("获取锁:{}", lockKey);
RLock lock = redissonClient.getLock(lockKey);
//尝试获取锁
try {
boolean tryLock = lock.tryLock(1, -1, TimeUnit.SECONDS);
if (!tryLock) {
log.info("获取锁失败:{}", lockKey);
return;
}
//开始发放优惠券
log.info("开始处理抢券结果:{}", hashKey);
Cursor<Map.Entry<String, Object>> cursor = null;
try {
// 通过scan从redis hash数据中批量获取数据,获取完数据需要手动关闭游标
ScanOptions scanOptions = ScanOptions.scanOptions()
.count(100)
.build();
while (true){
// sscan获取数据
cursor = redisTemplate.opsForHash().scan(hashKey, scanOptions);
// 遍历数据转换成SyncMessage列表
List<SyncMessage<Object>> collect = cursor.stream()
.map(entry -> SyncMessage
.builder()
.key(entry.getKey().toString())
.value(entry.getValue())
.build())
.collect(Collectors.toList());
log.info("{}获取{}数据{}条", Thread.currentThread().getId(), hashKey, collect.size());
if(collect.size() <=0){
break;
}
//处理抢券结果
collect.stream().forEach((objectSyncMessage) -> {
try {
//活动id
Long activityId = NumberUtils.parseLong(objectSyncMessage.getValue().toString());
//用户id
Long userId = NumberUtils.parseLong(objectSyncMessage.getKey());
//同步抢券结果
couponService.seizeCouponSync(activityId, userId);
//删除同步记录
this.redisTemplate.opsForHash().delete(hashKey, new Object[]{objectSyncMessage.getKey()});
} catch (Exception var5) {
log.error("hash结构同步消息单独处理异常,e:", var5);
}
});
}
} catch (Exception e) {
log.error("同步处理异常,e:", e);
throw new RuntimeException(e);
} finally {
lock.unlock();
// 关闭游标
if (cursor != null) {
cursor.close();
}
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}| 特性 | HGETALL (全量获取) | HSCAN (游标/增量获取) |
|---|---|---|
| 命令复杂度 | O(N),N 是 Hash 表的大小。 | O(1),每次只拿一小部分。 |
| 是否阻塞 | 是。数据量大时会长时间占用 Redis 线程,导致其他命令无法执行。 | 否。执行完一次分片立刻释放线程。 |
| 网络开销 | 一次性传输大量数据,容易打满网卡带宽。 | 分多次传输,流量平稳。 |
| 客户端内存 | 需要一次性申请巨大内存来接收结果,容易内存溢出。 | 每次只处理一小部分,内存占用极低。 |
| 游标是什么 | 无。 | Cursor:一个数字字符串。0 表示开始,Redis 返回给你一个新的数字,下次你传这个新数字,直到 Redis 返回 0 表示结束。 |
八.抢单
通过需求分析,抢单模块分如下子模块:
- 抢单设置子模块 设置服务技能、服务范围、开启抢单。
- 抢单查询子模块 查询抢单池中的订单
- 抢单子模块 点击“立即抢单”开始抢单。
抢单成功后生成服务单,服务单的状态包括:待分配、待服务、服务中、服务完成、已取消。
九.派单
阶段总结
本项目
1.订单管理
2.小程序认证
- 对接微信小程序认证接口
- 用户请求网关校验身份,向下传递用户信息,并在微服务通过拦截器拿到用户身份放入TreadLocal,service从TreadLoal中获取用户信息
3.验证码系统
- 提供手机号,用户类型
- 生成一个随机数,存入reids,发到用户手机
4.定位服务
5.小程序首页
- 缓存方案设计,首页中的哪些信息需要缓存服务,xxl-job
6.搜索模块
- 未完成
7.支付模块
- 未完成
8.优惠券系统
-
手动发券
-
自动发券
-
抢券(秒杀抢购系统)
9.订单模块
- 下单
- 订单表的设计
- 分布式锁控制重复订单
- 订单号生成唯一序列
- 取消订单
- 退款接口对接
- 策略模式优化取消订单
- 删除订单
- 逻辑标识显示
- 订单快照
- 未完成
- 状态机
- 未完成
- 订单查询优化
- 未完成
- 冷热分离
- 未完成
- 分库分表
- 未完成
10.秒杀
11.调度
上门类o2o
- 小程序认证
- 服务管理
- 优惠券
- 订单管理
- 我的中心
- 我的优惠券
- 我的订单
- 常用地址管理
- 头像昵称
电商方向
- 商品管理
- 商品搜索
- 下单支付
- 购物车
- 订单管理
- 活动管理
- 限时抢购
- 门户首页
- 统计看板
教育方向
- 课程管理
- 媒资管理
- 师资管理
- 订单管理
- 在线学习
问答
1如何设计接口
使用 @GetMapping注解表示GET方法。 @PutMapping:put方法 @DeleteMapping:delete方法 @PostMapping:post方法 @RequestMapping 可用于任何方法
请求参数: from表单不用添加注解 json:@RequestBody 路径上的:PathVariable 必须要求的:RequestParam
2.Mybatis-Plus有几种主键生成策略?
自增,不设置,手工,uuid 与雪花
3.如何开发一个接口的持久层?
生成模型类,要返回什么数据 如果单表 curd,直接 plus,不然的话单独定义 mapper 接口,再定义 mapper 映射写 xml 文件。最后单元测试
4.@Resource 和 @Autowired有什么区别?
[[Spring注解#2-autowired-和-resource-的区别|2. @Autowired 和 @Resource 的区别?]]
5.项目的分页查询是怎么实现的?
一种是 plus 自带的selectPage分页 一种是pagehelper分页组件适用于自定义sql的分页查询。 底层:在使用方法时,设置的分页参数会进入ThreadLocal线程里,然后用过拦截器PageInterceptor拦截 mybatis ,先查,得到 count 总数,然后修改 sql 语句查询(用完就清空)
6.前后联调
看日志来看去前端还是后端
7.如何开发一个接口的service方法?
接口单一原则 注意事务控制 增删改的接口,要进行入参的校验 入参和返回值避免与其他框架耦合,比如使用pagehelper 是返回的 page 类型如果需要,改成我们需要的 page 类型
8.接口的异常处理怎么实现的?
自定义的异常类型都继承了CommonException类型,在异常处理器中对此类型的异常进行处理。
@RestControllerAdvice注解加在类上 @ExceptionHandler注解加在方法上 方法内写逻辑,过滤异常(内部?外部,全局异常兜底)
9.认证方式
10.手机验证码服务的实现方案?
因为服务用到特别多,封装到 公共服务
用户请求时,验证码存放在 redis 中,string 类型 phone:user:code_业务类型 设置 600 秒过期,进行对比
前端限流,后端校验校验限流
11.Spring Cache 用在项目哪里了?怎么用的?
12.如何保证缓存一致性?
要求较高,延迟双删11.如何保证 redis 和 mysql 数据缓存一致性问题? 不高:定时任务 非常高,走数据库
注意:在使用缓存时不论采用哪种方式如果没有特殊要求一定要对key加过期时间,即使一段时间缓存不一致当缓存过期后最终数据是一致的。
13.项目哪里进行了缓存,缓存方案是什么?
见无边际
出来服务类型和服务项是1天删,其他都是永久储存
14.项目中哪里用了xxl-jo和 MQ?怎么用的?
门户的缓存进行定时更新 定时项指定用户发券
- 支付通知用了 MQ,当支付微服务判定出支付结果后,会发送一个消息给一个 MQ 的交换机(topic 类型),考虑部分其他微服务需要都需要收到支付微服务的支付通知,这里再交换机中绑定多个队列,这些微服务消费者来监听自己的队列,其中 topic 中会有一个业务标识,比如电商和家政就是不同的标识,交换机内绑定的微服务会判断是否是发给自己的来按需收取
(如果没有交换机,生产者就得知道每个具体的队列名字,耦合度太高。有了交换机,生产者只管发,怎么分发是交换机的事。) 交换机有哪些类型?(Direct, Fanout, Topic)广播,精准,模糊匹配
15.如何保证MQ消息的可靠性?
交易系统的通知
- 保证生产消息的可靠性
发送消息的工具类中使用spring提供的@Retryable注解,实现发送失败重试机制 通过注解的backoff属性指定重试等待策略,通过Recover注解指定失败回调方法,失败重试后仍然失败的会走失败回调方法,在回调方法中将失败消息写入一个失效消息表由定时任务进行补偿(重新发送) 实在不行人工找
另外MQ提供生产者确认机制,我们在发送消息时给每个消息指定一个唯一ID,设置回调方法,如果发送成功MQ返回ack,如果失败会返回nack,我们在回调方法中解析是ack还是nack,如果发送失败可以记录到失败表由定时任务去异步重新发送。
- 保证消费消息的可靠性
RabbitMQ是通过消费者回执来确认消费者是否成功处理消息的:消费者获取消息后,应该向RabbitMQ发送ACK回执,表明自己已经处理完成消息,RabbitMQ收到ACK后删除消息。
RabbitMQ提供三个确认模式:手动ack,自动ack、关闭ack
本项目使用自动ack模式,当消费消息失败会重试,重试3次如果还失败会将消息投递到失败消息队列,由定时任务程序定时读取队列的消息。 19.写入中奖记录和任务补偿发送MQ
16.可以百分百保证MQ的消息可靠性吗?
-
生产消息可靠性 生产消息可靠性是通过判断MQ是否发送ack回执,如果发nack表示发送消息失败,此时会进行重发或记录到失败消息表,通过定时任务进行补偿发送。如果Java程序并没有收到回执(如jvm进程异常结束了,或断电等因素),此时将无法保证生产消息的可靠性。
-
消费消息可靠性 保证消费消息可靠性方案首先保证发送消息设置为持久化,其次通过MQ的消费确认机制保证消费者消费成功消息后再将消息删除。
虽然设置了消息持久化,消息进入MQ首先是在缓存存在,MQ会根据一定的规则进行刷盘,比如:每隔几毫秒进行刷盘,如果在消息还没有保存到磁盘时MQ进程终止,此时将会丢失消息。虽然可以使用镜像队列(用于在 RabbitMQ 集群中复制队列的消息,这样做的目的是提高队列的可用性和容错性,以防止在单个节点故障时导致消息的丢失。)但也不能百分百保证消息不丢失。
所以做好补偿处理任务
17.如何保证MQ幂等性?或 如何防止重复消费?
1、使用数据库的唯一约束去控制。 比如:添加唯一索引保证添加数据的幂等性 2、使用token机制 发送消息时给消息指定一个唯一的ID 发送消息时将消息ID写入Redis 消费时根据消息ID查询Redis判断是否已经消费,如果已经消费则不再消费。
18.优惠券模块的核心表的哪些,是怎么设计的?
- 优惠券活动表
- 优惠券领取表
- 优惠券核销表
- 优惠券退回表
- 待发放优惠券表
19.自动发券怎么实现的?
自动发放逻辑 建立一个待发放表,提供一个内部接口给业务系统,用 xxl-job进行调度,首先查询有哪些发放的优惠券活动,然后建一个多线程池,每种活动分配一个线程
- 获取一个 redisson 分布式锁,锁的名称是活动的 id
- 然后根据活动id查询待发放优惠券表的名单 ,再将名单 中没有发券的用户批量插入到优惠券表。
20.订单的状态有哪些?
- 待付款
- 已付款
- 待分配(派单中)
- 待服务
- 已服务
- 待评价
- 已取消(未付款后取消)
- 已关闭(付款后取消)
21.服务表与订单表是怎么设计的?
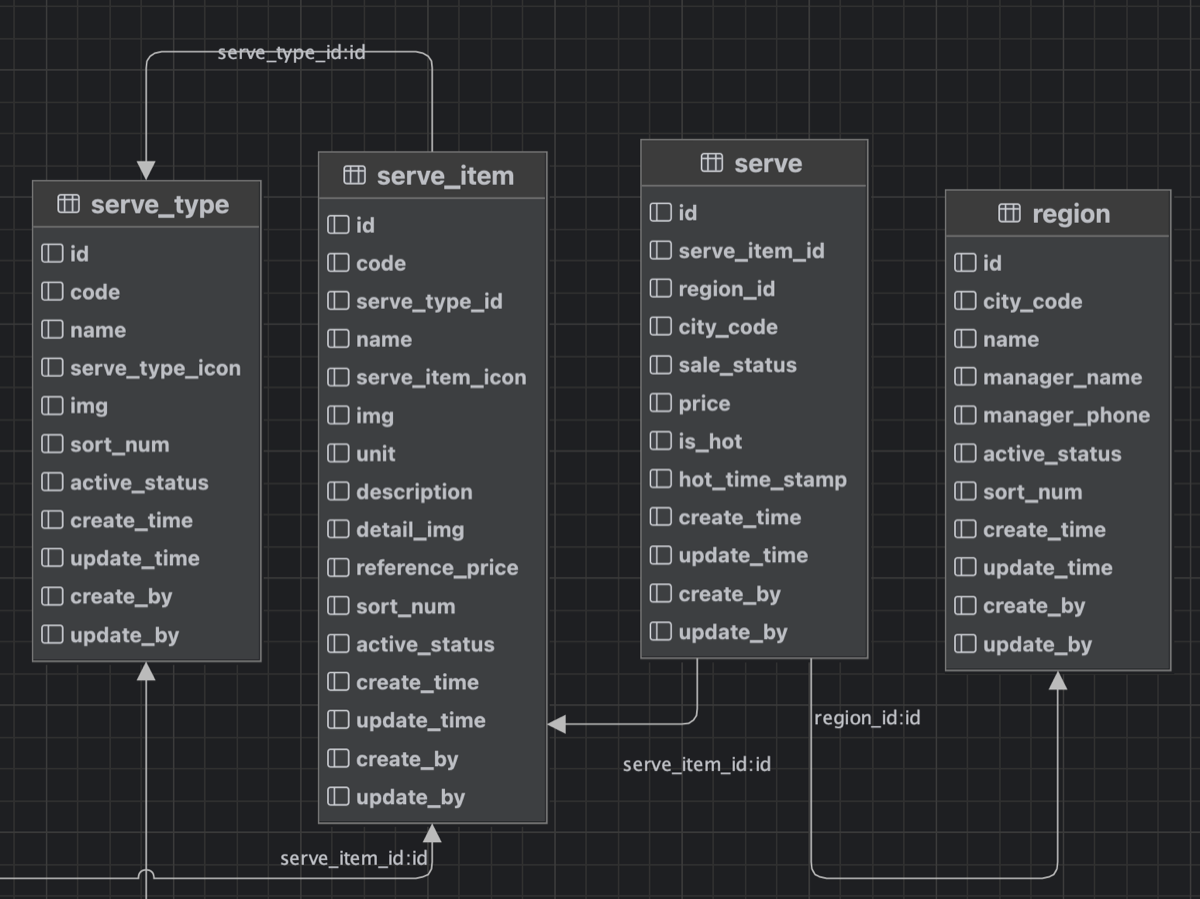
- 订单表
- 订单明细表(在此项目中没有购物车板块,所以和订单表是耦合的)
- 订单基础字段,订单号,排序字段,订单状态,是否显示标记
- 价格信息:总金额,优惠金额,实付金额,购买数量,第三方交易订单号
- 下单人信息:名字与 id手机号地址
- 服务信息,服务 id,服务名称,价格与单位,数量
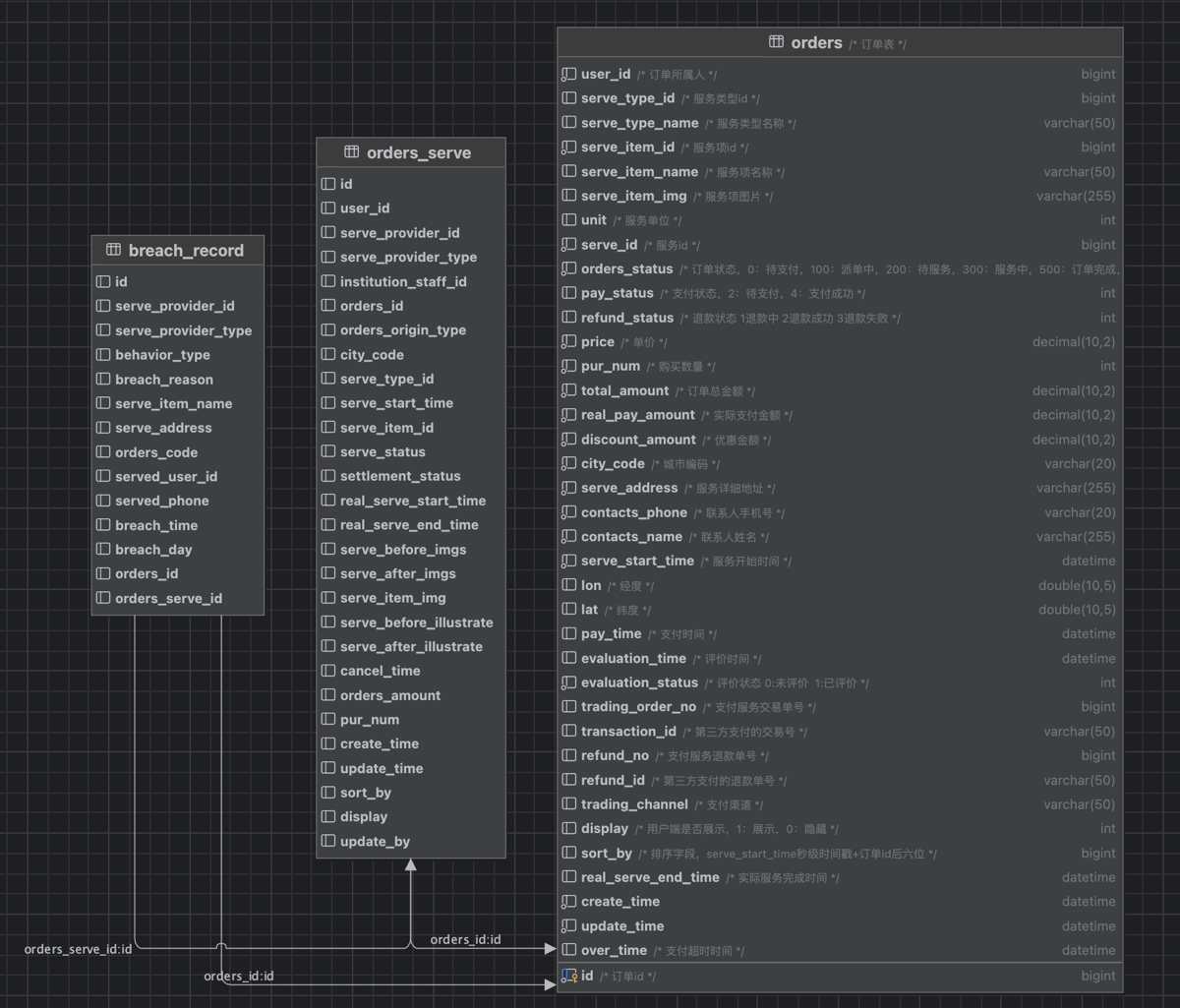
22.*Service 失效原因》?
- 非事务方法调用事务方法,而不是通过代理对象调用实务方法9.springboot怎么开启事务?18.Spring的事务什么情况下会失效?
- 非 public 方法
- 在方法中捕获了异常没有抛出去,没有把异常抛给代理对象,代理对象捕捉不到异常没有进行事务回滚
@Service
public class CouponIssueService {
@Autowired
private InventoryMapper inventoryMapper;
@Autowired
private RecordMapper recordMapper;
@Transactional // 期望开启事务
public void issueCoupon(Long couponId, Long userId) {
// 第一步:扣减库存(假设执行成功)
inventoryMapper.decreaseStock(couponId);
try {
// 第二步:模拟一个异常(比如:保存记录时发生了空指针,或者除以0异常)
int i = 1 / 0;
// 第三步:保存发放记录
recordMapper.saveRecord(couponId, userId);
} catch (Exception e) {
// 【关键错误在这里!】
// 你捕获了异常,只是打印了日志,但是没有继续向上抛出!
log.error("发放优惠券报错了", e);
}
}
}- 数据库表不支持事务,比如MySQL的MyISAM
23.spring如何解决循环依赖
[[1.Spring#13spring是如何解决循环依赖的|13.spring是如何解决循环依赖的?]]
24.如何防止重复订单提交
24.*AOP在项目中有用吗?怎么用的?
[[1.Spring#17spring-常用注解有什么|17.spring 常用注解有什么?]]这里配合 LOCK 锁注解理解4. 防止重复提交订单
25.用到策略模式了吗?
具体逻辑 里面有构造器注入装配(与抽奖系统联动)与策略模式具体逻辑
- 在业务中使用 cancelManger 传入 DTO,进入 Manager 后,构造器的使用传入 cancelDTO 类型,判断用户类型,订单状态,来选择进入不同的策略
- OrderCancelStrategy strategy = getStrategy(orderCancelDTO.getCurrentUserType(), orders.getOrdersStatus());具体是靠这段代码,找出 Map 中的 各种实现了OrderCancelStrategy接口的策略,然后调用strategy内的方法(此时已经是具体的策略了)进入该策略下的具体逻辑(是否退款,是否有权)
- 优势:如果要加入 vip 类型的用户取消订单的逻辑,直接写一个专属的取消逻辑实现OrderCancelStrategy接口,然后头顶注解(2:NoPayed)
26.*什么是状态机,它解决了什么问题?
状态机就是对状态进行统一管理的数学模型,应用在软件领域是状态机设计模式,有了状态机就可以避免在业务代码中对状态进行硬编码,增加系统的可扩展性。状态机设计模式包括四个要素:现态、事件、动作、次态。 1、现态:是指当前所处的状态。 2、事件:当一个条件被满足,状态会由现态变为新的状态,事件发生可能会触发一个动作,或者执行一次状态的迁移。 3、动作:发生事件执行的动作,动作执行完毕后,可以迁移到新的状态,也可以仍旧保持原状态。动作不是必需的。 4、次态:条件满足后要迁往的新状态。 通过状态机更改状态只需要指定事件名称即可,避免了状态字段在代码中硬编码。
首先,使用模板模式创建一个状态机的抽象类,固定整个流程,start 方法(perist 初始化),changeStatus 方法(先检验,再执行具体的 handler,再保存快照与 perist 表,最后留一个后处理给子类扩展使用。
- 其中,在订单服务中,定义一个具体的 order状态机类,来继承刚刚说的抽象状态机类,可以自定义后处理方法,比如同步订单历史表
- 第二,再 handler 方法执行前,我们是通过取出名字和目前的状态,然后拼接后,利用 spring 动态容器的特性,去找我们需要的 handler 方法,比如component 名字为“order_cancel”的order_cancel_handler(实现 StatusChangeHandler 接口里的 handler 方法)来试图更改初始状态到另一个状态,除此之外还有 orderdispatch_handler(也就是从已支付到已派送的状态)
- 最后,整个组件的使用:
- start 的使用:例如在订单创建服务中(这里可以与策略模式中的取消订单一起记忆),我们在最后的保存创建订单后,加入了一段逻辑:创建订单快照,传入order_状态机组件的 start 方法中,然后保存快照(订单快照)(存入 redis 中)与 persist 表(即保存当时的状态,订单号)以便在使用组件其中的 changestatus 时能进行幂等性判断。
- changestatus 的使用:在所有需要更改业务状态的代码中解耦使用:如支付成功时,订单被人员或系统派单时,订单被各种人员取消时(与策略模式记忆),服务完成订单改为已完成时,与订单关闭时。在业务代码中直接使用 changestatus方法,传入用户的 id,订单的 id,当前的状态类型(已在枚举类中定义,起始,终点订单状态与 code),与快照。之后进入抽象类中进行幂等性判断与快照保存与后处理。
- 其中的 code 的作用是完成 Bean 的动态查找对应叫这个名字的 handler:“order 拼接 code”
- 枚举定义如图,PAYED(…)类似于- :
public static final OrderStatusChangeEventEnum PAYED = new OrderStatusChangeEventEnum(...)。 Java Enum 构造语法,本质就是一个特殊的类Class -它在实例化一个对象。
27.项目是怎么分库分表的
分 3 库
- 对用户 id 主键值对 3 取余 分表
- 范围分表,1500 万为一张,虽然数据分配不太均匀但无迁移问题
28.怎么对订单查询优化的?
-
订单详情 订单查询service 代码中使用了状态机组件的从 redis 获取订单详情快照的方法(先查数据库,如果没有再查数据库存入 redis)(json 字符串格式,倒计时 30min,状态更改时删除订单快照)
-
对于用户端 C 端,订单列表
3) 用户端(C端)订单列表查询优化 从分页查询,改为 count 查询,以免 count 操作 利用覆盖索引,查询符合条件(状态?用户 id?)的订单 id,这里在每个数据表中添加一个排序字段,有序且唯一(服务预约时间+订单号后5位)1. 关于“滚动ID(Cursor)”的设计 再根据 订单 id查询订单信息,存入 redisHash 结构中
- 滚动游标
- 联合索引与最左前缀原则
- 覆盖索引查询
- 批量走 redis 或数据库
29.什么是聚集索引和非聚集索引
这俩属于“物理结构”,都属于 B+树
假设有一张表 User (id, name, age, city)。
- 聚集索引:
id(存了整行数据:id, name, age, city) - 非聚集索引:
idx_name_age (name)非叶子节点:存的是索引字段的值 name,叶子节点是主键值(如 id)和 name,而不是整行数据 - 非聚集索引(联合):
idx_name_age (name, age)叶子节点不仅有主键 id,还有 name 和 age
覆盖索引:一种查询结果,通过联合索引实现
- 不用回表,需要的数据都在非聚集索引树上就能找到 4.索引
如何知道是否使用了索引?
explain 关键字对 sql 句子 查看是否使用了索引和具体哪些索引
通过Extra可以判断是否实现覆盖索引。 当Extra的值是Using index时表示使用了覆盖索引。
30.秒杀都用到什么了
“秒杀系统的核心难点是高并发读和高并发写,为了保护数据库,我的技术方案主要分为三个层面:”
-
上游“拦”:利用 CDN 和 Nginx 限流,把绝大部分无效流量和静态资源请求拦截在系统之外,防止带宽被打满。
-
中游“抗”:利用 Redis 做缓存和库存扣减。通过 Redis 的原子性(如 Lua 脚本)来防止超卖,抗住高并发的读写压力。
-
下游“排”:利用 消息队列(MQ) 做异步削峰。抢到库存后,将订单消息写入 MQ,让数据库按照自己的处理能力慢慢消费,防止数据库崩溃。
数据库优化(兜底)
- 人话:最后的堡垒,虽然流量已经削减得很小了,但还是要尽可能快。
- 逻辑:分库分表(数据量太大时拆分)、索引优化(查得快)、行锁优化。
一句话总结: 秒杀就是把请求尽量拦截在数据库之前,能用浏览器解决的别去服务器,能用 Redis 解决的别去数据库,能异步解决的别同步。
31.解决超卖都有哪些方案
- 对于单机环境,数据库行锁,实现乐观锁与悲观锁
- 对于分布式系统,使用 redis 分布式锁,控制多个 jvm 去获取锁
- 对于分布式系统,利用 redis原子操作的特点,用 decr 来实现
32.什么是乐观锁与悲观锁
33.项目中保证Redis原子操作用什么方案?
MULTI 事务命令可以实现多个Redis命令具有原子性,但是没有条件判断 pipeline则不保证 redis 的原子性 3.方案二的具体细节问答
34.抢券是怎么做的?或方案是什么?
-
首先预热程序加载活动信息到 redis 中
-
在查券中,只访问 redis,在进入抢券界面时,自动进行券的时间判断(通过 redisjson 中的开始时间和结束时间),因为里面的活动状态是没有时效性的,此外券的库存也是没有时效性,由抢券阶段解决
-
抢券阶段中,进行 lua 脚本的判断,根据返回值来判断超卖与一人一单,如果成功,写入成功用户记录队列与抢券同步队列
抢券成功队列:为了校验用户是否抢过该优惠券。 抢券同步队列:将抢券结果同步到数据库
-
收尾阶段,通过定时任务,查询 redis 中的抢券同步队列,像优惠券表(coupon)插入用户抢券记录,并更新优惠活动券(activity)表更新库存,写入成功后,删除抢券成功队列的记录,代表一整个阶段完成,如果失败就不删。
35.具体的redis各个队列的数据结构说说
- string活动信息:activity:list |符合条件的优惠券的 json数据 |永不过期
- hash优惠券活动库存:coupon:resource:stock:「活动 id%10」|活动 id|对应的库存|永不过期
- hash抢券成功队列:coupon:seize:list:「活动 id%10」|用户 id|1|用不过期(活动结束删除)
- hash 抢券同步队列:queue:coupon:seize:sync:「活动 id%10」|用户 id|活动 id|永不过期(成功写入删除)
36.讲一下项目中的基于分片的多线程同步组件
- 使用xxljobhandler. seizeSnycJob 定时开启同步任务
- 每隔10分钟,调用线程池开始任务
- 使用 seizehandlerJob.start 根据队列分片创建多线程,并行处理
- 同步队列控制在 10(核心) 到 20(最大队列数)线程存活时间为 60 秒,阻塞队列使用
SynchronousQueue,此队列不存储任务,ArrayBlockingQueue<>(10),有界阻塞队列,只能存 10 个等待任务3.有线程池参数设置的经验吗?拒绝策略:CallerRunsPolicy,如果线程池中绝对满员,由 Caller 线程(项目经理)自己完成(会降低任务的产生速度,这是个好事儿啊)
- 同步队列控制在 10(核心) 到 20(最大队列数)线程存活时间为 60 秒,阻塞队列使用
- 使用 seizehandler.run每个线程抢夺分布式锁,处理自己数据片的活动同步任务(使用看门狗)
opsForHash().scan使用游标批量取 100 条处理,以免堵塞- redisTemplate.opsForHash().scan(H key, ScanOptions options)方法从hash表获取数据。
- Icouponservice.seizeSync 具体执行业务逻辑:写入优惠券表,扣减活动库存
- 这里到第三步是有个问题,如果处理完第二步,时程序崩溃,没有删除 redis 队列那条记录,再次重启服务会相同一个用户再发一次券。必须在数据库中加入
userId + activityId加入唯一索引,并在代码中 try-catch 主键冲突异常。返回重发券 - 上面是针对一人只能领一张券的情况,如果一个人可以领多张券,那么联合索引可以再加入交易流水单号 UUID,这样能保证单号不重复
- 这里到第三步是有个问题,如果处理完第二步,时程序崩溃,没有删除 redis 队列那条记录,再次重启服务会相同一个用户再发一次券。必须在数据库中加入
opsForHash().delete成功后删除
- 结束
37.优惠券核销的交互流程?
- 用户端请求订单服务的下单系统,下单系统请求营销服务系统的获取可使用优惠券的远程调用接口
- 根据传入的用户 id 与下单金额,过滤出可用的,符合条件:满减,满足最低金额,未使用未过期的优惠券,返回给订单服务系统,展示给用户
- 用户下单核销时,将优惠券改为已使用,加入优惠券核销表,若发生取消订单,退款订单,添加优惠券退回表,若此时已过期则作废,删除核销记录。
- 总结:优惠券的核销与退回由于发生了远程调用,使用 seata 处理分布式事务
38.什么是 CAP 原理性
可用性,一致性,分区容忍性。在分布式系统中,最多同时满足俩
39.下单接口是怎么实现的?
订单表如何设计
- 订单表;根据用户id哈希决定数据库(分库表达式为:db_用户id % 3)
- 服务单表:根据服务人员id哈希决定数据库,分库表达式:jzo2o-orders-${serve_provider_id % 3}
- 快照表:根据db_shard_id哈希决定数据库,分库表达式:jzo2o-orders-${db_shard_id % 3},db_shard_id即用户的id 21.服务表与订单表是怎么设计的?
订单号生成规则 [[#开发知识点|开发知识点]]
下单接口如何防止重复提交 4. 防止重复提交订单
如何计算价格 2.优惠券核销
存在分布式事务如何解决
40.redis集群?
“为了模拟真实的生产环境,我在本地使用 Docker Compose 搭建了一套 3主3从(3 Master 3 Slave) 的高可用集群。
网络规划: 我定义了一个独立的 Docker Bridge 网络,让这 6 个容器在内网互通,模拟局域网环境。
节点配置: 每个节点开启
cluster-enabled yes,并绑定宿主机的不同端口(7001-7006)方便调试。持久化与容灾: 配置了 AOF 持久化,并实际测试过 Kill 掉一个 Master 容器,观察 Gossip 协议 判定下线以及 Slave 自动故障转移(Failover) 的过程。
正是因为搭建了这个环境,我才在开发抢券功能时,真实地复现了 Lua 脚本操作多个 Key 时报错
CROSSSLOT Keys in request don't hash to the same slot的问题,从而引出了后面使用 Hash Tag 的优化方案。”
💡 解析: 这段话不仅回答了“怎么搭的”,还顺便秀了你懂 3主3从、Gossip 协议、Failover,最后完美闭环到你简历上的 Lua 脚本跨槽问题。
决定“主从关系”的关键,就在你最后执行的那条创建命令里的 --cluster-replicas 参数。
假设你有 6 个 Redis 容器(Node-1 到 Node-6),你想搭一个 3主3从 的集群。
你只需要执行这一条命令:
redis-cli --cluster create \
redis-1:6379 redis-2:6379 redis-3:6379 \
redis-4:6379 redis-5:6379 redis-6:6379 \
--cluster-replicas 1
这里的 --cluster-replicas 1 是什么意思?
- 它告诉 Redis:“请按照 1 个主节点配 1 个从节点 的比例,自动帮我分配角色。”
. 被追问细节时的“防身术”
面试官可能会问一些细节,以此判断是不是你自己搭的。
Q1: Redis 集群至少需要几个节点?
- 答: 至少需要 3 个 Master 节点,因为 Redis Cluster 的选举机制需要半数以上节点同意(类似 ZooKeeper/Raft),且 Slot(槽)分片也需要至少 3 个节点来分摊才有意义。为了高可用,通常每个 Master 配一个 Slave,所以最少是 6 个节点。
Q2: 你的 Docker Compose 文件大概长什么样?
- 答: “就是定义了 6 个 service,镜像用的是官方
redis:alpine。关键是command启动命令里要带上--cluster-enabled yes和--appendonly yes。还有一个重点是配置network_mode: host或者自定义 network,确保节点间能通过 IP 相互发现。”
41.你的抢券服务是怎么抗住高并发的?为什么不用数据库行锁?
42.Redis 数据怎么同步回 MySQL?
“你异步同步数据,如果 Redis 里的数据量很大,单线程处理不过来怎么办?积压了怎么办?”
-
“我设计了一个基于分片的多线程同步组件。
-
分片策略: 我把同步队列按 Hash 取模分成了 10 个(例如
queue_0到queue_9)。 -
多线程模型: 我用
ThreadPoolExecutor创建了一个线程池。每个线程负责处理一个分片队列的数据。 -
防重与锁: 为了防止多个节点重复处理同一个队列,我给每个队列加了 Redisson 分布式锁。
-
取数优化: 我没有用
HGETALL(会阻塞 Redis),而是用了HSCAN(游标),每次批处理 100 条,既保证了速度又不会打挂 Redis。”
43.*首页服务的深度分页优化(Scroll 游标法)
-
“C端订单列表数据量很大,翻页怎么优化的?”
-
痛点: 传统
limit offset, size在深度分页(比如翻到第 1万页)时,MySQL 需要扫描前 10010 条数据然后丢弃前 10000 条,性能极差。 -
方案: 滚动分页(Scroll Pagination) + 覆盖索引。
-
实现:
-
前端传入上一页最后一条数据的
sort_by(由服务时间+订单号组成的唯一且有序的游标)。 -
SQL 改为:
where sort_by < ? order by sort_by desc limit 10。 -
覆盖索引: 建立了联合索引,先只查出 ID,避免回表。拿到 ID 后再走缓存或批量查详情。
-
-
效果: 无论翻到第几页,复杂度都是 O(1),性能提升百倍。
44.下单并核销优惠券涉及两个微服务,你怎么保证事务一致性?
-
“我使用了 Seata 的 AT 模式。
-
原理: 它基于两阶段提交(2PC)。
-
一阶段:业务数据和 Undo Log(回滚日志)在同一个本地事务中提交。
-
二阶段:如果所有服务都成功,TC 通知删除 Undo Log(异步);如果有服务失败,TC 通知根据 Undo Log 进行反向补偿(自动生成 update 语句回滚数据)。
-
-
为什么选 AT? 相比 TCC 需要手写 try/confirm/cancel 代码,AT 对代码无侵入,开发效率高,适合目前的业务场景。”
45.订单状态流转很复杂,怎么防止‘已取消’的订单被‘支付’?
46. AI 提效
复杂 SQL/Lua 生成:
- “在写抢券的 Lua 脚本时,因为涉及多个 Redis Key 的操作和边界判断,容易出错。我使用 AI 帮我生成了脚本的骨架,并让它帮我检查原子性漏洞。比如它提示我
HGET返回nil和false的区别,帮我避了很多坑。”
47.订单取消?
48.自定义分布式锁?
-
“所以我没有自己用
setnx去造轮子,而是使用了 Redisson 框架。” -
“Redisson 有一个 Watchdog(看门狗)机制。当我加锁时,如果没指定过期时间,它默认给 30秒。”
-
“核心原理: 只要持有锁的线程还在运行,看门狗会每隔 10秒(默认配置的 1/3)自动把锁的过期时间重新续满到 30秒。”
-
“这样就保证了:只要业务没跑完,锁就永远不过期;如果机器宕机了,看门狗线程也没了,锁会在 30秒后自动释放,不会死锁。”
49.支付回调的幂等性
-
机制: “绝对不会。这是支付接口最基本的幂等性设计。”
-
实现(利用状态机):
-
“当收到回调时,我首先检查该订单在数据库里的状态。”
-
“我的状态机限制了流转方向:只有
WAIT_PAY(待支付)状态才能流转到PAY_SUCCESS(支付成功)。” -
“第一次回调: 状态是
WAIT_PAY,更新成功,状态变为PAY_SUCCESS。” -
“第二次回调: 状态已经是
PAY_SUCCESS了,状态机直接报错或返回成功(告知支付宝已处理),数据库更新操作会被拦截,根本不会执行加钱逻辑。”
-
50.讲一下你第二个项目吧
“这是一个微服务架构的 O2O 家政服务平台。
我主要负责的是最复杂的4️⃣订单微服务和 抢单(订单流转与取消订单策略,支付回调)/3️⃣营销(优惠券查询与秒杀发放)微服务和 2️⃣C 端(优惠券下单,查历史订单,查订单详情)的微服务与1️⃣管理端的 CURD。
相比于普通的 CRUD,我在这个项目中主要攻克了几个分布式场景下的难点(这里开始埋钩子):
首先,是复杂状态流转的治理。 家政订单的状态非常多,且涉及支付、退款、派单等多个分支,很容易出现状态混乱。 为了保证流转的严密性,我引入并定制了一个**‘状态机引擎’**,把状态流转原子化,彻底杜绝了非法状态变更的问题。 (钩子1: 等他问你:状态机怎么设计的?有什么好处?)
其次,是分布式数据一致性的保障。 因为下单和核销优惠券跨了服务,为了保证数据不丢不错,我根据业务场景,对比了 TCC 方案,最终选型并落地了 Seata 的 AT 模式来处理分布式事务。 (钩子2: 等他问你:为什么选 AT?原理是什么?Undo Log 是干嘛的?)
最后,是 C 端查询性能的优化。 在面对海量订单列表查询时,我发现传统的
limit offset导致了严重的慢查询。 我通过分析执行计划,采用**‘游标法(Scroll Pagination)’结合覆盖索引**进行了重构,把深度分页的查询性能提升了两个数量级。 (钩子3: 等他问你:深度分页为什么慢?游标法具体 SQL 怎么写?)此外,在抢券的高并发场景下,我还设计了基于分片的多线程异步消费模型,来解决 Redis 和数据库的数据同步延迟问题。”
51.*跨槽问题?
关于“Redis Cluster Hash Tag” :
-
面试官必问:“为什么要用 Hash Tag?不用会怎么样?”
-
标准答案:“Redis Cluster 默认会根据 Key 计算 CRC16 值分片到不同槽位。Lua 脚本如果操作多个 Key(比如扣库存时同时操作‘库存Key’和‘流水Key’),如果这两个 Key 不在同一个节点,Lua 脚本会报错。我使用了
{seckill}:goods_id这种 Hash Tag 语法,强制让相关联的 Key 落到同一个哈希槽,确保了 Lua 脚本的原子性执行。”