1.为什么使用redis?
“引入 Redis 主要是为了解决传统关系型数据库(如 MySQL)在高性能和高并发场景下的瓶颈问题。”
具体展开为两点(核心价值):
-
高性能 (Performance):
-
内存存储: Redis 的数据都在内存中,读写速度是微秒级的。
-
复杂计算下沉: 像排行榜(ZSet)、计数器(Incr)、交并集(Set)这种逻辑,如果在 MySQL 里做需要复杂的 SQL 和磁盘 I/O,而在 Redis 中是原生的 O(1) 或 O(logN) 操作,效率极高。
-
-
高并发 (High Concurrency):
-
抗压能力: Redis 单机 QPS 能轻松达到 10 万+,而 MySQL 单机通常在 1 万 左右。
-
保护数据库: 在大流量进来时,Redis 充当了“缓冲盾牌”,拦截了绝大部分请求,防止流量直接打垮脆弱的数据库。
-
面试追问预警(为什么不用 Java Map 做缓存?): “虽然本地缓存(如 HashMap)更快,但 Redis 解决了分布式数据一致性问题(多台服务器共享数据)和内存容量限制问题(不由 JVM 堆内存限制),且支持持久化。”
2.为什么redis比mysql要快?
核心原因在于两者设计的“主战场”完全不同:
-
存储介质不同(最根本原因):
-
Redis: 是基于内存的数据库。内存的访问速度是磁盘的几个数量级(纳秒级 vs 毫秒级),这使得 Redis 的 I/O 操作极快。
-
MySQL: 是基于磁盘的数据库。为了持久化保存数据,它的读写主要依赖磁盘 I/O,速度受限于磁盘的寻址和传输速率。
-
-
数据结构设计的目的不同:
-
MySQL (B+ 树): 它的 B+ 树是为了**“减少磁盘 I/O 次数”**而设计的。它通过增加节点的分叉数来降低树的高度,从而减少读取磁盘块(Page)的次数。
-
Redis (跳表/哈希表等): 它的数据结构(如 ZSet 用的跳表)是为**“内存操作”**设计的。在内存中,指针跳转的开销非常小,不需要像 B+ 树那样为了省几次跳转而把结构做得那么复杂。Redis 的哈希表甚至能达到 O(1) 的读写效率。
-
一句话总结: “MySQL 像是在图书馆(磁盘)里翻书,为了少跑几趟腿,索引必须做得非常扁平;Redis 像是在脑子(内存)里记事,想起来也就是一瞬间的事,所以数据结构可以更灵活高效。”
3.本地缓存和Redis缓存的区别?
“本地缓存(如 Map、Ehcache)是‘独享’的内存,速度极快但无法共享;Redis 缓存是‘共享’的远程服务,速度稍慢(网络开销)但能让多台服务器共用数据。”
主要区别对比(核心):
-
访问速度 (Speed):
-
本地缓存: 最快。因为数据就在应用程序的进程内存里,读写是纯内存操作,没有网络开销。
-
Redis: 稍慢。需要通过网络请求访问 Redis 服务,存在网络延迟(虽然也是毫秒级,但比本地缓存慢)。
-
-
数据一致性 (Consistency):
-
本地缓存: 难保证。如果你的应用部署了多台服务器(分布式),每台服务器的本地缓存是独立的。修改了 A 服务器的缓存,B 服务器并不知道,会导致用户在不同服务器看到的数据不一样。
-
Redis: 强一致(相对而言)。所有服务器都连同一个 Redis,数据是中心化存储的,修改一次,所有服务器都能读到最新的。
-
-
持久化与可靠性 (Persistence):
-
本地缓存: 无持久化。应用重启,缓存全丢。
-
Redis: 支持持久化(RDB/AOF)。服务重启后数据能恢复,且支持主从备份,更可靠。
-
-
适用场景 (Use Case):
-
本地缓存: 适合极高频读、极少变动、允许少量不一致的数据(如国家省份列表、配置参数)。
-
Redis: 适合分布式共享、高并发写、数据需要实时同步的场景(如库存、Session、排行榜)。
-
4.高并发场景,Redis单节点+MySQL单节点能有多大的并发量?
“Redis 单节点通常能抗住 10 万+ QPS,而 MySQL 单节点通常在 1000 ~ 5000 QPS/TPS 左右。两者相差 10~100 倍,所以才需要 Redis 来做‘挡箭牌’。”(4核心 8g内存)
具体并发能力对比:
-
Redis 单节点:
-
读写能力: 极高。
-
QPS (Queries Per Second): 官方基准测试通常在 10 万 级别(视 Key 大小和命令复杂度而定,简单命令甚至更高)。
-
瓶颈: 通常受限于 网络带宽 和 CPU(如果是高复杂度的计算)。
-
-
MySQL 单节点:
-
读写能力: 较低。
-
TPS (Transactions Per Second): 通常在 1000 ~ 4000 左右(写操作)。
-
QPS (读操作): 如果只是简单查询且命中 Page Cache,可能达到 1 万+,但一旦涉及磁盘 I/O 或复杂关联查询,会迅速下降。
-
瓶颈: 主要是 磁盘 I/O 和 锁竞争。
-
架构启示(为什么这样搭配?): “由于两者的性能差距巨大,在高并发系统中,我们必须遵循**‘二八定律’**:让 Redis 拦截掉 80%~90% 的读请求,只让剩下 10% 的写请求和缓存未命中请求打到 MySQL 上,从而保护脆弱的数据库。”
5.redis应用场景是什么?
“Redis 不仅仅是一个缓存,它凭借丰富的数据结构,广泛应用于计数、排行榜、分布式锁、社交关系计算、消息队列等多种高性能业务场景。”
具体场景与对应数据结构(面试核心):
-
缓存 (Caching) —— 最基础用法:
-
String: 缓存复杂的对象(如用户信息、商品详情)、共享 Session、常规计数。
-
Hash: 缓存结构化数据(如购物车),修改字段时不需要序列化整个对象。
-
-
计数与统计 (Counting & Statistics):
-
String: 简单的累加计数(视频播放数、点赞数)。
-
Bitmap: 二值状态统计(用户签到、是否登录、连续签到),极其节省内存。
-
HyperLogLog: 海量数据的基数统计(网站 UV),虽然有微小误差但内存占用极低。
-
-
排行榜 (Ranking):
- ZSet (Sorted Set): 利用 Score 进行排序,实现实时热搜榜、直播间贡献榜、成绩排名等。
-
社交功能 (Social Features):
- Set: 利用集合的交集、并集、差集运算,实现“共同关注”、“共同好友”、“抽奖活动”等功能。
-
分布式协同 (Distributed Coordination):
- String: 利用
SETNX实现分布式锁,解决并发竞争问题。
- String: 利用
-
消息队列 (Message Queue):
-
List: 简单的消息队列(利用
LPUSH+BRPOP)。 -
Stream: 专业的消息队列(Redis 5.0+),支持消费者组 (Consumer Group) 和自动生成 ID,类似于 Kafka。
-
-
地理位置 (LBS):
- GEO: 存储经纬度,计算两地距离或寻找“附近的人/车”(如滴滴叫车)。
6.Redis除了缓存,还有哪些应用?
同上
7.Redis支持并发操作吗?
“支持。Redis 是专门为高并发场景设计的,单节点能支撑 10 万+ QPS。但需要区分**‘并发连接’和‘并行执行’**的概念。”
核心原理与并发控制(面试关键点):
-
高并发连接(I/O 多路复用):
-
Redis 使用 epoll(I/O 多路复用技术)来监听成千上万个 Socket 连接。
-
这使得 Redis 可以同时处理海量的客户端连接请求,而不会阻塞。
-
-
串行执行(单线程模型):
-
Redis 的命令执行核心模块是单线程的。
-
这意味着,同一时刻只能执行一条命令。即使有 100 个客户端同时发请求,Redis 也会把它们排队,一个接一个地串行执行。
-
优势: 这种设计天然避免了多线程编程中的资源竞争、死锁和上下文切换开销,使得内部数据结构极其安全,不需要加锁。
-
-
如何解决业务层面的并发竞争? 虽然 Redis 内部没问题,但客户端在**“读-改-写”**(Read-Modify-Write)的业务逻辑中会产生竞态条件。解决方案有:
-
利用原子命令: 使用
INCR、DECR、SETNX等原子命令直接操作,不需要先查再改。 -
Lua 脚本: 将多个操作打包成一个 Lua 脚本发送给 Redis,Redis 会将其作为一个原子整体执行,中间不会被插入其他命令。
-
分布式锁: 在操作共享资源前,先抢占 Redis 分布式锁(如使用
SETNX或 Redisson),保证同一时间只有一个客户端能执行业务逻辑。
-
8.Redis分布式锁的实现原理?什么场景下用到分布式锁?
“分布式系统” + “高并发” + “写共享资源”。
在单机系统(单 JVM)中,我们用 Java 的 synchronized 或 ReentrantLock 就能锁住资源。但在分布式系统(多台服务器)中,不同服务器的线程无法看到彼此的锁,这时就需要一个**外部的、所有人都看得见的“中间人”**来管理锁,Redis 就是这个中间人。
-
典型案例:
-
秒杀/抢购: 防止商品超卖(库存扣减)。
-
支付/金融: 防止同一个订单被重复支付。
-
定时任务: 保证多台服务器中,同一时间只有一个节点在执行某个定时任务。
-
- 实现原理是什么?(Implementation Principles)
Redis 分布式锁的实现是一个由简入繁的过程,核心要满足**“互斥性”、“安全性”和“原子性”**。
A. 加锁 (Locking) —— 核心命令
使用 Redis 的 SET 命令的扩展参数,一条命令完成加锁和设置过期时间,保证原子性。
$$\text{SET lock_key unique_value NX PX 10000}$$
-
NX(Not Exists): 只有当 Key 不存在时才写入。保证了互斥性(只有一个客户端能写成功)。 -
PX 10000: 设置 10 秒自动过期。保证了防死锁(即使客户端宕机,锁也会自动释放)。 -
unique_value(UUID): 设置一个客户端唯一的标识(如 UUID)。这是为了解锁时的安全性(防止删了别人的锁)。
B. 解锁 (Unlocking) —— Lua 脚本
解锁时,不能直接 DEL,必须先检查“锁是不是我的”。为了保证“检查 + 删除”两步操作的原子性,必须使用 Lua 脚本:
Lua
-- 如果 Value 等于我的 UUID,就删除;否则返回 0
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end
9. 进阶难点:如何解决“锁过期了,业务还没做完”?
如果业务逻辑执行时间太长,超过了锁的过期时间(例如 10秒),锁被 Redis 自动释放了,其他客户端就会趁虚而入,导致并发问题。
解决方案:看门狗机制 (Watchdog)
通常使用开源框架 Redisson 来实现。
-
原理: 当客户端加锁成功后,Redisson 会启动一个后台线程(看门狗)。它会每隔一段时间(默认 10秒)检查一下,如果业务还没结束,就自动给锁“续期”,重置过期时间。
-
结果: 只要业务在跑,锁就不过期;业务跑完或机器挂了(看门狗也挂了),锁才会释放。
一句话总结:
“最标准的实现是使用 SET key value NX PX 命令加锁,使用 Lua 脚本 解锁,并配合 Redisson 的看门狗机制 来解决锁过期问题。”
10.Redis的大Key问题是什么?
1. 什么是 Big Key?
并不是 Key 本身很大,而是 Key 对应的 Value 很大。
-
String 类型: Value 超过 10KB(一般业务标准)。
-
集合类型 (Hash/List/Set/ZSet): 元素个数超过 5000 个 或总大小超过 10MB。
2. 大 Key 有什么危害?(面试必问)
因为 Redis 是单线程处理命令的,处理大 Key 会导致:
-
客户端超时阻塞: 操作大 Key(如读取、删除)耗时久,后来的请求排队等待,导致整个系统响应变慢。
-
网络阻塞: 比如读取一个几 MB 的 Key,会占用大量带宽,导致网卡流量打满。
-
工作线程阻塞: 使用
DEL删除大 Key 时,释放内存涉及大量 CPU 计算,直接把主线程卡死。
3. 怎么发现大 Key?
-
redis-cli --bigkeys:官方自带命令,扫描整个 Redis,统计每种类型最大的 Key。 -
SCAN+MEMORY USAGE:自己写脚本抽样扫描。 -
RDB 分析工具:使用
rdb-tools分析离线备份文件(不影响线上性能,推荐)。
4. 怎么删除大 Key?(核心解决方案)
千万不能直接 DEL!
-
Redis 4.0+ (推荐): 使用
UNLINK命令。- 它会把 Key 与数据“断开”,真正的内存释放操作会丢给后台线程(
BIO)去异步处理,不会阻塞主线程。
- 它会把 Key 与数据“断开”,真正的内存释放操作会丢给后台线程(
-
Redis 4.0 以下: 必须使用渐进式删除。
-
Hash: 使用
HSCAN每次获取一部分字段,再用HDEL删除。 -
List: 使用
LPOP/RPOP循环删除。 -
Set/ZSet: 使用
SSCAN/ZSCAN分批删除。
-
💡 结合你简历的“高并发”场景:
如果面试官问:“你的抽奖系统里怎么防止大 Key?”
你可以这样回答(结合你的项目):
“在设计预处理概率表时,我特别注意了分片逻辑。如果奖品池非常大,我不会把所有数据塞进一个 Hash 中,而是拆分成多个小的 Hash,或者控制每个 Key 的大小。 另外,在运维层面,我们禁用了线上的
KEYS *命令,并配置了 Lazy Free (lazyfree-lazy-server-del) 机制,确保即使产生大 Key,删除时也是异步释放内存,不会阻塞我的高并发扣减请求。”
11.如何保证 redis 和 mysql 数据缓存一致性问题?
核心结论:标准方案是什么?
业界公认的最佳实践策略是 Cache Aside Pattern(旁路缓存模式) 中的: 先更新数据库,再删除缓存。
口诀: 读的时候,先读缓存,没有再读库并回写;写的时候,先更新库,再删缓存。
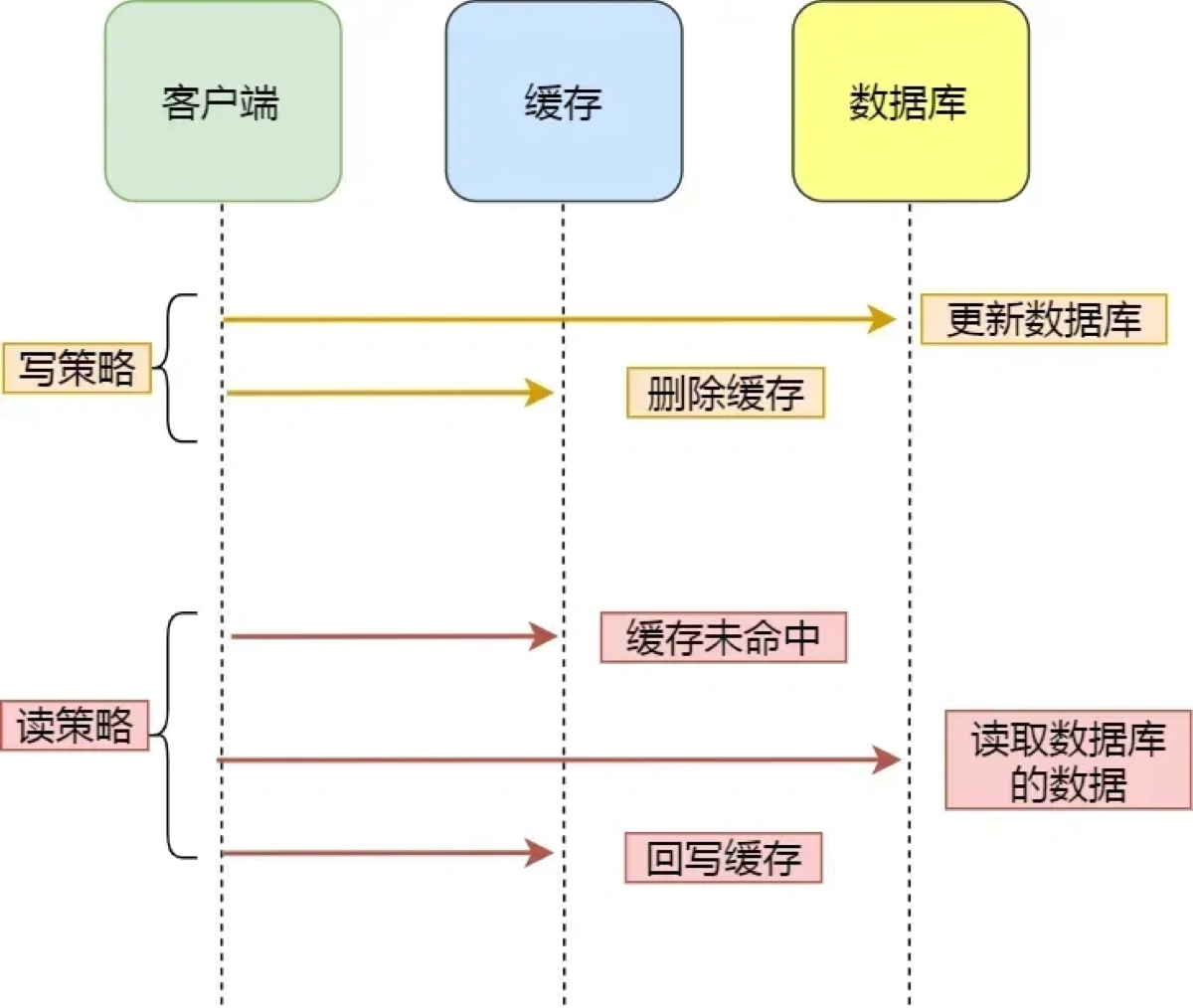
面试高频追问链(按难度排序)
Level 1: 为什么是“删除缓存”而不是“更新缓存”?
-
懒加载思想: 如果你频繁修改数据库(比如 1 分钟改了 100 次),但这 1 分钟内没人来读。如果你每次都更新缓存,就浪费了 100 次 Redis 写操作。
-
避免并发脏数据: 两个线程同时更新,线程 A 先更新 DB,线程 B 后更新 DB;但在更新缓存时,可能因为网络原因,B 先更新了 Redis,A 后更新了 Redis。结果:DB 是 B 的新值,Redis 是 A 的旧值 → 数据不一致。
Level 2: 为什么是“先更库,后删缓存”?反过来(先删缓存,后更库)行不行?
-
不行(有大坑)!
-
场景: 线程 A 删了缓存 → 线程 A 去更库(还没更完) → 线程 B 来了,发现缓存空的 → 线程 B 去读库(读到旧值) → 线程 B 把旧值写入缓存 → 线程 A 终于更库完成了。
-
后果: 缓存里永远是旧数据,直到缓存过期。这是一个非常容易触发的 Bug。
-
补救(延时双删): 也就是删缓存 → 更库 → 休眠 1 秒 → 再删缓存。但这个“休眠多久”很难评估,严重拖慢性能,不推荐。
Level 3: “先更库,后删缓存” 就完全没问题吗?
-
理论上也有极低概率的问题: 线程 A 读库(旧值) → 线程 B 更库 → 线程 B 删缓存 → 线程 A 写入缓存(旧值)。
-
但是! 这种情况要求“数据库写”比“数据库读”快得多,这在实际物理世界中几乎不可能发生(读通常比写快)。所以这个方案是相对最安全的。
Level 4 (杀手锏): 万一“更新数据库成功”,但“删除缓存失败”了怎么办?
这时候 DB 是新值,Redis 是旧值,数据不一致了。你需要保证缓存删除操作最终执行成功。
方案 A:消息队列重试机制
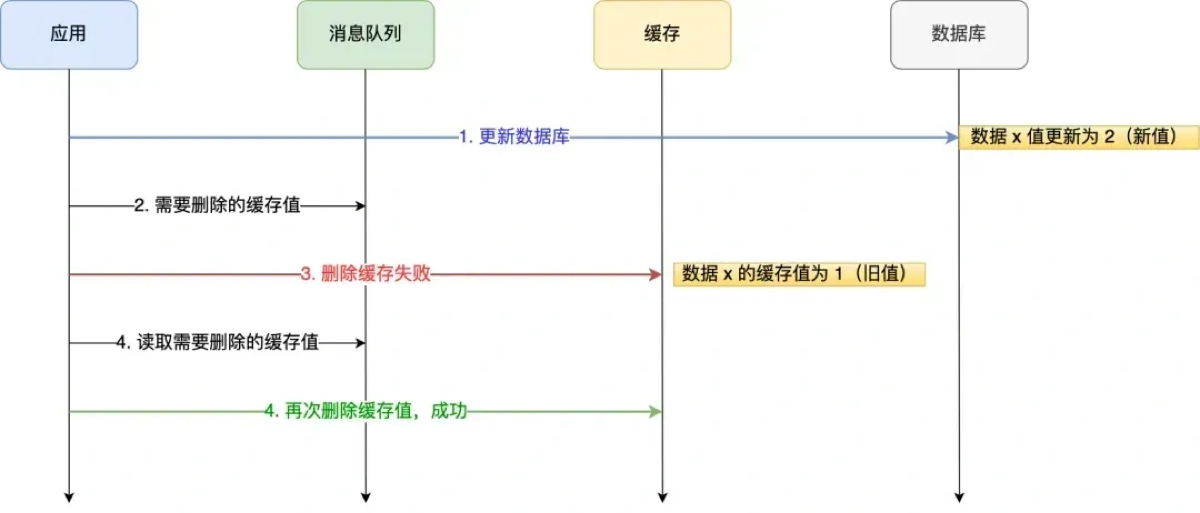
-
更新数据库。
-
删缓存失败 → 把要删的 Key 发送到 MQ(Kafka/RabbitMQ)。
-
消费者监听 MQ,不断重试删除操作,直到成功。
- 缺点: 业务代码入侵重,代码里到处是 MQ 发送逻辑。
方案 B:订阅 MySQL Binlog(大厂方案,推荐写进简历)
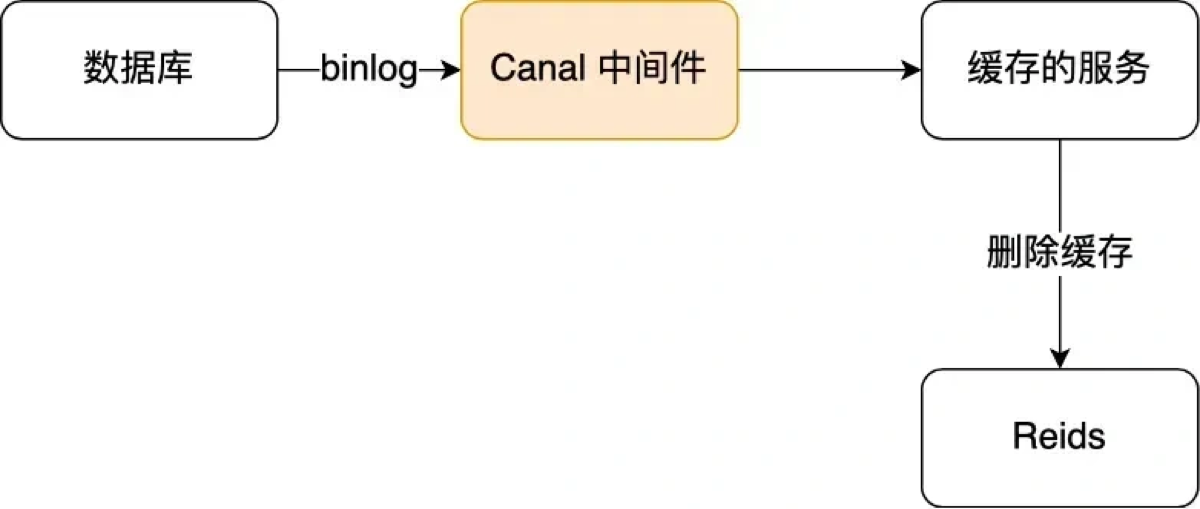
-
业务代码只管更新数据库,不操心缓存。
-
使用中间件(如 Canal)伪装成 MySQL 的从节点,监听 Binlog 日志。
-
一旦发现数据变更,Canal 解析日志,自动投递消息去删除 Redis 缓存。
- 优点: 业务代码 0 侵入,完全解耦。
12.缓存雪崩、击穿、穿透是什么?怎么解决?
| 概念 | 关键点 | 形象比喻 | 发生场景 | 核心解决方案 |
|---|---|---|---|---|
| 缓存雪崩 (Avalanche) | 大量 Key 同时失效 | 就像雪崩一样,所有保护层瞬间消失,大量请求直接压垮数据库。 | 1. 缓存服务宕机。 2. 大量 Key 设置了相同的过期时间(如零点刷新)。 | 1. 过期时间加随机值。 2. Redis 高可用(集群)。 |
| 缓存击穿 (Breakdown) | 单个热点 Key 失效 | 像一颗子弹击穿了盾牌上的一个点。一个热点 Key 刚过期,万级并发瞬间涌入 DB。 | 秒杀活动中,某个爆款商品的缓存突然过期。 | 1. 互斥锁 (Mutex)。 2. 逻辑过期(永不过期)。 |
| 缓存穿透 (Penetration) | 数据根本不存在 | 像子弹穿透了盾牌和身体。请求的数据在 Redis 和 DB 里都没有,导致每次都查库。 | 1. 黑客恶意攻击(查 ID=-1)。 2. 业务逻辑错误。 | 1. 布隆过滤器 (Bloom Filter)。 2. 缓存空对象 (Value=Null)。 |
- B. 缓存击穿 (Cache Breakdown)
场景: 你的抽奖系统里有一个超级大奖(如 iPhone),这是热点 Key。万级用户都在疯狂刷新这个奖品的详情。突然,这个 Key 过期了,这 1 万个并发请求瞬间穿过 Redis,全部砸在数据库上查找这个奖品。
解决方案:
-
互斥锁 (Mutex Lock): 发现 Key 不在时,不要所有人都去查库。用
SETNX抢一把锁,抢到的人去查库并回写 Redis,其他人等待或重试。一句话亮点: “对于热点 Key,我采用了互斥锁策略,保证同一时刻只有一个线程去数据库加载数据,构建了保护屏障。”
-
逻辑过期 (Logical Expiration):(进阶方案,适合对性能要求极高的场景) Redis Key 设置为永不过期,但在 Value 里面存一个过期时间戳。取出来发现快过期了?返回旧数据,同时异步启动一个线程去后台更新数据。
-
C. 缓存穿透 (Cache Penetration)
场景: 黑客写了个脚本,疯狂请求 ID = -99999 的奖品。因为数据库里没有 -99999,Redis 里也没有,所以每次请求都会打到数据库,导致数据库白白空转挂掉。
解决方案:
-
缓存空对象 (Null Object): 发现数据库没数据,也在 Redis 里存一个
Key: null,并设置一个较短的过期时间(如 60秒)。缺点: 如果黑客每次换不同的随机 ID 攻击,Redis 内存会被占满。
-
布隆过滤器 (Bloom Filter):(满分答案) 在访问 Redis 之前,先问一下布隆过滤器“这个 ID 存在吗?”。
-
布隆过滤器说不存在 → 直接返回,连 Redis 都不查。
-
布隆过滤器说可能存在 → 再查 Redis → 再查库。
-
原理: 它是利用极小的内存(位图)来高效判断元素是否存在的工具。
-
13.布隆过滤器原理介绍一下
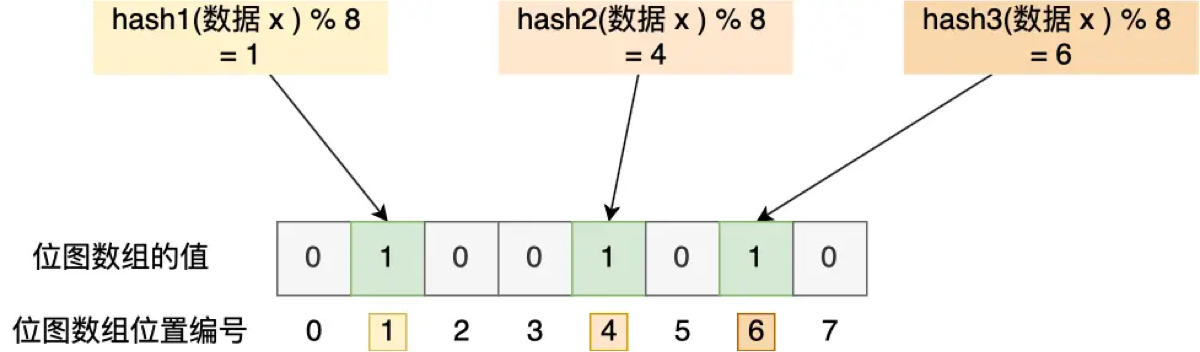
1. 核心原理:位图 + 哈希函数
你可以把它想象成一个**“极其节省空间的指纹库”**。
-
数据结构: 它本质上是一个很长的 二进制向量(位数组/Bit Array),初始化时所有位都是
0。 -
工具: 它配备了 $k$ 个哈希函数。
步骤一:写入数据 (Add)
假设我们要把 "user_1" 存进去,且有 3 个哈希函数:
-
用 3 个哈希函数分别算一下
"user_1",得到 3 个位置下标(比如 1, 4, 7)。 -
把位数组中这 3 个位置的值都置为
1。
步骤二:查询数据 (Check)
现在来了一个请求查 "user_1":
-
同样用那 3 个哈希函数算一遍,得到下标 1, 4, 7。
-
看这 3 个位置是不是都是
1?-
如果有一个是 0: 说明
"user_1"绝对不存在。(直接拦截,不用查库了) -
如果全都是 1: 说明
"user_1"可能存在。(放行,去查 Redis/DB)
-
2. 面试必问:为什么会“误判”?(False Positive)
这是布隆过滤器的核心特性(也是代价)。
-
原因: 不同的字符串经过哈希运算后,可能会映射到相同的位置(哈希冲突)。
-
场景: 假设
"user_1"占用了位置 1, 4, 7。后来你要查"user_2",它的哈希结果刚好也是 1, 4, 7(或者它的位置被其他几个 key 凑齐了全是 1)。 -
结果: 布隆过滤器会告诉你
"user_2"存在,但实际上它不存在。
核心口诀(背诵):
“布隆过滤器说不存在,那就一定不存在;
布隆过滤器说存在,那它只是可能存在。”
3. 优缺点对比(面试官追问点)
| 特性 | 说明 | 面试应对 |
|---|---|---|
| 优点 | 快、省。空间复杂度极低(不需要存 key 本身,只存几个 bit),查询时间是 O(k) 常数级。 | “相比于用 HashMap 存所有 Key,布隆过滤器能节省 90% 以上的内存。” |
| 缺点 | 有误判率、删除困难。 | “误判可以通过调整数组长度和哈希函数数量来降低;删除困难是因为把某一位重置为 0可能会误删其他 Key。” |
14.如何设计秒杀场景处理高并发以及超卖现象?
层层拦截,把请求量像漏斗一样筛减,最后只让极少数请求打到数据库。
1. 秒杀系统的核心架构(漏斗三层级)
面试时,你可以按这个顺序讲,逻辑非常清晰:
第一层:客户端/网关层(拦截 90% 流量)
-
页面静态化 + CDN: 秒杀页面做成静态 HTML,推送到 CDN 节点。用户刷新页面请求的是 CDN,不打你的服务器。
-
按钮防抖: 用户点一次“抢购”后,按钮立刻变灰(置为 Disabled)几秒钟,防止单身三十年的手速疯狂连点。
-
网关限流 (Nginx/Gateway): 限制同一 IP 的访问频率,拦截恶意脚本。
第二层:应用服务层(Redis 拦截 9% 流量)
-
库存预热: 活动开始前,把库存提前加载到 Redis 中。
-
缓存抗压: 所有的读请求(查库存、查商品详情)全部走 Redis,坚决不查库。
-
扣减拦截(你的亮点): 在这里进行Redis 预扣减(使用你简历里的
decr或 Lua 方案或者分布式锁)。2.锁的选择-
如果 Redis 扣减成功 → 才有资格进入下一步。
-
如果 Redis 扣减失败(库存<0) → 直接返回“已抢光”,请求到此截止。
-
第三层:数据库层(处理最后 1% 流量)
-
异步削峰 (MQ): 抢到资格的用户,不要立刻去写数据库生成订单。而是发送一条消息到 消息队列 (RabbitMQ/Kafka/RocketMQ)。
-
消费者慢慢写: 后端服务监听 MQ,按照数据库能承受的速度,慢慢地扣减真实库存、创建订单。这就叫**“削峰填谷”**。
“针对高并发秒杀场景,我采用的是**‘全链路漏斗过滤’**的设计思想:
-
在上游,利用 Nginx 和 CDN 拦截大部分静态资源和恶意请求。
-
在核心扣减环节(这是我的项目亮点),我彻底摒弃了直接操作数据库的方案,而是采用了 Redis 预热 + 原子递减 (Decr) 的策略。
-
流量进来先走 Redis 扣减,利用 Redis 单机 10w+ 的吞吐量抗住洪峰。
-
只有在 Redis 扣减成功的极少数请求,我才会通过 MQ 异步(云岚到家里是多线程游标同步读取 redis 缓存队列到 mysql)发送给数据库做最终的订单落地。
-
-
在超卖控制上,Redis 的原子性保证了并发安全,配合数据库层面的
stock > 0乐观锁做最终兜底,确保了哪怕 QPS 破万,库存也绝对准确。”