项目已上线:http://81.70.76.245:3030/?userId=liergou01&activityId=100301
nano ~/.zshrc
1.8.0_472 (arm64) "Amazon" - "Amazon Corretto 8" /Users/xinduan/Library/Java/JavaVirtualMachines/corretto-1.8.0_472/Contents/Home
source ~/.zshrc
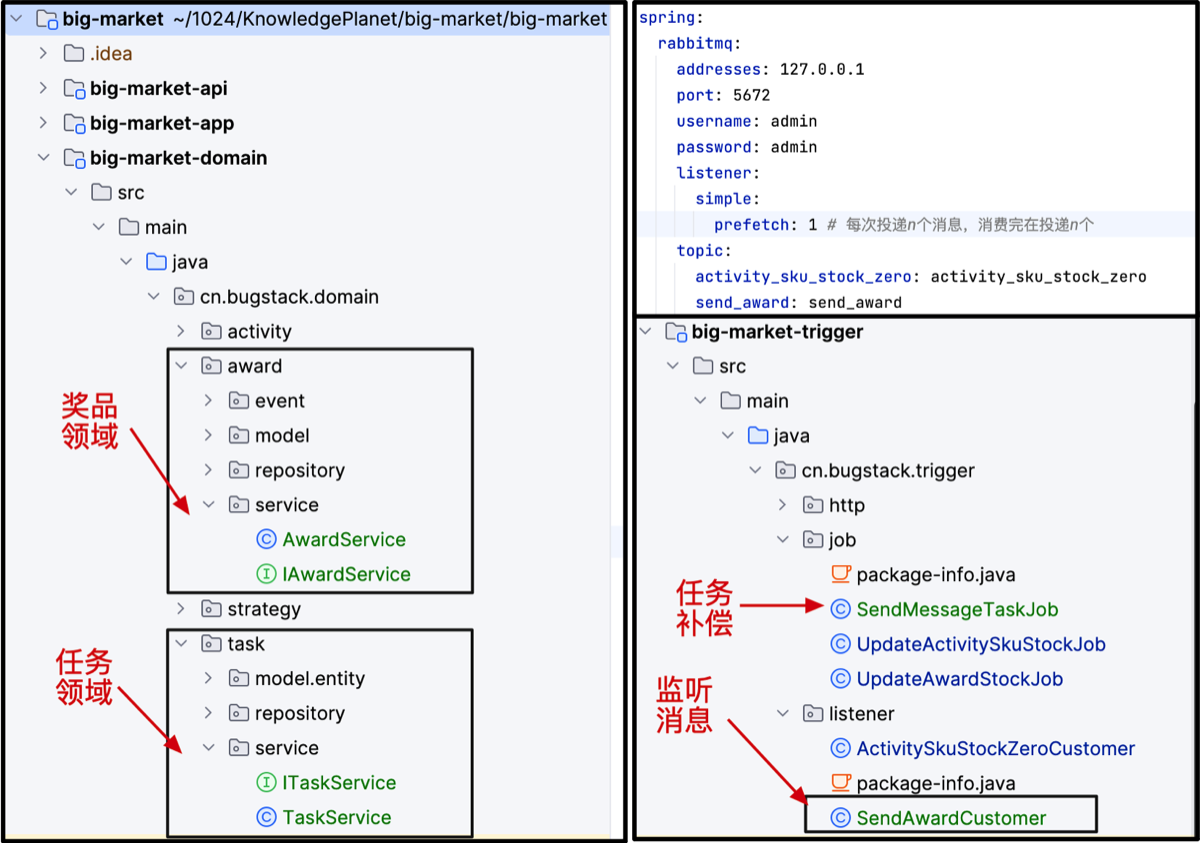
0.架构梳理
1.项目搭建
项目由start.spring.io 脚手架创建,使用了统一 maven-archetype-plugin 插件,自定义了一套 DDD 工程骨架脚手架。
- api 类似菜单。外部服务(如订单系统)调用抽奖系统上,引入 api 的 jar 包后
- 代码里写着IRaffleService.draw(),他知道接口长什么样了,入参和返回值是什么
- 当服务 A 运行
.draw()时,RPC 框架如 dubbo 和 freign,会拦截这个调用,框架去问注册中心 nacos 或 zookeeper,谁实现了IRaffleService 接口? - 注册中心回答 ip。。。。端口号。。。在 big-maket-trigger 那个服务里,之后 RPC 框架将数据发送过去
2.项目中都遇到了什么问题?
在开始项目时,引入脚手架之外的组件时,因为 jar 包版本不同,出现编译通过,但是在代码运行时,调用的方法不存在,通过 mavenHelper 插件,找到其他组件中多引入了相同的 jar 包,另外在项目的规则树逻辑判断上出现问题,通过抛出自定义的异常,debug 来解决。还有一些空指针异常也是,加入额外的判断。
3.DDD模式讲一讲一你的理解
一种软件设计方式,就像在这个项目中,我负责实现的抽奖中的策略,就是一个独立的领域模型。在这个领域中我需要提供策略的装载、随机数算法计算、抽奖模板调用(含责任链和规则树) 功能,这样一个领域就像划分好的一个独立个体,它拥有属于它的对象信息(实体、值对象、聚合),当需要使用数据库资源、缓存资源,以及外部接口资源的时候,都通过依赖倒置进行调用。也就是说,我的领域不做其他模块的引入,而是领域只负责业务功能实现,所需的所有数据,则有外部接口通过依赖倒置提供。
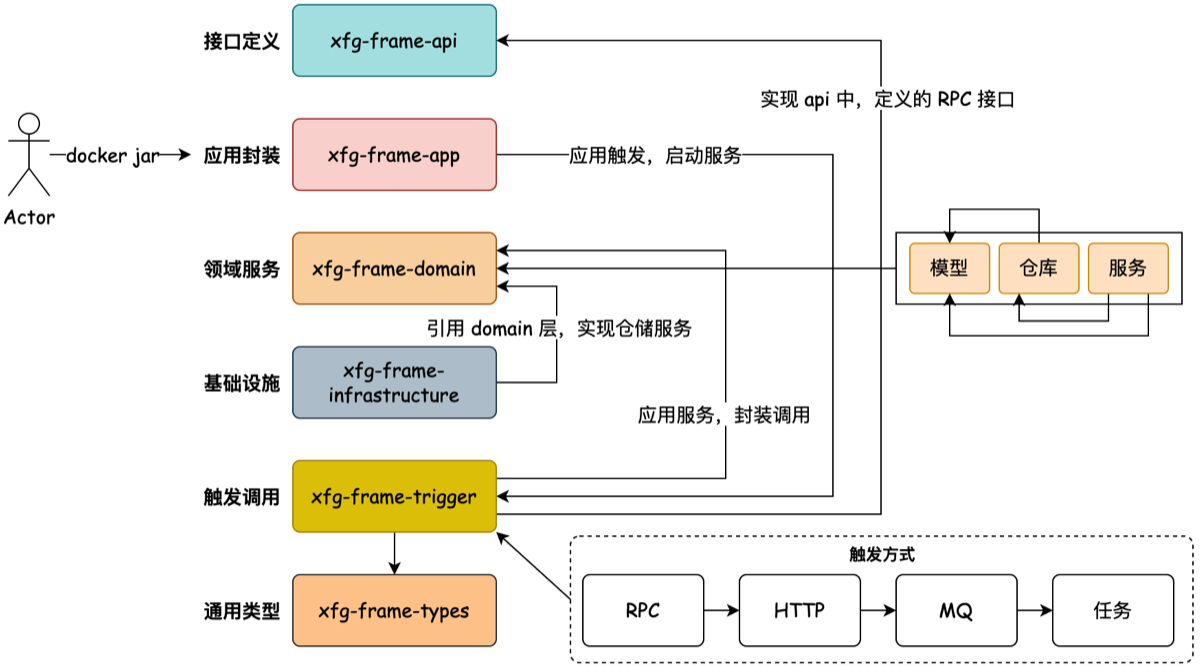
1.DDD架构设计 分为 6 层架构
- api,为 RPC 提供接口,为其他服务提供联系
- app 层,主要是项目的启动类,切面,日志等
- domain层,核心的业务层
- 值对象 valobj 没有唯一标识
- 实体对象 entity,多一个唯一标识
- 聚合对象,包含多个实体对象,比如订单号与商品名称数量,与业务强相关 🚗 一个超级通俗的例子:
- infrastructure 层,mq,redis,mysql 的具体逻辑,类似于 mapper 层,实现 domain 层的数据持久化
- trigger 层,通过 mq,RPC,http 等触发 ,实现 api 层的接口。接受外部请求,校验参数,联系 domain 层,返回结果
- type 层,通用的返回对象,枚举类,常量等,被公共使用
4. 因为你的项目是前后端分离的,接口跨域怎么做的?
-
本质:跨域问题是浏览器执行的同源策略导致的,为了防止恶意网站窃取数据。
-
现状:我的项目是前后端分离的,前端(Vue/React)和后端(Spring Boot)运行在不同的端口(或域名)上,属于“不同源”,所以默认无法交互。
-
解决:我使用了 Spring Boot 的
@CrossOrigin注解。-
它会在响应头中添加
Access-Control-Allow-Origin字段。 -
开发时,为了方便调试,我配置为
*,允许所有访问。 -
上线后,为了安全,我会将它限制为前端部署的具体域名(如
gaga.plus),防止第三方站点恶意调用我的接口。
-
5. 你的抽奖流程中,哪些被定义为值对象,哪些被定义为实体对象
描述对象属性的值,不具备 唯一id
- 值对象 (VO):像项目中的规则树 (
RuleTreeVO) 或枚举,它们只用于描述属性或结构,在抽奖过程中是只读的,不需要唯一 ID 进行追踪,所以定义为 VO。 - 实体 (Entity):像抽奖单 (
PartakeEntity) 或奖品 (AwardEntity),它们必须有唯一 ID(如订单号、奖品 ID),因为它们在业务流程中会有状态流转(如从“未支付”变“已支付”,库存从 10 变 9),最终需要持久化到数据库,所以必须定义为 Entity。
对于实体,我们使用充血模型,将状态变更的逻辑(如扣减库存、修改状态)封装在实体内部,保证了数据的一致性和安全性。 例如
- 在 strategyEntity 中的
getRuleWeight(),内部有一个判断取出的实体内是否有数据库中的ruleModels字段是否有值,还有一个取出ruleModels内的各种字段后判断其中有没有rule_weight字段,然后返回rule_weight字段,来代表此策略有权重规则(还有一种策略是黑名单策略) - 在 strategyRuleEntity 中的
getRuleWeightValues(),(也就是上面的 strategy 要看具体的规则时,查看 strategy_Rule 内的数据表内的两种规则具体的配置),需要解析出具体的配置,项目中是是一个字符串4000:102,103,104,105 5000:102,103,104,105,106,107 6000:102,103,104,105,106,107,108,109,需要解析出后,返回一个 map 结构的结果。这里直接在实体定义充血方法,这样不用将繁杂重复的逻辑放在具体的业务代码里。即使以后业务需求有更改,换成 json 字符串或用别的符号分割,直接在实体内修改即可。
6. 关于访问数据层的依赖倒置,是怎么使用的,有什么好处,你可以描述下吗
MVC 的贫血模式中,数据库持久化对象,一般会被当做业务对象来使用,后期非常难维护,但在 DDD 中,是以领域实现为核心,一个领域内的所需外部服务,都有领域层做接口,由数据层做具体的实现。数据库持久化操作,定义的 PO 对象,就被这样的方式被限定在基础层了,外部是没法引入使用的,也就天然的防止了数据库持久化对象进入业务中。 DDD 把依赖关系箭头掉了个头,领域层当老板,定义接口让打工人来实现数据持久化,防止数据库 PO 对象泄露
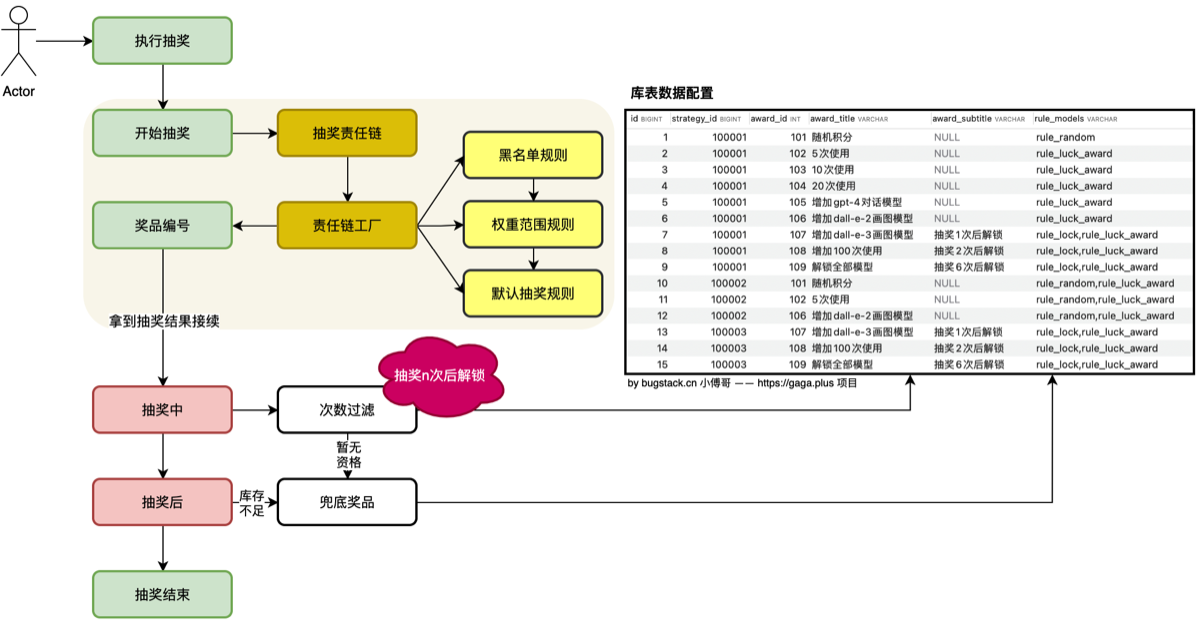
7.把抽奖划分为抽奖前、中、后,三个动作。请具体结合场景讲解下,为什么这样设计
对于需求中的各类功能点;黑名单抽奖、权重抽奖、默认抽奖、抽奖N次解锁、兜底抽奖等等情况,是可以拆解为抽奖前、中、后,3个行为动作的,基于这样的考虑后,就可以设计出非常容易扩展的松耦合结构。
8.讲讲抽奖流程?
-
首先就是,奖品的概率装配,在装配时,我们使用空间换时间的方法,根据概率值来直接将奖品放入 list 列表中打乱,抽奖时直接选取其中一个即可。另一种是生成概率值后 for 循环与范围值对比,来看在哪个区间。
- 具体来说:先查询具体策略下的每个奖品,比如有 8 个奖品,奖品之间的被抽出的概率不同,比如一个是 0.0001 一个是 0.1.我们查数据库时,找出最小的概率作为“精度”,计算出需要的格子数(1 除于小数)。之后创建一个这个格子数的数组(Map),将奖品铺开,打乱,存入 redis
- 需要注意点是,分布式系统下,redis 能解决分布式问题
- 存入 redis 时,使用 map 结构:strategy_rate_table_10001 中,里面value 和 key,在抽奖时,根据生成的随机数,比如 5,发送一个
strategy_rate_table_10001 5就能返回 102 编号的奖品 
-
第二种情况:如果有策略权重的装配,当该策略为权重装配时(rule-model字段有rule_weight时)查询 strategy_rule 数据表查询具体的权重配比
4000:102,103,104,105 5000:102,103,104,105,106,107 6000:102,103,104,105,106,107,108,109。即,消耗多少积分,必得几号几号奖品- 从规则表读取出序列后,解析,遍历这些分组(key=3000,Key=5000)对于每个分组,都执行一遍策略装配(与概率装配平行)
- 当用户触发了权重规则(在抽奖前时可以校验用户 redis 中储存的已消耗的积分来判断是否触发保底次数,如果触发了,直接抽奖后清空保底保底次数,不然的话,还是走默认抽奖也就是上面的全概率装配的奖池)
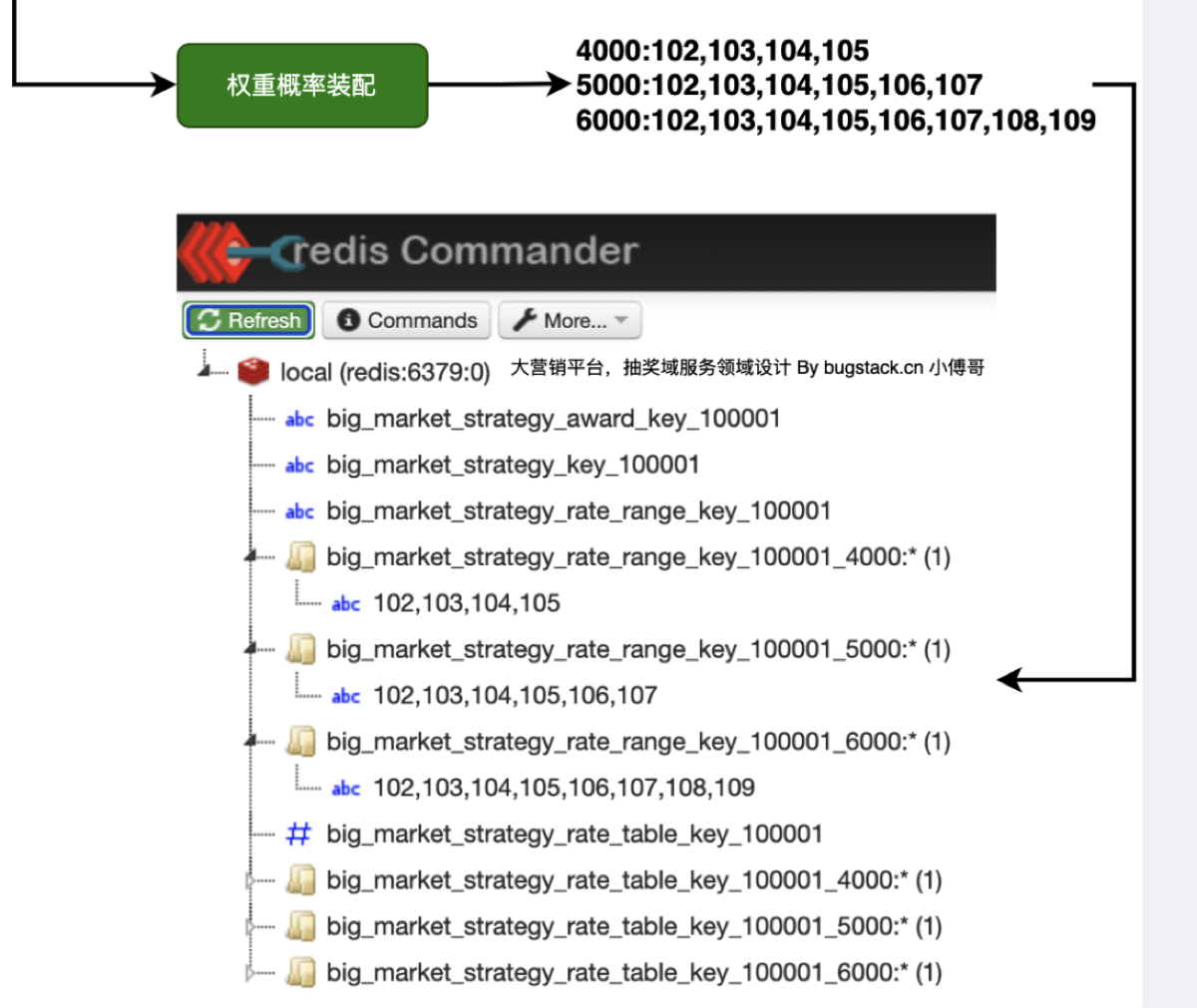
| Redis Key | 说明 | 谁来用? |
|---|---|---|
strategy_rate_10001 | 默认奖池 | 积分不足 4000 的普通用户 |
strategy_rate_10001_4000 | 4000分 VIP 奖池 | 消耗积分 >= 4000 的用户 |
strategy_rate_10001_5000 | 5000分 VIP 奖池 | 消耗积分 >= 5000 的用户 |
- 以上是两种装配方式,接下来我使用了模板模式来串联抽奖前抽奖中的流程
- 在AbstractRaffleStrategy中定义骨架模板,由DefaultRaffleStrategy 来实现抽象模版中的可变的那个过滤方法
- 参数校验
- 查询策略
- 抽奖前规则过滤 ← 子类实现
- 默认抽奖逻辑
- 在AbstractRaffleStrategy中定义骨架模板,由DefaultRaffleStrategy 来实现抽象模版中的可变的那个过滤方法
- 其中,抽奖前的规则过滤使用到了策略模式,来根据具体情况
- 利用工厂模式(从刚开始工厂根据扫描的注解放入 map 的那个 map 里取出策略。)获取rule_blacklist策略,来判断是否接管。如果不是黑名单,则继续用权重过滤
+-------------------------------+
| DefaultRaffleStrategy |
| doCheckRaffleBeforeLogic() |
+-------------------------------+
|
+----------------+-----------------+
| |
黑名单规则优先执行 其它规则顺序执行
| |
logicFilter["rule_blacklist"] logicFilter["rule_weight"]
| |
+-------+-------+ +------+-------+
| | | |
TAKE_OVER ALLOW TAKE_OVER ALLOW
| | | |
返回固定奖品ID 进入下一规则 限定范围抽奖 进入默认抽奖
-
抽奖时(特殊判断当前奖品是否有次数锁) 1.需要加入
doCheckRaffleCenterLogic()的子类方法,来根据用户用户的抽奖次数是否到达当前已经抽到的奖品是否匹配(这里指的是该奖品有次数锁的情况 ),如果匹配(即大于等于)放行即可,如果不匹配,拦截走兜底奖励,也就是说,是先抽奖再判断是否这个奖品匹配。后面会转换为决策树。在树节点中配置具体几次的次数 -
之后我们对整个抽奖前的阶段进行了责任链的重构,虽然我们是用来模板模式与策略模式,但所有的规则判断逻辑,如黑名单,权重,其实还是堆在
DefaultRaffleStrategy里的,随着规则变多,这个类还是会很挤,所以之后我们又对规则判断与业务逻辑彻底分开,使用责任链来实现- 在之前的
doCheckRaffleBeforeLogic中,需要一堆 if-else 或循序来遍历所有规则,如果要增加一个规则,既需要写规则类,又需要在 ifelse 中添加,不符合开闭原则 - 于是我们将黑名单,权重抽奖,默认抽奖封装成独立节点首尾相连,从链头往下走,处理不了就下一个节点处理
 testt
a.所有节点(黑名单,权重,默认)都需要实现
testt
a.所有节点(黑名单,权重,默认)都需要实现AbstractLogicChain→ILogicChain接口7.责任链模式处理抽奖规则 1.logic():核心逻辑,判断我是不是该拦截这个用户 2.next():传递棒,我不拦截,交个下个人 3.appendNext():组装链。在初始化时,将所有节点串起来 b.DefaultChainFactory此工厂类将这些节点初始化时收起来,如果配置里有 如@Component(“rule_blacklist”)会被扫描后,启动时扫描所有实现了这里没有用到自动装配,而是懒加载 getBean 指定后添加链接链接点(通过 appendNext),第五节的还是策略模式的时候用的是 map 自动装配,但是逻辑还得实时更改。 c.在抽奖时,新传入策略 id 到工厂类中,在工厂类中读取数据库中配置的该策略是否有黑名单和权重抽奖 1.如果没有,默认装配一个默认抽康责任链,如果有的话就挨个装配。并返回责任链链头 2.开始核心的 logic 挨个判断。来决定是否接管与传递下一位 :ILogicChan接口的类,自动装配(使用的是构造器注入不断学习)return next().logic(userId,strategy)
- 在之前的
-
之后我又对抽奖中和抽奖后进行了规则树的重构,抽奖中和抽奖后因为逻辑比较复杂,不像抽奖前的阶段那么线性,需要判断奖品是否有库存,二叉分裂后,有库存,判断是否有次数锁。没库存,直接发保底奖品。只能写成 ifelse,所以为了引入了组合模式来实现一个决策树引擎
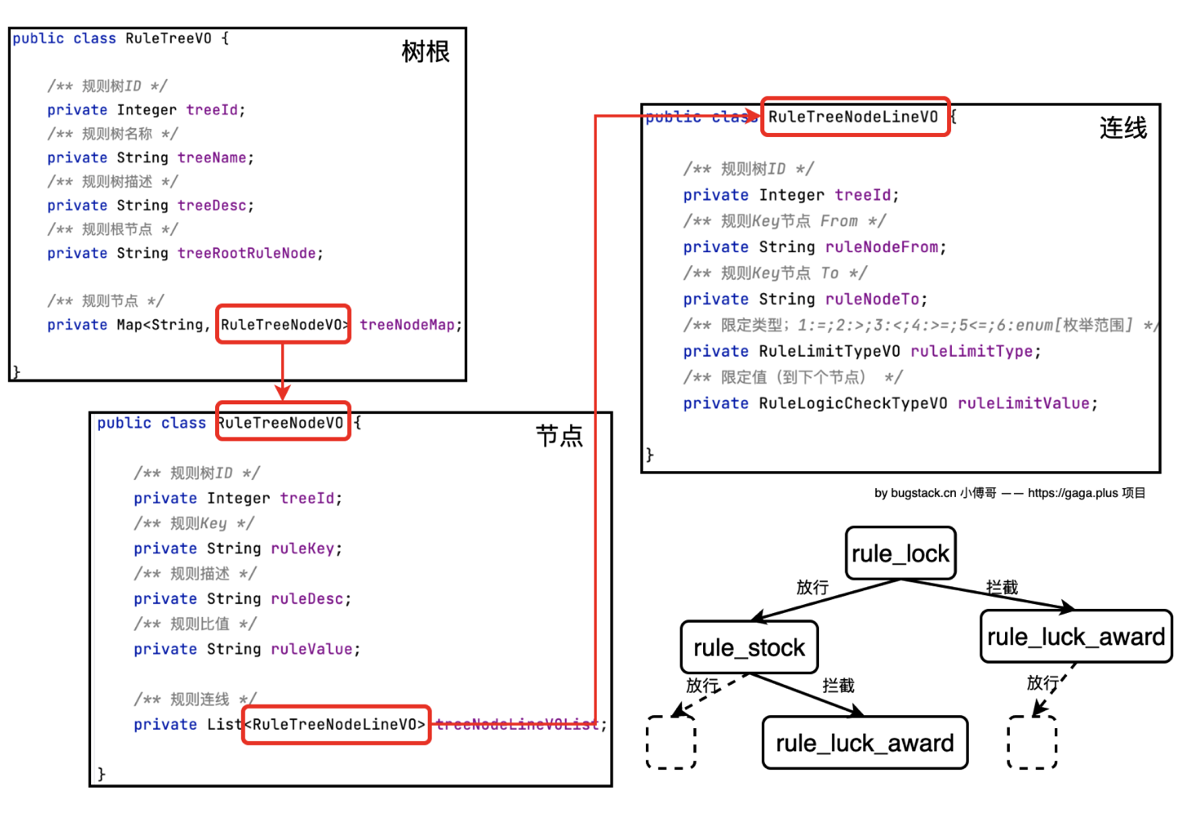
- 为了将这种流程配置化在数据库层面里,而不是写死在业务代码中,我实现了 3 个核心对象
- 树根
RuleTreeVO整颗树的入口,类似于责任链的链头 - 树节点
RuleTreeNodeVO具体的判断节点(库存判断?次数判断?),类似于责任链的 logic 方法 - 树连线
RuleTreeNodeLineVO定义当前节点的跳转逻辑,类似于责任链的 next,如果接管,去左边的路,如果通行,走右边的路
- 树根
- 之后实现一个规则树引擎
DecisionTreeEngine,让上面的静态模型跑起来- start:从 TreeRoot 拿到第一个节点 (比如次数节点)
- Execute:执行当前节点的业务逻辑(库存够不够?抽奖次数够不够?)
- Result:节点返回结果(接管还是允许通行?)
- Next:引擎拿到结果后遍历当前节点伸出去的line 连线。找到匹配的那条线顺着线找打下一个节点如(库存节点)
- Loop:重复步骤,知道走到叶子节点(如直接发奖),流程结束
- 如果后面新增风控拦截,或者 VIP 特权等逻辑分支,只需要重新匹配一下数据库中的节点与连线即可,无需修改核心代码
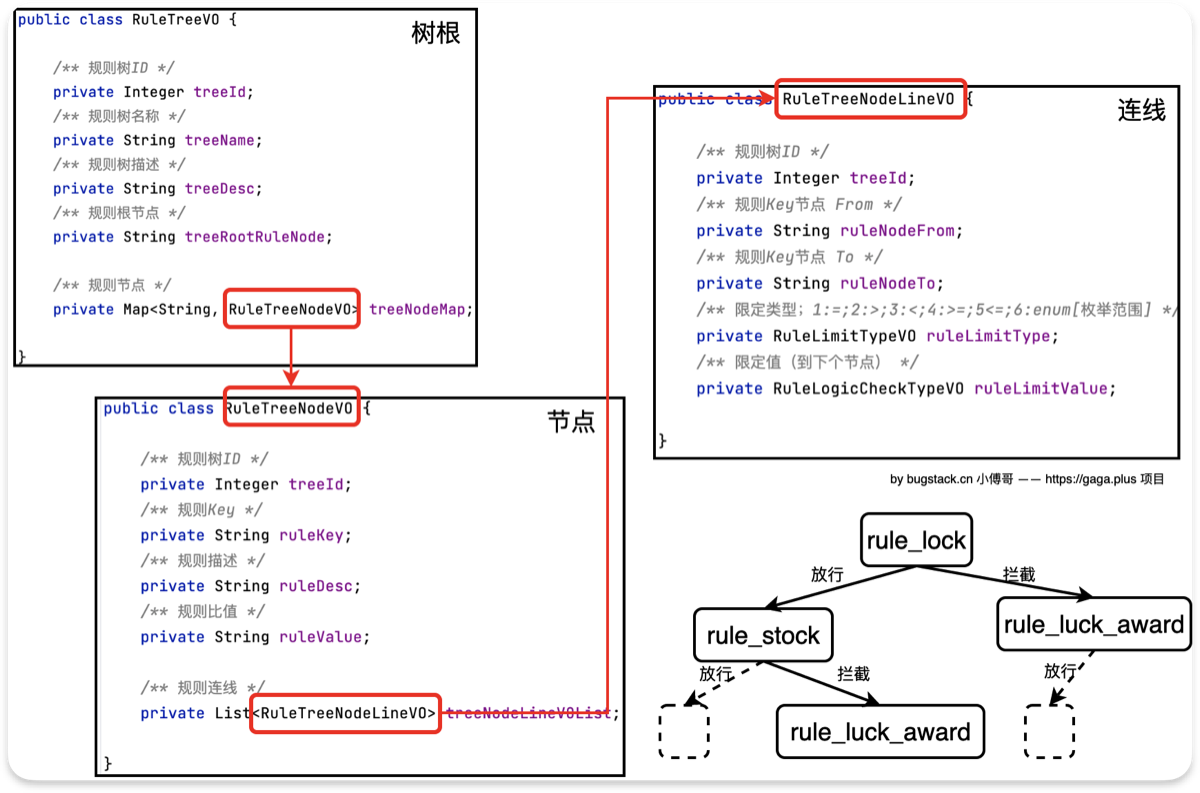
- 具体需要定义的数据结构有
- 树根,核心字段是 treeRootRuleNode,标记决策引擎的初始入口,同时还维护一个 treeNodeMap,所有的子节点都扁平化的存储在这里,方便引擎通过 key 快速找到节点,不需要深度递归查找
- 树节点,每个树节点都代表一个业务规则,包含 rulekey,对应 spring 容器中具体的组件 Bean,还包含 ruleValue,存储该节点的所需的规则解锁阈值(如,需解锁 4 次),还有规则连线List,相当于 next
- 树连线,路由逻辑,定义了一个ruleLimitType:如大于小于等于,目前只有等于。ruleLimitValue:判断(枚举)值,如 allow,takeover。具体的逻辑是,如果当前节点的执行结果,匹配到某条连线的值,引擎就会顺着这个线走到
ruleNodeTo指向的下个节点。 - 总体逻辑看 上面的2 小节
- 14.你提到的规则树(Rule Tree),为什么要用树结构?传统的 if-else 责任链不行吗?
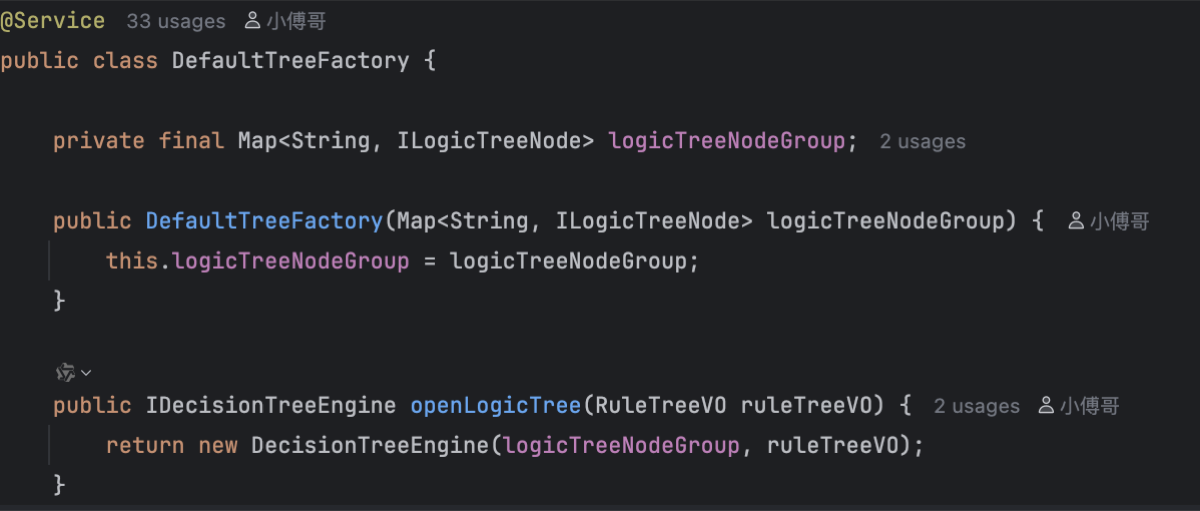
- 工厂类:这里也是需要工厂模式进行自动装配,像策略模式那一集一样,当 spring 启动并初始化
DefaultTreeFactory这个 Bean时,看到构造函数里有一个Map<String, ILogicTreeNode>参数,所以会在容器中找到所有实现了ILogicTreeNode接口的 Bean,将各种树节点收集起来,key 做 component 的指定的名字,value 就是对应的 Bean 实例对象,这时候logicTreeNodeGroup就是一个节点工具箱,谁用谁取,由引擎看着RuleTreeVO(地图)。走到rule_lock节点时,取出 Map 中的单例 Bean,执行逻辑,在顺着连线继续在工具箱找 Bean。 - 规则树引擎类:在传入工具箱 Map 到
DecisionTreeEngine的引擎时,这里是 new 出一个DecisionTreeEngine(logicTreeNodeGroup,ruleTreeVo)因为 树节点 Node是无状态工具类(单例),工厂也是无状态(单例)。但是引擎是有状态的执行者(多例),注意看代码里的private final RuleTreeVO ruleTreeVO;每个引擎对象都绑定一个具体的规则树配置 (VO),比如张三用的是规则树 A,李四用的是规则树 B,不能让张三李四共用同一个DecisionTreeEngine单例 Bean,否则李四的数据会被张三覆盖掉。 因为他们三个的生命周期是不一样的,不能直接把DecisionTreeEngine 作为一个 Bean 交给 Spring 管理,要搞个工厂手动 new
- 为了将这种流程配置化在数据库层面里,而不是写死在业务代码中,我实现了 3 个核心对象
-
到最后,我将整个抽奖流程串联,用模版模式框架住整个抽奖前,中,后的逻辑判断流程
- 之前也是用的模板模式来定义骨架
AbstractRaffleStrategy但是,使用抽奖方法protected abstract void doCheckRaffleBeforeLogic(...)来让继承的子类来实现抽奖前,中后的具体逻辑,在这些具体逻辑内,遍历策略列表,调用一个个 filter(黑名单,权重) - 重构之后,依旧是用模板模式定义骨架,但是不需要定义抽象子类,而是直接调用责任链方法传入用户 id 等信息(由父文件夹中的 repository 查询数据库支撑),然后调用规则树得到最终结果
- 依旧保留骨架“校验用户参数”,“一些经过处理(责任链,规则树)后的到逻辑判断”,“返回最终结果”等。
- 之前也是用的模板模式来定义骨架
9.讲讲抽奖后的的流程?
-
首先考虑到的是,抽奖之后,得到的奖品如何实现不超卖的问题
- 因为不能访问数据库然后根据数据库行锁来解决,这样会导致压力很大,所以我用到了 redis 来实现库存扣减这部分的操作。
- 为保证又快又安全,我使用”redis原子操作+最终一致性”的方案,将核心逻辑封装在规则树的库存节点中。
- 先是用 decr 的原子性来扣减库存,根据返回结果来判断是否可以扣减库存
- 之后进行第二道防线,来兜底,为了防止并发下的数据混乱网络抖动超卖,使用了 setnx 锁(setnx 在 redisson 是用 trySet 实现)来锁住具体的‘库存令牌’如
stock_token_1001_99),确保每个具体的商品库存 id˙ 只能被消费一次。如果后续有回复库存,手动处理,也不会进行超卖- 如果以上都成功,写入延迟队列,延迟消费更新数据库记录(在 trigger 层的 job:
updateAwardStockJob) - 如果都不成功,进入规则树的兜底节点:在数据库配置的 rule_value中取出解析,返回兜底奖品
- 如果以上都成功,写入延迟队列,延迟消费更新数据库记录(在 trigger 层的 job:
- 在延迟队列同步到数据库中时,并没有由 MQ 来完成,而是是用来 Redisson 的
RDelayedQueue来 offer,也就是推入消息。他底层是自动的维护了 ZSet(sorted Set,将执行时间戳为 Scroce ,消息内容为 Member) 结构 启动后台线程来监听队列。因为只需要同步库存,所以轻量化就可以保证。由定时任务,每 5 秒来使用 redis 队列取出相应的数据同步到库存。
-
- IStrategyDispatch 接口新增加了 subtractionAwardStock 接口,最终都是到 StrategyArmoryDispatch 类实现。这样做是为了让功能内聚,既然你提供了库存的装配,策略的装配,也要内聚库存的扣减。
-
之后我们进行抽奖 API 接口的抽取,将抽奖过程完全顺一遍,开门迎客
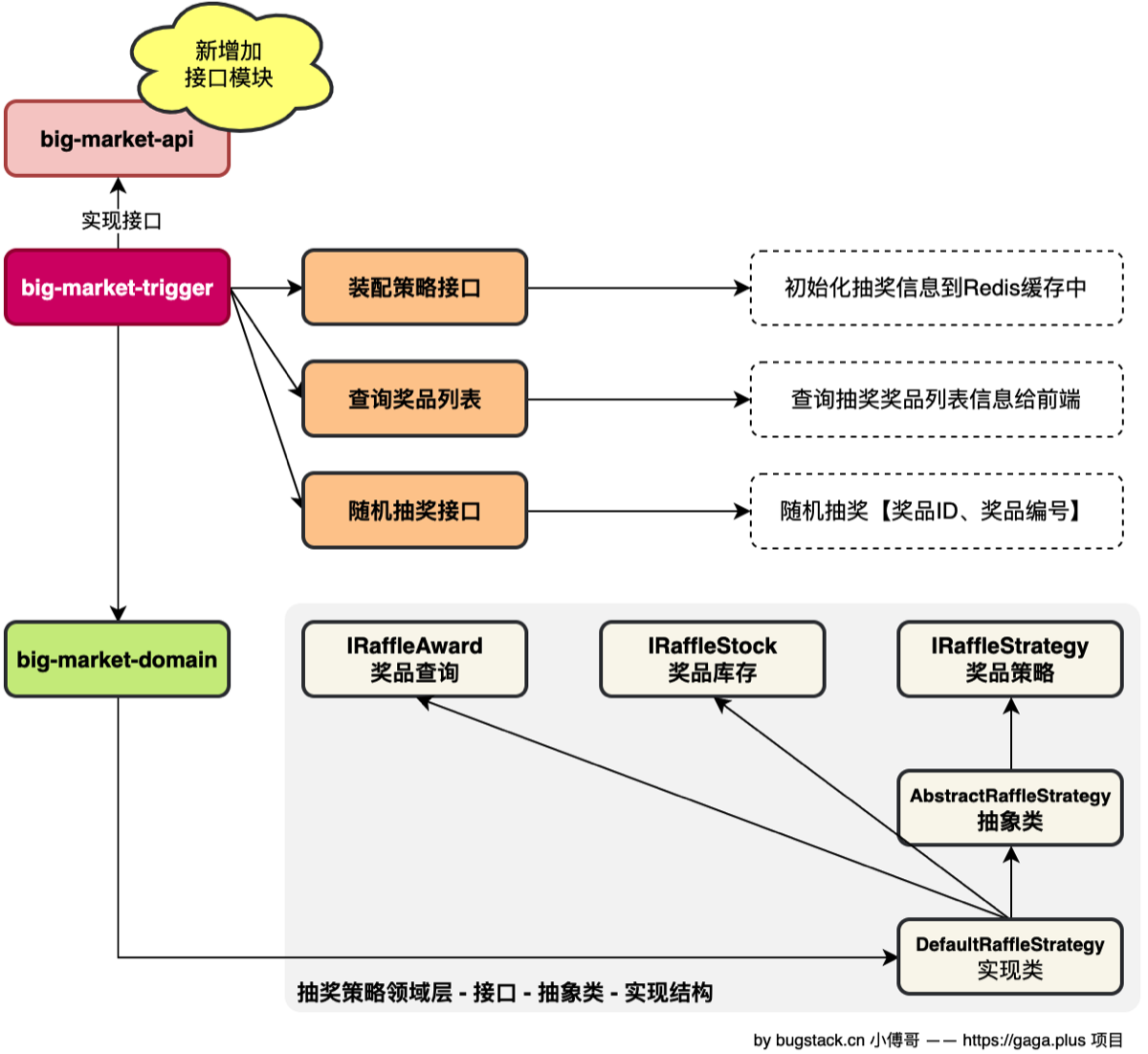
- 我通过 Trigger 层,实现对外 API 的暴露,提供三个核心能力
- 策略装配接口:用于对奖品及其策略的预热,将概率计算加载到 redis 中
- 奖品查询接口:用于前端展示抽奖奖品页面,加入 sort字段来控住展示顺序
- 抽奖执行接口:他是核心接口,用于接收用户的请求,在内部串联调用责任链与规则树,最终返回抽奖结果
- 具体就是在 api 层定义一个接口 IRaffleService 接口,有上面的 Trigger 层 RaffleController 类实现接口,然后调用 Domain 领域层,执行具体逻辑
-
对接好抽奖接口后,我开始将抽奖引擎转化为面向用户的业务系统,关注凭什么用户能抽奖,核心逻辑:将一次抽奖机会看作一次商品,用户参与抽奖的过程,本质就是一个“下单购买商品”的过程
- 以前的逻辑:用户来了,抽奖,得奖品
- 现在在用户抽奖前,引入资格验证
- 验资:用户 A,活动里还有“余额”吗
- 额度限制:不仅有总次数,还有月日次数,比如活动总共能玩 10 次,但是每天只能玩一次。
- 扣费:抽一次,总账户-1,日账户-1
- 下单:系统生成抽奖单,证明用户参与过此活动
- 为了实现步骤 2,我设计了 5 张表
- 活动配置类
- activity 表:定义活动的“壳”,活动 id,名称,抽奖策略等
- activity_count 表:定义活动的“规则”配置,总次数,月,日次数
- 用户资产类
- activity_account:用户的钱包,总剩余,月日剩余→高并发更新的热点表
- activity_order:用户的发票,每次抽奖前,都需生成订单发票,作用:幂等性,如果中间网络抖动,用户重试时,发现订单已存在,就不会重复扣减账户余额,里面有个 state 字段,来表示当前订单是否已完成
- activity_account_flow:银行流水,对账审计
- 活动配置类
-
定义好一些必要的关于奖品入库操作需要的表后,我引入了一个 DB—router 组件,来实现分库分表,来应对这种数据量非常大的情况
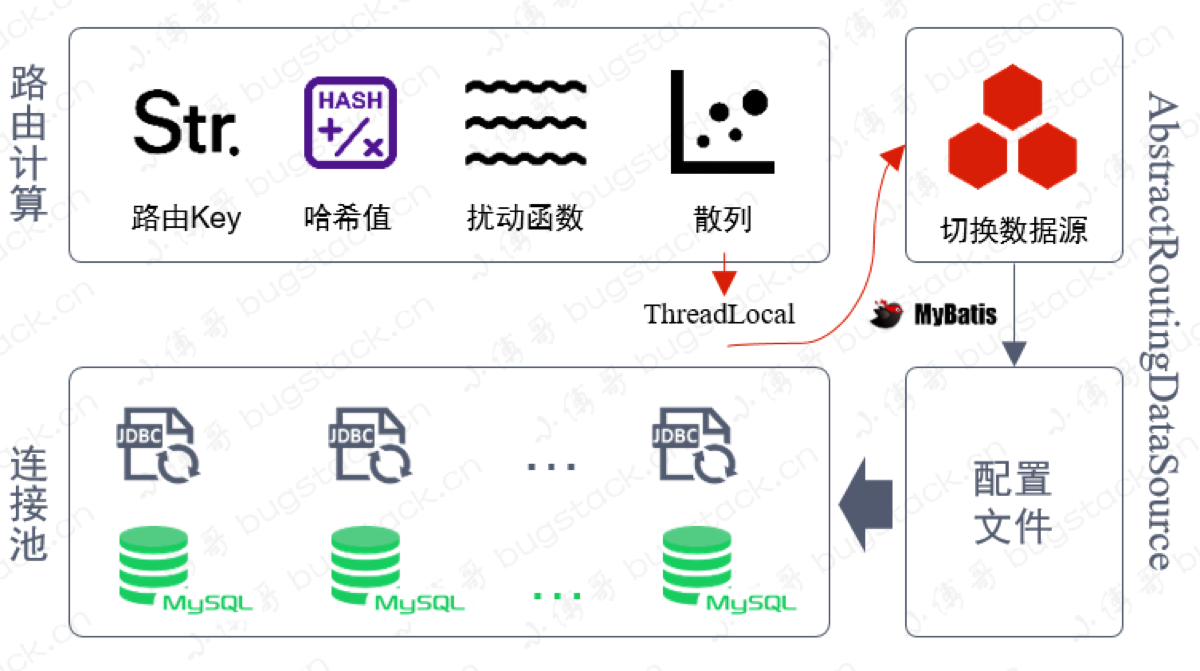
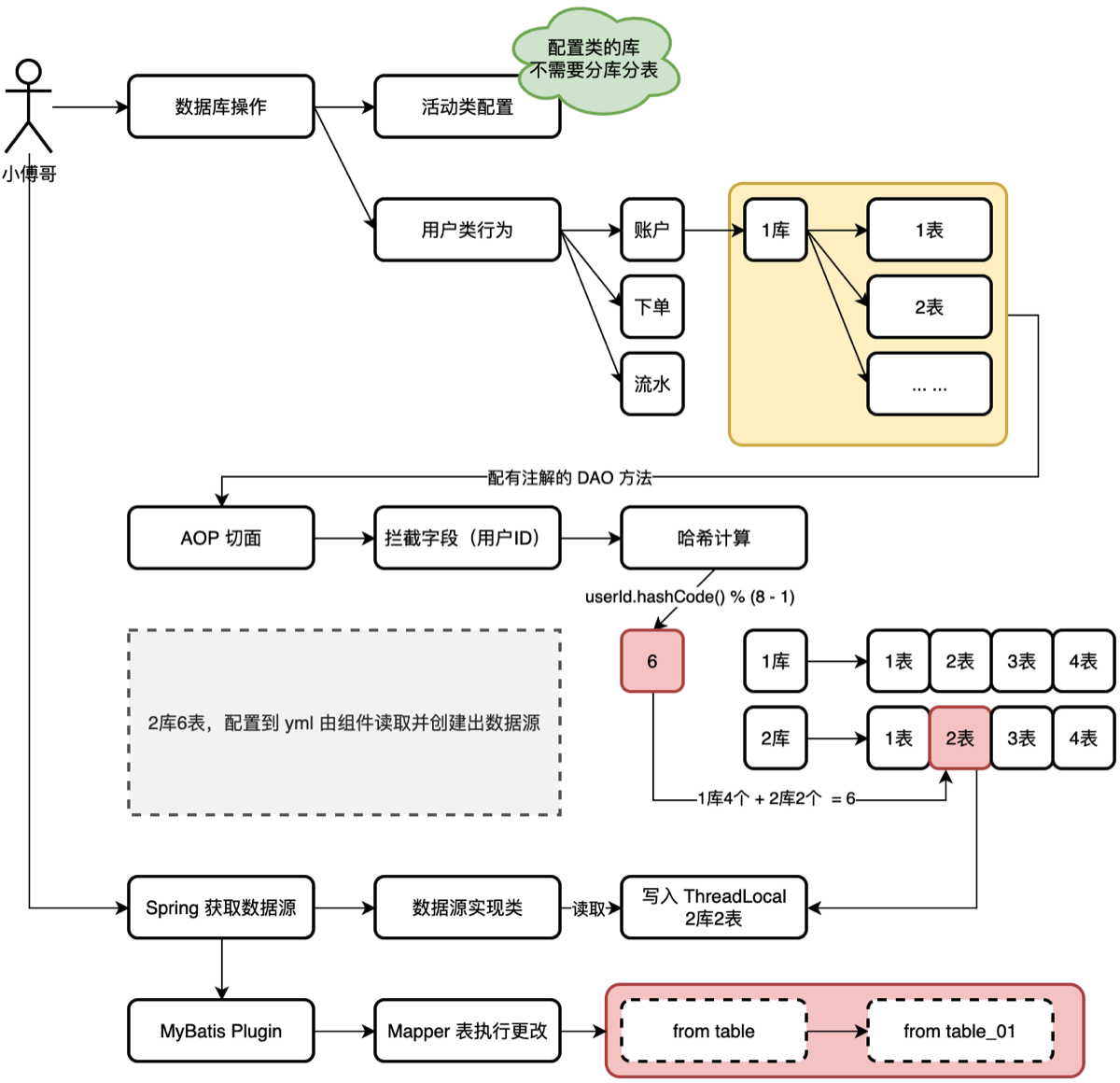
- 核心扰动函数算法原理:HashMap 的扰动函数散列算法
i. 公式:
idx = (size - 1) & (hashCode ^ (hashCode >>> 16))。先算出总格子数,在扰动,在根据总格子数取余 1. 这里直接复用了 JDK 的 HashMap 的源码实现 2. 单纯的 hashCode 可能不够散列(特别是低位重复时),所以让高 16 位也参与运算,增加随机性 3. 最后通过& (size - 1)等价于取模,但效率更高 (前提是库表总数必须是 2 的 N 次幂) 4. - 算出总索引idx后,再拆分为: -dbIdx(库索引) =idx / tbCount + 1。 -tbIdx(表索引) =idx - tbCount * (dbIdx - 1)。 - 这里想象成两个库,一个库 4 个表,一共 0~7 张表,库索引取整,表索引取余找出库中的表的相对位置 - 整个过程对开发者透明,流程如下
- 切入点:定义一个
@DBRouter注解,AOP 拦截所有带有该注解的 DAO 方法。 - 路由算法,见 3
- 上下文传递:计算出的库表索引被存入 TreadLocal 中
private static final ThreadLocal<String> dbKey = new ThreadLocal<String>();- 库:
DynamicDataSource重写它的determineCurrentLookupKey()读取 ThreadLocal 中的库索引,动态切换 JDBC 连接。 - 表:~~MyBatis 通过动态 SQL(
${tbIdx})或者插件读取 ThreadLocal 中的表索引,替换真实的表名。~~实际上是通过拦截器模式,拦截器直接找到 TreadLocal 要表索引,然后在 sql 语句通过正则表达式匹配到关键语句,通过反射修改 sql 语句替换表索引
- 库:
- 最后clearTreadLocal!
- 切入点:定义一个
-
完成基础的必要的表的建立后和分库组件后,我开始重构用户抽奖下单的这个动作:因为用户获取抽奖次数来源是不同的,是签到?还是 VIP?还是积分兑换?来源不同的库存和规则很难写在同一张活动表上,所以我们进行库存架构的重构解耦,将抽奖次数包装为 SKU库存量单位 ,下单必须购买一个 SKU,SKU 可以来源不同
- 新增一个 activity_SKU表,不在总活动表中添加库存了,也不在总活动表添加每天每月的配置了,而是讲这些单独放在 SKU 表中,用活动 id与次数id 与其他两个表相连
- 将流水表合并到订单表
- 完成表的重构后,定一个一个下单模板抽象类createOrder,(参数校验,查询基础信息,规则过滤,构建聚合对象,保存订单)
- 具体的下单流程:用户触发行为,如点击抽奖,或支付成功回调,根据用户的行为拿到 SKU,然后查询两个表参数校验,然后就是上面的后面。
- 参数校验,使用责任链(活动的:有效期、状态)(商品库存的:有效期、状态、库存(sku))
- 落地实现:使用IactionChain接口,通过 ActionChainFactory 组装校验链,因为固定,所以直接构造时确定顺序
- 之后就是构建聚合对象(扣减额度,写入订单表需要的数据)
- 下单(重要)
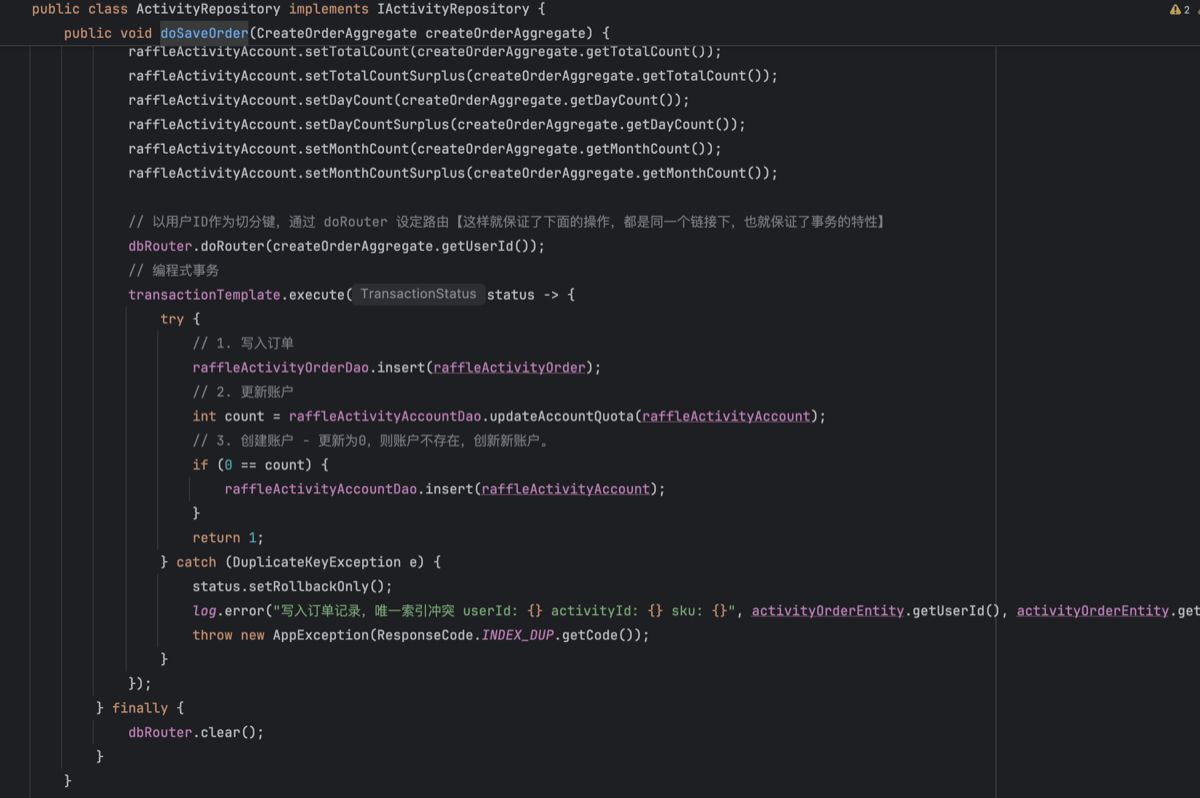
- 使用 db-router 组件:调用
dbRouter.doRouter(userId),根据用户 id 算出他属于哪个库,存入当前的线程中,然后自动知晓库和表 - 之后开启编程性事务:transactionTemplate.excute(。。。),更细粒度的控制路由清理和异常处理,而放弃事务注解
- 写入两张表:订单表和额度表
- 使用 db-router 组件的 clear 方法,实际就是清理 TreadLocal
- 为了这个流程有重复下单的情况,我们在数据库建立了唯一索引字段,上游必须传入一个唯一单号,根据报错与否来保证幂等性
-
在确定下单流程与写入数据库的流程后,我之后解决了写入数据库的问题,因为使用到 redis,要保证 SKU 库存一致性,必须引入 MQ,核心思想:redis 抗压(原子扣减)+延迟队列做同步(最终一致性)+MQ 处理售罄(最后的通知)
- redis 和延迟队列(redission)复用当时扣减奖品库存那一段
- 多出一个库存耗尽的”熔断”处理
- 当redis decr 处理时,返回值小于 0时,发送一个 MQ 消息,消费者:
ActivitySkuStockZeroCustomer。目的是通知数据库立马把库存设置为 0,之所以这里不同延迟队列,为了拦截后续可能穿过缓存层的查询请求,并用于展示前端已抢光 - 具体工程落地:在Trigger 层新增一个 MQ 监听器(
Listener),当收到库存归零后,调用数据库操作清零 - redisson 的延迟队列的任务是减负,即使丢到几个中间状态也没事,只要最终一致性就行,这里的 MQ 用于状态通知,利用率解耦和广播能力
- 当redis decr 处理时,返回值小于 0时,发送一个 MQ 消息,消费者:
-
最后,我完成写入中奖记录和 task 任务表(用于 mq补发)
- 首先设计六张表
- 总用户活动账户,月,日用户活动表
- 用户抽奖订单表(这里与活动订单表区分开,那个是抽奖前(SKU 的下单)
- 用户中奖记录表与任务补发表
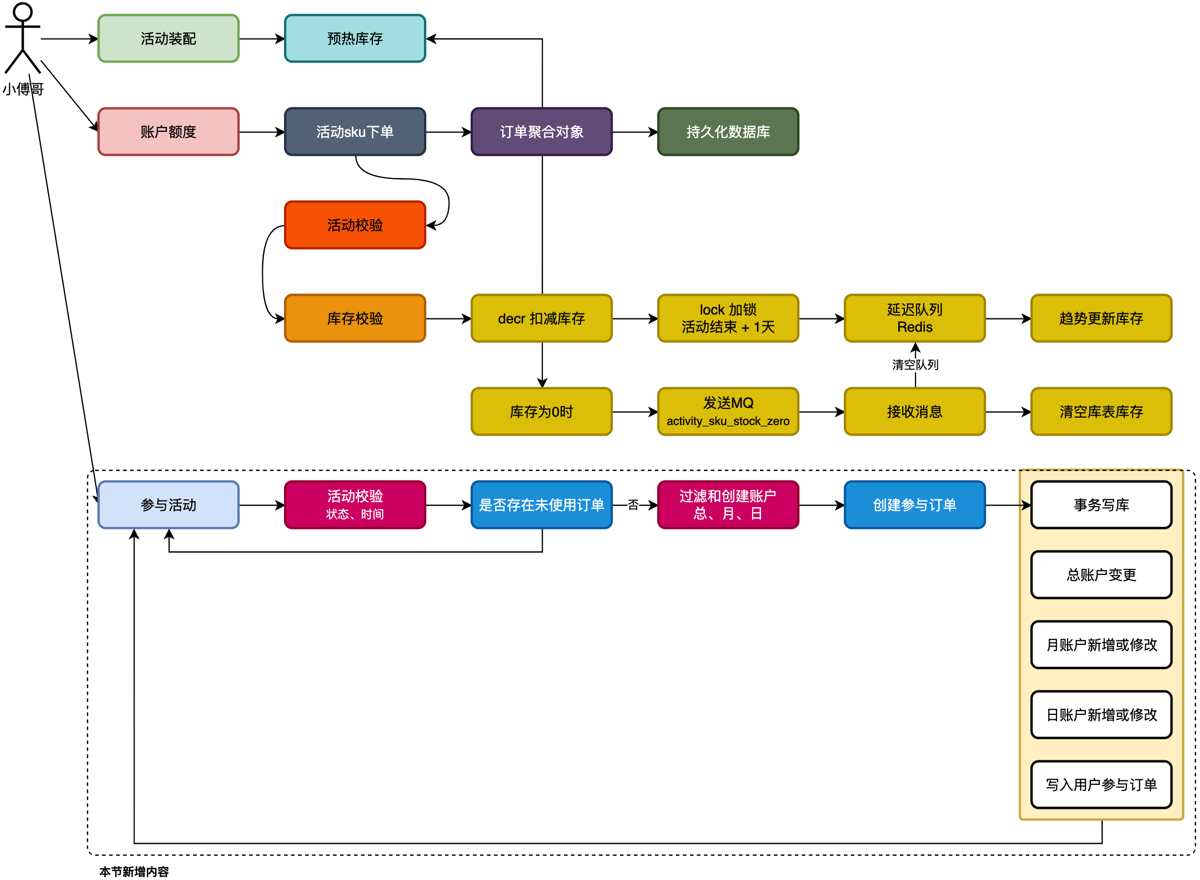
- 创建完表后,总结并细分一下活动领域
- 装配 Armory
- 预热活动 SKU ,活动信息,信息到 redis
- 充值 Quota(creatOrder1)
- 就是上面的下单 SKU 写入库存
- 参与 Partake(creatOrder2)
- 本节重点,证明用户这一次抽奖是合法的,与上面购买单区分开
- 流程 :检验用户在这个活动下有没有账户,总,月,日额度是否充足
- 之后创建订单方法内,参考购买单(dbrouter,事务 execute,db-clear()),事务写库,总账户变更(直接 update),日月账户(insert或 update(懒加载,不用每天维护每日限额表))。写入订单表(以上四个表是在同一个事务中)。期间捕捉异常 status.setRollbackOnly();
- 装配 Armory
- 首先设计六张表
-
最后的最后。使用 MQ 扫描 Task 表补发奖品。(写入用户中奖记录的同时写入 task 任务表,并初始化状态字段为待发放)这里没用 redisson 延迟队列,因为场景和一致性目标完全不同。这里不同查询数据库更改数据库,而是追加写入,无竞争。这里的一致性是指“中奖记录(DB)与发奖动作(MQ)的一致性”
- 场景:用户中奖后,通常需要调用外部接口(物流?发券系统?),如果在同一个数据库事务里调用 RPC 接口,一旦出现网络问题,数据库事务回滚,用户看到界面显示抽到 Iphone,但中奖记录没有(或者发货系统没有)
- 解决方案:将“中奖记录”与“实际发货”分开,先 DB,再 MQ 异步执行(MQ 的发送在写入中奖记录的事务后)
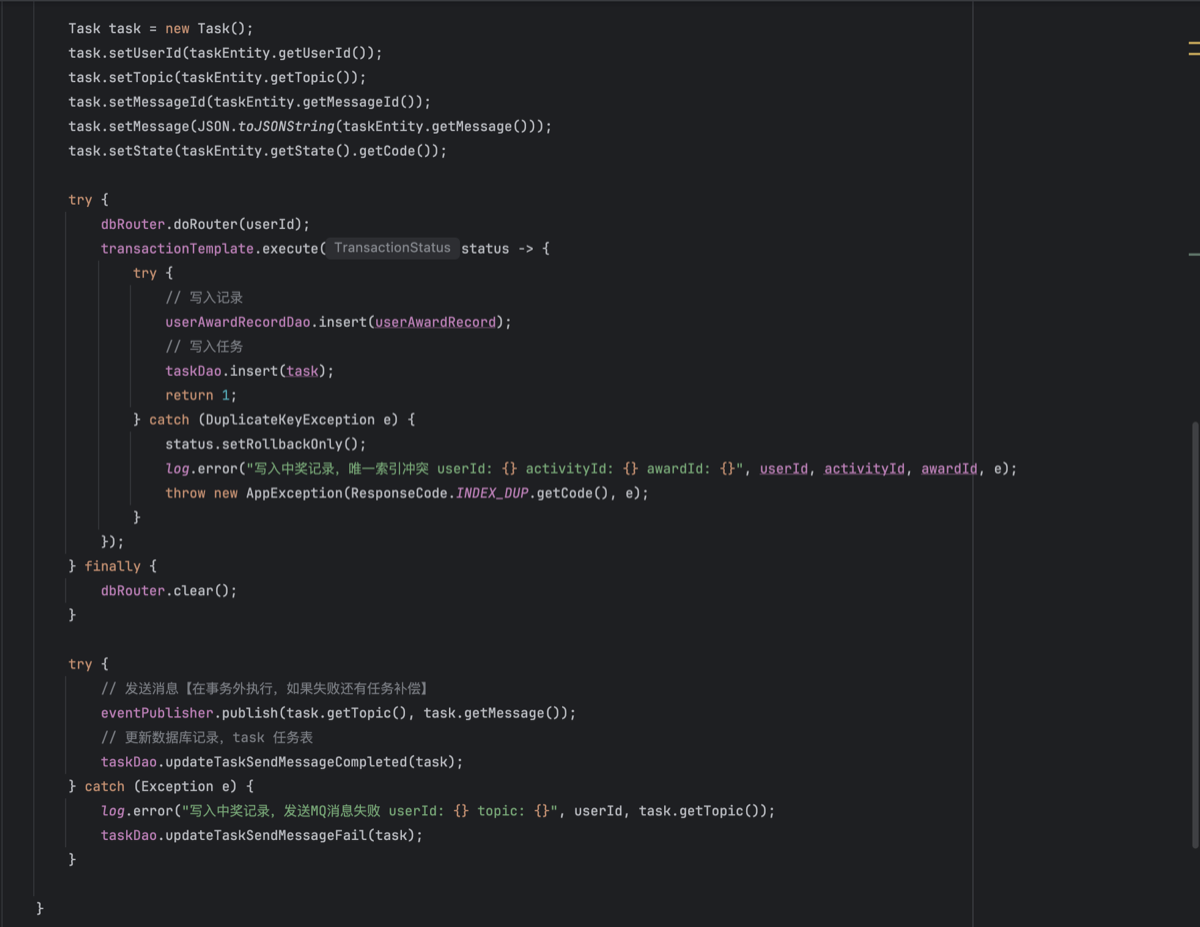
- 所以这里 MQ 的作用是对接未来的发货系统或者别的微服务,让他们来监听这个 MQ,监听到后,返回给 MQ ACK,这时 MQ 改写 TASK 任务表对应的数据状态为✅
- 保底:用定时任务每五秒扫描发送失败的中奖记录
- 工程实现:细化 domain 领域的 award 模块(中奖的核心业务,调用 task 模块创建任务)与 task 模块(只负责存任务,发 MQ,扫表重传)。在 trigger 层,添加一个未来别的服务的消费者 Listener,在添加一个定时扫描的任务类在 job 包内(任务类:dbrouter 读取库的数量,每个库都有一张表。for 循环查出待发送消息,executor.execute(()→ { 发送 MQ,改状态}))CallerRunsPolicy 让提交任务的线程自己跑,避免任务丢失,报错,降速。3.有线程池参数设置的经验吗?36.讲一下项目中的基于分片的多线程同步组件
10.整体怎么运作的?
11.一致性问题
- 分布式系统中,redis 挂了,mq 丢消息怎么办,如何保证用户抽奖扣的次数且能一定发奖?
关于一致性,在这个抽奖系统中,我重点解决的是库存扣减和发奖的一致性。
-
库存侧: 我没有直接依靠DB事务抗高并发,而是用 Redis
decr做原子扣减,同时用setnx加锁做兜底,防止超卖。库存的同步是异步的,通过 Redisson 延迟队列更新数据库,保证最终一致性。 -
发奖侧(重难点): 针对发奖可能涉及第三方接口(网络抖动)的问题,我采用了**‘本地任务表 + MQ’**的方案(文档第19节)。
-
我在事务中同时写入‘中奖记录’和‘Task任务表’(状态为待发送)。
-
事务提交后,再发送MQ。
-
如果MQ发送失败,我有定时任务(Xxl-job)扫描Task表进行重试补偿。
-
这保证了即使MQ挂了,用户中奖的数据也不会丢,做到了至少投递一次(At-least-once)。”
12.高并发问题
- QPS一高,你的系统哪里先挂?数据库分库分表是怎么做的?(分治思想+缓存前置 )
“高并发场景下,数据库通常是瓶颈。
-
读写分离与分库分表: 我自研了一个基于
ThreadLocal和 AOP 的轻量级DB-Router组件(文档第13节)。通过对 UserID 进行哈希扰动(参考了 HashMap 源码(size-1) & hash),将数据分散到 2库 4表(举例)中,大幅降低了单表压力。 -
无锁化设计: 在扣减库存时,我避免了数据库行锁,而是全量依赖 Redis。特别是在库存耗尽时(文档第16节),我设计了一个 ‘库存熔断’ 机制:当 Redis 返回 -1 时,直接触发 MQ 消息通知数据库同步清零,并拦截后续所有请求,防止流量打穿到 DB。”
13.AI提效
-
场景一(代码重构): “在做规则树引擎(Decision Tree)时,逻辑比较复杂。我利用 Cursor/GitHub Copilot 帮我生成了基于组合模式的代码骨架,并让 AI 帮我设计了
RuleTreeNode的数据结构,这让我的开发效率提升了 30%。” -
场景二(单元测试): “C端业务对稳定性要求高。我利用 AI 快速生成了全链路的单元测试用例,特别是针对 Redis Lua 脚本的边缘测试(比如库存为 1 时的并发扣减),AI 帮我构造了很多我没想到的边界条件。”
14.你提到的规则树(Rule Tree),为什么要用树结构?传统的 if-else 责任链不行吗?
public DefaultStrategyAwardVO process(String userId, Long strategyId, Integer initialScore) {
// 1. 找到根节点 (rootNode)
String nextNodeKey = ruleTreeVO.getTreeRootRuleNode();
Map<String, RuleTreeNodeVO> treeNodeMap = ruleTreeVO.getTreeNodeMap();
// 2. 拿到根节点对象
RuleTreeNodeVO currentNode = treeNodeMap.get(nextNodeKey);
// 3. 循环遍历(只要还有节点就一直走)
while (null != currentNode) {
// A. 执行当前节点的逻辑(调用 Spring 注入的 LogicFilter)
// 比如:判断库存、判断次数
ILogicTreeNode logicTreeNode = logicTreeNodeGroup.get(currentNode.getRuleKey());
String logicValue = logicTreeNode.logic(userId, strategyId, currentNode.getRuleValue());
// B. 核心:根据逻辑返回的值(ALLOW/TAKE_OVER),找连线(Line)
String nextKey = nextNode(logicValue, currentNode.getTreeNodeLineVOList());
// C. 如果找到了连线指向的下一个节点 Key,就更新 currentNode 继续循环
// D. 如果没找到,说明到头了(或者被拦截了),返回当前节点的处理结果
currentNode = treeNodeMap.get(nextKey);
}
return ...;
}
责任链的组装与调用
理由: 责任链的精髓不在于 next() 方法,而在于链条是如何串起来的。 参考: 文档第7节。
口述/手写重点:
如何组装: “我在 DefaultChainFactory 中,从 Map 中拿到所有的 Bean(黑名单、权重、默认),然后手动用 appendNext() 把它们串成一个链表:BlackList -> Weight -> Default。”
如何调用: “我在 performRaffle 抽奖主入口,直接调用链头的 logic() 方法。它会自动向下传递,直到有人接管(TAKE_OVER)或走完默认流程。”
-
-
痛点: 责任链(Chain)适合线性流程(如:黑名单 → 权重 → 默认)。但抽奖中/后期的逻辑是分叉的(例如:库存充足走A路,库存不足走B路;次数解锁满足走C路,不满足走D路)。
-
方案:
if-else会导致代码极其臃肿难以维护(“面条代码”)。 -
实现: 我参考了组合模式,设计了
TreeRoot、TreeNode、TreeLine。这就把业务逻辑的编排从代码层面上移到了数据层面(数据库配置)。运营如果想调整规则顺序,我不需要改代码发版,只需要改数据库配置即可。
-
-
15.你说你设计了 DB-Router 分库分表组件,为什么不用 Sharding-JDBC?
-
“我知道 Sharding-JDBC 功能很强大,但它比较重,且作为一个实习生项目,我想深入理解分库分表的底层原理。
-
我的 DB-Router 更加轻量级。我通过自定义注解
@DBRouter+ AOP 切面,配合ThreadLocal传递路由 Key(UserID),在AbstractRoutingDataSource层动态切换数据源。 -
虽然功能不如 Sharding-JDBC 全面,但对于目前的业务场景(基于 UserID 的哈希分片)已经足够高效,且让我彻底搞懂了 Spring 事务管理和数据源切换的机制。”
16. Redis与 Mysql 长期不一致
“关于 Redis 库存扣减,如果 Redis 扣减成功了,但是 MQ 发送失败了(延迟同步数据库失败),导致 Redis 和 DB 数据长期不一致,怎么解决?”
-
这就是在考你兜底机制。
-
回答: “首先,Redis 是主数据,C端展示以 Redis 为准,短期不一致是可以接受的。其次,为了防止长期不一致,我有一个定时任务(Xxl-job)。它会定期扫描数据库中的库存水位,并与 Redis 进行核对(或者全量同步),如果发现偏差超过阈值,会进行报警人工介入,或者以数据库的库存为基准进行回滚/修正。”
17.redis 挂了怎么办
“你的库存全在 Redis 里,Redis 崩了,流量瞬间打到 MySQL,数据库必死。你的系统怎么活?”
第一层:架构级高可用(基建)
“首先,在基础设施层面,生产环境通常采用 Redis Sentinel(哨兵) 或 Redis Cluster(集群) 模式。 如果主节点挂了,哨兵会自动进行主从切换(Failover),应用层感知到新主节点后继续工作。这能解决大部分单点故障。”
第二层:应用级降级(重点!体现你的业务思考)
“但是,作为开发,我必须考虑极端情况(比如整个 Redis 集群不可用,或者网络抖动)。 针对抽奖这种高并发场景,绝对不能直接回源查数据库,否则 MySQL 会瞬间被打挂,导致整个站点雪崩。
我的方案是 ‘熔断 + 本地缓存兜底’:
熔断(Circuit Breaker): 引入 Sentinel 或 Resilience4j。当检测到 Redis 异常率飙升时,触发熔断,直接拦截后续请求,返回‘当前排队人数过多’,保护数据库。
本地缓存(Local Cache): 对于活动配置、白名单等读多写少的数据,我在应用层加了 Guava/Caffeine 本地缓存。即使 Redis 挂了,核心配置还能读到,保证基本页面能打开,只是不能抽奖。
有损服务: 如果必须保证服务可用,可以开启‘降级模式’,只允许小流量通过,或者只允许白名单用户抽奖,直接走数据库,放弃高并发能力,保住核心业务不宕机。”
第三层:事后恢复(数据一致性)
“Redis 恢复后,因为它是异步写库的,可能存在 Redis 数据丢失(AOF/RDB没来得及落盘)。 这时候需要运行我的 ‘库存校对任务’(你文档里的 Xxl-job),以 MySQL 的记录为准,将剩余库存重新预热加载回 Redis,使系统恢复正常。”
18.Lua 脚本的“原子性”陷阱
“你用了 Lua 脚本扣减库存。Redis 的 Lua 脚本执行是原子性的,但如果脚本逻辑很复杂,执行时间过长(比如超过 100ms),会发生什么?”
“Redis 是单线程模型。如果 Lua 脚本执行太慢,会阻塞后续所有命令的执行(Get/Set 都进不来),导致 Redis 假死。 我的优化:
-
严格控制 Lua 脚本的逻辑复杂度,只做最简单的比较和扣减,不写循环。
-
在脚本中只传递必要的 Key,避免在大 Key(如包含几万个元素的 Hash/Set)上操作。
-
(进阶)如果必须处理复杂逻辑,我会拆分为多次请求,或者在应用层做预校验。”
19.关于分库分表的“扩容”难题
- “你现在是 2库4表。如果业务发展太快,不够用了,要变成 4库8表,怎么做数据迁移?怎么保证不停机?”
“这涉及在线平滑扩容,通常分四步走:
-
双写阶段: 修改代码,所有新数据同时写入旧库和新库(以旧库为准)。
-
存量迁移: 跑一个脚本,后台把旧库的历史数据搬运到新库(遇到双写更新的数据,以最新时间戳为准)。
-
校验阶段: 抽样对比新旧库数据,直到数据完全一致。
-
切换阶段: 将读流量切到新库,观察稳定后,停止双写,下线旧库。”
20.关于“幂等性”的极限拉扯
-
“用户手抖,1秒钟点了 10 次抽奖。你如何防止他抽 10 次?如果他用了连点器(脚本),你的前端防抖没用,后端怎么防?”
-
基于 Redis 的分布式锁:
setnx lock_key_uid_activityId。 -
数据库唯一索引: 在
user_strategy_export表中,user_id + activity_id + order_id建立唯一索引。即使 Redis 锁失效,数据库也会报DuplicateKeyException,保证最后一道防线不被击穿。
21.日志组件是怎么做的
“我实现的实时日志组件利用了 Logback 的扩展机制。通过继承 AppenderBase 并重写 append 方法,我将自定义组件挂载到了 Logback 的事件分发链上。
这种设计的优势在于完全的非侵入性:它利用了框架的观察者模式,在日志框架进行事件分发时异步捕获 ILoggingEvent。同时,我配合 logback-spring.xml 中的 Root 级别配置和异步 Appender 包装,确保了日志采集过程不会阻塞主业务线程,实现了业务逻辑与监控逻辑的彻底解耦。”
- 什么是 WebSocket?(通俗理解)
-
普通 HTTP(外卖小哥): 你(客户端)打个电话问:“我的外卖到了吗?”小哥(服务端)说:“还没。”然后挂了。你想知道进度,得不停地打电话问(轮询)。
-
WebSocket(专属对讲机): 你和小哥建立了一个持久的通话频道。小哥一边骑车一边对着对讲机喊:“我出发了”、“我过红绿灯了”、“我到门口了”。服务端可以主动推消息给你,不用你问。
- 你的项目是怎么做这个日志功能的?
在你的“大营销平台”项目中,我们并没有用它做业务提醒,而是做了一个**“实时性能/监控中心”**。它的链路是这样的:
-
后端拦截(Logback Appender):我们写了一个钩子,每当 Java 代码打印一条日志时,Logback 会分身出一份数据给我们的
WebSocketAppender。 -
实时发射(WebSocket Server):后端通过 WebSocket 管道,把这行日志像射箭一样射向前端。
-
前端缓冲(React Buffer Queue):前端收到后,为了不让页面闪瞎眼,先存进一个“小仓库(队列)”,然后按你刚才要求的频率(比如 150ms)一行行优雅地吐出来。
这就是把“死”的服务器文件日志,变成了“活”的可视化流数据。
💡 面试官可能会追问:
-
问: “为什么不用 HTTP 轮询看日志?”
-
你: “HTTP 轮询会有大量无效请求,且实时性差。而日志是流式数据,WebSocket 的长连接特性不仅能节省服务器开销,还能达到‘所见即所得’的实时效果,这对于监控高并发系统的瞬时状态至关重要。”
-
根目录
pom.xml:在<dependencyManagement>中声明版本(如果你有版本管理习惯)。 -
big-market-app模块的pom.xml:这是最重要的。app模块是整个 Spring Boot 的运行入口,它负责把所有模块组合起来并启动 Web 容器。
操作: 打开 big-market-app/pom.xml,添加以下内容:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-websocket</artifactId>
</dependency>这个日志实时监控组件,本质上是为你原本“静止”的后端系统安装了一个**“直播摄像头”**。
在传统的开发中,后端日志是写在服务器的文件里的(比如 app.log),你想看日志得去连服务器执行 tail -f。而这个组件的作用,就是把这些本该写入文件的日志,实时地通过网络“发射”到你的浏览器控制台上。
为了让你在面试时能讲得透彻,我们把它拆解为三个核心角色:
1. 核心角色:谁在干活?
我们可以把这个过程比喻成一个**“快递配送系统”**:
-
WebSocketAppender(情报员):它潜伏在 Java 的日志框架(Logback)里。每当你的代码执行
log.info("用户开始抽奖")时,它就会第一时间跳出来,把这条消息复制一份,交给配送中心。 -
LogWebSocketHandler(配送中心):它负责管理所有的连接。当你的前端页面打开时,它会维持一个“长连接”管道。收到情报员的消息后,它会顺着管道把消息推送到前端。
-
LogConsole(收件人):这是你前端写的 React 组件。它像一个等温箱,实时接收消息,并一行行地显示在屏幕上,还负责自动滚动。
2. 数据的“生命周期”:日志是怎么飞过去的?
-
产生:后端执行业务逻辑,调用
log.info()。 -
拦截:
WebSocketAppender拦截到这条日志事件。 -
加工:它把时间、日志级别(INFO/ERROR)、内容封装成一个字符串。
-
传送:调用
LogWebSocketHandler.sendLog(),通过 WebSocket 协议,将数据从云服务器的 Docker 容器中传出。 -
渲染:前端
onMessage接收到字符串,更新 React 的state,页面实时刷新。
好的,我们现在深入到 Java 后端,看看这套“日志直播系统”在服务端是如何运转的。
在 DDD(领域驱动设计)架构中,这套功能的实现体现了典型的基础设施适配和解耦思想。我们按日志流动的顺序,分三块来讲解:
1. 拦截器:WebSocketAppender.java (基础设施层)
它的角色: 潜伏在日志框架里的“间谍”。
public class WebSocketAppender extends AppenderBase<ILoggingEvent> {
@Override
protected void append(ILoggingEvent eventObject) {
if (eventObject != null) {
// 1. 格式化日志:从事件对象中提取时间戳、级别、线程名、消息内容
String log = String.format("%d [%s] %s - %s",
eventObject.getTimeStamp(),
eventObject.getLevel().levelStr,
eventObject.getThreadName(),
eventObject.getFormattedMessage());
// 2. 关键动作:把加工好的字符串交给“广播员”发送出去
LogWebSocketHandler.sendLog(log);
}
}
}- 面试点: 它是继承自 Logback 的
AppenderBase。这意味着它不需要你在业务代码里写任何一行代码,只要配置了 XML,系统所有的log.info都会自动流经这里。这叫非侵入式设计。
2. 广播员:LogWebSocketHandler.java (触发器/适配器层)
它的角色: 负责管理对讲机频道(连接)并喊话。
public class LogWebSocketHandler extends TextWebSocketHandler {
// 🌟 线程安全的 Set:保存所有当前连接着网页的“听众”
private static final Set<WebSocketSession> sessions = new CopyOnWriteArraySet<>();
@Override
public void afterConnectionEstablished(WebSocketSession session) {
// 网页打开,握手成功,把这个连接存起来
sessions.add(session);
}
@Override
public void afterConnectionClosed(WebSocketSession session, CloseStatus status) {
// 网页关闭,把连接移除,防止内存泄漏
sessions.remove(session);
}
// 🌟 核心方法:由 Appender 调用,群发日志
public static void sendLog(String message) {
for (WebSocketSession session : sessions) {
if (session.isOpen()) {
try {
// 顺着管道把字符串射向前端
session.sendMessage(new TextMessage(message));
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}- 面试点: 为什么用
CopyOnWriteArraySet?因为日志推送非常频繁,而用户的连接/断开是随机的。这个类保证了在多线程环境下,遍历发送日志和增加/删除连接不会发生冲突(并发安全)。
3. 总机:WebSocketConfig.java (配置层)
它的角色: 告诉 Spring 哪个电话号码(URL)对应哪个服务。
@Configuration
@EnableWebSocket // 开启 WebSocket 功能
public class WebSocketConfig implements WebSocketConfigurer {
@Override
public void registerWebSocketHandlers(WebSocketHandlerRegistry registry) {
// 映射路径:前端通过 ws://IP:端口/ws/log 就能连上
// setAllowedOrigins("*"):解决跨域问题,允许前端跨服务器访问
registry.addHandler(new LogWebSocketHandler(), "/ws/log").setAllowedOrigins("*");
}
}4. 激活开关:logback-spring.xml
它的角色: 启动“间谍”的指令。
<appender name="WEBSOCKET" class="cn.bugstack.infrastructure.adapter.WebSocketAppender" />
<root level="info">
<appender-ref ref="CONSOLE" /> <appender-ref ref="WEBSOCKET" /> </root>💡 总结这个 Java 后端设计的亮点(面试必杀技)
当你面对面试官讲解这段 Java 代码时,一定要提到以下三个关键词:
-
观察者模式 (Observer Pattern):
Logback框架是主体,我们的WebSocketAppender是观察者。每当有日志产生,主体就会通知所有观察者。这种设计让日志推送功能与业务逻辑完全解耦。
-
异步化处理思想:
- 如果在 XML 里配置了
AsyncAppender包裹我们的WEBSOCKET,那么日志推送就会在独立的线程池中运行。即便 WebSocket 推送网络卡顿,也绝对不会影响主业务(比如抽奖)的执行速度。
- 如果在 XML 里配置了
-
单例与静态通信:
- 通过静态方法
LogWebSocketHandler.sendLog实现 Appender(底层工具)与 Handler(网络接口)的通信,这在日志这种全局单例的场景下非常高效。
- 通过静态方法
这套后端代码配合你前面优化的“匀速滴落”前端逻辑,构成了一个完整的“高并发日志观测方案”。
你现在回头看你的 pom.xml 和目录结构,是不是觉得这些代码放的位置(Infrastructure 和 App/Trigger 层)非常有道理了?
3. 为什么这个东西在简历上“很值钱”?
作为一个找实习的学生,面试官看中的不是你用了什么框架,而是你解决问题的工程思维。你可以从以下几个维度去“吹”:
| 维度 | 你的技术亮点 |
|---|---|
| 性能意识 | 你会提到:日志打印非常频繁,为了不阻塞主业务线程,我会考虑异步推送,不影响接口响应速度。 |
| 全栈能力 | 你打通了 Java → WebSocket → Nginx/Docker → React 的全链路,证明你不是只会写 CRUD。 |
| 架构思维 | 你知道把配置放在 app 层,把实现放在 infrastructure 层,这体现了对 DDD(领域驱动设计) 的深刻理解。 |
| 运维友好 | 你可以说:这是为了方便开发调试,不用频繁登录服务器看日志,提高了研发效能。 |
4. 重点突破:面试官可能会问的问题
问:如果日志量特别大,前端会不会卡死?
你的绝杀回答:
“确实存在这个风险。所以在实现时,我在前端设置了日志缓冲区限制,只保留最新的 100 条数据(slice(-100))。同时在后端,我可以通过 Logback 的配置,只过滤 INFO 以上级别的关键业务日志,避免心跳包等垃圾日志占满带宽。”
💡 给你的“数字花园”加点料
在你的笔记里,我建议你画一张简单的数据流转图。不需要很复杂,用文本块画就行:
[Java 业务代码] -> [Logback 框架] -> [WebSocketAppender]
| (实时推送)
[浏览器 React 组件] <- [WebSocket 协议] <- [Handler 处理器]现在你对这个组件的“来龙去脉”是不是清晰多了?如果你准备好了,我们可以聊聊如何把后端代码打包到 Docker 中,并让前端正确连上那个 ws:// 地址。
“日志打印是非常频繁的操作,你直接在 Appender 里同步调用 WebSocket 发送,会不会卡死业务线程?”
你可以这样回答(显得你思考过性能):
“目前是初步实现。为了不影响主业务性能,后续可以考虑在
WebSocketAppender内部引入一个阻塞队列(BlockingQueue),采用‘异步生产消费’模型,让日志异步推送,确保业务链路的零侵入和高性能。”
22.QPS,DB-router
-
关于“2C4G 支撑 2000 QPS” :
-
面试官必问:“你这个 2000 QPS 是怎么测出来的?”
-
标准答案:“我是用 JMeter 在本地模拟并发请求,直接压测的云服务器公网 IP。因为云服务器 峰值带宽只有 3 Mbps,加上 Tomcat 线程池的瓶颈,我观察到 CPU 在 2000 QPS 时负载达到 90%,响应时间开始变慢,所以测出了这个物理极限。”(这样回答极其真实)。
-
-
关于“DB-Router” :
-
面试官必问:“你这个路由组件是怎么实现的?”
-
标准答案:“核心是利用 Spring 的
AbstractRoutingDataSource。我在 ThreadLocal 里存了当前请求的路由 Key(比如 UserID),然后重写了determineCurrentLookupKey()方法,动态决定用哪个 DataSource。这其实就是简易版的 Sharding-JDBC 实现。”
-
23.防刷组件
1.DDD架构设计
MVC与DDD
DDD 是一种软件设计方法,Domain-driven design (DDD) is a major software design approach. MVC简单易懂,但较复杂的场景需要维护时,代码迭代成本会变高
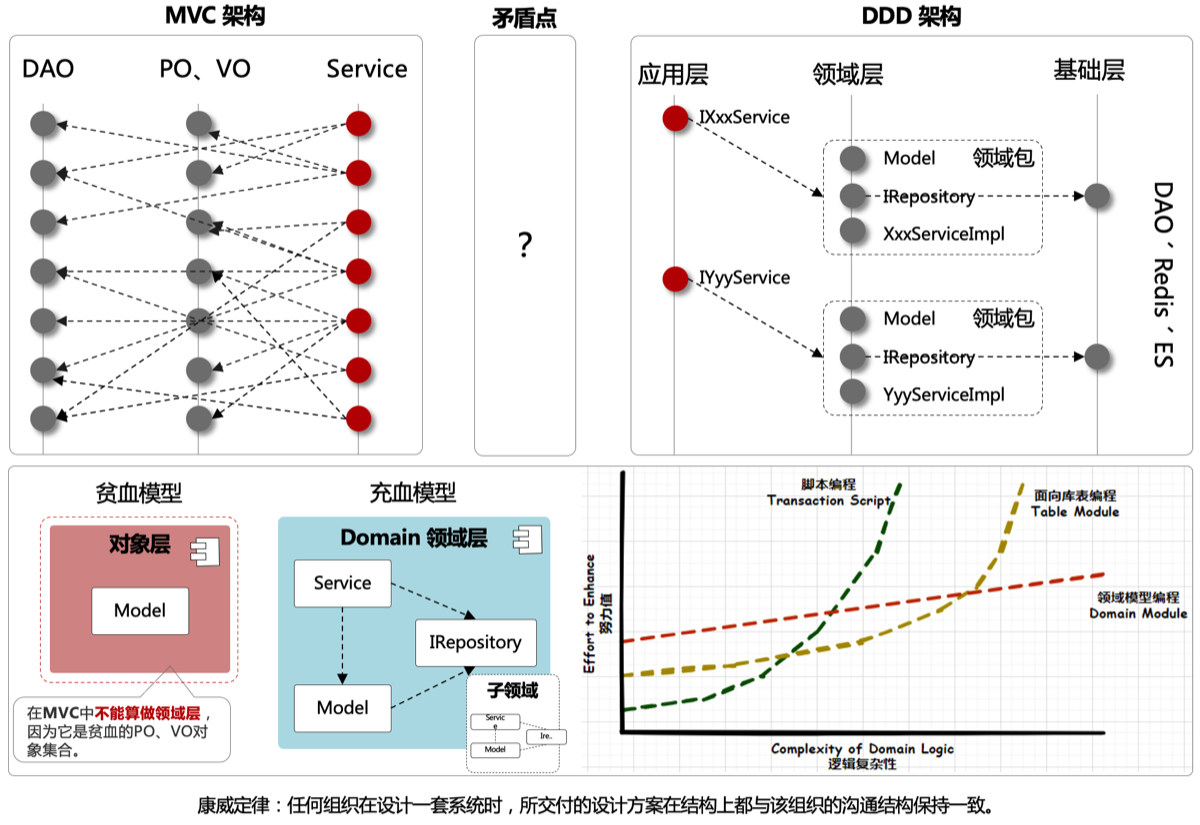
-
DDD 是把复杂业务拆成“领域”,每个领域像一个小公司一样自我管理,代码按业务逻辑而不是按技术堆放,从而让系统可维护、可扩展、不乱套。
MVC 最容易写成:
- controller 里面写逻辑
- service 调 DAO
- service 越堆越大
- VO、DTO、PO 被乱用
- 最后一个功能要改,需要了解全系统不同地方的逻辑 → 巨麻烦
DDD的分层结构
如下是 DDD 架构的一种分层结构,也可以有其他种方式,核心的重点在于适合你所在场景的业务开发。
① xfg-frame-api → 对外的接口(公司的前台/宣传册) “我们的服务是怎么调用的?RPC 格式是什么?”,RPC = Remote Procedure Call(远程过程调用) ② xfg-frame-app → 应用程序启动层(公司的行政/运营部门) “负责把公司运转起来,但不参与业务逻辑。”
例如:
- SpringBoot 启动类
- AOP、限流、日志
- 配置文件
- 打包成 docker 镜像
这里**不写业务逻辑,只负责应用运行**。
③ xfg-frame-domain → 领域层(公司的核心业务部门) DDD 的灵魂!业务逻辑都在这里。
每个领域像“一个小公司”:
- 模型 model(员工)
- 仓储接口 repository(资源获取)
- 业务 service(业务规则、流程)
例如“订单领域”就是一个独立团队:
`订单模型(OrderEntity) 订单值对象(OrderIdVO) 订单仓库接口(IOrderRepository) 订单服务(OrderService)`
领域层就是你系统的**真实业务能力所在**。
④ xfg-frame-infrastructure → 基础设施层(公司的后勤部门) “数据库、Redis、MQ 的真实实现都在这里。”
领域层只定义接口:
`IOrderRepository`
基础设施层来实现:
`OrderRepository implements IOrderRepository`
这样做的好处:
- 业务层不依赖 MyBatis 代码
- 想从 MySQL 换成 MongoDB,只改基础设施,不改业务逻辑
- 业务变动不会炸掉 DAO
⑤ xfg-frame-trigger → 触发器层(公司的对外接口部门) “别人通过 HTTP / RPC / MQ / 定时任务 调用你”
也叫 Adapter 层,负责接入各种触发方式:
- HTTP Controller
- Dubbo RPC 实现类
- MQ 消费者
- 定时任务
触发器做的事是:
1. 接收外部请求
2. 参数校验
3. 调用 domain 业务逻辑
4. 返回处理后的结果
触发器不写业务!
⑥ xfg-frame-types → 通用工具层(公司的共享工具库) “常量、通用的响应对象、枚举等公共类型。”
这里没有业务逻辑,只放工具类,例如:
- Response
- Constants
- 枚举类型
所有层都能引用
领域分层
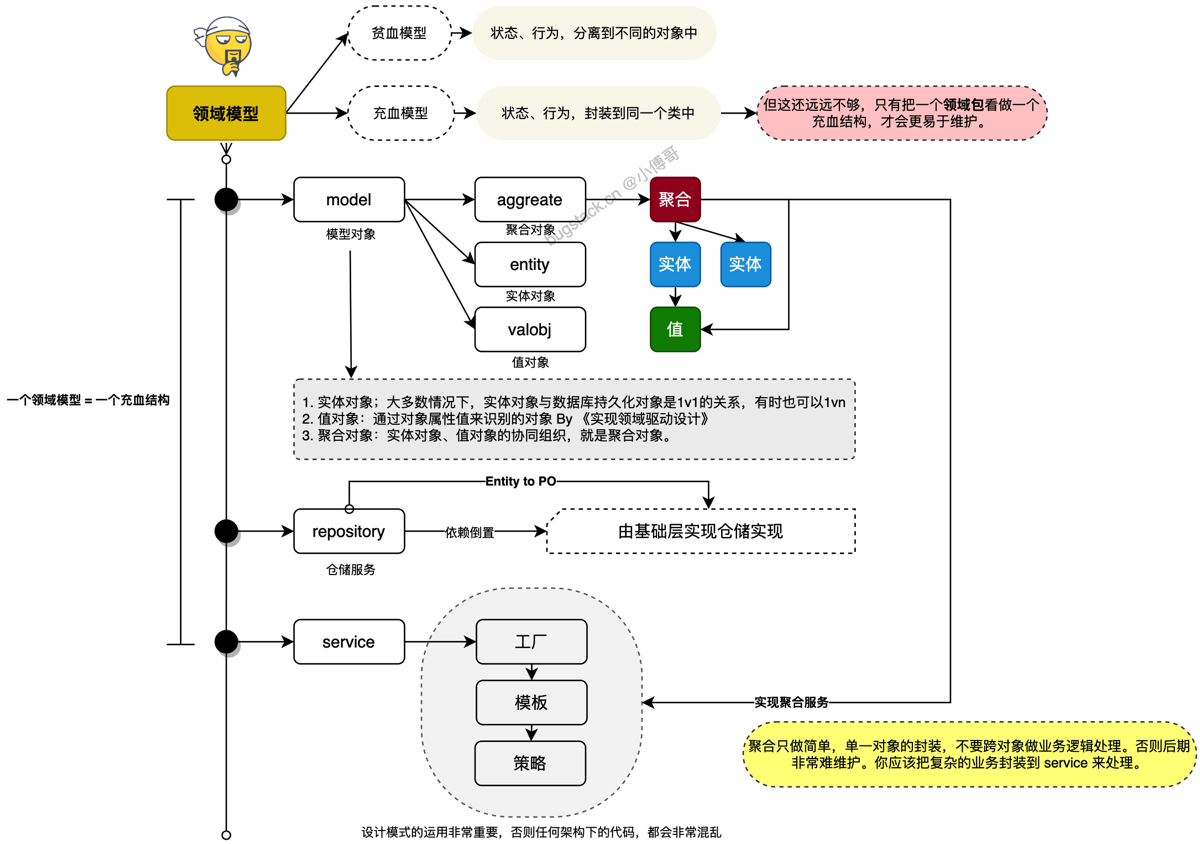
model 里还分为;valobj - 值对象、entity 实体对象、aggregates 聚合对象
| 概念 | 有没有 ID | 能不能单独存在? | 是什么? |
|---|---|---|---|
| 值对象 VO | ❌ 没有 | ❌ 不能 | 小数据值 |
| 实体 Entity | ✔ 有 | ✔ 能 | 业务中的“东西” |
| 聚合根 Aggregate | ✔ 有 | ✔ 必须有 | 整个业务逻辑的大 Boss |
🚗 一个超级通俗的例子:
我们开一家「电商系统」来解释 DDD 的三个核心概念 假设业务里有:
- 商品(name、price、description…)
- 订单(orderId、收件人、订单项…)
- 用户(userId、昵称、手机号…) DDD 中,针对数据和对象会这样拆分:
① 值对象 VO(valobj) ≈ 不可变、没有唯一 ID 的“小数据片段” 关键特征:
- 没有唯一标识(没有 ID)
- 只关心内容,而不是它是谁
- 通常是不可变对象(immutable)
- 代表纯粹的“值” 比如:
- 商品名
ProductNameVO - 商品描述
ProductDescriptionVO - 年龄
AgeVO - 地址
AddressVO - Money(金额) 这些东西变化时,不是“修改”,而是“重新生成一个新对象”。
“iPhone 16 Pro Max(蓝色)价格 8999”
这里「名称」「描述」「价格」都只是值,不会单独存数据库,不会有自己的 ID。
你不会给“商品名称”单独建一张表,对吧?
② 实体对象 Entity ≈ 有一个唯一 ID 的可变化的业务对象 关键特征:
- 有唯一标识(ID)
- 即使属性变化,它还是同一个对象
- 通常和数据库 PO 强相关,但不是完全等价 比如:
- 用户(userId)
- 订单(orderId)
- 商品(productId) 这些东西会单独存表,因为它们是业务的主要对象。
OrderItemEntity(id=1, productName="可乐", price=3)
即使你把可乐的价格从 3 改成 3.5,它仍然是 OrderItem id=1。
③ 聚合根 Aggregate ≈ 一组实体的“老板”,负责保持业务一致性 这是 DDD 最不好理解、但最重要的概念。 聚合(Aggregate)理解成:
一组强相关实体的组织结构,它们必须成为一个业务整体,由一个“聚合根”负责。 聚合根的作用:
- 对外的唯一入口
- 保证整体数据的一致性
- 业务规则在这里封装
一个订单聚合可以包含:
结构示意:
OrderAggregate(聚合根)
├── OrderEntity(订单本体)
├── List<OrderItemEntity>(订单项)
├── AddressVO
└── PriceVO
【聚合规则】
- 订单创建时,订单项不能为空(聚合根校验)
- 订单总价必须 = 各订单项相加(聚合根确保一致性)
- 添加订单项、删除订单项,都必须通过 OrderAggregate 来做 📌 聚合根 = 决策者 📌 实体 = 成员对象 📌 值对象 = 基础值信息
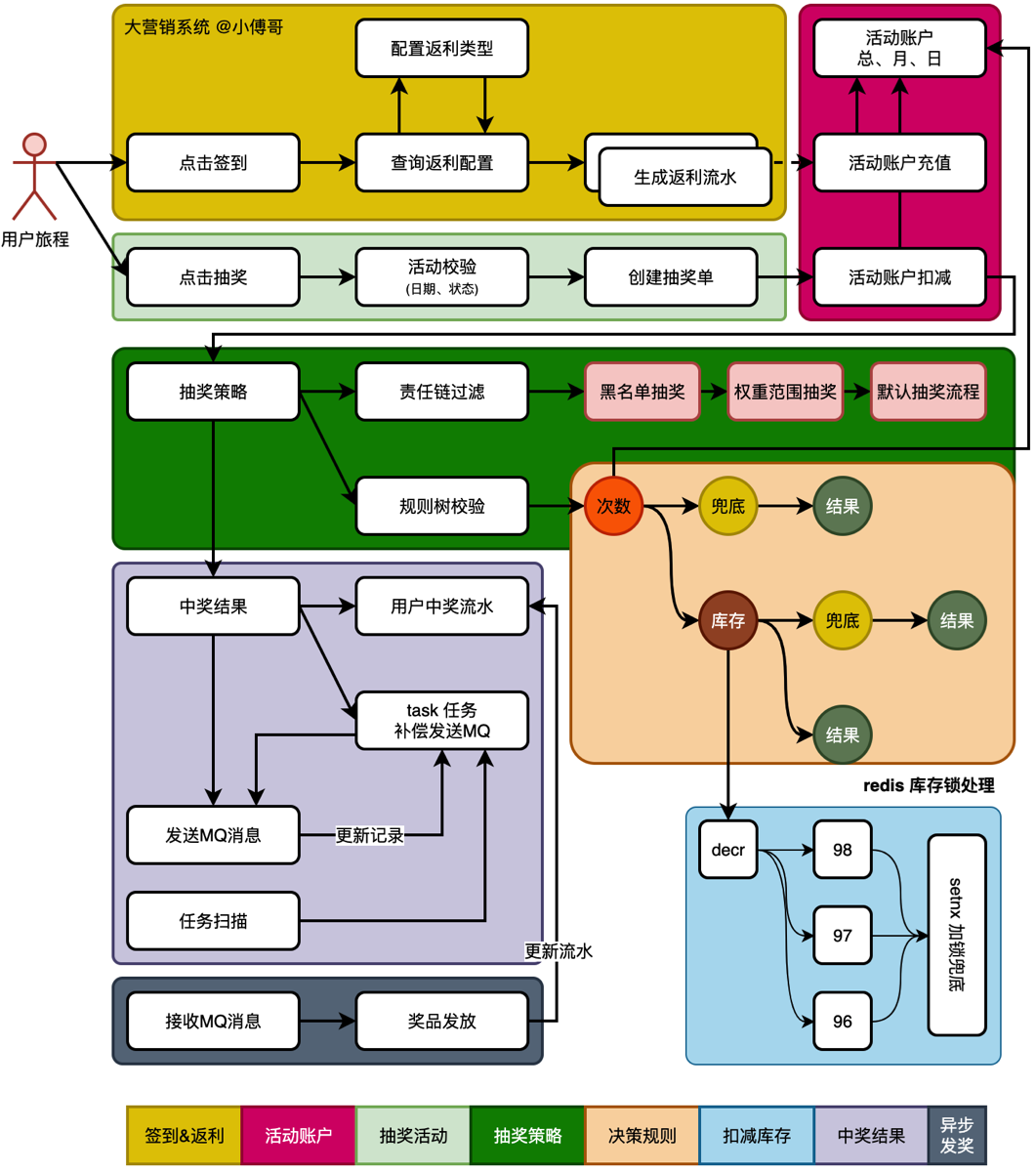
本项目业务流程
本项目战略设计
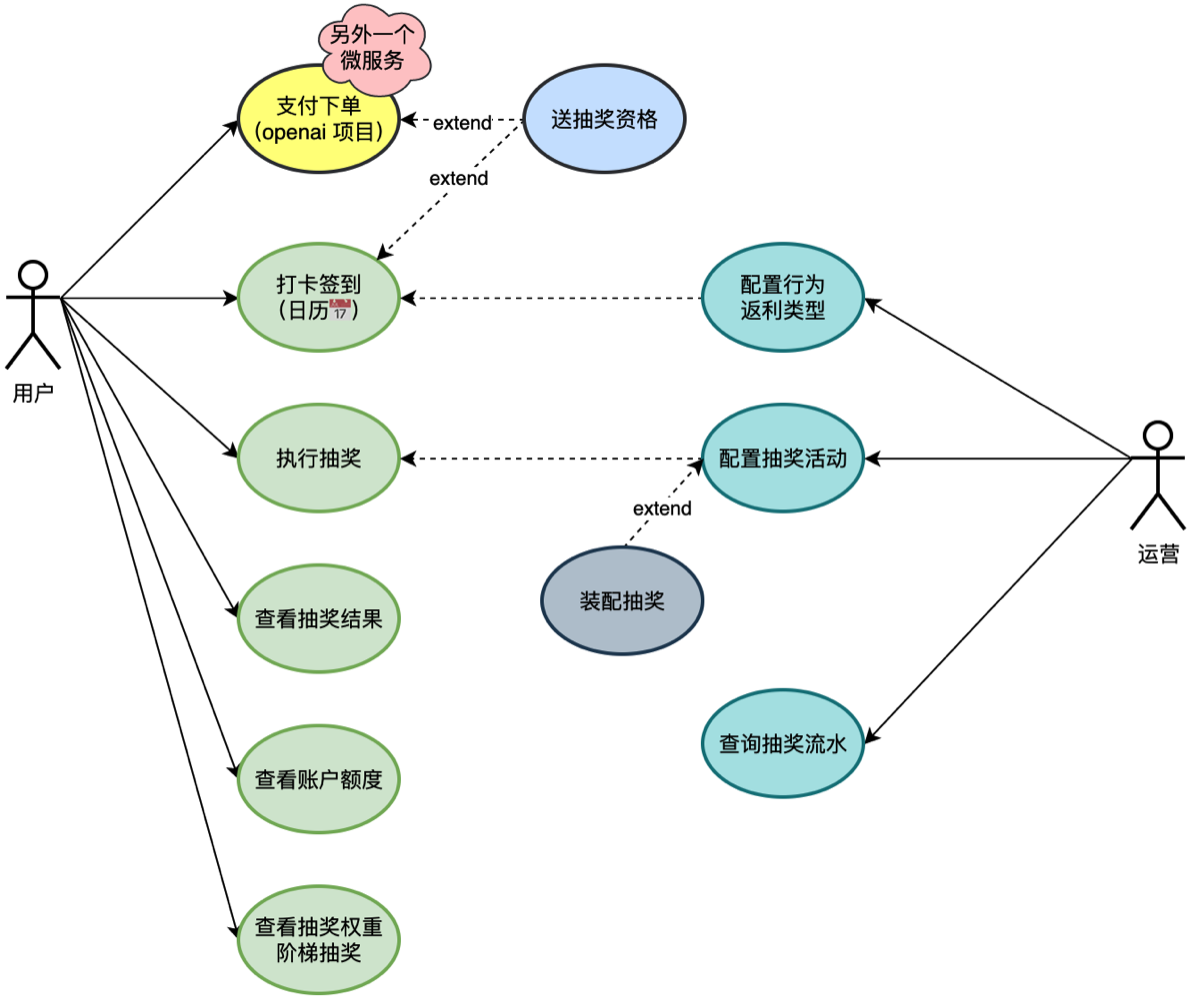
1.用例图
- 根据业务需求画系统用例图(use case diagram:是用户与系统交互的最简表示形式,展现了用户和与他相关的用例之间的关系)
2.事件定义风暴
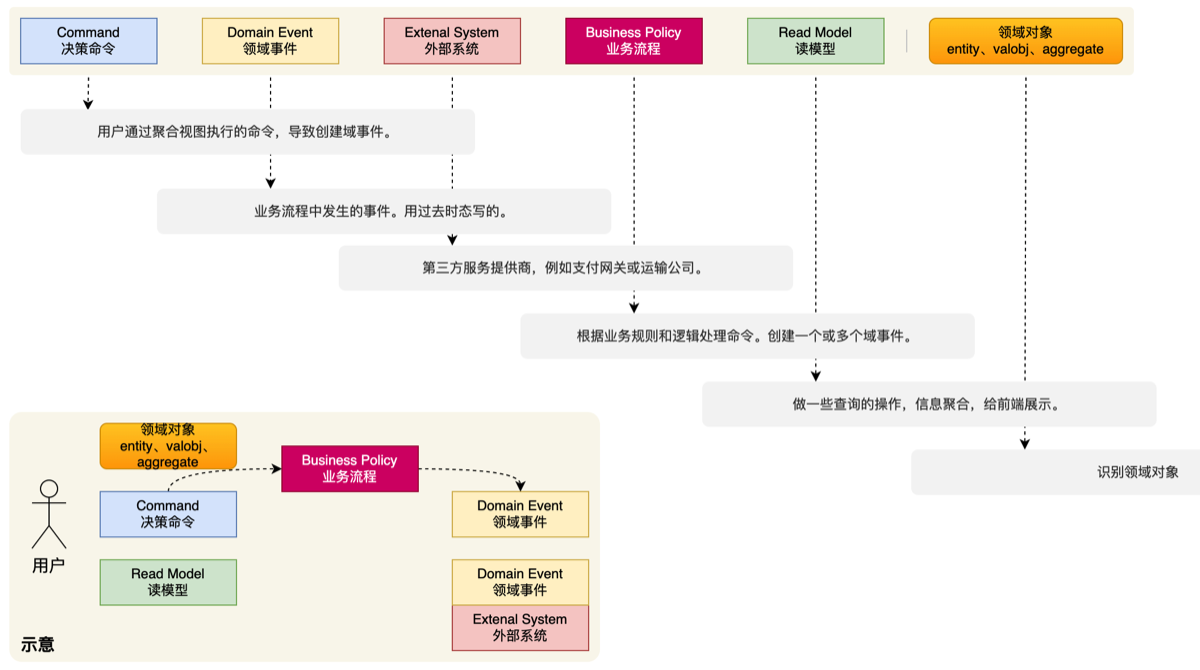
3.寻找领域事件(最核心的部分)
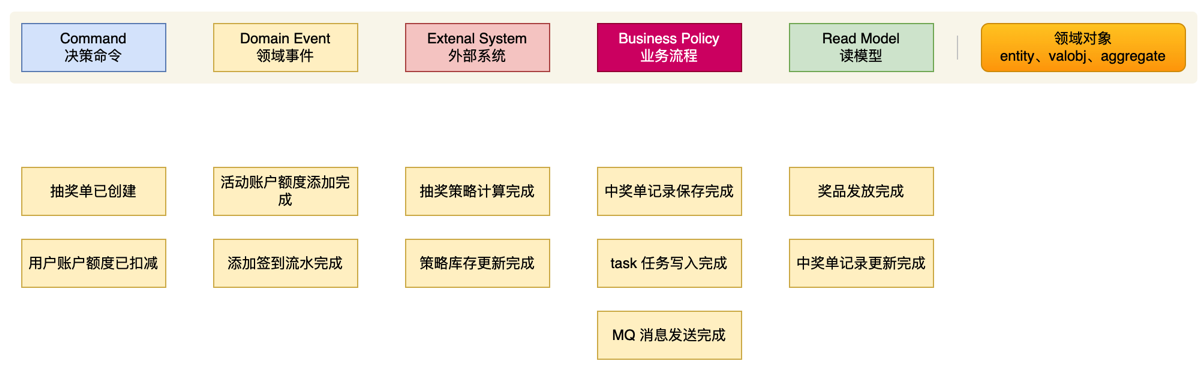
4.识别领域角色和对象
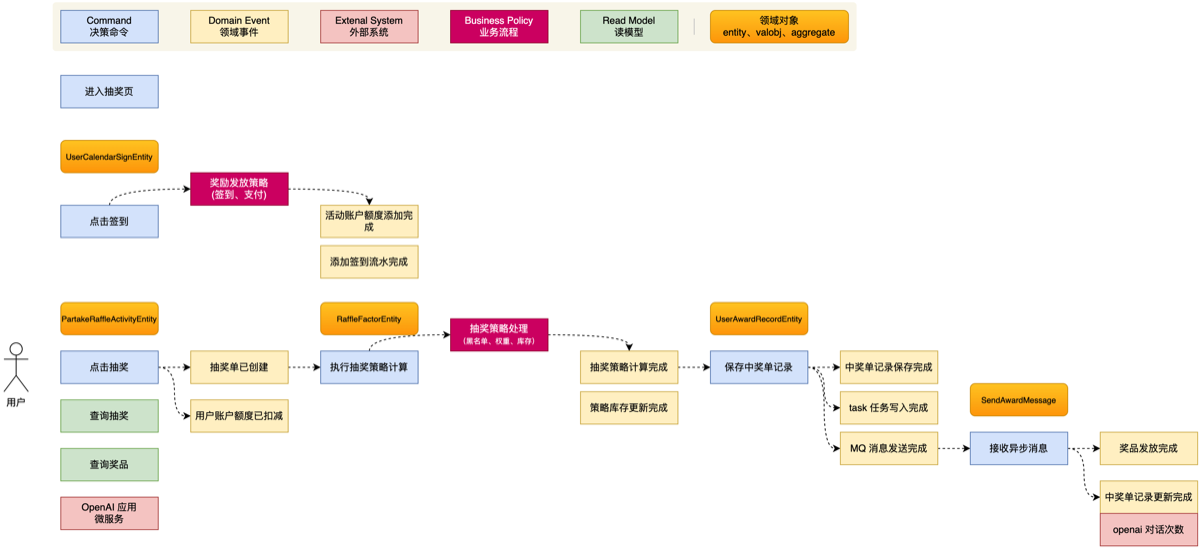
5.划分领域边界
- 圈出领域
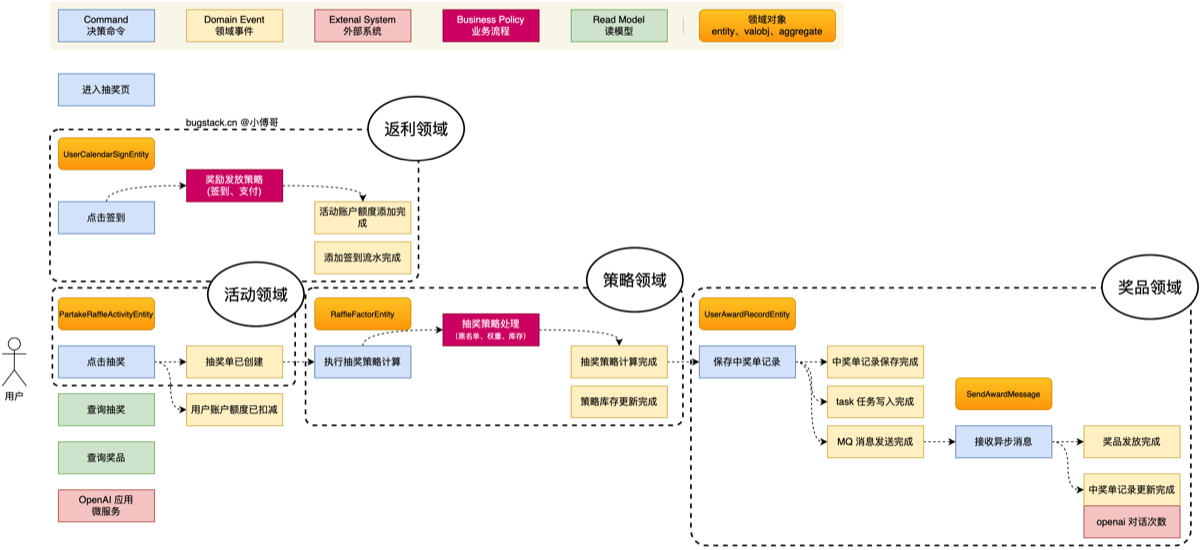
- 领域边界
6.研发详细细节
- 实体对象
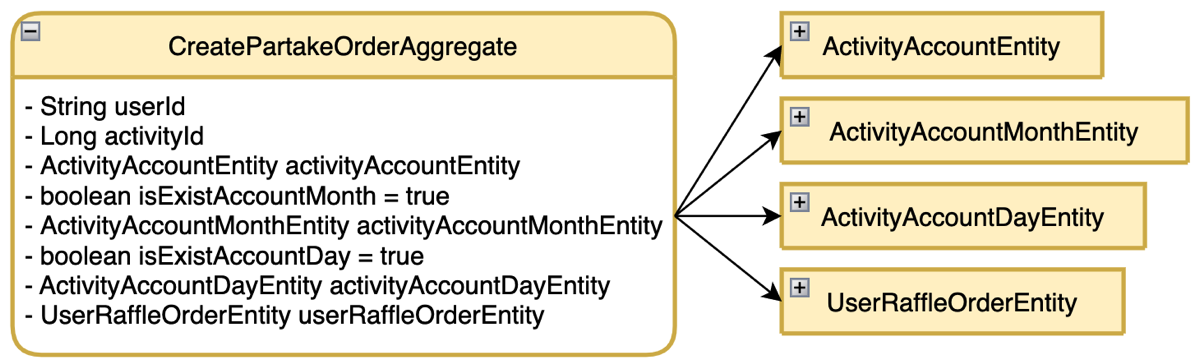
对每个领域对象进行字段的详细细节
- 流程设计
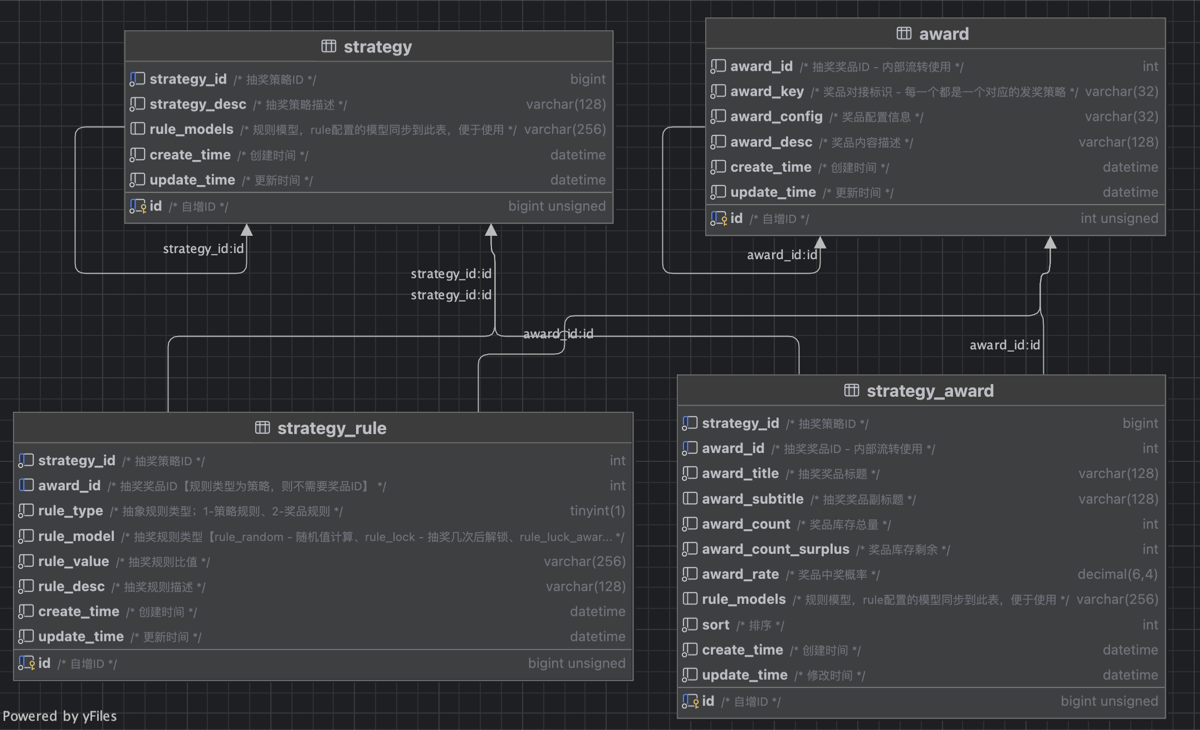
2.数据库
3.策略概率装配处理
feature/231223-xfg-strategy-armory
#无边记 无边记第三节
项目架构图
 本节先实现最核心的部分
本节先实现最核心的部分
策略的选择
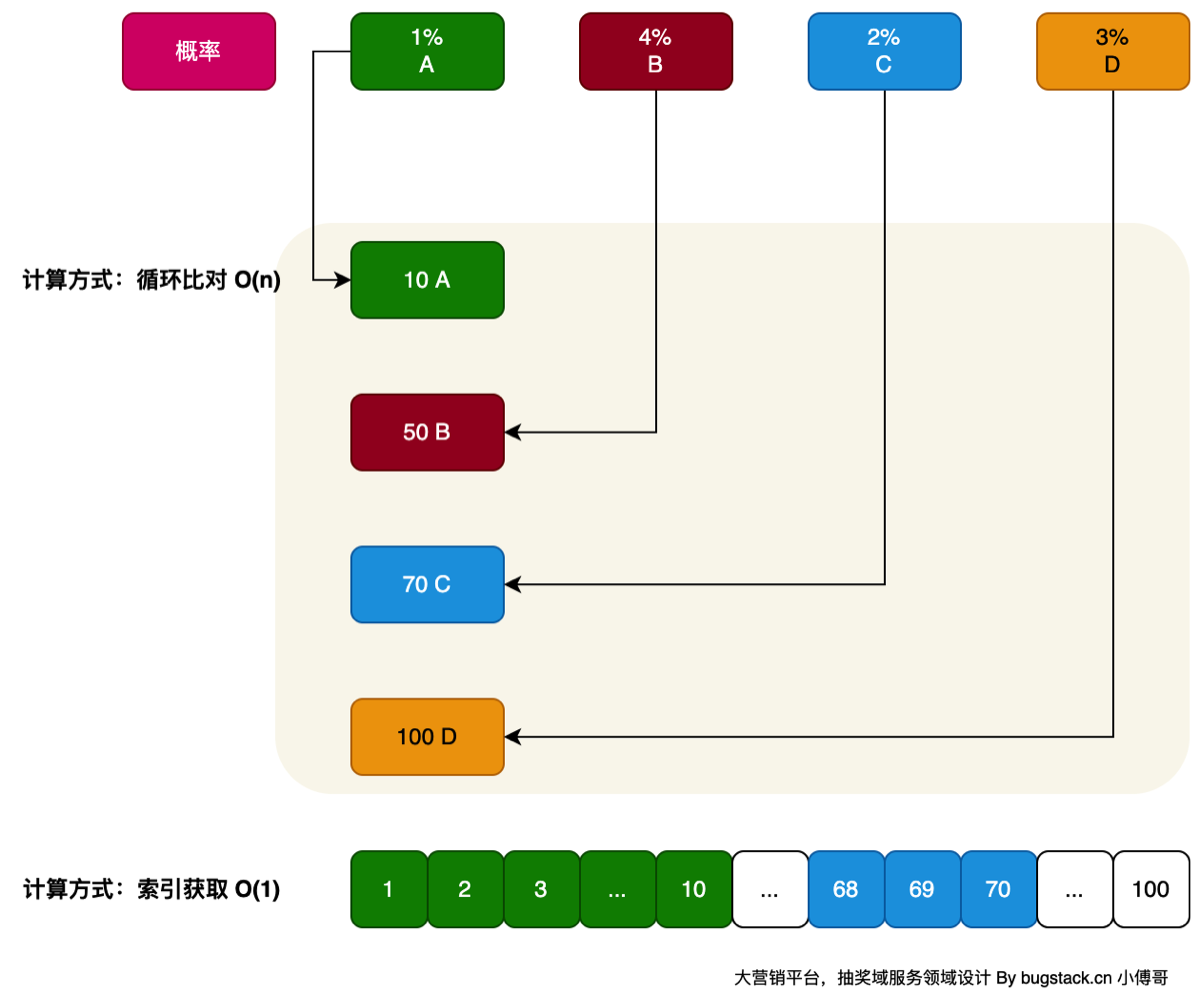
这里使用空间换时间的做法
- 提前算好抽奖的概率分布,用redis存储,抽奖时生成随机值,在空间中定位
- 另一种是生成随机值后与概率范围做for循环比较,如果总概率超过100万,可以用此方法,与实际诉求来依赖
记忆点 为什么用redis不用本地内存
- redis可以解决分布式问题,本地内存需要让多台机器都保持数据的同步更新,需要引入配置中心及定时检测的手段来处理启动前/后,对活动变更/新增做本地内存做数据加载处理
策略装配库(兵工厂),负责初始化策略计算;
- 查询策略配置
- 获取最小概率值
- 获取概率值总和
- 用 1 % 0.0001 获得概率范围,百分位、千分位、万分位
- 生成策略奖品概率查找表「这里指需要在list集合中,存放上对应的奖品占位即可,占位越多等于概率越高」
- 对存储的奖品进行乱序操作。避免顺序生成的随机数前面是固定的奖品。
- 期间存储奖品table时,也要存储table的长度,在抽奖时,先根据策略在redis查对应的长度,在根据长度生成随机数获取相应奖品
- 生成出Map集合,key值,对应的就是后续的概率值。通过概率来获得对应的奖品ID
- 存放到 Redis
注意,这里调用的 IStrategyRepository 由仓储层进行实现。
4.策略权重的装配
231231-xfg-strategy-armory-rule-weight-note
#无边记 见无边记第四节
- 本章对上一章进行重构,满足对策略权重的装配处理(如果存在)
- 策略权重
- 如果用户抽奖N积分后,可以升级中奖返回(更高阶高价值的奖品)
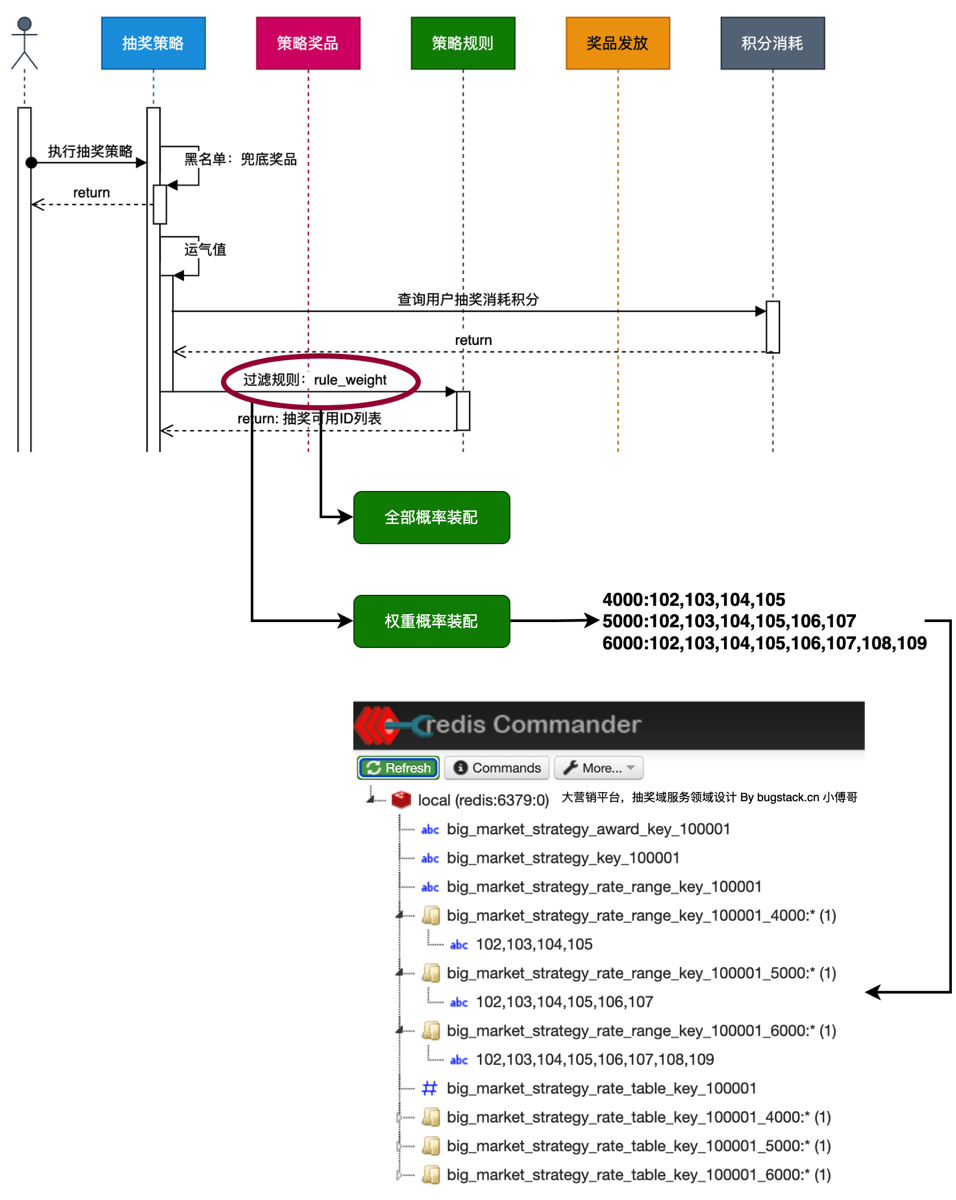
- 在装填策略后在装填权重策略(如果有)
- 查询是否策略id是否在策略表内存在权重策略
- 在查询策略规则表看是否存在具体策略组[1,4,7]
- 当存在时,在策略规则实体内使用get具体策略方法,返回一个map,key是权重名字,val是具体的权重组
- 循环key取出各自的权重组,拷贝后过滤不存在该组的奖品,装填带策略权重的奖品池
5.抽奖前置规则过滤
实现抽奖前置权重和黑名单规则,在用户抽奖前进行规则过滤。本节会使用到模板模式、策略模式、工厂模式,来实现功能;
一.模版模式
定义一个算法的固定流程框架,并允许子类在不改变整体流程的情况下,重写其中的某些步骤。
📌 核心点
- 父类:定义固定流程(模板)。
- 子类:负责实现具体步骤。
- 流程就像一个“骨架/模板”,不能改变顺序。
📌 示例(当前项目)
AbstractRaffleStrategy 就是模板模式:
performRaffle() {
1. 参数校验
2. 查询策略
3. 抽奖前规则过滤 ← 子类实现
4. 默认抽奖逻辑
}你只需要在子类 DefaultRaffleStrategy 中实现:
doCheckRaffleBeforeLogic()
整个抽奖流程不会变,这就是模板模式。
📌 适用场景
- 流程固定,但某些步骤会变化(多态扩展)
- 典型:抽奖流程、处理表单流程、爬虫流程、支付流程…
二.策略模式
将一系列可替换的算法封装成独立策略对象,在运行时动态选择其中一个。
📌 核心点
- 策略之间是 并列、可互换 的。
- 不同规则是不同的策略类。
📌 示例(你的项目)
抽奖前规则:黑名单 & 权重
@LogicStrategy(logicMode = RULE_BLACKLIST) class RuleBlackListLogicFilter implements ILogicFilter {} @LogicStrategy(logicMode = RULE_WEIGHT) class RuleWeightLogicFilter implements ILogicFilter {}“ 两者都是策略,都实现了:
public interface ILogicFilter {
RuleActionEntity filter(RuleMatterEntity entity);
}当抽奖时,会根据规则选择不同策略执行。
📌 使用场景
- 多种可替换算法:排序、压缩、加密
- 多种计费模式、风控规则、抽奖规则
- if-else 太多、要从代码中“解耦逻辑”
三.工厂模式
使用工厂对象统一创建实例,避免你自己 new,让创建逻辑可控、可扩展。
简单工厂模式核心:
一个工厂类,负责创建一组相关的对象,根据传入的“标识”选择返回哪个对象。
DefaultLogicFactory 是一个带自动注册的简单工厂。 它不是工厂方法,也不是抽象工厂,而是一个策略池工厂(Registry Simple Factory)。
📌 项目里的例子
DefaultLogicFactory 会自动扫描所有 ILogicFilter 策略:
logicFilterMap.put(strategy.logicMode().getCode(), logic);在抽奖时通过工厂获取具体策略:
logicFilterGroup = logicFactory.openLogicFilter();
你无需知道策略类叫什么,不需要 new,只需要:
根据 code 找对象
📌 使用场景
- 对象创建复杂
- 需要根据类型动态创建实例
- 想隐藏创建细节
⭐ 三者的关系(超级重要)
在你的抽奖系统中:
模板模式
规定整个抽奖流程(父类骨架)
策略模式
用于“抽奖前规则过滤”(黑名单、权重等)
工厂模式
用于组装策略对象,让程序动态选择用哪个策略
流程设计
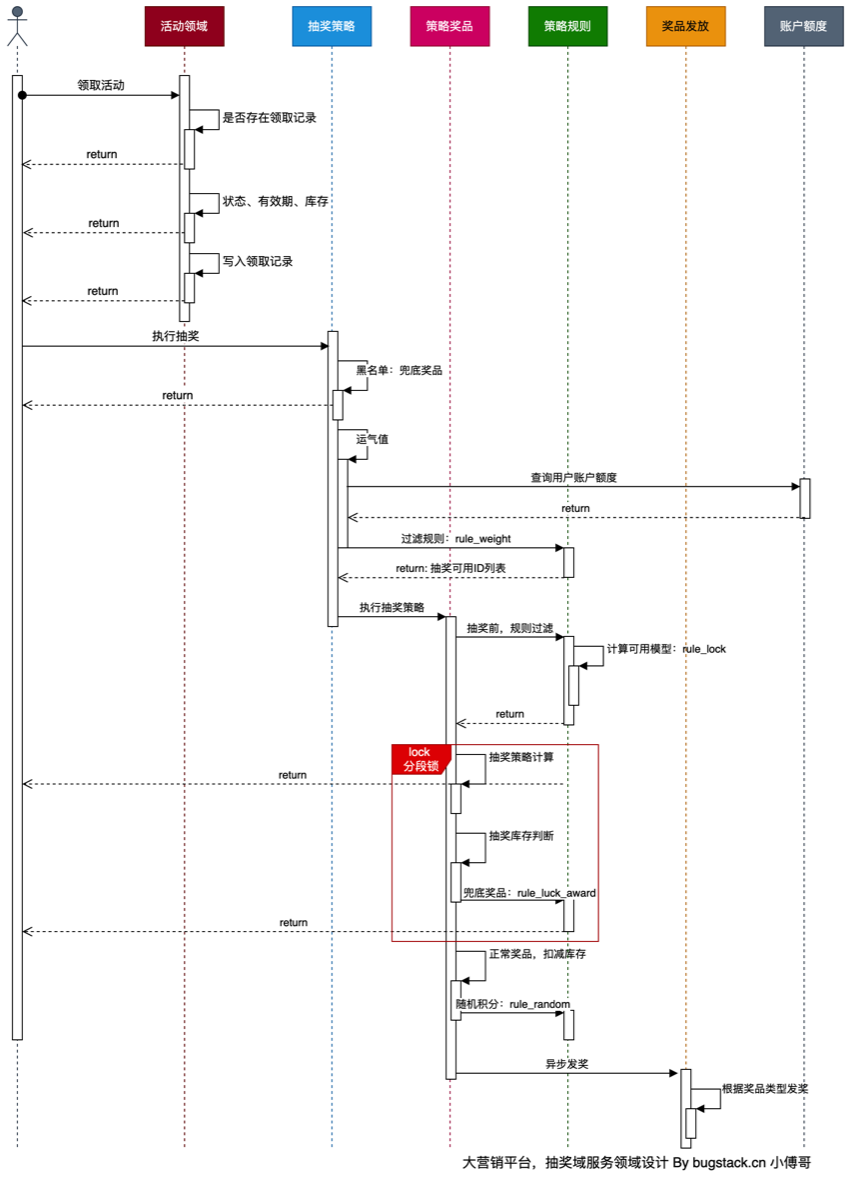
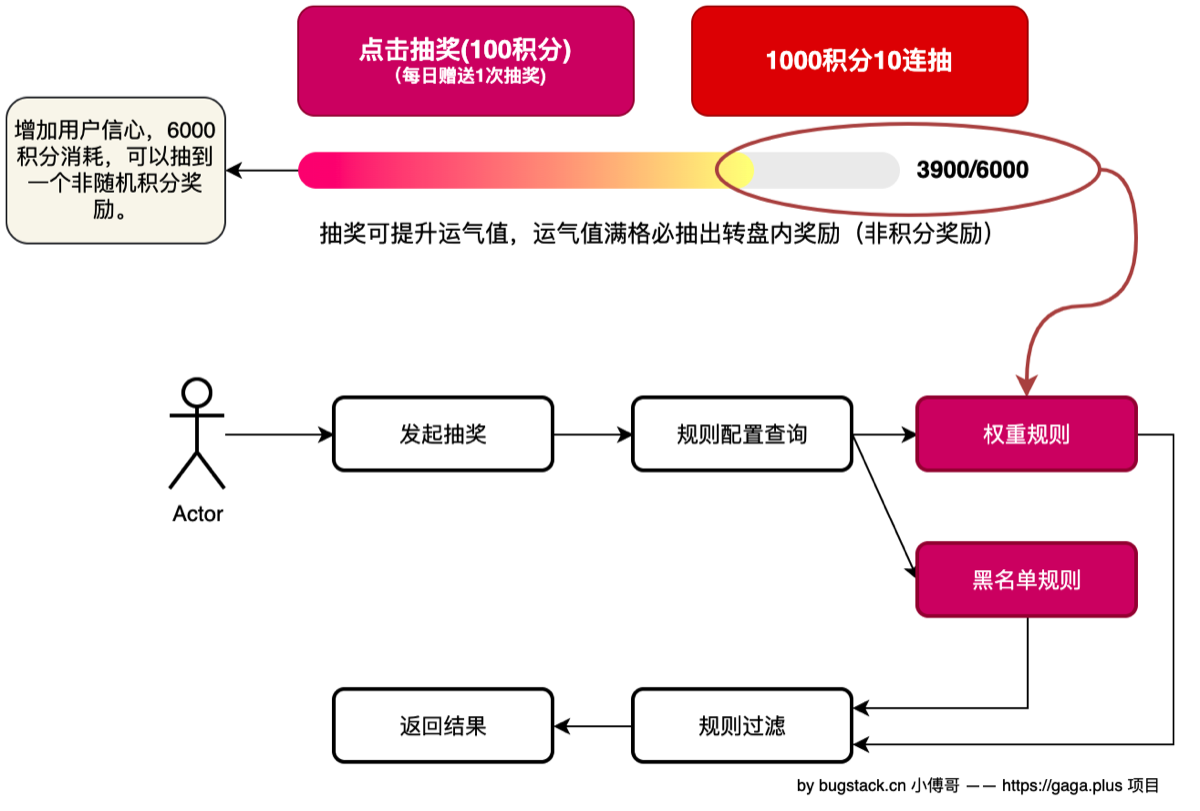
- 正规规则来说,分为抽奖前、抽奖中、抽奖后,三个阶段执行。本节我们先来处理抽奖前的规则。
用户在执行抽奖前,需先判断是否为黑名单用户,返回固定积分,在判断是否已超过N积分,来决定奖池
项目结构

- rule 下面是实现的整个规则部分的处理,后续可以更好的扩展添加其他规则。
- raffle 是抽奖功能的实现,抽象类是模板模式,定义出标准的抽奖流程
代码结构
- AbstractRaffleStrategy
定义抽奖流程的固定步骤,把其中可变步骤(例如规则过滤)抽象出去,让子类实现 就像做一碗拉面,流程固定:
- 准备食材
- 检查用户规则(是否黑名单、积分是否符合范围)
- 执行抽奖
- 返回结果
这就是模板方法模式的经典使用场景:
固定流程:
✔ 参数校验 ✔ 查策略 ✔ 执行规则过滤 ✔ 抽奖(或使用规则结果) ✔ 返回奖品 可变步骤只有一个: 👉 规则过滤 doCheckRaffleBeforeLogic()
doCheckRaffleBeforeLogic() 的实现在DefaultRaffleStrategy中
+-------------------------------+
| DefaultRaffleStrategy |
| doCheckRaffleBeforeLogic() |
+-------------------------------+
|
+----------------+-----------------+
| |
黑名单规则优先执行 其它规则顺序执行
| |
logicFilter["rule_blacklist"] logicFilter["rule_weight"]
| |
+-------+-------+ +------+-------+
| | | |
TAKE_OVER ALLOW TAKE_OVER ALLOW
| | | |
返回固定奖品ID 进入下一规则 限定范围抽奖 进入默认抽奖
DefaultRaffleStrategy 的 doCheckRaffleBeforeLogic() 是前置规则引擎的执行入口。它会使用工厂提供的规则池,先过滤黑名单,再按顺序执行其它规则,只要任何规则返回 TAKE_OVER 就接管抽奖流程,否则执行默认抽奖。
+-----------------------------------+
| 抽奖模板(Template) |
| AbstractRaffleStrategy |
|-----------------------------------|
| 1 参数校验 |
| 2 查询策略 |
| 3 调用 doCheckRaffleBeforeLogic | <─── 子类处理规则逻辑
| 4 如果 TAKE_OVER → 按规则返回结果 |
| 5 默认抽奖流程 |
+-----------------------------------+
|
v
+------------------------------------------------------------+
| DefaultRaffleStrategy(规则执行者) |
|------------------------------------------------------------|
| 从工厂获取所有规则:logicFactory.openLogicFilter() |
| 优先执行黑名单 → 判断 ALLOW / TAKE_OVER |
| 顺序执行剩余规则 → 判断 ALLOW / TAKE_OVER |
| 返回第一个 TAKE_OVER 的规则结果 |
+------------------------------------------------------------+
|
v
+--------------------------------+
| 规则工厂(Factory) |启动时就开始收集
| DefaultLogicFactory |
|--------------------------------|
| 自动扫描所有 @LogicStrategy |
| 建立规则池 Map<code, filter> |
| 提供 openLogicFilter() 返回池 |
+--------------------------------+
|
v
-----------------------------------------------------------
| 规则策略(Strategy) |
|----------------------------------------------------------|
| RuleBackListLogicFilter → 黑名单规则(TAKE_OVER) |
| RuleWeightLogicFilter → 权重规则(TAKE_OVER) |
| …未来可扩展更多规则… |
| 每个规则都实现 ILogicFilter 接口 |
-----------------------------------------------------------
6.中奖中置规则过滤
240113-xfg-raffle-rule-center-note'
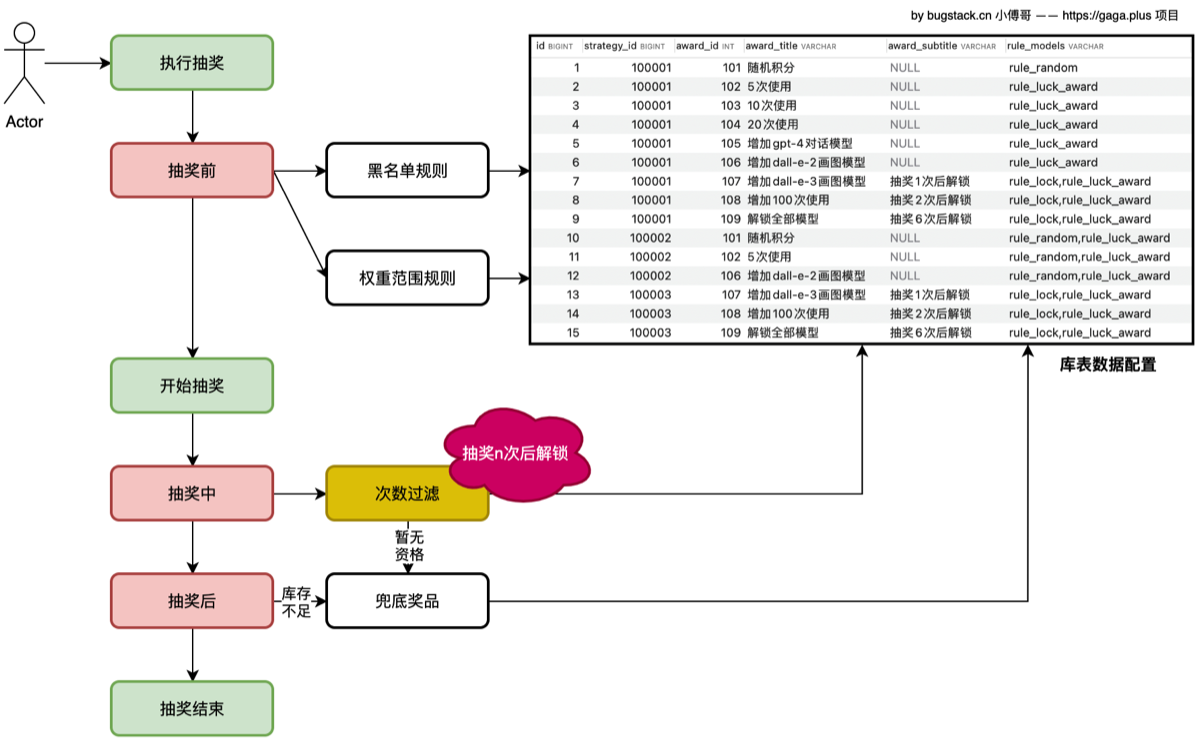
- 本章诉求 为刺激用户消耗手中的积分,为后面一些奖品增加条件:需要抽奖过几次后才能解锁(rule_lock字段) 故在抽奖中这个阶段,添加次数过滤(也算是一种黑名单或者权重策略)

7.责任链模式处理抽奖规则
240120-xfg-raffle-chain-note
- 本章诉求
在前面的章节,我们用模版,策略,工厂三种设计模式定义抽奖前中后的规则过滤,但前置规则(只判断,不抽奖)的校验和抽奖逻辑混在一起,显得臃肿,指责过多,这节,通过责任链把“”规则判断“和”抽奖行为“分开,让其每一节点只干一件事情→清晰可扩展
流程设计
抽奖的前置规则可以抽象为一种策略行为,比如黑白名单策略,权重策略,而这些策略规则是互斥的,所以责任链很适合

2.1 定义责任链接口(ILogicChain)
接口:
public interface ILogicChain {
ILogicChain next();
ILogicChain appendNext(ILogicChain next);
Integer logic(String userId, Long strategyId);
}appendNext():构建链next():执行链的下一个节点logic():每个节点自己的核心逻辑 这是本节最基础的定义。
2.2 黑名单节点(BackListLogicChain)
特点:
- @Component(“rule_blacklist”)
- 逻辑:命中黑名单 → 接管抽奖直接返回 awardId,否则 next()
这一段结构示例:
黑名单节点 ↓(放行) 权重节点
2.3 权重节点(RuleWeightLogicChain)
特点:
- @Component(“rule_weight”)
- 逻辑:根据积分范围选择某个奖品 → 接管,否则 next()
2.4 默认节点(DefaultLogicChain)
特点:
- @Component(“default”)
- 逻辑:抽奖的最终兜底逻辑(一定会返回奖品) 责任链结构就像这样:
黑名单
↓ 权重
↓ 默认抽奖
strategy
│
│ ① 抽奖入口 performRaffle
│
▼
┌──────────────────────────────┐
│ DefaultChainFactory │
│ ← Map<String,ILogicChain> │
└──────────────────────────────┘
│
▼
构建责任链(基于 rule_models 配置)
链头
↓
┌────────────────────────┐
│ BackListLogicChain │ rule_blacklist
└────────────────────────┘
↓ (next)
┌────────────────────────┐
│ RuleWeightLogicChain │ rule_weight
└────────────────────────┘
↓ (next)
┌────────────────────────┐
│ DefaultLogicChain │ default
└────────────────────────┘
(责任链执行逻辑)
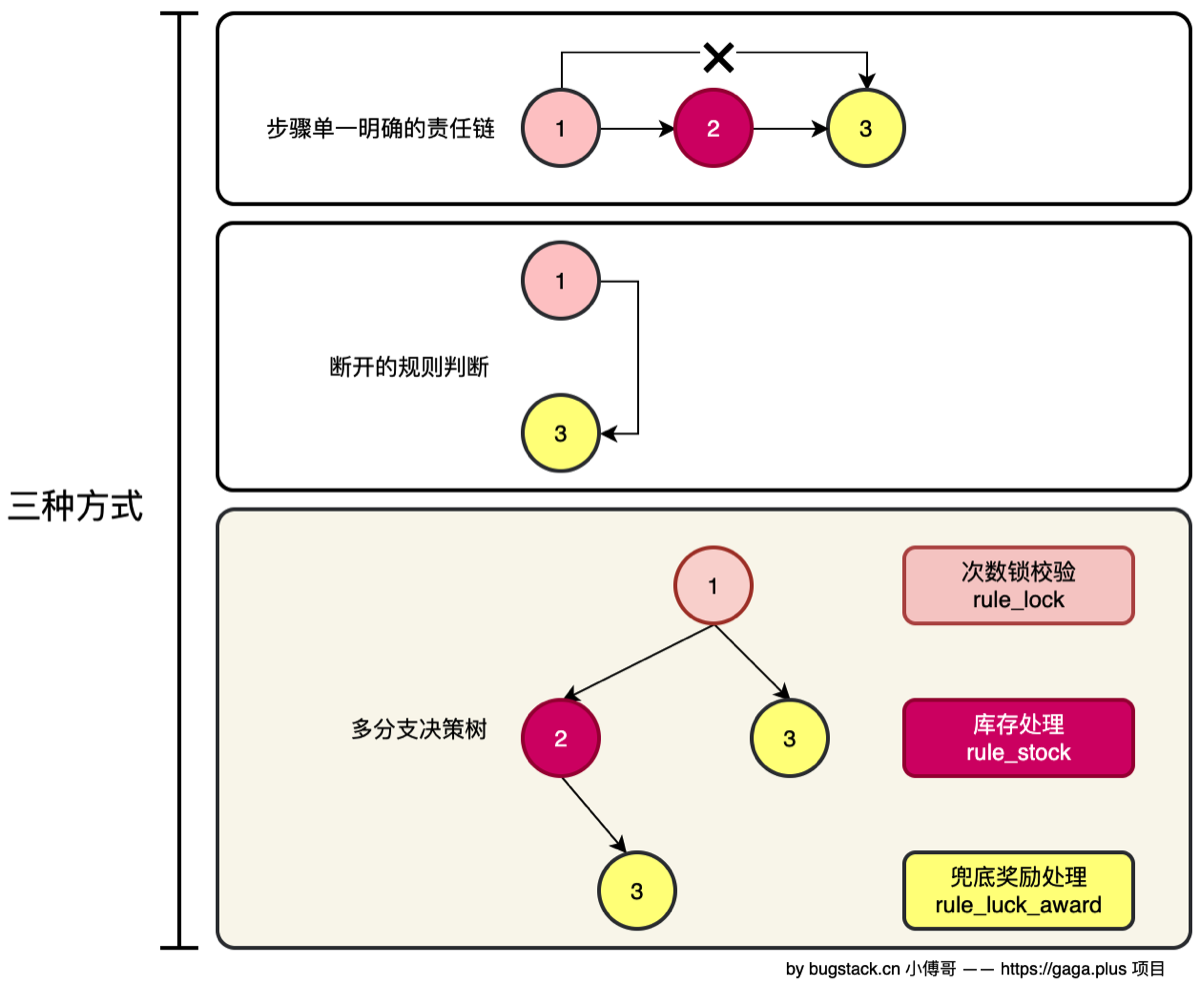
8.抽奖规则树模型结构设计
240127-xfg-rule-tree-note
- 本章诉求 解决先阶段中抽奖策略规则的中、后两部分执行问题。.引入组合模式的规则引擎,让过滤节点可以满足一颗二叉树的结构,自由的组合和多分支莲路的方式完成流程的处理
“抽奖中/抽奖后”的规则完全不同! 比如:
- 抽到某个奖品后,还要判断库存
- 如果库存不足,要判断是否给兜底奖
- 抽奖次数与某些奖品的解锁条件关联
- 抽奖后还可能触发一些后置规则
① 设计规则树结构(组合模式) ② 编写树执行引擎(决策树引擎) ③ 提供工厂装配树结构(工厂模式)
流程设计
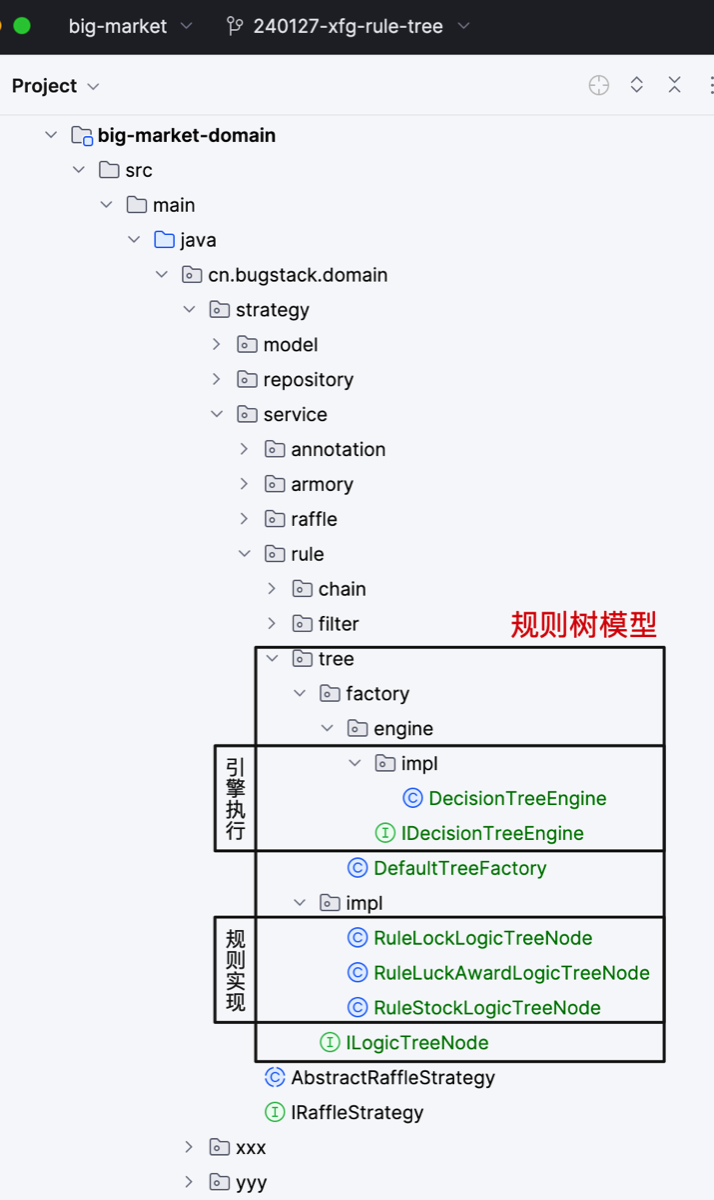
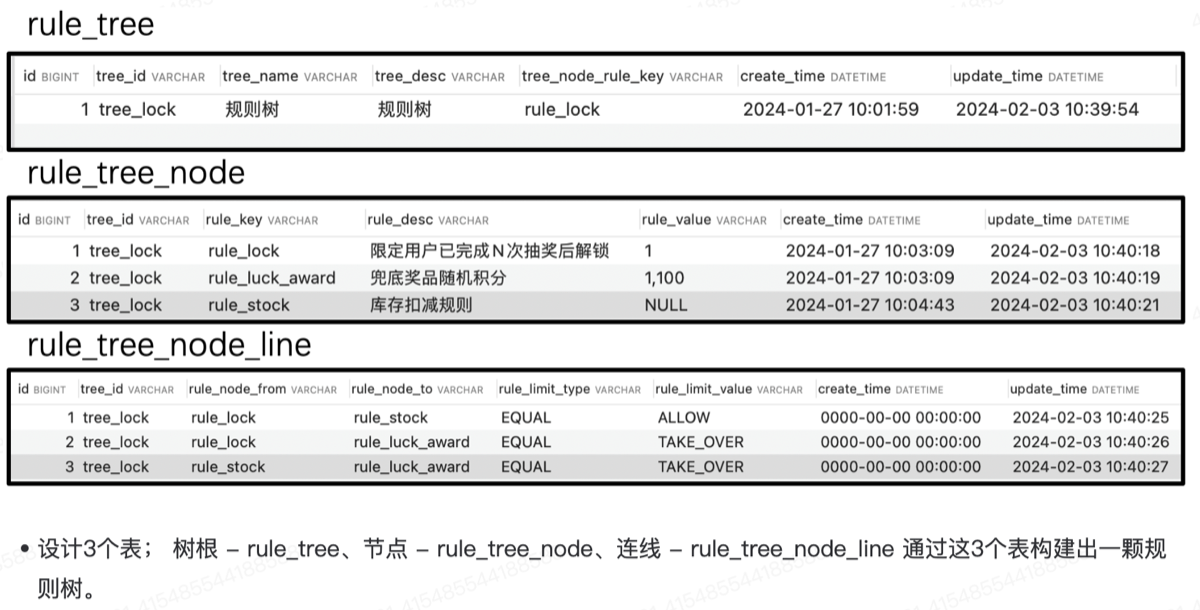
- 工程结构
规则树模型
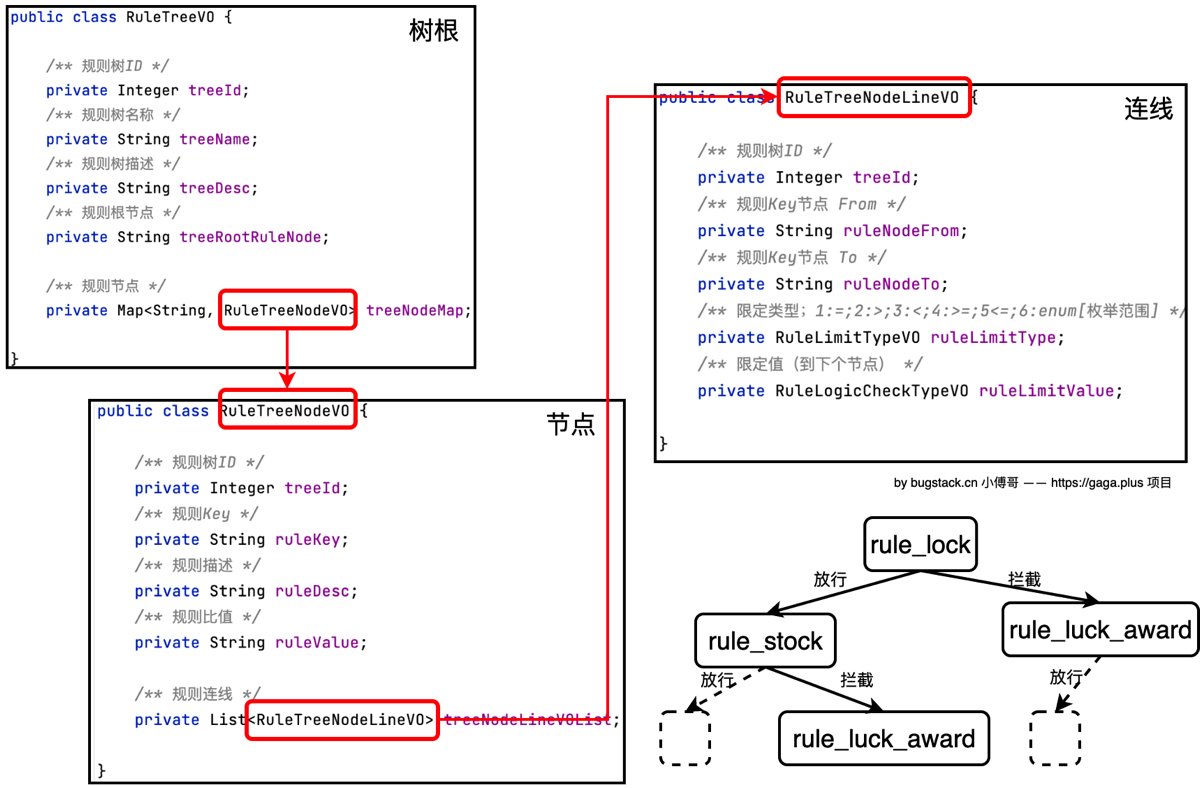
- RuleTreeVO 决策树的树根信息,标记出最开始从哪个节点执行「treeRootRuleNode」。
- RuleTreeNodeVO 决策树的节点,这些节点可以组合出任意需要的规则树。
- RuleTreeNodeLineVO 决策树节点连线,用于标识出怎么从一个节点到下一个节点。
rule_lock(抽奖次数是否满足解锁条件)
│
├── TAKE_OVER → rule_luck_award(直接给奖励)
└── ALLOW → rule_stock (检查库存)
│
└── TAKE_OVER → rule_luck_award (库存不足给兜底奖)
9.模版模式串联抽奖规则
240203-xfg-raffle-rule-flow-note
责任链进行抽奖计算,基于抽奖计算结果对基础抽奖在进行规则树的过滤,最终返回抽奖结果。串联上两节课程
流程设计
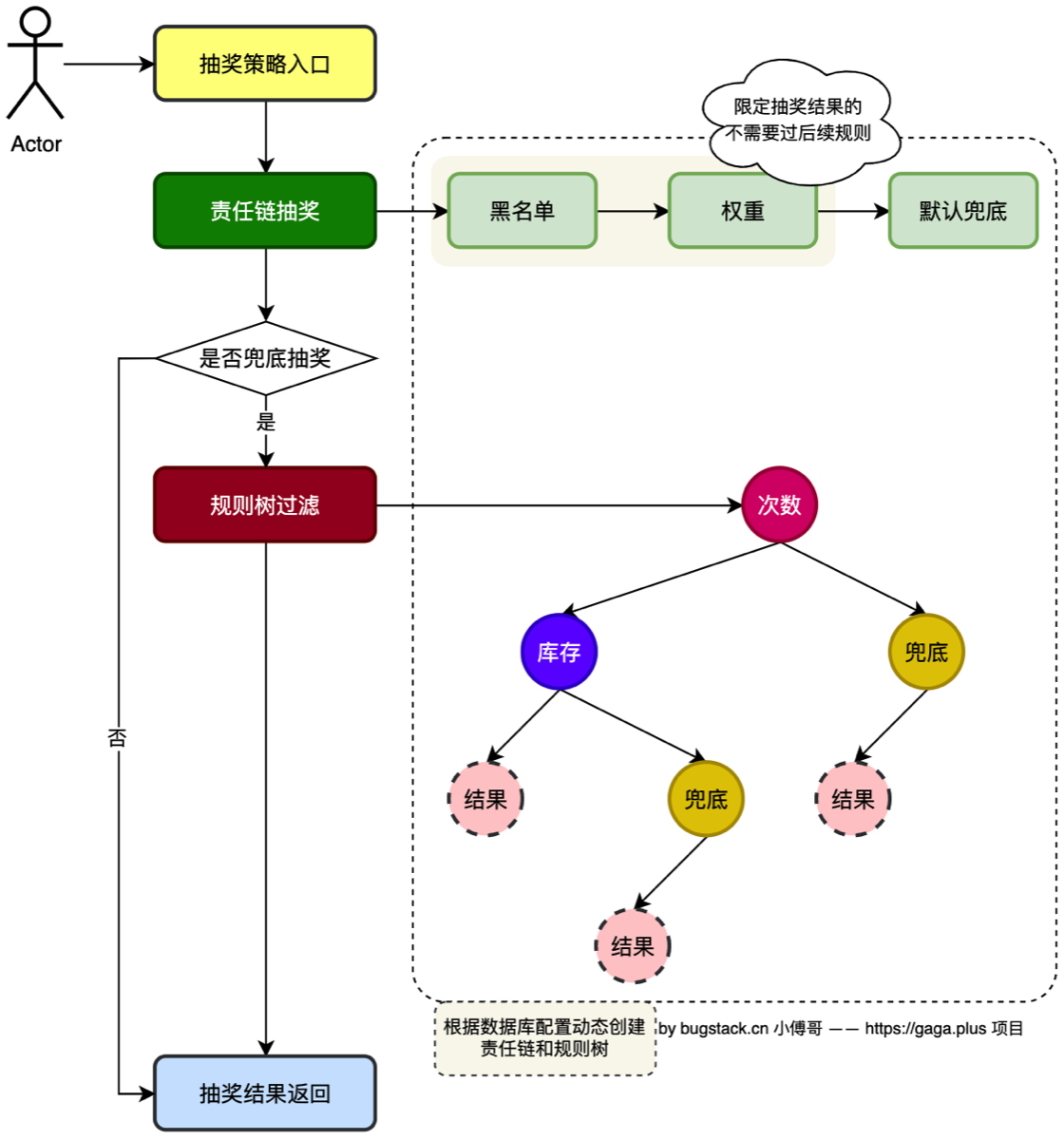
功能实现
- 库表设计
- 工程结构
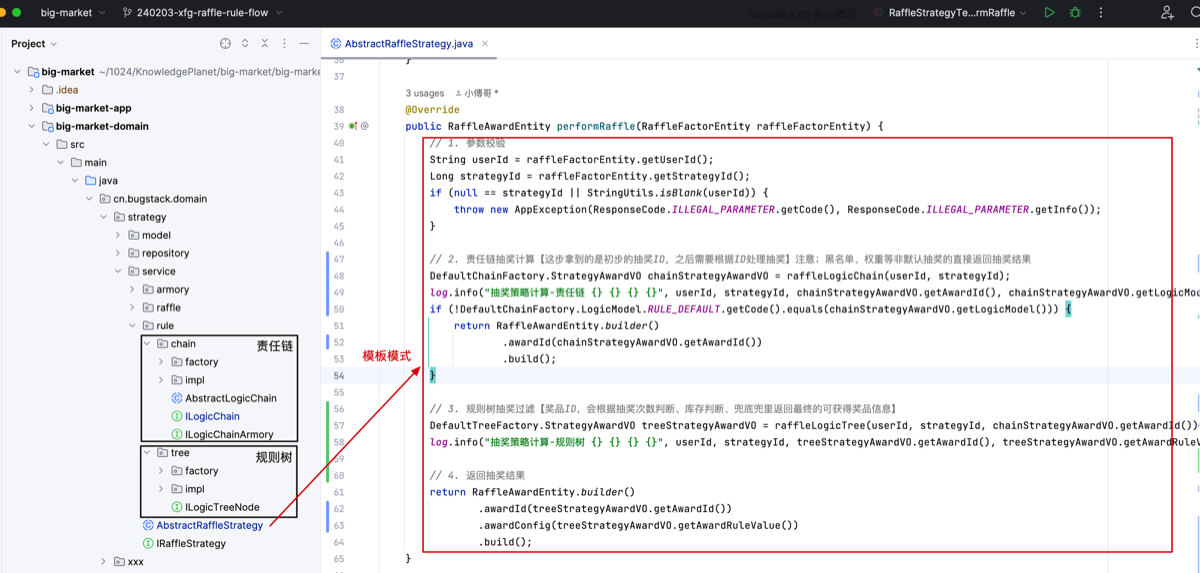
- rule 规则部分,保留;责任链、规则树,去掉之前的 filter 过滤器。
- 在 AbstractRaffleStrategy 抽象类,串联调用流程。先是责任链,后是规则树。责任链处理的是不同的抽奖【黑名单、权重、默认】,处理完的抽奖结果,如果是默认抽奖则需要进行库存、次数等校验,并给出最终发奖结果。
- 本节还包括了根据上一节实现的规则树模型,设计的库表结构。并实现出仓储数据查询的操作。
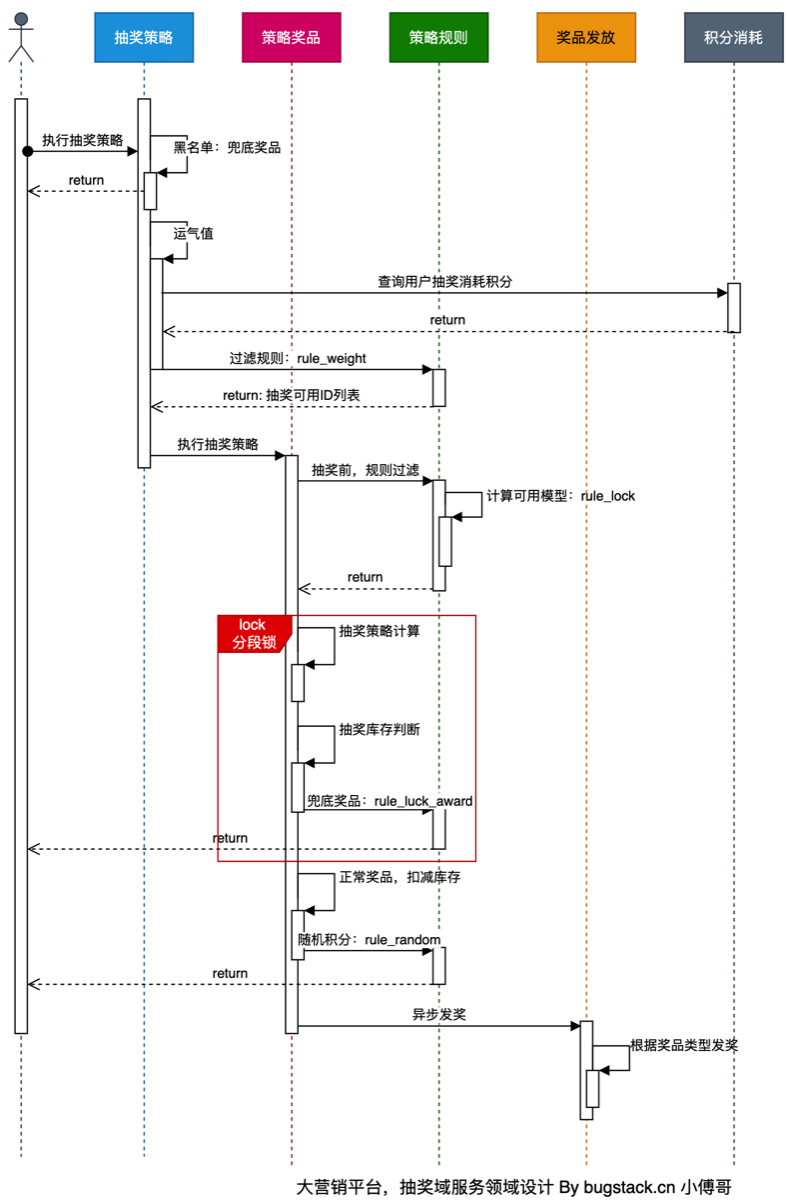
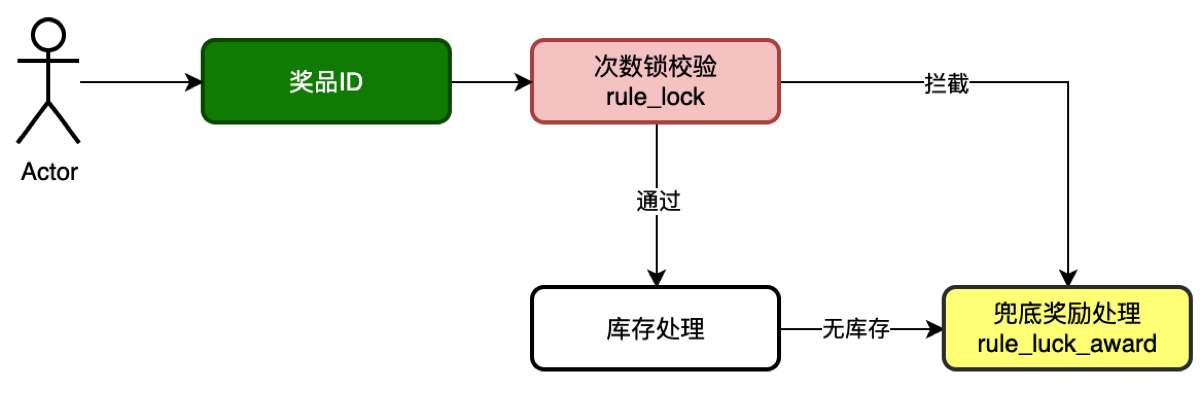
10.不超卖库存规则实现
- 本章诉求 当通过抽奖策略计算完用户可获得的奖品ID后,接下来进行这一奖品的库存扣减操作,只有扣减成功才能获得,否则走兜底奖励
流程设计
如果只对数据库进行操作,则对数据库的访问压力很大,需要用户排队,这里使用redis缓存作库存,只要做到不超卖就行
但不能用一条key加锁和等待释放的方式来处理,这样效率依旧很低
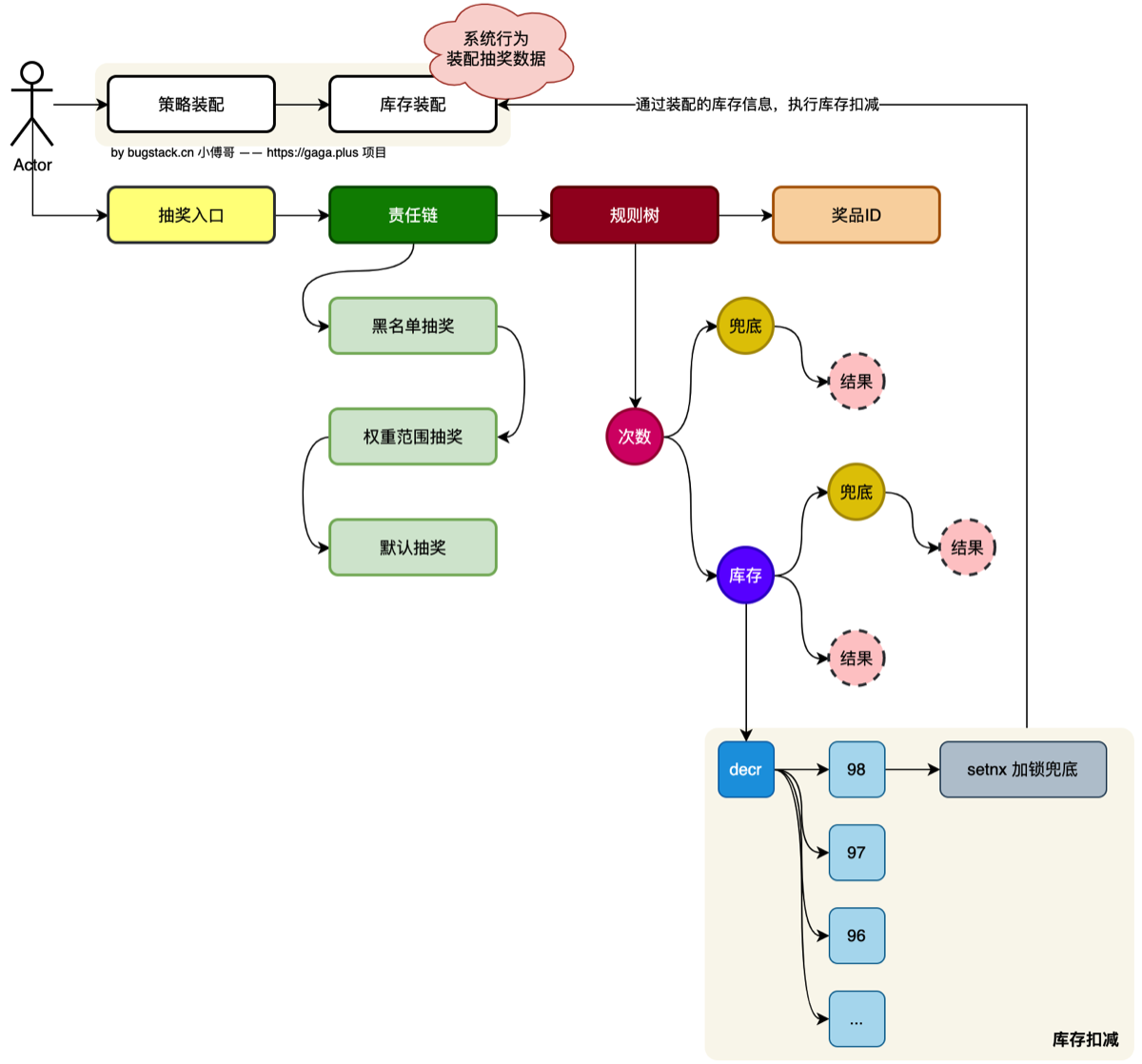
- 故在对上面所实现的规则树中,对于库存节点的操作,使用decr方式扣减库存.
- decr是原子操作,效率非常高
- 还需setnx加锁是一种兜底手段,避免后续库存的恢复
- 库存消耗完后,需要更新库表的数据量,这里通过Redisson延迟队列+定时任务,缓慢消耗队列数据来更新库表数据变化
redissonClient.getAtomicLong(key).decrementAndGet()
- 底层命令: 对应 Redis 的
DECR命令。
redissonClient.getBucket(key).trySet("lock")
- 底层命令: 对应 Redis 的
SETNX(或带参数的SET ... NX)。
场景模拟:加上 setnx 之后(文中的方案)
假设当前库存是 98。
- 用户 A 进来了,执行
decr,拿到 98。 - 系统立即执行
setnx(key="stock_token_98", value=user_a_id)。- 因为这个 Key 之前不存在,返回 True (成功)。
- 用户 A 成功锁定第 98 号库存。
- 用户 A 后续业务失败了,甚至总库存被错误地回滚回了 99。
- 用户 B 进来了,执行
decr,再次拿到了 98。 - 系统尝试执行
setnx(key="stock_token_98", value=user_b_id)。- 关键点来了:因为用户 A 之前已经写入了
stock_token_98,Redis 发现该 Key 已存在。 - 返回 False (失败)。
- 关键点来了:因为用户 A 之前已经写入了
- 系统判断:虽然
decr分配了名额,但锁失败了。说明这个“第 98 号”名额已经是脏数据(被消耗过),系统拒绝用户 B 的请求,或者让用户 B 重试(去抢第 97 号)。
在这里,setnx 的作用可以归纳为:
- 幂等性保证(Idempotency):确保每一个具体的库存 ID(如第 98 号、第 97 号)在全生命周期内只能被消费一次。
- 防止超卖的最后一道防线(兜底):即使最外层的计数器 (
count) 出现了计算错误、并发回滚错误,只要具体的token(stock_token_N) 被占用了,就不会发生两个用户抢到同一个具体商品的情况。
工程结构
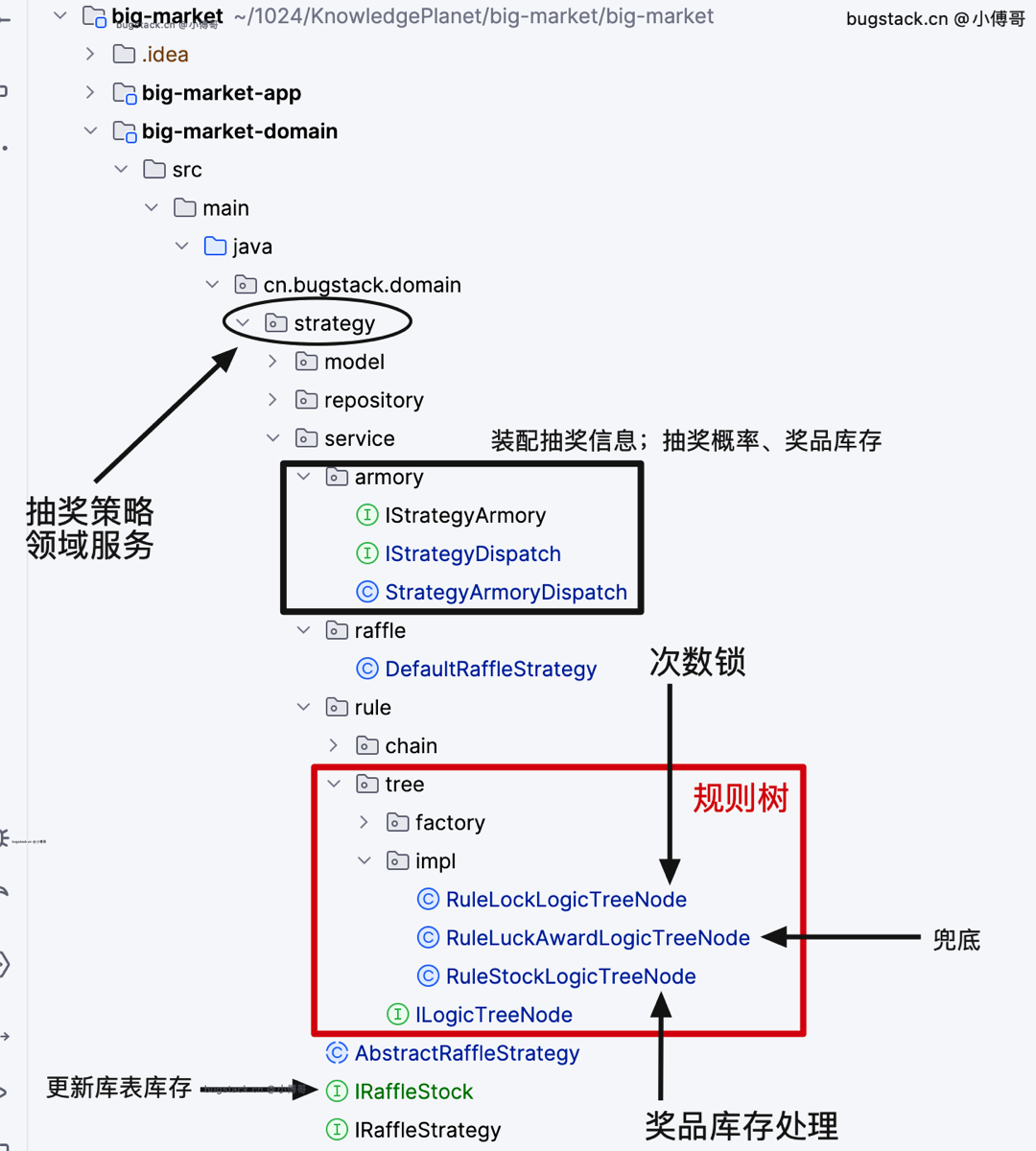
- 承接上一节规则树的使用,本节完善规则树节点的逻辑。包括;次数锁、兜底和奖品库存的处理。奖品库存的处理是大头。
- 奖品库存处理,就会涉及从 redis 缓存读取数据做 decr 扣减操作。而这部分缓存的数据,要放到装配处理里,事先做好数据的装配操作。
- 最后一步就是新增 IRaffleStock 接口,处理扣减库存结束后,写到到 redis 队列中的库存消耗数据,再由 trigger 中定时任务扫描获取 redis 队列数据,从而缓慢更新库表数据。
11.抽奖API接口实现
240215-xfg-raffle-controller
结合着前面两节(13、14) WEB UI 的开发,以及接口的 Mock 让前端调用。我们可以知道服务端应该提供的接口标准。
流程设计
在大营销的系统架构设计中,有一个 trigger 模块,专门用于提供触发操作。这里我们把 HTTP 调用、RPC(Dubbo)调用、定时任务、MQ监听 等动作,都称为触发操作。触发表示通过一种调用方式,调用到领域的服务上。
RPC 让你在写分布式代码时,感觉像是在写单机代码,通过共享一个“接口 Jar 包”作为契约,既保证了类型安全(编译时就能发现错误),又隐藏了复杂的网络通信细节.
工程结构
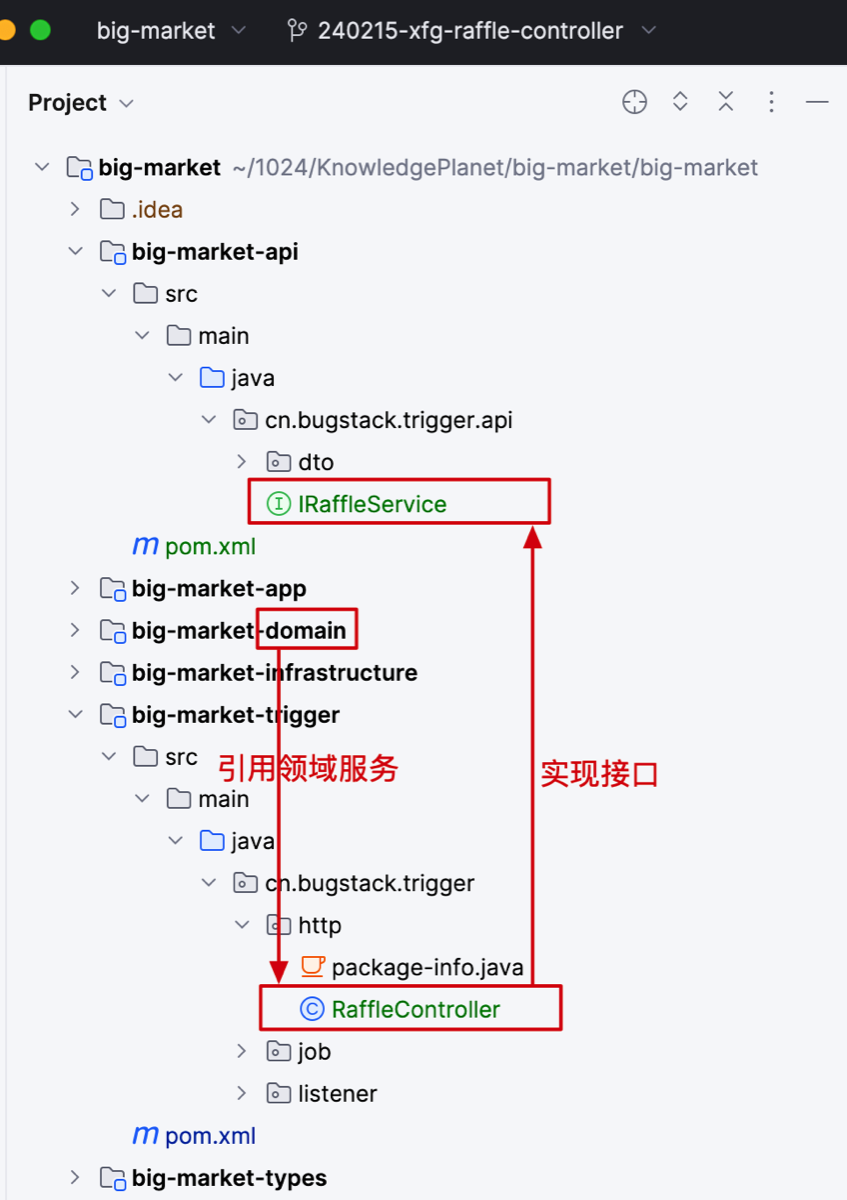
- 定义 IRaffleService 接口,由 trigger 模块下的 http 层 RaffleController 实现接口。
- 接口层的实现,直接调用到 domain 领域层。也就是我们前面所实现的抽奖策略领域服务。【本节会对抽奖策略领域服务新增接口,做到单一职责的设计】
抽奖策略
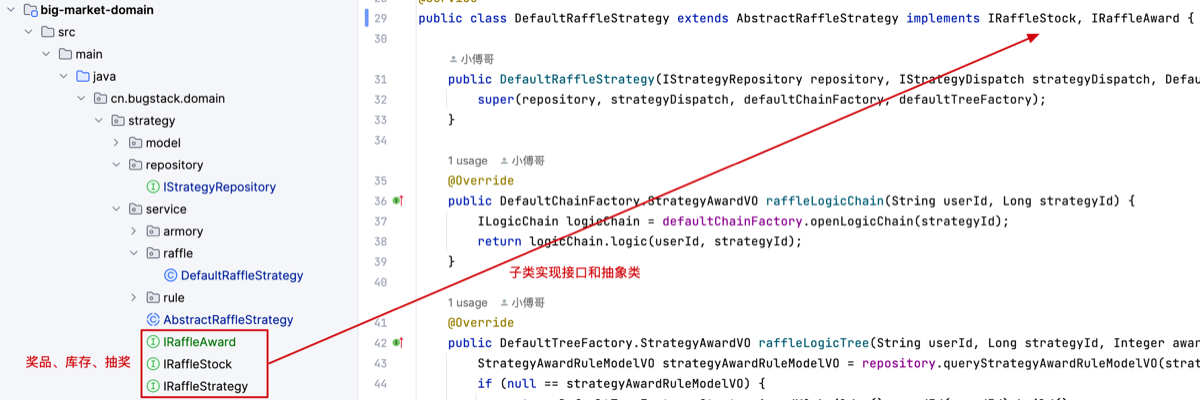
- 新增加 IRaffleAward 策略奖品接口,查询奖品信息。让 DefaultRaffleStrategy 子类实现。【注意奖品查询会用到之前的接口,并做了新的字段的增加查询】
- 调整 IRaffleStock 库存的处理接口,由子类实现。因为这两个接口,都不需要做抽象类的处理。
- DefaultRaffleStrategy 子类继承了一个抽象类,并实现2个接口。这样的结构会更加清晰,知道子类在做什么,也更好维护。
-
定义查询奖品列表接口,用于大转盘展示奖品使用。
- 注意调用到 StrategyRepository#queryStrategyAwardList 方法的时候,缓存的 Key 调整 STRATEGY_AWARD_LIST_KEY 这个是查询 List 的结果。在查询字段上,增加了 额外的内容,如 sort。
-
抽奖策略接口返回的结果 RaffleAwardEntity 需要调整下字段。在我们前面章节实现的前端 UI 中知道,抽奖优先根据奖品列表的顺序ID进行抽奖,正好这个字段是我们数据库设计的 sort 排序字段。所以我们在 RaffleAwardEntity 中新增加这个字段来使用。
对外接口
在API中定义3个接口;策略装配接口、查询抽奖奖品列表配置、随机抽奖接口。
在trigger层,实现上面的接口,写入具体逻辑(头上顶RequestMapping注解),同时封装对应的错误码
- 策略装配,将策略信息装配到缓存中;/api/v1/raffle/strategy_armory
- 查询奖品列表;/api/v1/raffle/query_raffle_award_list
- 随机抽奖接口;/api/v1/raffle/random_raffle
其他调整
4.1 规则树节点判断 DecisionTreeEngine#nextNode 决策树引擎的判断下一个阶段方法,在找不到下一个阶段的时候返回 null 不需要抛异常。null 结束即可。 4.2 缓存获取值判断* 在通过缓存获取抽奖范围值时,如果忘记初始化策略到缓存中会抛异常。所以新增加了判断代码,增强健壮性。
12.用户参与抽奖活动库表设计
240302-xfg-table-activity
在一个营销场景中,抽奖的流程分为;参与的有效期、整体的预算库存、个人的可参与次数、之后是抽奖策略的计算处理,返回抽奖结果。 大营销第1阶段已经完成了抽奖策略的领域模块实现,接下来则需要设计一个外壳,把抽奖策略包装进去。这个外壳就是一个抽奖活动的配置,在活动上有相关的库存、时间、状态,个人在总、日、月分别可进行的参数次数判断。
业务流程
以用户参与活动为视角,来理解整个业务流程
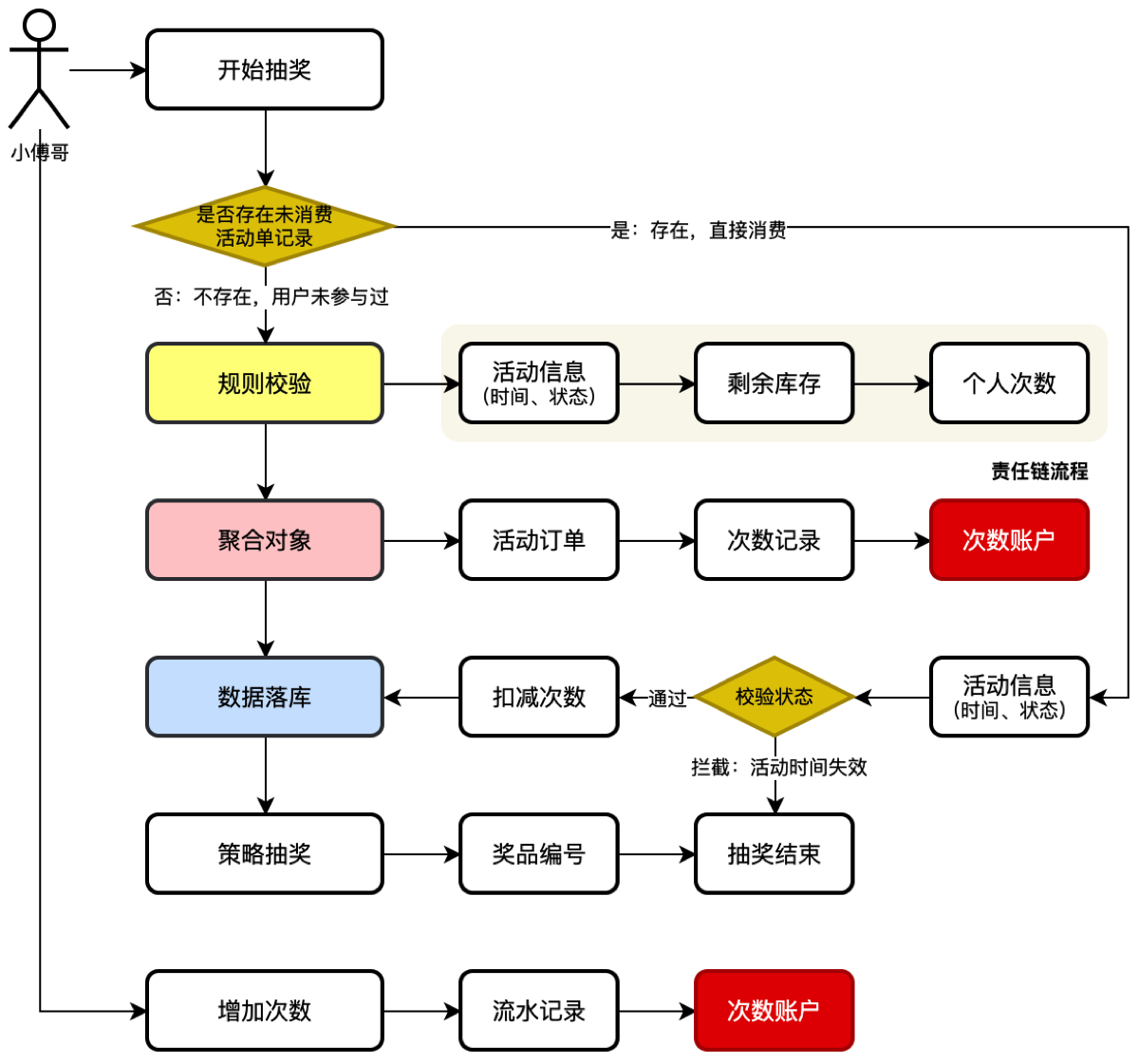
- 我们可以把用户参与抽奖理解为pdd的一次下单,下单后才具备参与抽奖的资格。而下单的过程中,则需要过滤活动的相关信息以及库存数据。
- 所有的判断流程做完后开始写入库中,库中则是用户一个互动的次数账户记录。记录着用户可以参与的抽奖次数。同时需要把参与活动的记录写一条订单。
- 此外为了扩展用户在一些场景中,首次【签到/登录】可以赠送一个抽奖次数外,还可以通过购买、做任务、兑换等方式获得新的抽奖次数。这样用户就可以不断地消耗自己的积分兑换抽奖次数来抽奖了。
库表设计
整个设计分为5张表;两个活动配置表(抽奖活动表、参与次数表)、三个用户领取表(活动下单记录、活动次数账户、账户次数流水)
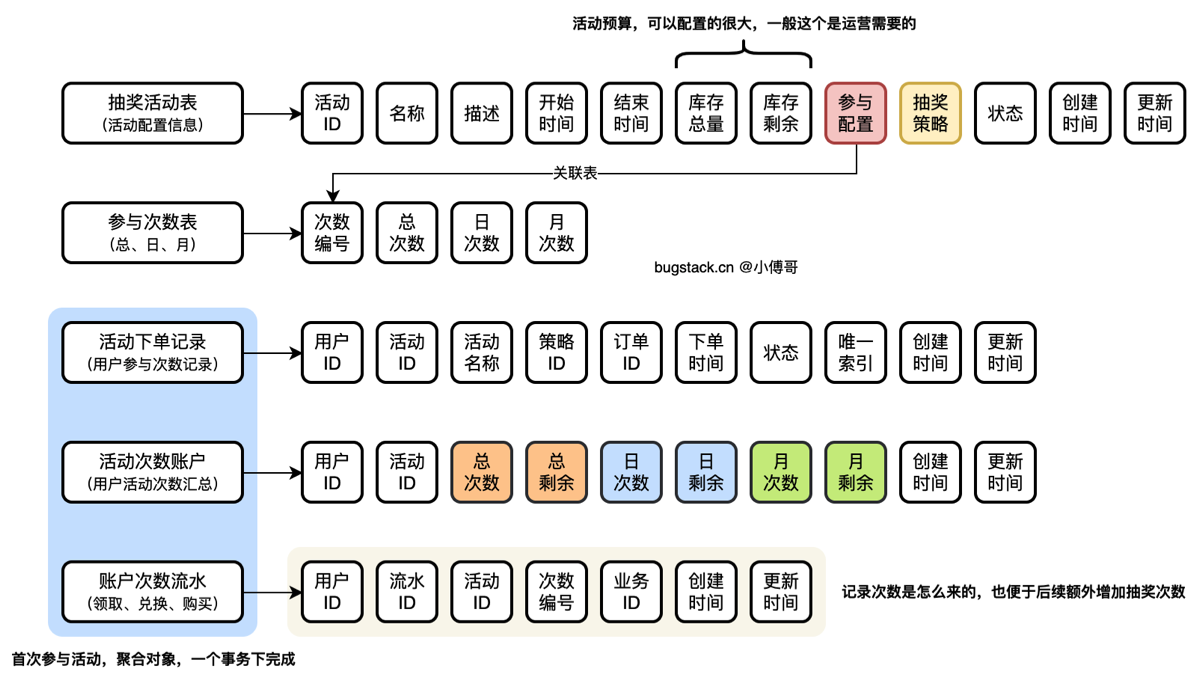
- 抽奖活动表,配置了用户参与一个活动的时候,需要进行的必要信息判断。时间、库存、状态等。
- 参与次数表,单独分离出来。这样更方便后续基于不同的次数编号,做扩展。比如兑换一个新的抽奖次数。
- 活动下单记录表,用户参与活动,则需要先创建一笔订单记录。如果用户抽奖中有失败流程,也可以基于订单的状态,用户重新发起抽奖,也不会额外占用库存记录。
- 活动次数账户表,记录着一个用户在一个活动的可参与次数数据,也就是个人活动账户。
- 账户次数流水表,每一笔对账户变动的记录,无论是任何的方式的变动,都要有一条流水。
13.引入分库分表路由组件
分库分表在分布式架构中是一种非常常用且成熟的数据存储方案,如果早期设计为单库单表,后期要扩展为分库分表时,迁移成本和工程改造成本非常大
假设你有 物理机A 和 物理机B。为了省钱且安全,可以这样部署:
- 物理机 A 运行两个虚拟机:
- VM1:跑 库1的主节点
- VM2:跑 库2的备节点
- 物理机 B 运行两个虚拟机:
- VM3:跑 库2的主节点
- VM4:跑 库1的备节点 效果:
- 资源利用率:两台机器都跑满了,没浪费。
- 安全性:如果物理机 A 停电了,物理机 B 上有“库1的备节点”,可以立刻顶上,数据不丢失,服务不断。
- 分库分表:逻辑上你已经拥有了“库1”和“库2”两个库。
当需要扩充数据库时,只需要再买物理机,讲其中2个虚拟机合并到之前分库分表的配置即可
功能流程
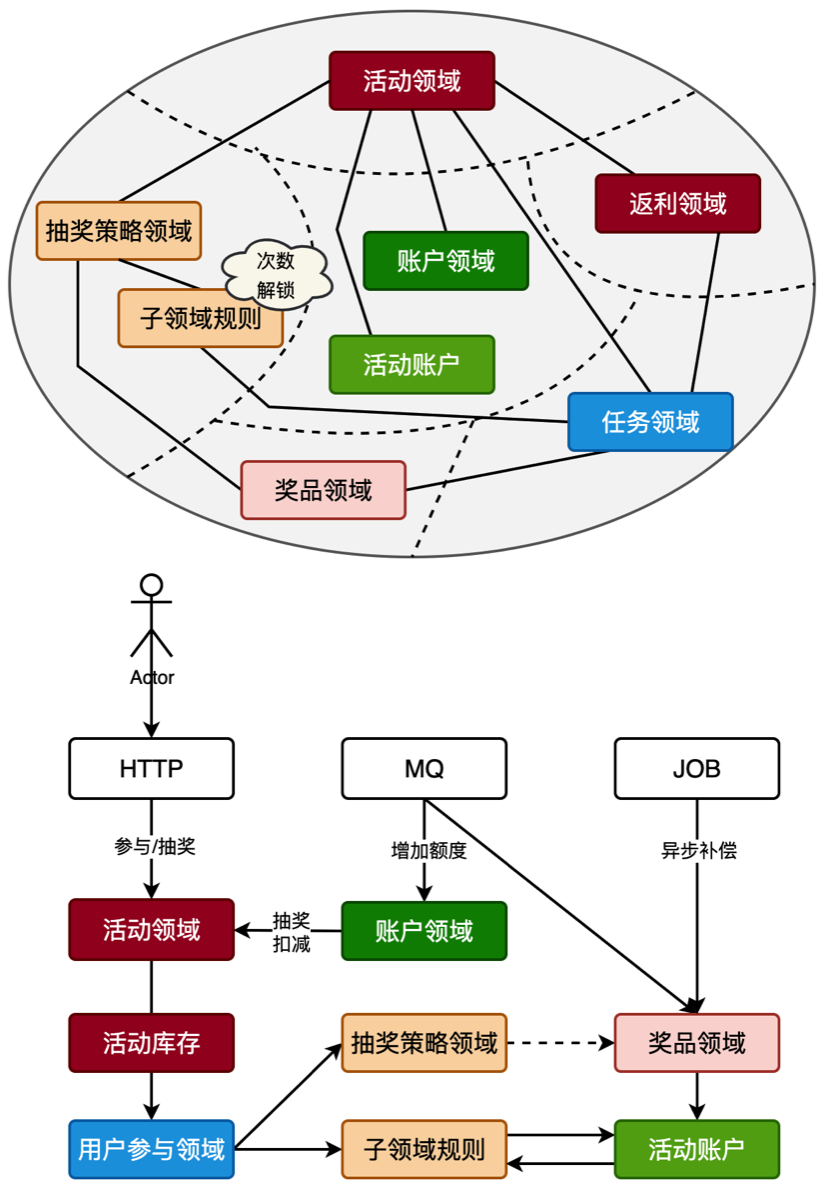
在大营销的系统设计中,有一个配置库(big_market)和两个分库(big_market_01、big_market_02),我们需要对两个分库进行配置路由操作。达到分库分表的目的,而配置库则是一个单库单表存储活动等配置类信息。分库分表调用流程【如图】
- 这里使用的开源的数据库分库分表路由组件(DB-Router),而非sharding-jdbc
- 以用户对数据库的操作为视角,发生用户类的行为操作时【账户、下单、流水】,则会根据用户ID(userId)进行路由,把数据分配到x库y表中。
- 路由计算的处理,是以配置了 @DBRouter注解的 DAO 方法进行路由切面开始。通过获取用户ID(userId)值进行哈希索引计算。哈希值 & 2从n次幂数量的库表 - 1 得到一个值,在根据这个值计算应该分配到哪个库表上去。比如这个是6,分库分表是2库4表,共计8个,那么6就分配到了1库4+2库2个等于6,也就得到了2库2表。
- 对于计算得到的分库分表值,存入到 ThreaLocal 中,这个东西的目的是可以在一个线程的调用中,可以随时获取值,而不需要通过方法传递。
- 最后 Spring 在执行数据库操作前,会获取路由。而路由组件则实现了动态路由,从 ThreadLocal 中获取。此外注意,因为还有分表的操作,比如 table 需要为 table_01 这个动作是由 MyBatis Plugin 插件开发实现的(拦截器)。
数据源配置
(和JDBC好像)
- dbCount 分几个库,tbCount 分几个表,两个数的乘积为2的次幂。
- default 为默认不走分库分表时候路由到哪个库,这里是我们需要的配置库。
- routerKey 默认走的路由 Key,一个数据路由,是需要有一个键的,这里选择的是用户ID作为路由计算键。
- list: db01,db02 表示分库分表,走那套库。
- db0、db1、db2 就是配置的数据库信息了。这里给每个数据库都配置了对应的连接池信息。
库表使用
在 big-market-infrastructure 基础层,配置路由操作。

就是在sql语句时插入注解
14.抽奖活动订单流程设计
240316-xfg-activity-order-design
本节我们要设计出,用户参与抽奖活动的流程设计,并可以支持后续满足用户通过不同行为来增加自己的抽奖次数。 那么站在本节的诉求上,小傅哥将会带着读者对前面所设计的活动库表做一个解耦操作。来满足后续流程中个人可参与抽奖活动次数的变化处理。
功能流程
我们可以把抽奖的行为理解为一个下单过程,用户参与抽奖,也等价于商品下单。只不过这个商品的 sku 是活动信息。
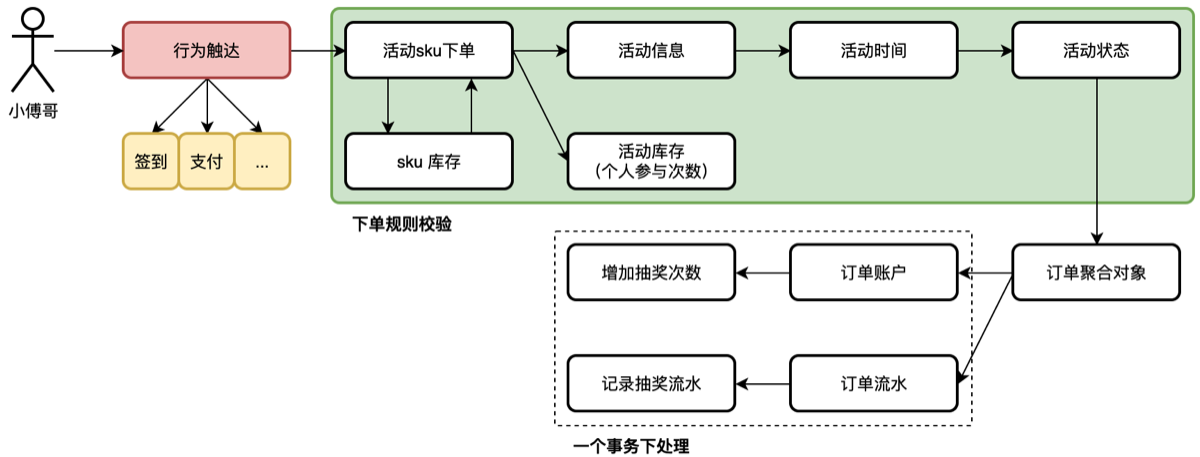
- 用户的触达行为是后续需要扩展的部分,当我们把大营销结合给其他系统的时候,就可以让支付后的消息推送过来,给用户领取一次抽奖次数。并参与抽奖。【还记得你在商城,或者一些云服务购买后,可以参与抽奖的过程吗?】
- 在上一节,小傅哥是把活动的可参与库存、用户的库存,都配置到活动本身。那这样就有一个问题,比如不同的场景,所需要在一个活动上给用户分配的抽奖次数不同,那么就不好配置了。所以我们要抽象一下,把活动和个人参与的次数,从活动配置中解耦出来,并通过 sku 商品表的方式配置出这样一组商品信息。
- 另外,在活动信息表中,还有活动的库存。这里我们把活动的库存也提取出来,放到 sku 上。一个商品的 sku 能下单多少次,由 sku 管理就行了。
库表调整
按照我们的功能流程设计,新增加 sku 表,并去掉分库分表中的 flow 流水表,而是直接由 order 订单表提供。
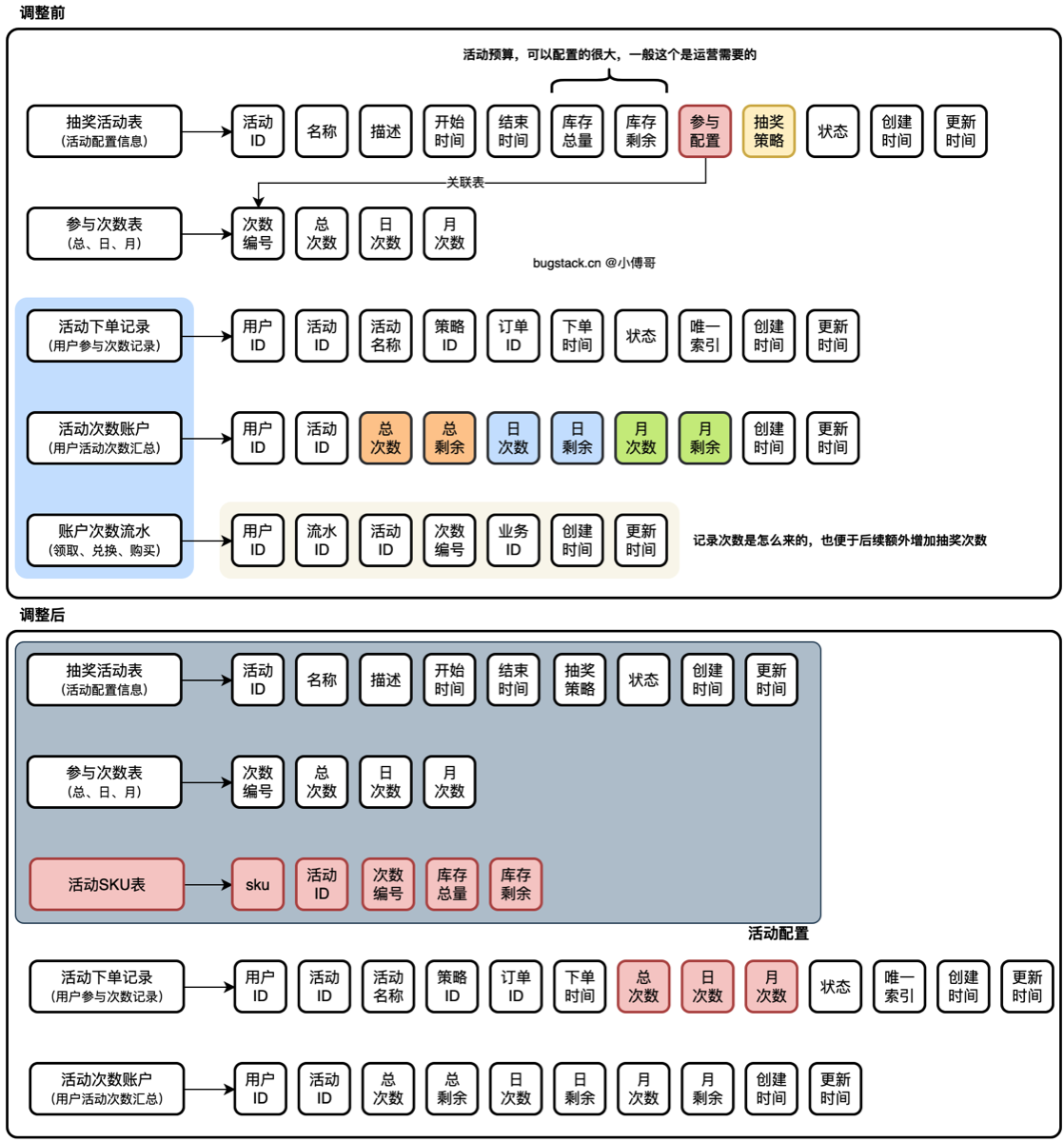
- 首先,去掉活动表中的关联操作,并新增加活动 sku 表来做关联。这样就可以把活动和参与次数当成一种物料,之后 sku 来定义库存或者将来想扩展价格或者积分兑换也是可以的。
- 之后,去掉原来的次数流水表,把流水的用途合并到订单表中。想获得更多的抽奖次数,就直接对 sku 下单即可。无论是通过赠送、签到、打卡、积分兑换等任何方式,都是可以的。这样也就增强了营销活动的扩展性。
- 注意:调整的库表信息,已经放到了导出sql语句,放到本节分支下 docs/dev-ops/mysql/sql 下。
工程结构
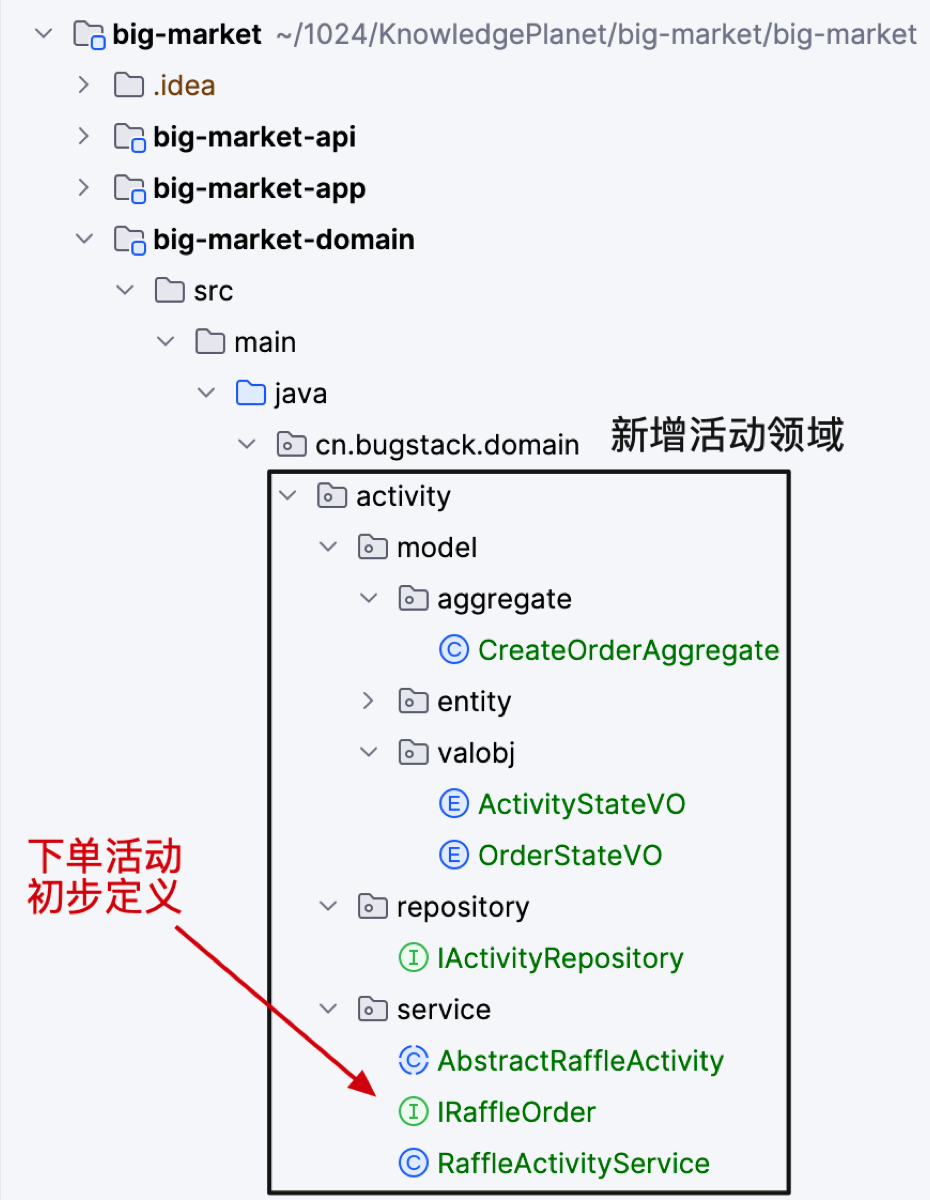
- 在 domain 领域下新增加活动领域模块。在这个模块下会陆续提供出活动的下单、配置等服务。学习中可以以此为入口,查看到对应的基础层、启动层(app)的变化。
- 本节先初步定义出领域模块和下单抽奖的抽象类,抽象类的作用是定义一个执行下单的标准流程。后续将逐步完成这块的功能。
- 其他所涉及的对象可以参考工程或者视频来看。在 DDD 规范中,通常会把具有唯一ID标识,影响数据库数据变动的操作,定义为实体对象。而用于描述对象属性的值,如枚举值、没有生命周期对象,可以被定义为 VO 对象。
15.抽奖活动流水入库
在基于活动、次数所组合的活动 sku,用户参与活动就相当于,下单sku给自己的活动账户充值可参与的额度次数。所以本节把活动的下单的过程落入到数据库中。
本节写库会涉及到分库分表组件切分和开启事务的操作。
功能流程
按照上一节我们对活动流程的设计,用户参与抽奖活动就会有一个活动额度账户,而本节则让来实现参与活动对自己的活动额度账户充值的过程。
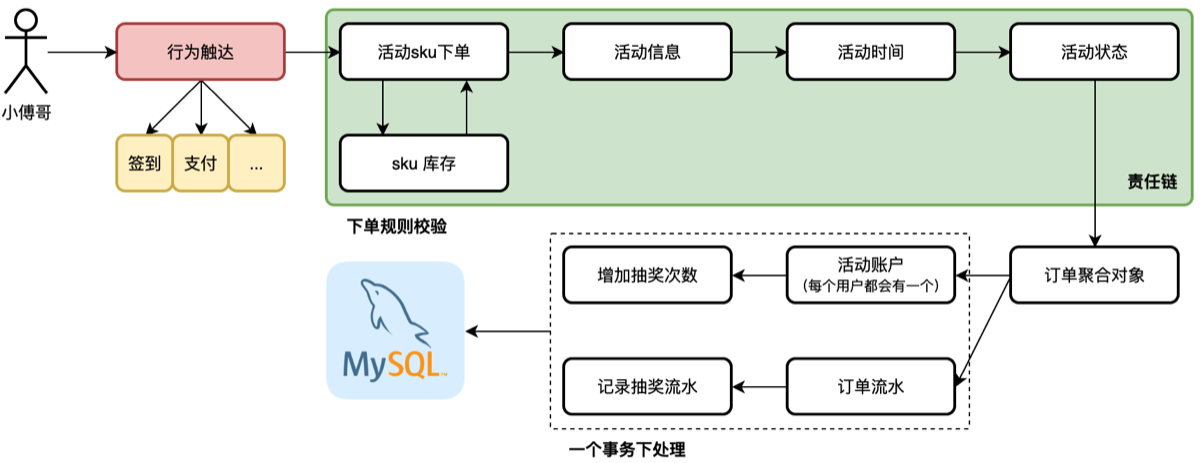
- 本节会先实现出领取活动的框架结构代码,并对数据进行落库操作。(落库的过程会有分库分表下事务的操作)
- 活动日期、活动状态、sku库存校验和扣减,这些都是固定的流程。无论创建多少个活动都会走这样的统一流程,所以这里适合添加一个责任链模式的结构。
- 因为是分库分表设计,所以库表数据的写入需要确定切分键,并在同一个连接下执行 commit 这样才能把用户的活动账户和订单流程,一起写库。(也就是一个事务的特性)
库表调整
我们给用户增加的账户充值下单动作,需要外部透传对应的业务唯一ID 这样才能保证幂等。允许外部用同一个单号请求多次,但结果相同。
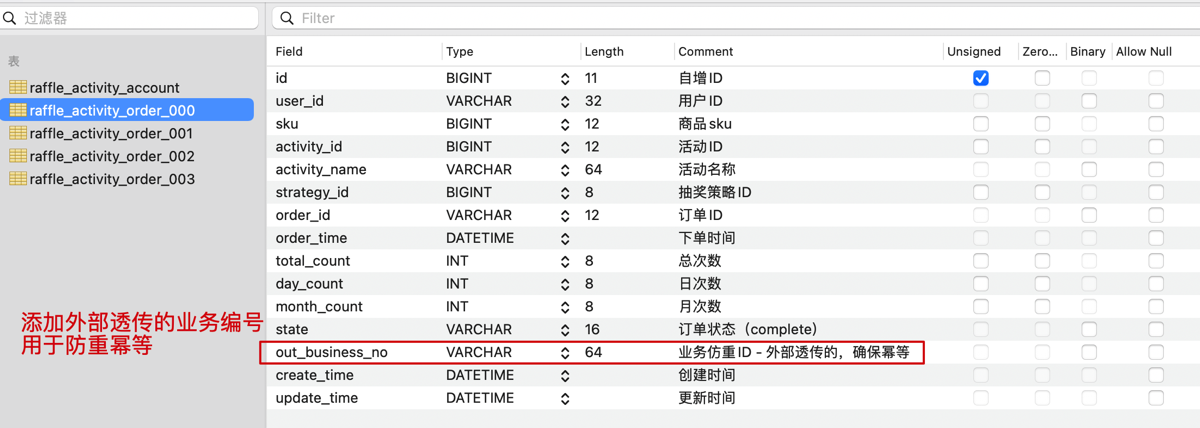
- out_business_no 是一个唯一索引字段,这样也就确保了重复的插入会有唯一索引冲突。通过冲突的异常来告诉调用者,这个业务ID的业务已经处理了。
工程结构
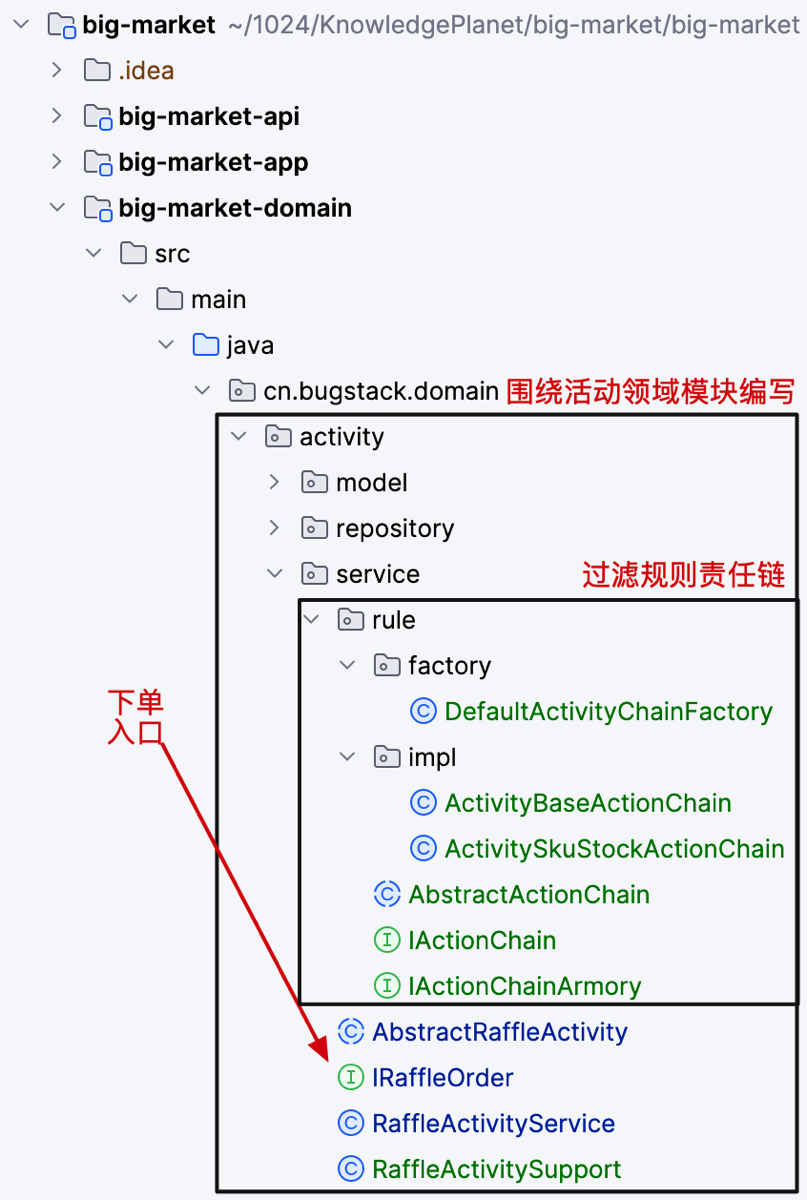
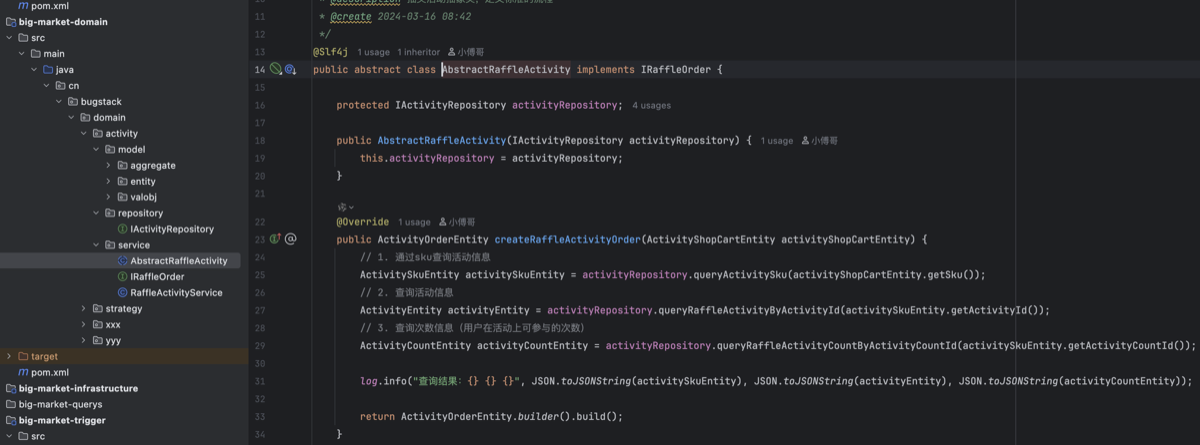
以 domain 下的 activity 领域模块进行功能实现;
- IRaffleOrder 是抽奖下单的入口,也就是给用户在当前的这个活动,个人的账户上充值。比如这次是允许抽奖1次。
- AbstractRaffleActivity 是抽象类,定义出抽奖下单的流程。
- RaffleActivitySupport 是支撑类,类似 Spring 源码中也会有 XxxSupport 来提供数据支撑。这样可以简化抽象类(AbstractRaffleActivity)里的代码量。
- RaffleActivityService 是抽象类定义的抽象接口由此类实现。
- rule 模块下是责任链的规则实现部分。
- 抽象类定义出了整个抽奖活动的充值过程;参数校验、查询基础信息(由支撑类提供)、活动动作规则校验(这部分是责任链的处理,暂时先实现结构)、构建订单聚合对象、保存订单、返回单号。
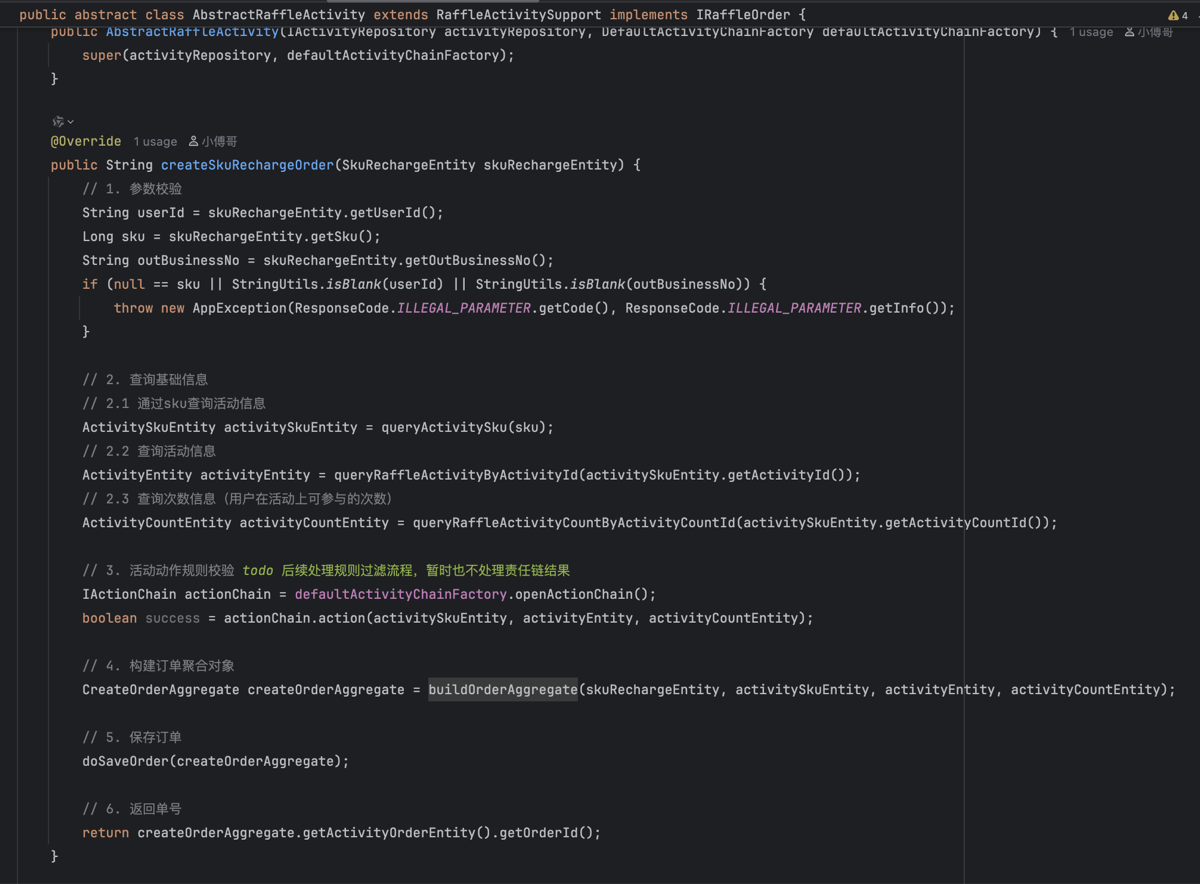
-
这一部分的重点主要是到写库操作这块。
-
dbRouter.doRouter(createOrderAggregate.getUserId()); 是在确定路由的结果,也就是让 Spring 知道应该链接到哪个库上去。
-
transactionTemplate 的操作是编程式事务,事务中操作了2个表。只有这2个表在同一个库,同一个连接上,才能确保一次 commit 提交下的事务。
-
整个过程完成后执行 dbRouter.clear; 也就清理掉了路由组件中 ThreadLocal 中的值。
-
责任链需要一个规则接口,一个组装规则的接口,一个抽象类来填充责任链。
-
之后是实现责任链接口的各个具体要处理的规则操作,比如;活动基础信息校验,活动库存处理。
-
此外还有一个责任链的处理工厂,负责将各部分责任链对象注入进来后加工组装出一个责任链的链条⛓。就像我们讲的,这个责任链是一个固定结构的链接,所以在工厂中提供个统一的链就可以了。
16.引入MQ处理活动SKU库存一致性
完成上一节内的责任链内部的逻辑,包括日期,状态,sku库存
- sku库存的扣减操作
- 判断缓存库存和数据库存一致性问题
- 先在策略阶段采用延迟队列作趋势更新
- 引入MQ,在库存消耗空后发送MQ消息,直接更新清空库存
功能流程
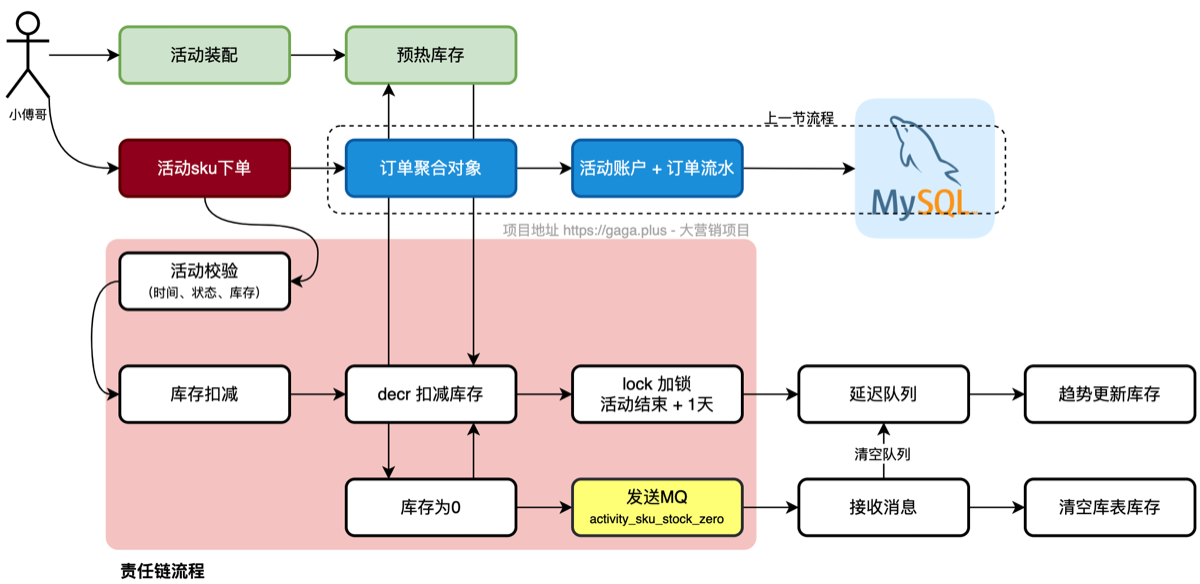
- 第一步;完成责任链的活动校验,时间、状态、库存。
- 第二步;对库存的扣减,使用 decr + lock 锁的方式(兜底)进行处理。
- 第三步;做完库存扣减后,发送延迟队列,由任务调度更新趋势库存,满足最终一致。
- 第四步;库存消耗为0后,发送MQ消息,驱动变更数据库库存为0
工程结构
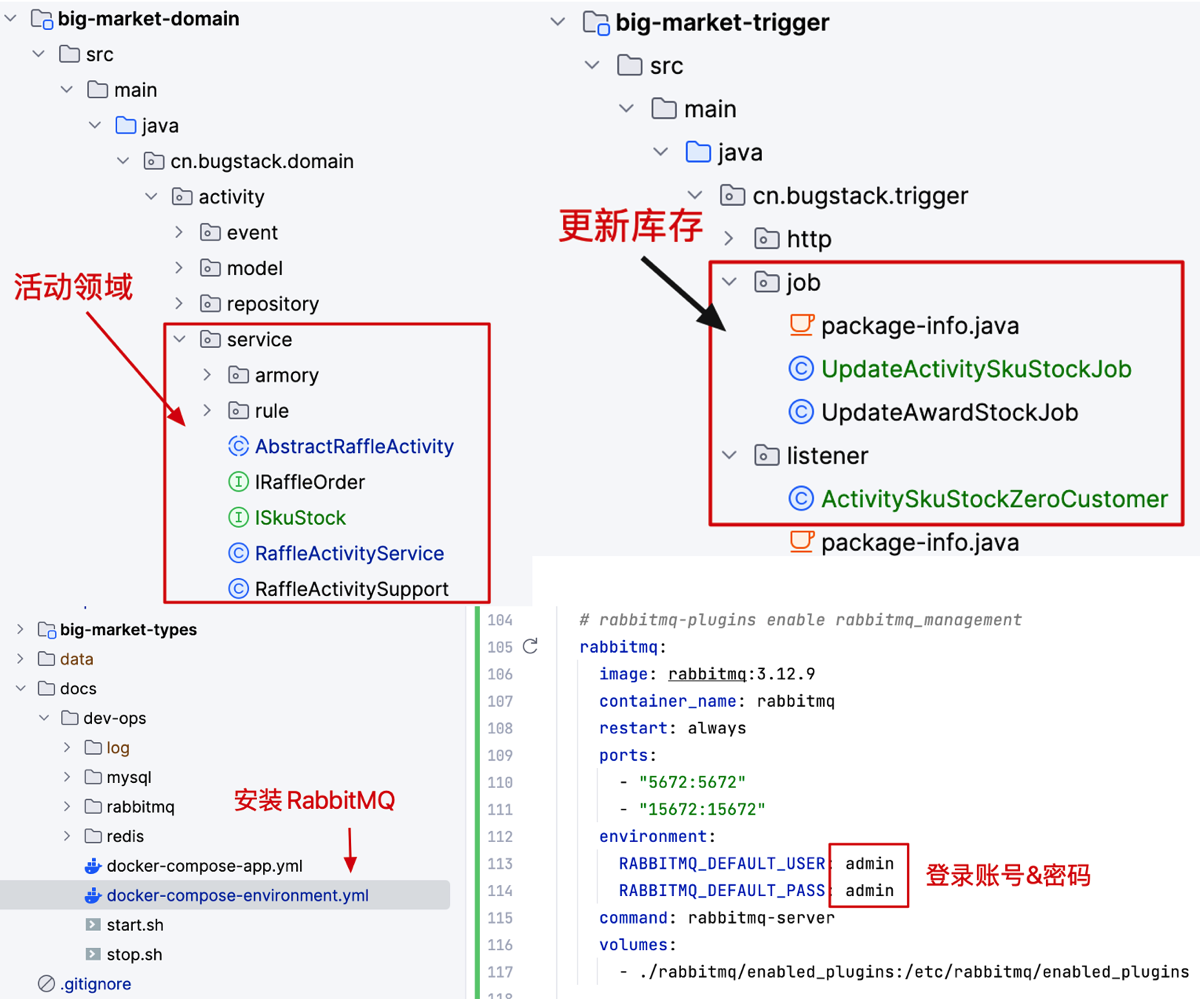
- domain 领域层是本节要实现的核心主功能,以完善开发上一节的活动责任链功能和扩展出 ISkuStock 接口的能力。
- trigger 是触发器层,用于接收mq消息、执行任务,和http请求的处理。本节会在 listener 中消费 mq
-
活动预热的代码书写assembleActivitySku(与抽奖预热相同)
-
责任链的内部链条逻辑填充粉红框内(包括1️⃣基础的校验,2️⃣库存的扣减)
- 消息队列代码activitySkuStockConsumeSendQueue与最终一致性判断subtractionActivitySkuStock(库存清空),这俩在2️⃣库存扣减逻辑内的具体实现
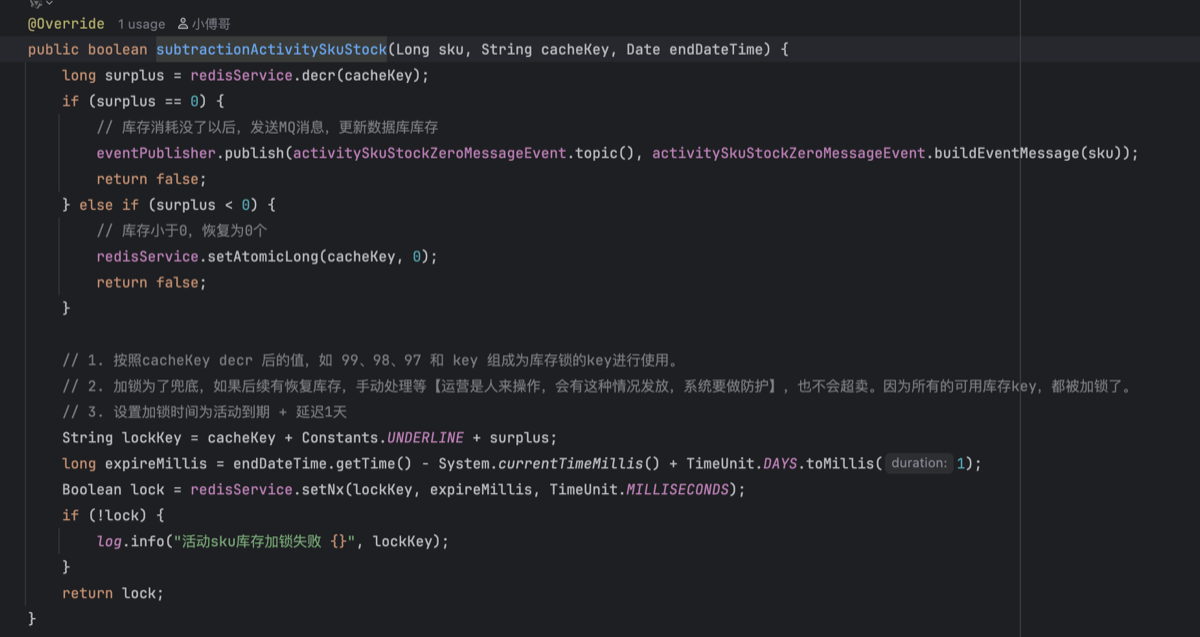
-
监听消费代码ActivitySkuStockZeroCustomer
17.用户领取活动库表设计
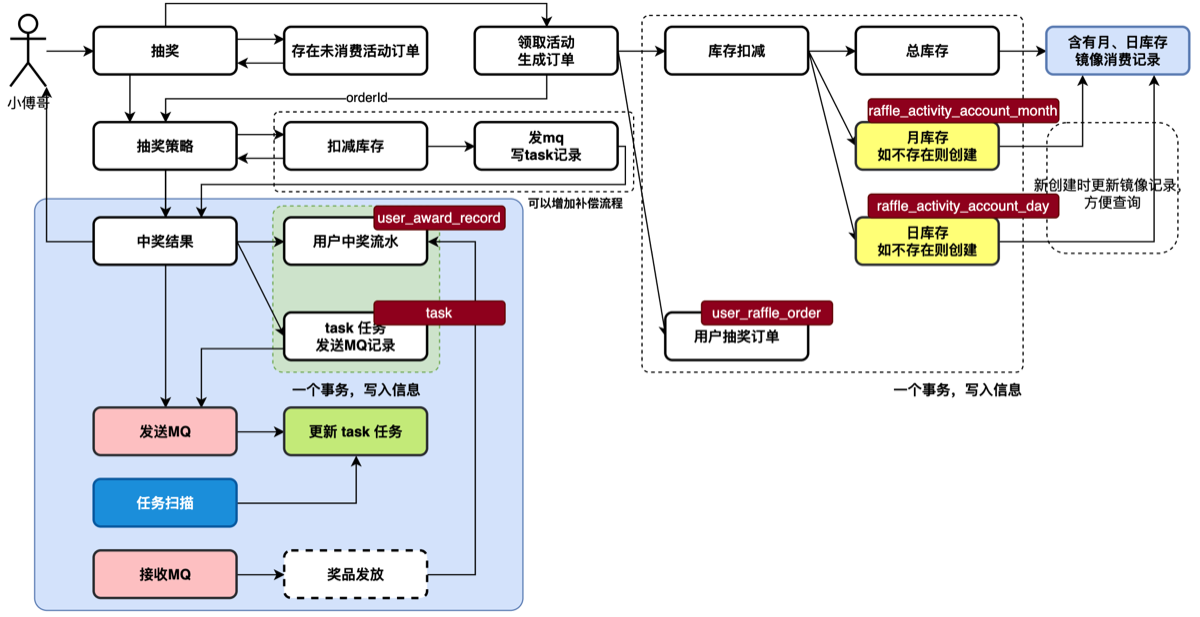
设计用于,用户参与活动所需的库表。从用户参与活动,扣减个人活动账户次数,创建活动订单。抽奖完成获得奖品ID后,写入中奖记录和task任务表(发mq补偿使用)。之后发送MQ消息,更新中奖记录。 这一套流程,需要本节增加6张表。—— 小傅哥给大家的这些设计,都是来自于真实的场景中,而不是随便一张库表就只写 CRUD 。
业务流程
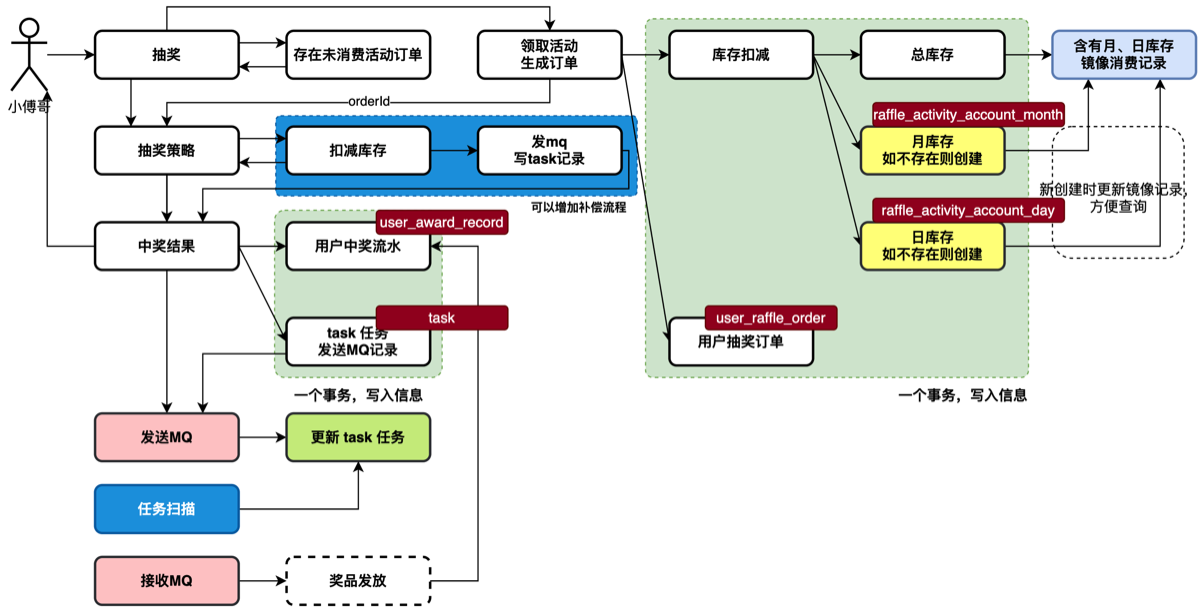
- 首先,用户抽奖开始,需要领取活动,扣减个人账户额度。生成一个抽奖订单。每个用户都有一个活动账户额度,里面包含了;总可参与次数、月可参与次数、日可参与次数。这样的设计是为了应对复杂的业务需求。那么有这样的表,就不能只是在一个表里扣减额度,因为每天都要扣减额度,但只在一个账户中扣减,日的次数第一天扣减完,第二天相当于回复为原始库存继续扣减。所以这里要生成一个出每日活动账户,当前则在自己的日账户中扣减。而总库存的日,是一种镜像记录,方便查询统计的。
- 账户,在扣减额度和用户的订单,要在一个事务内完成。但不能和后续的抽奖结果继续做事务,因为抽奖的过程还有很多的操作,而已包括缓存的处理,而他们都不能做事务。所以这部分是分开的。
- 之后,抽奖策略结果计算完毕后,把奖品ID写入中奖记录表中,同时写一个 task 任务表。任务表是发 MQ 消息的。但在写入完成奖品订单后,则直接发送一个 MQ 消息【发送后更新 task 表状态】,如果发送失败则还有 task 任务表,由 job 任务扫描的方式处理。这样可以尽快的发送 MQ 消息。
- 最后,接收发送的 MQ 开始发放奖品,本节暂时先不处理奖品的发放。
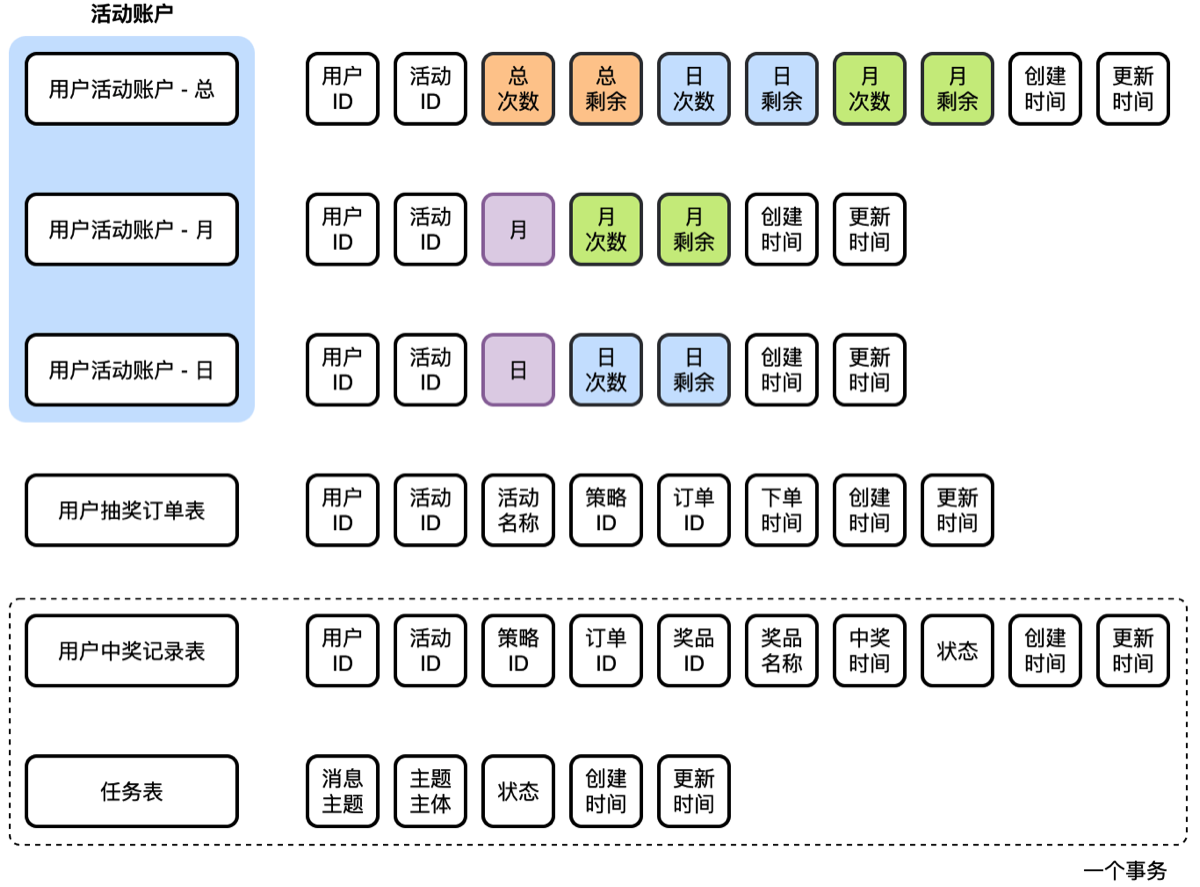
- 活动账户(月、日),分别记录每日和没有的参与次数。每天一条记录和每月一条记录。
- 用户抽奖订单表,则是每个用户参与抽奖的时候产生的订单。
- 用户中奖记录表,则是参与抽奖后获得具体奖品的记录表。
- 任务表,用于发送MQ消息。通过任务扫描发送,是一种兜底设计。
18.领取活动扣减账户额度
240405-xfg-activity-partake
活动领域包含三个核心子领域:
- 活动部署
- 活动账户充值
- 用户参与活动
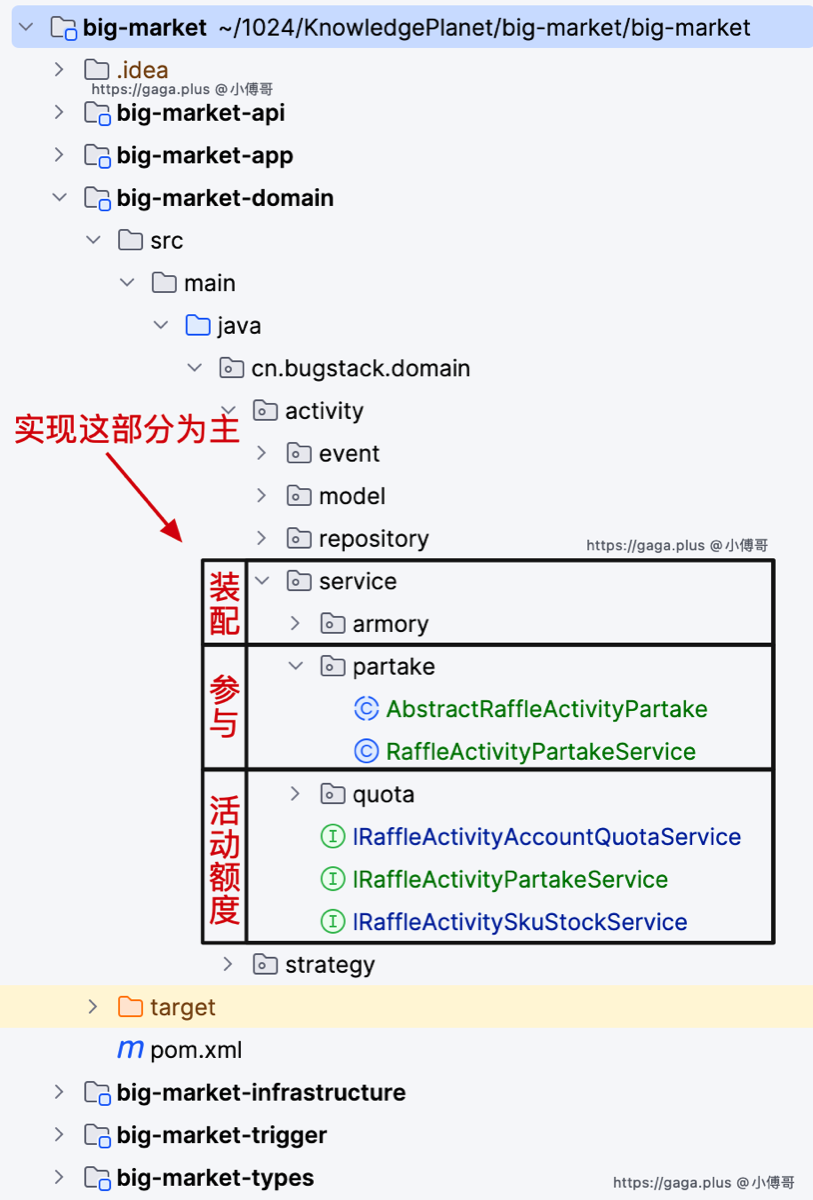
类似的,上面的策略领域只有一个核心子领域:
- 策略装配
- 具体规则:树,责任链
- 抽奖动作
业务流程
用户抽奖的业务流程分为;给自己的活动账户添加额度(购买、兑换、打卡),领取活动(扣减互动账户额度)、执行抽奖策略、抽奖结果落库。本节实现到领取活动部分。 在本节实现中先给原有实现额度充值的对象,新增加 quota 额度子领域文件夹,迁移类进去以及调整类名。这样一个活动类下就有 quota、armory 两个子领域了,之后本节在增加一个 partake 参与活动的领域。
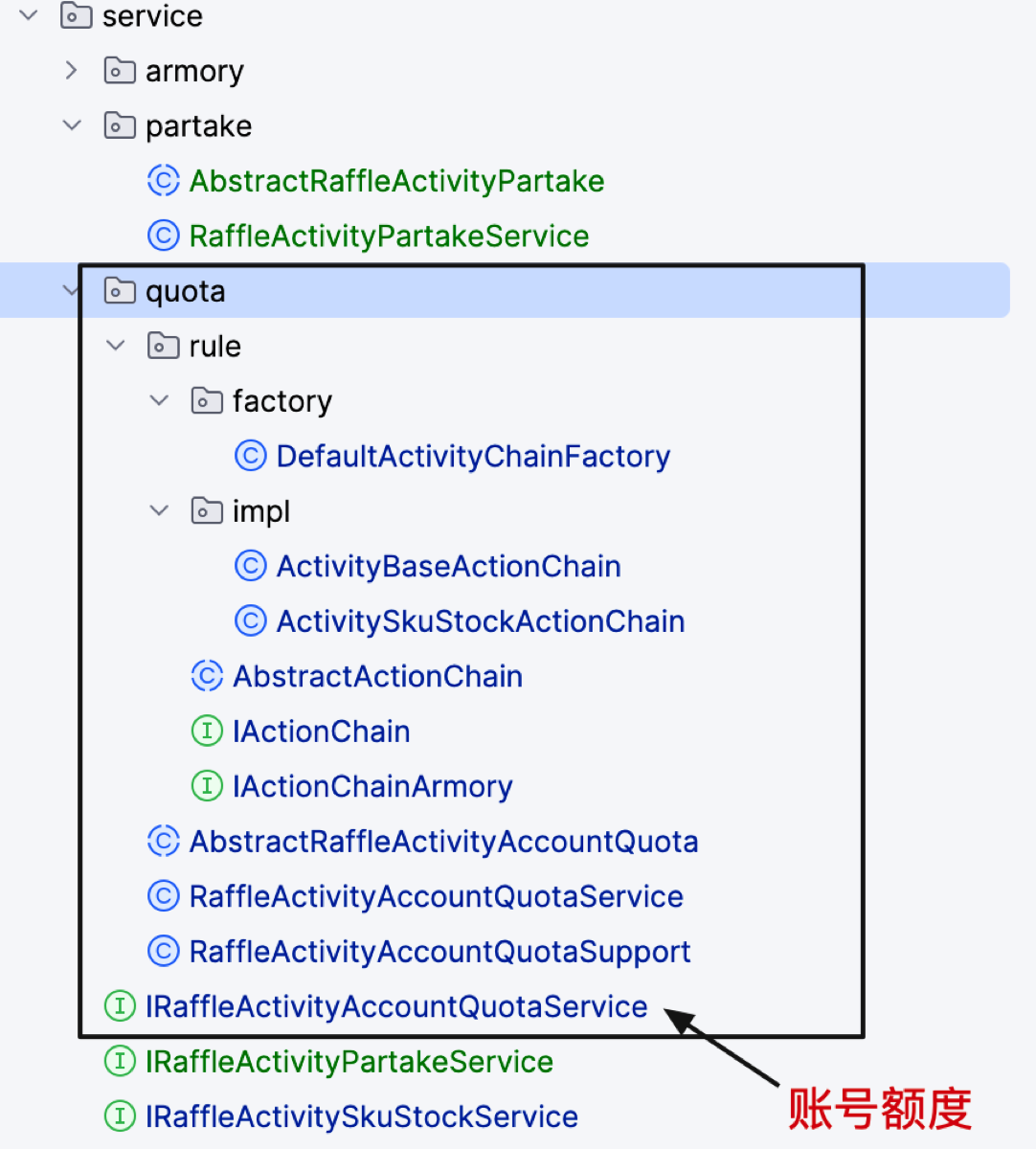
- 创建活动订单创建接口IRaffleActivityPartakeService:createOrder…
- 抽象类实现接口AbstractRaffleActivityPartake
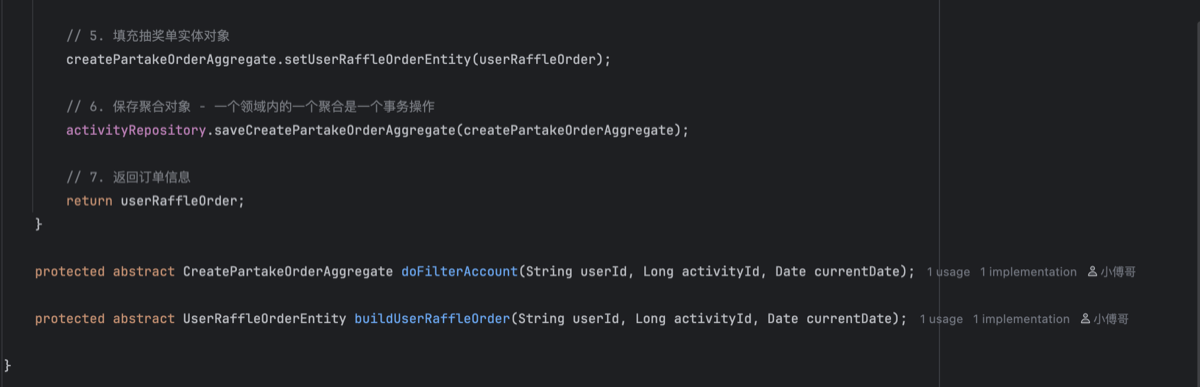
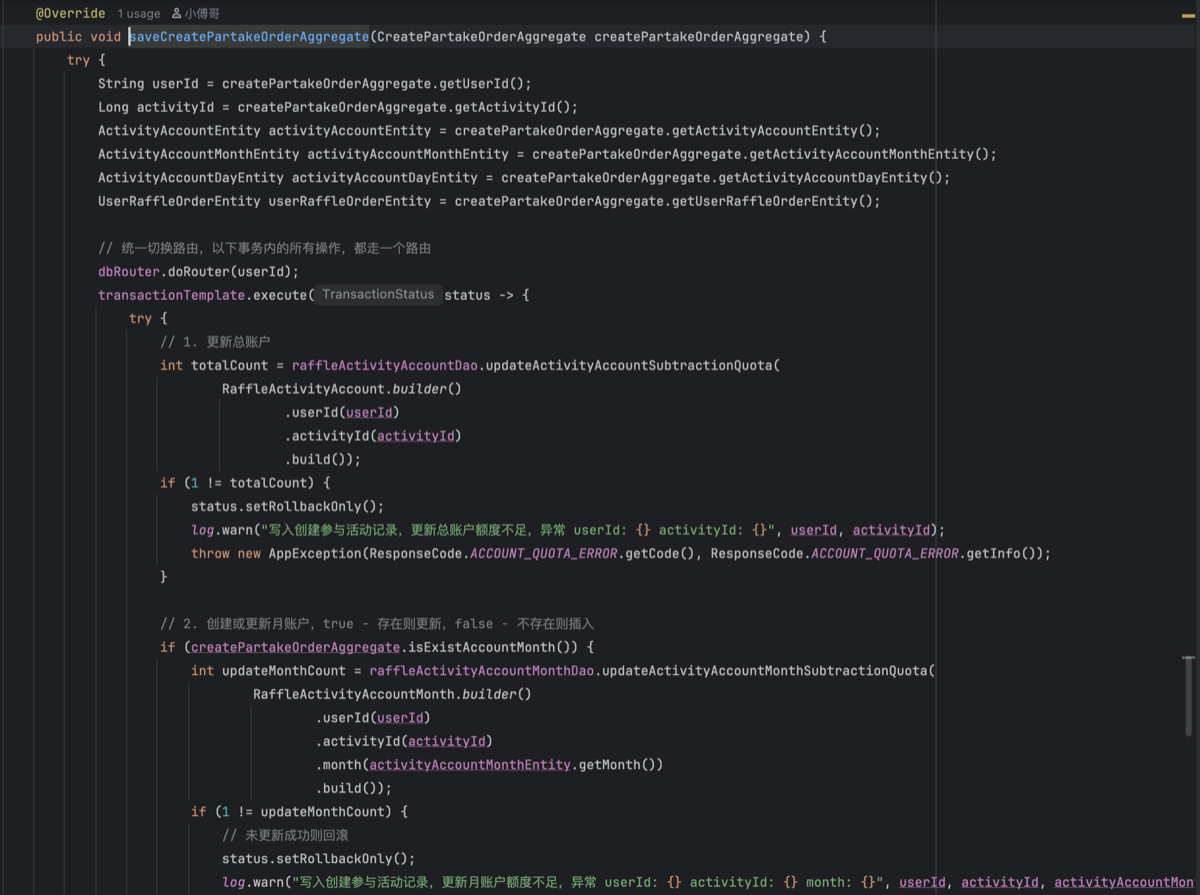
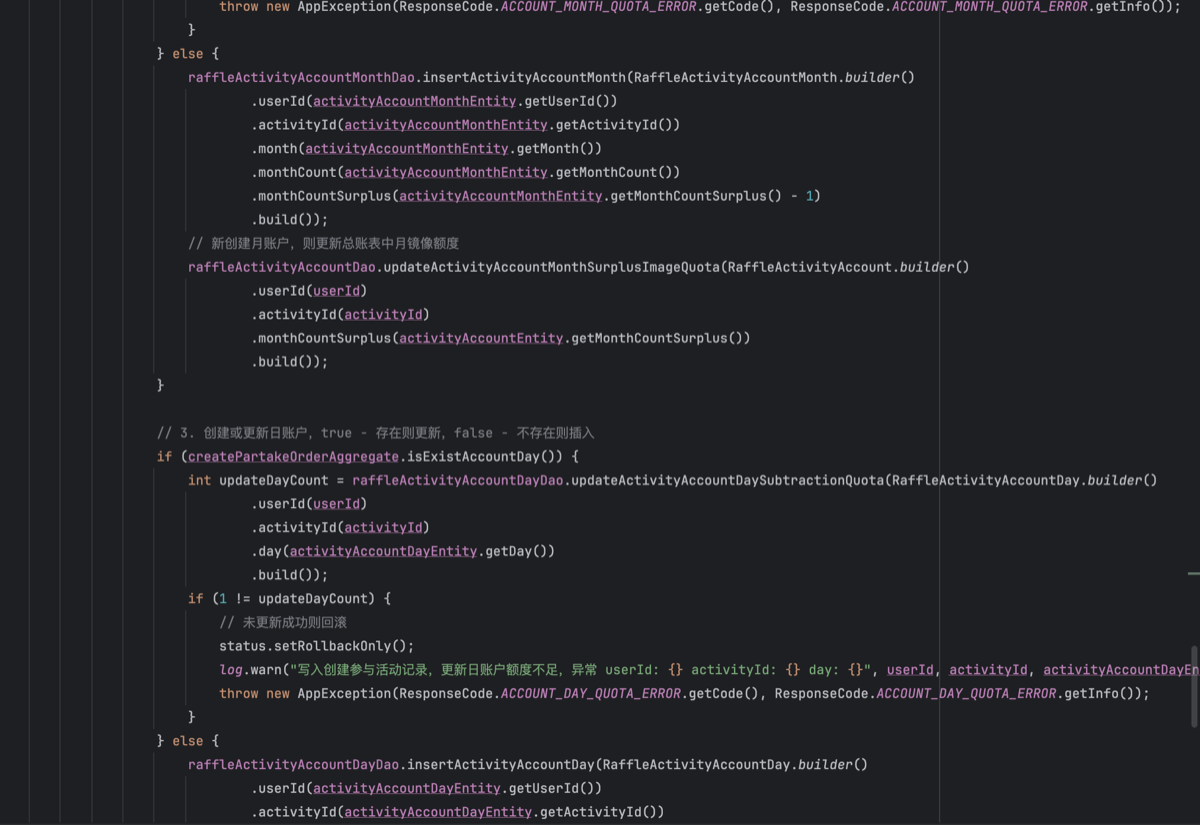
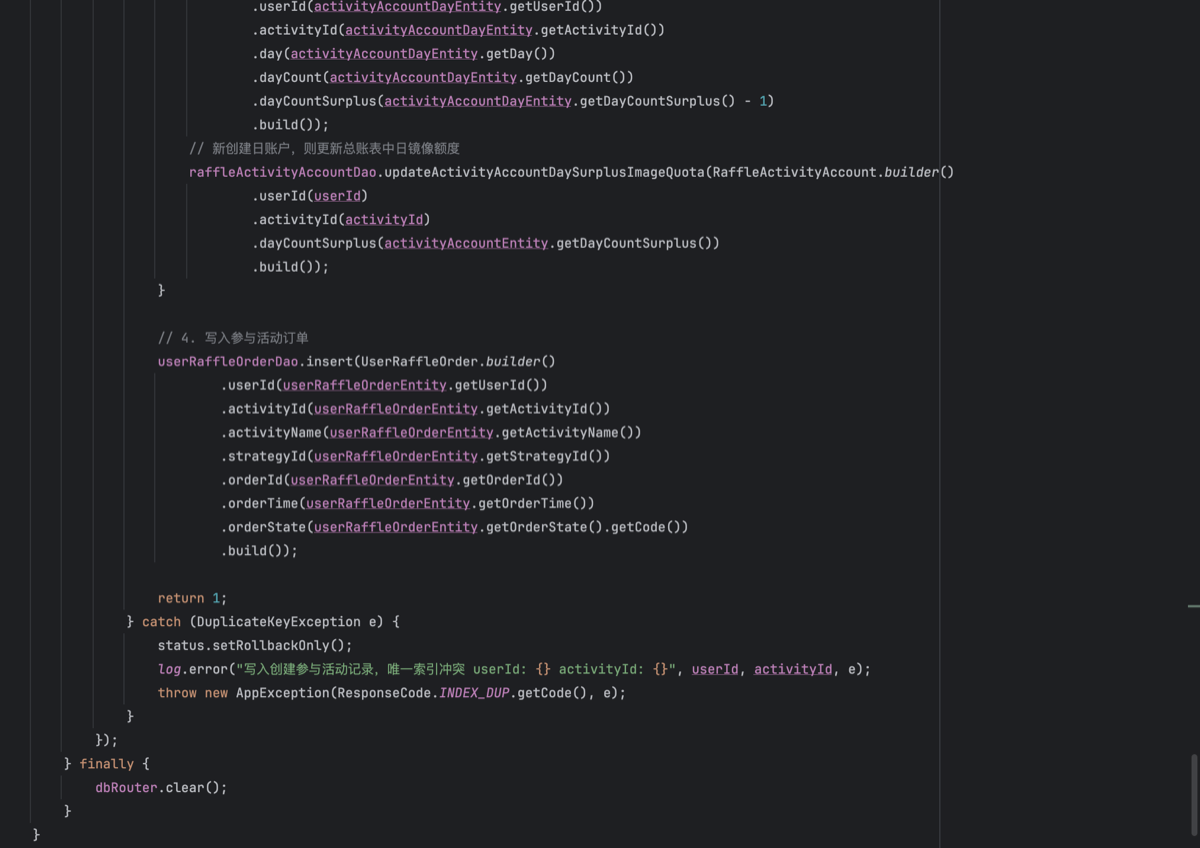
- 复杂点在于这里的事务操作,月账户、日账户,是随着用户每次参与活动自动创建的。所以根据是否有已经有账户选择更新和创建操作。如果这里出现创建的时候已经存在了数据,则会抛出一个主键冲突异常。也就是一个日账户的用户ID、活动ID、和当日,组装了一个唯一索引,来仿重。
- 账户的流程处理完毕后,则是写入订单,这些过程是一个事务下进行的。在过程中如果更新数量不为1则抛出异常。
19.写入中奖记录和任务补偿发送MQ
串一下抽奖流程 活动账户额度充值→活动参与→抽奖执行(策略)→中奖记录写入及后续发奖(本节内容)
本节用到task任务表,在写入奖品记录时,同时写入task消息发送任务,当mq发送发送失败时,由任务扫描task消息进行发送
业务流程
- 因为抽奖到发奖时,有些奖品不是在抽奖系统,而是各种http接口或者RPC接口来发放,有时会发生网络抖动问题,因此需要作异步解耦:在数据库写入记录时,记录一个状态,等奖品发送完毕后,更新这个状态.
- 经过以上步骤后,让用户知道是否中奖,之后点击详情或奖品列表来查看自己中奖结果
- 具体操作就是文章开头所说,这里不能用事务解决,事务主要时数据库事务,这里MQ不是数据库事务,用task表,通过异步补偿来进行
功能实现
- 在domain 领域层添加奖品领域、任务领域,两个模块。一个处理奖品写入记录,另外处理任务的扫描补偿。
- trigger 层一个是任务扫描,另外一个是监听奖品记录后发送的 MQ 消息。本节先接收 MQ 消息,后续再做奖品发放。
奖品领域
- AwardService 实现IAwardService,用来同时save数据库与saveTASK消息,其中具体操作在仓储层saveUserAwardRecord
- saveUserAwardRecord中,从聚合对象中取出奖品记录及TASK消息实体,存储后,自动发送一个MQ(在事务外)
- 其中,task的处理为
任务领域
- 定义TaskService 实现 ITaskService接口,供上面奖品领域内的发送MQ来使用
- 定义未完成MQ发送的任务表,之后是发送消息的操作,以及2个更新发送状态的操作。
- 定义SendMessageTaskJob任务,来定时扫描task表
- 这里需要对分库分表的情况下,扫描每个库和表下的task表(用dbRouter内的set)使用线程异步处理扫描库表与消息发送两个动作
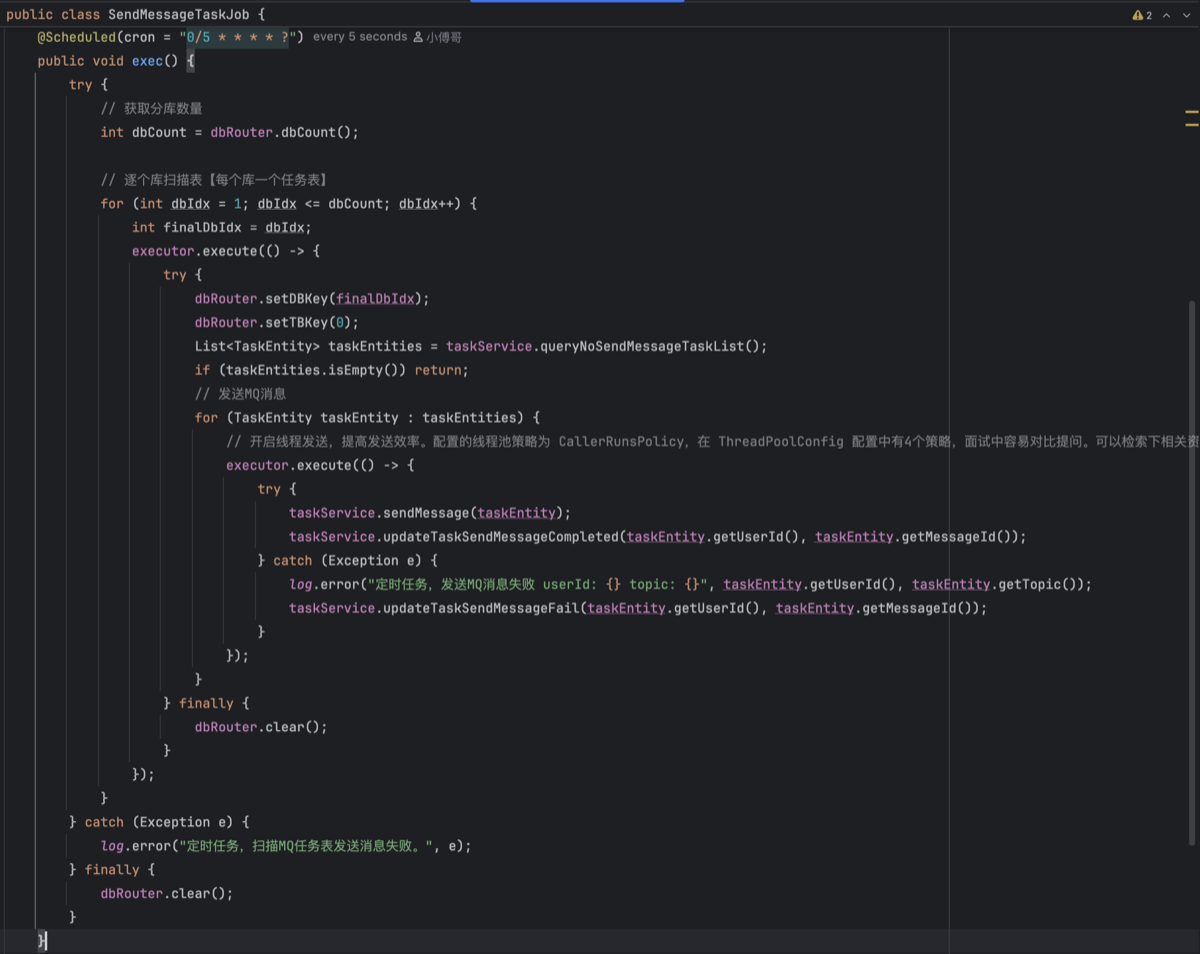
- 这里需要对分库分表的情况下,扫描每个库和表下的task表(用dbRouter内的set)使用线程异步处理扫描库表与消息发送两个动作
消息监听
- 这一节只是监听和打印消息,还没有发送奖品的操作,后续会处理奖品。
20.抽奖活动串联
串联各个模块,提供抽奖API接口
业务流程
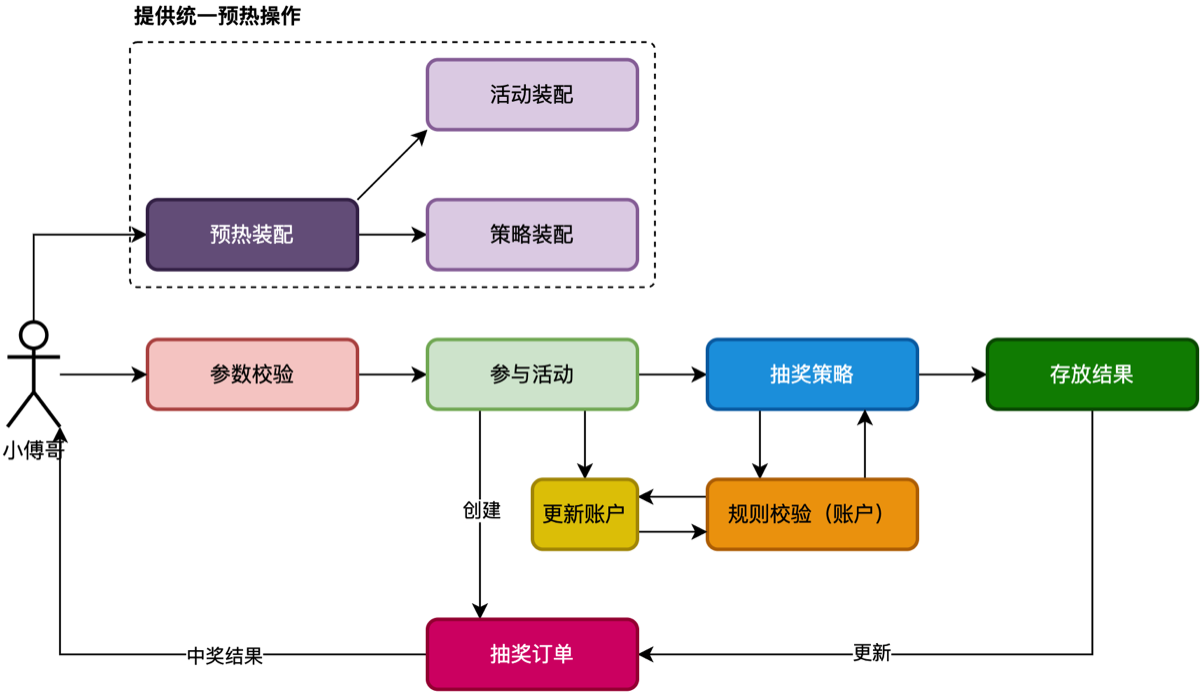
- 开发内容1;串联整个抽奖流程,提供 API
- 开发内容2;提供以活动为主导的,预热装配动作
- 开发内容3;抽奖策略模块中,校验账户额度。【之前的一个策略规则,需要根据已经抽奖次数进行解锁】
- 开发内容4;存放抽奖结果后,更新用户参与活动时的抽奖单状态为已使用。
工程结构
- 以api模块开始,定义一个接口类 IRaffleActivityService,实现装配和抽奖接口。另外对之前的 IRaffleService 接口调整名称为 IRaffleStrategyService,这样更好区分。
- 进入 RaffleActivityController 会看到对抽奖参与、抽奖策略、奖品服务、装配操作的领域模块调用。
总流程
- RaffleActivityController 实现IRaffleActivityService内的总装配与抽奖
- 传入活动ID,先进行活动装配,在进行策略装配,活动与策略是1:1绑定使用的。不会一个策略配置到多个活动上。
- 冲突: 如果活动 A 和活动 B 共用同一个策略 ID。当活动 A 的用户太热情把奖品抽光了,活动 B 的用户进来就会发现也没库存了。这通常不符合业务需求(每个活动应该有自己独立的预算和库存)。
- 解决: 1:1 绑定保证了库存池是隔离的。
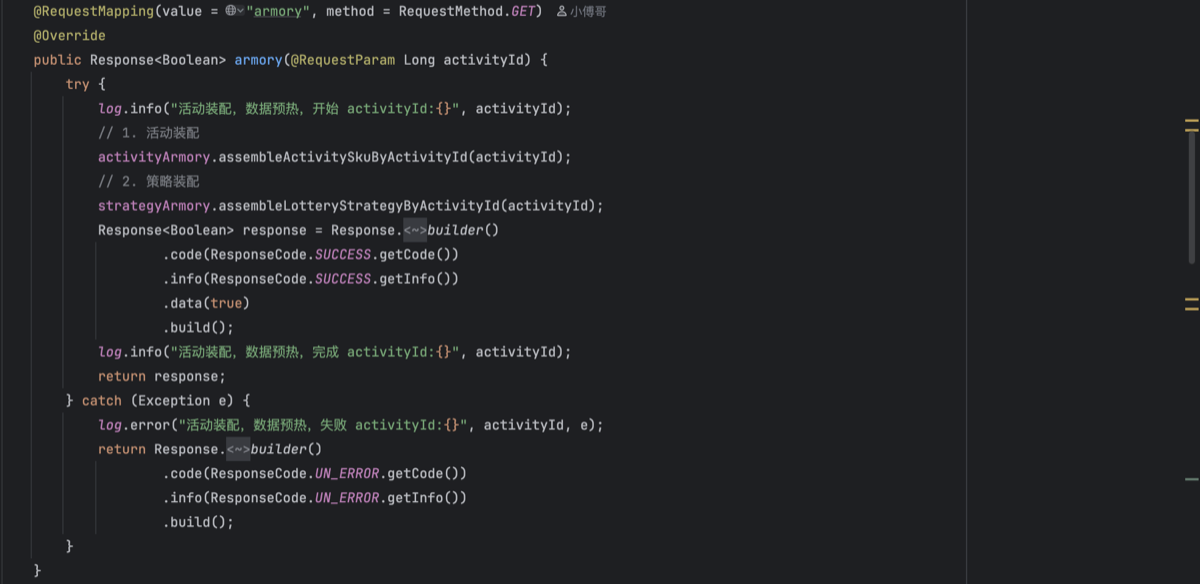
- 传入活动ID,先进行活动装配,在进行策略装配,活动与策略是1:1绑定使用的。不会一个策略配置到多个活动上。
- 在进行抽奖(不同于刚开始几节的抽奖,里面有19节的写入记录部分)
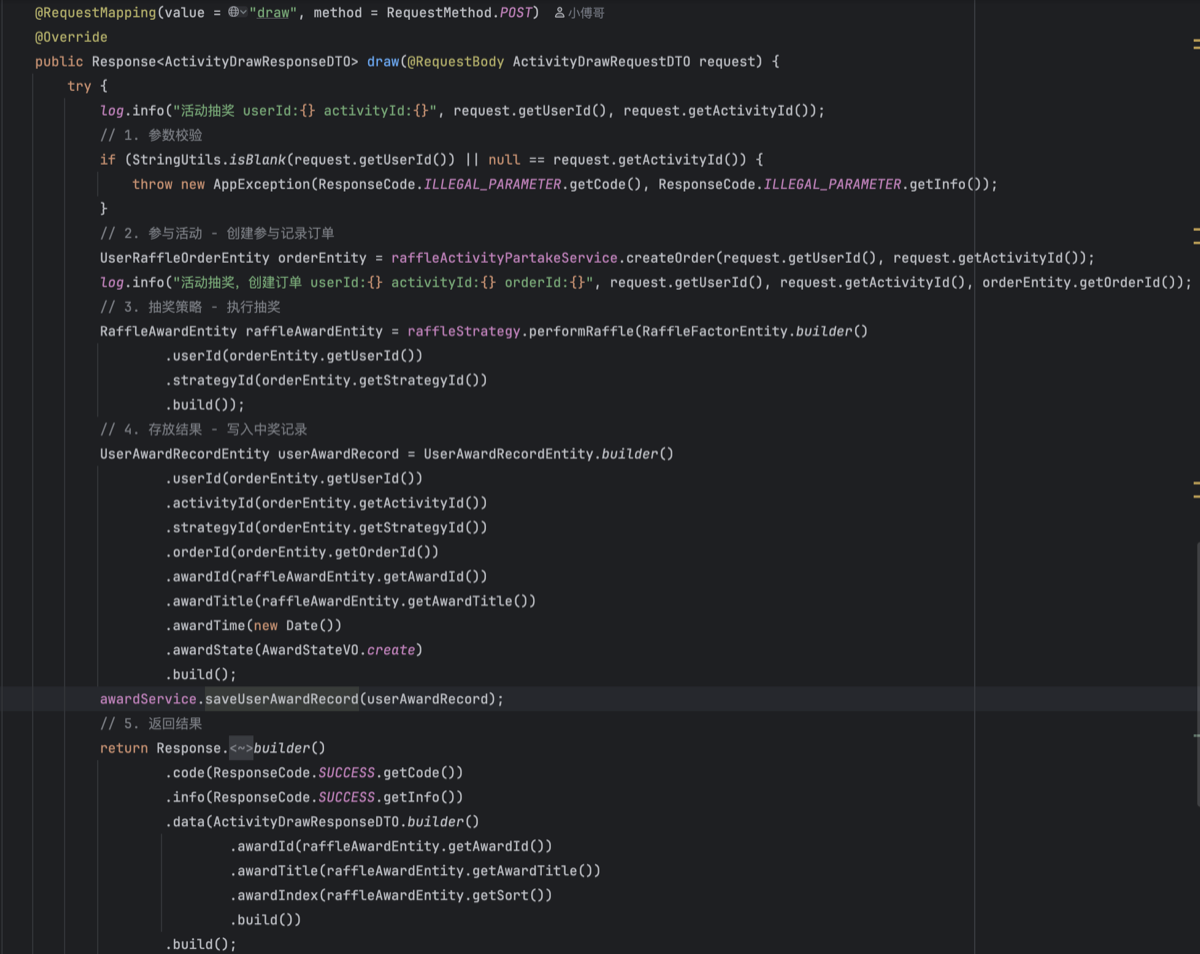
- 流程包括;参数校验 → 参与活动 -(创建参与记录订单) → 抽奖策略 (执行抽奖) → 存放结果(写入中奖记录) → 最后返回抽奖结果即可
1-20阶段抽奖流程总结
21.活动信息 API 迭代和功能完善
纯curd,但需要有业务的理解
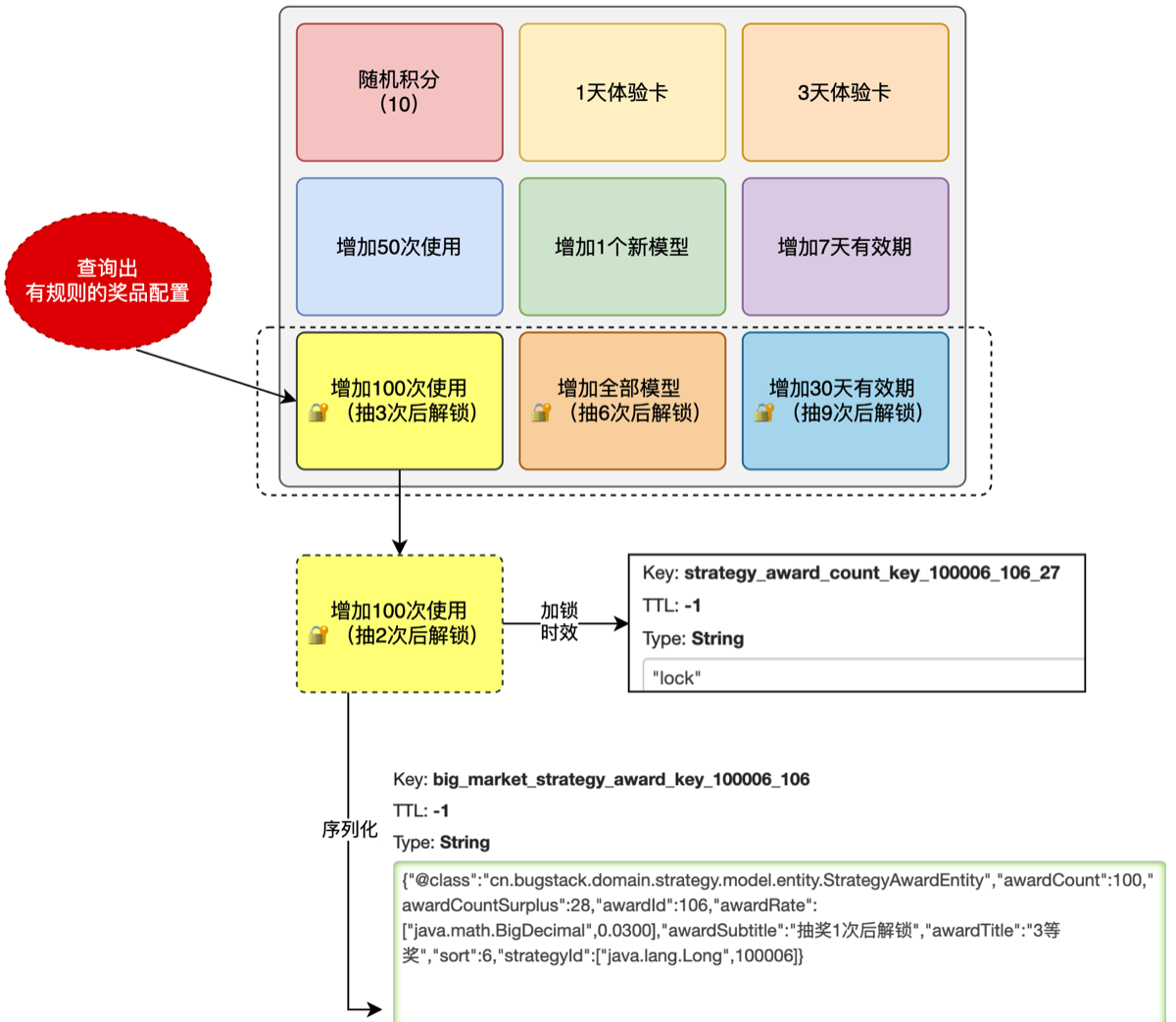
在查询活动奖品信息接口加入功能
- 返回奖品的待解锁次数,由此需求我们需要改
- 将原来只传入策略 Id 改为传入的是用户 id 与活动 id(因为需要判断用户抽奖了几次,和每个奖品的次数锁配置信息)
- 因为需要展示给前端,在 VO 结构中加入:1️⃣是否解锁 ,2️⃣剩余解锁次数,3️⃣奖品的次数锁配置
- 首先,根据活动 id 查询奖品信息表(一个 list 的奖品实体)
- 处理得到后的奖品实体列表,过滤出有 rulelock 的 treeids
- 根据 treeids,批量查询规则树配置表得出具体的次数
- 在根据用户id 查询用户每日抽奖次数表
- 最后填充新加的三个数据返回
在抽奖接口中加入功能
- 需要加入当前时间,为了在 redis 锁库存时判断是否超时
- 从抽奖接口加入 endTime 字段,传给规则树,再到 logic 的规则树节点,进入redis 扣减逻辑,判断传入是否有时间,如果时间不为 null,则加入过期时间,这样的话,具体库存的 SetNX 锁会自带有过期时间
24.防刷组件
方案 B 已落地,核心能力都加上了,并且已编译通过(mvn -q -DskipTests compile)。
已完成
- 接口层防刷 AOP(防连点 + 用户/IP 限流)
- 动态黑白灰名单(DB + Redis 热缓存)
- 领域服务:RiskControlService.java
- 仓储实现:RiskRepository.java
- MyBatis 映射:risk_user_tag_mapper.xml
- 责任链扩展
rule_risk
- 风控标签管理 API(运行时可改)
- 控制器:RiskControlController.java
POST /api/v1/risk/control/upsert_user_tagPOST /api/v1/risk/control/remove_user_tag?userId=xxxGET /api/v1/risk/control/query_user_tag?userId=xxx
- 配置与基础能力补充
- 风控配置:application-dev.yml
- Redis 原子计数带 TTL:IRedisService.java / RedissonService.java
- 风控响应码:ResponseCode.java
数据库变更
- 已写入初始化 SQL(新环境直接生效):
risk_user_tag + rule_risk SQL
如果你是已有库,需要执行同等迁移(重点):
- 新建
risk_user_tag表。 strategy.rule_models增加rule_risk(如rule_blacklist,rule_risk,rule_weight)。strategy_rule增加rule_risk配置(格式奖品ID:频率阈值,例101:3)。
联调注意
draw请求建议带X-Device-Id,否则命中rule_risk会被降级奖品。- 策略改完后要重新装配:
/api/v1/raffle/activity/armory?activityId=...。 - 这次只做了编译校验,未跑集成测试。
如果你同意,我下一步可以直接补一组压测脚本(连续点击、并发 50)把拦截率和吞吐指标跑出来,正好用于简历量化。