1.说一下你对 Spring 的理解
是什么 → 核心思想 → 生态体系
1. 定位 (What) Spring 是一个轻量级的、开源的 JavaEE 开发框架。 它的核心目的是为了解决企业级应用开发的复杂性。它就像是 Java 世界的‘粘合剂’,能把各种不同的技术(如数据库、Web、缓存)整合在一起。
2. 两大核心思想 (Core Philosophy) Spring 最精髓的部分在于 IoC 和 AOP:
-
IoC (Inversion of Control,控制反转):
-
以前: 我们需要哪个对象,必须自己在代码里
new出来,对象之间的依赖关系不仅复杂,而且耦合度极高。 -
现在: 我们把创建对象和管理依赖的权利交出去(反转),交给 Spring 容器来管理。我们需要用的时候,Spring 会通过 DI (依赖注入) 把对象送过来。
-
好处: 实现了解耦,让对象只需关注业务逻辑,不用管对象的创建和销毁。
-
-
AOP (Aspect Oriented Programming,面向切面编程):
-
作用: 它把那些与业务逻辑无关、但在很多地方都要用的系统级功能(比如:日志记录、权限校验、事务管理)抽离出来,封装成一个‘切面’。
-
好处: 然后在运行时,Spring 会自动把这个切面‘织入’到业务代码中。这样既减少了重复代码,又让业务逻辑更纯粹。
-
3. 核心优势 (Why use it)
-
容器化管理: 管理 Bean 的全生命周期(单例/多例)。
-
事务支持: 它的声明式事务(
@Transactional)非常强大,让我们从繁琐的手动提交/回滚事务中解放出来。 -
集成能力: 它对各种优秀框架(MyBatis、Hibernate、Redis)提供了极好的集成支持。
4. 生态体系 (The Ecosystem) 现在的 Spring 不仅仅是一个框架,而是一个庞大的家族:
-
Spring Boot: 通过‘约定大于配置’,实现了快速开发,内置 Tomcat,彻底解决了复杂的配置痛点。
-
Spring Cloud: 基于 Spring Boot,提供了一整套微服务解决方案(服务发现、配置中心、网关等)。
2.**spring的核心思想说说你的理解?
“我觉得 Spring 的核心思想就是通过 IoC(控制反转) 和 AOP(面向切面) 来实现系统的解耦。
-
IoC 是为了解决对象之间的耦合。它剥夺了我们手动创建对象的权力,交给容器管理,让我们从复杂的依赖关系中解放出来。
-
AOP 是为了解决业务逻辑与系统逻辑的耦合。它把日志、事务等非业务代码抽离出来,让业务逻辑更加纯粹。
最终目的,就是让开发变得更简单、代码更易维护。”
3.Spring IoC和AOP 介绍一下
1. IoC (Inversion of Control,控制反转)
-
是什么: IoC 是一种设计思想。它把对象的创建权和依赖关系的维护权,从代码中剥离出来,交给了 Spring 容器去管理。
-
为什么用: 为了解耦。
-
以前我们需要在代码里
new User(),如果User的构造函数变了,所有用到的地方都要改。 -
现在我们要用的时候,直接问容器要(通过 DI 依赖注入),根本不需要关心对象是怎么生出来的。
-
-
底层原理: 核心是 工厂模式 + 反射机制。容器启动时,解析 XML 或注解,通过反射创建对象并存入 Map 缓存中。
2. AOP (Aspect Oriented Programming,面向切面编程)
-
是什么: AOP 是对 OOP(面向对象)的一种补充。它把系统中那些与业务无关,但在多个模块中通用的逻辑(比如:日志记录、事务管理、权限校验)抽取出来,封装成一个切面 (Aspect)。
-
切面 (Aspect): 也就是我们写的那个类(比如
LogAspect),里面包含了逻辑。 -
切点 (Pointcut): 定义了‘在哪些地方’执行(比如
execution(* com.example.service.*.*(..)))。 -
通知 (Advice): 定义了‘什么时候’执行(比如
Before前置、After后置、Around环绕)。 -
为什么用: 为了减少重复代码和让业务逻辑更纯粹。
- 比如写日志,不用在每个方法里都写一遍
log.info,而是配置一个切面,自动在运行的时候把日志逻辑加进去。
- 比如写日志,不用在每个方法里都写一遍
-
底层原理: 核心是 动态代理。
-
如果目标对象实现了接口,默认使用 JDK 动态代理。
-
如果没有实现接口,使用 CGLIB 代理(生成子类)。
-
4.依赖倒置,依赖注入,控制反转分别是什么?
这三个概念虽然紧密相关,但侧重点完全不同,可以概括为:依赖倒置是‘指导原则’,控制反转是‘设计思想’,依赖注入是‘实现手段’。
1. 依赖倒置原则 (Dependency Inversion Principle - DIP)
-
是什么(原则): 这是面向对象设计(SOLID)中的 “D”。
-
核心规则:
-
高层模块不应该依赖低层模块,两者都应该依赖其抽象(接口/抽象类)。
-
抽象不应该依赖细节,细节应该依赖抽象。
-
-
通俗理解: 老板(高层)不应该依赖具体的某个员工(张三),老板应该依赖‘职位’(接口)。只要能干活,换成李四也行。这就是面向接口编程。
2. 控制反转 (Inversion of Control - IoC)
-
是什么(思想): 它是为了实现‘依赖倒置’原则而提出的一种设计思想。
-
反转了什么? 反转了资源的获取方式。
-
传统(正转): 我需要什么对象,我自己
new出来。我是控制者。 -
IoC(反转): 我把对象的控制权交出去(交给 IoC 容器)。我需要什么,容器会给我。
-
-
生活比喻: 以前是**‘自助餐’(想吃什么自己去拿);现在是‘点外卖’**(下单后,外卖员把饭送到你手上,你失去了挑选具体那盘菜的控制权,但获得了便利)。
3. 依赖注入 (Dependency Injection - DI)
-
是什么(手段): 它是 IoC 最经典的落地实现方式(IoC 是理论,DI 是实操)。
-
具体动作: 容器全权负责创建对象,并在运行时把对象注入到需要它的地方。
-
怎么注入? 主要有三种方式:构造器注入、Setter 注入、字段注入(@Autowired)。
-
一句话总结: IoC 是我的目的(不想自己 new),DI 是我达成目的的手段(容器帮我塞进来)。”
-
单体注入 (最常见):你需要一个具体的对象。
-
@Autowired private UserService userService; -
Spring 去找:谁是 UserService?找到一个,塞给你。
-
-
集合注入 (Collection Injection):你需要一批同类型的对象。
-
@Autowired private List<PayService> payServices; -
Spring 去找:所有实现了
PayService接口的人,统统给我站出来!然后把他们打包成一个 List,塞给你。
-
5.如果让你设计一个SpringIoc,你觉得会从哪些方面考虑这个设计?
“要设计一个简单的 IoC 容器,我会模仿 Spring 的核心流程,至少包含以下 4 个 核心步骤:
1. 定义 Bean (BeanDefinition) 首先,我需要一个能够描述对象的类,就叫 BeanDefinition。
-
因为用户可能会用 XML、注解或者 Java Config 来定义 Bean,配置方式五花八门。
-
所以容器不能直接依赖这些配置,必须把它们统一转化为一个内部的标准对象 ——
BeanDefinition(里面存类名、Scope、属性依赖等信息)。
2. 加载与解析 (BeanDefinitionReader) 我需要一个读取器,去读取用户的配置(比如扫描包下的 @Component 注解)。
- 解析完后,把这些
BeanDefinition注册到一个 Map 中(比如ConcurrentHashMap<String, BeanDefinition>)。这个 Map 就是容器的大脑。
3. 实例化与注入 (BeanFactory / Reflection) 这是容器最核心的工厂功能。当用户调用 getBean() 时:
-
实例化: 根据
BeanDefinition里的类名,利用 Java 反射 机制创建对象实例。 -
依赖注入 (DI): 检查这个对象里有没有加了
@Autowired的属性。如果有,就去 Map 里找对应的 Bean(或者先递归创建它),然后通过反射塞进去。
4. 扩展机制 (BeanPostProcessor) —— 灵魂所在 为了让容器更强大(比如支持 AOP),我会在 Bean 初始化的前后,预留两个钩子函数:postProcessBeforeInitialization 和 postProcessAfterInitialization。
-
作用: 允许用户自定义逻辑。
-
实现 AOP: 比如在
After钩子里,我可以判断这个 Bean 是否需要 AOP,如果需要,我就不返回原始对象,而是利用动态代理返回一个代理对象。这就是 AOP 的实现原理。”
6.SpringAOP主要想解决什么问题
“Spring AOP 主要解决了两个核心痛点:代码重复 和 逻辑纠缠。
它旨在将那些与业务无关,却为业务模块所共同调用的逻辑(我们称为**‘横切关注点’**)封装起来。
具体可以从以下三个方面来理解:
1. 解决代码分散与重复 (Don’t Repeat Yourself)
-
痛点: 在没有 AOP 之前,如果我们要在每个方法执行前记录日志、或者在每个数据库操作前开启事务,我们需要在每个方法里都写一遍重复的代码。
-
解决: AOP 把这些重复的代码抽取出来,统一定义在一个地方(切面),然后动态地‘织入’到需要的地方。
2. 实现关注点分离 (Separation of Concerns)
-
痛点: 业务代码应该只关注业务(比如‘转账’)。但实际上,业务代码里往往混杂着大量的‘非业务代码’(比如权限校验、异常处理、性能监控)。这导致业务逻辑不纯粹,代码难以维护。
-
解决: AOP 让业务类只做业务类该做的事。非业务逻辑由 AOP 代理类在运行时自动处理。
3. 实现无侵入性 (Non-Intrusive)
-
优势: 我不需要修改原本的业务类代码(甚至不需要知道业务类的存在),就能给它添加新的功能(比如加一个监控)。这对维护旧系统非常有用。”
-
形象比喻:纵向 vs 横向
-
纵向(OOP 面向对象): 也就是我们的业务流程。比如:用户登录 → 下单 → 支付。这是从上到下的执行流。
-
横向(AOP 面向切面): 也就是所有的业务流程都需要经过的一道道“关卡”。比如:所有流程都要记录日志、都要验证权限。
AOP 就是把这些横向的关卡切进去,而不打断纵向的业务流。
7.AOP在spring中的应用,你知道哪些?
| 类型 | 典型功能 | 对应注解/类 | 核心逻辑 |
|---|---|---|---|
| 框架级 | 事务管理 | @Transactional | 自动 commit/rollback |
| 框架级 | 缓存处理 | @Cacheable | 先查缓存,兜底查库 |
| 框架级 | 安全控制 | @PreAuthorize | 拦截校验角色权限 |
| 业务级 | 统一日志 | 自定义 @Log | 记录入参、出参、耗时 |
| 业务级 | 防重/限流 | 自定义 @RateLimit | 检查 Redis 计数器 |
8.**SpringAOP的原理了解吗
简单来说,当容器启动时,Spring 会为那些需要被增强(比如加了 @Transactional 或自定义切面)的 Bean,动态生成一个代理对象。 我们在代码里拿到的 Bean,其实是这个代理对象,而不是原来的那个目标对象。
Spring 实现了两种动态代理方式,根据目标类是否实现接口来决定使用哪一种:
1. JDK 动态代理 (JDK Dynamic Proxy)
-
适用情况: 目标对象实现了接口。这是 Spring 的默认行为(在非 Spring Boot 2.x 环境下)。
-
原理: 利用 Java 原生的
java.lang.reflect.Proxy类。它会在运行时创建一个实现了相同接口的代理类。 -
局限性: 只能代理接口方法,如果目标类没有实现接口,就没法用 JDK 代理。
2. CGLIB 动态代理 (Code Generation Library)
-
适用情况: 目标对象没有实现接口(是一个普通的类)。
-
原理: 利用底层字节码技术(ASM),在运行时动态生成一个目标类的子类。
-
机制: 这个子类会重写 (Override) 父类的非 final 方法,在子类中植入增强逻辑。
-
局限性: 因为是基于继承的,所以无法代理
final修饰的类或方法(没法继承和重写)。 -
JDK 动态代理 是 “签合同”(必须要有接口/合同)。
-
CGLIB 是 “认干爹”(通过继承子类来实现)。
情况一:如果是 JDK 动态代理 (基于接口)
触发条件:
-
你的
OrderServiceImpl实现了接口(代码里有@Override,说明很有可能实现了接口)。 -
Spring 配置为优先使用 JDK 代理(非 Spring Boot 2.x 默认行为)。
发生了什么: Spring 在运行期间,会在内存里偷偷生成一个原本不存在的类(我们就叫它 $Proxy0)。
-
关系: 这个
$Proxy0和你的OrderServiceImpl是兄弟关系。它们都实现了同一个接口OrderService。 -
owner 是谁:
owner实际上是$Proxy0的实例。 -
调用流程:
-
你调用
owner.placeOrder()。 -
其实调用的是
$Proxy0.placeOrder()。 -
$Proxy0内部会先去执行LockAspect切面里的代码(加锁)。 -
切面执行完
pjp.proceed()后,通过反射调用你的OrderServiceImpl.placeOrder()(原始业务)。
-
情况二:如果是 CGLIB 动态代理 (基于继承)
触发条件:
-
你的类没有实现接口。
-
或者(最常见情况)你用的是 Spring Boot 2.x 及以上。为了防止乱套,Spring Boot 默认强行开启了 CGLIB (
proxy-target-class=true),不管你有没有接口。
发生了什么: Spring 在运行期间,利用字节码技术,生成了一个 OrderServiceImpl 的子类(名字通常叫 OrderServiceImpl$$EnhancerBySpringCGLIB...)。
-
关系: 这个生成的类是你的
OrderServiceImpl的儿子(子类)。 -
owner 是谁:
owner实际上是这个子类的实例。 -
调用流程:
-
你调用
owner.placeOrder()。 -
其实调用的是子类重写过的
placeOrder()方法。 -
子类方法里包含了切面逻辑(加锁)。
-
切面执行完后,子类调用
super.placeOrder(),也就是爸爸(你的原始代码)的方法。
-
结合你的代码看“自我调用”的坑
你代码里有一段特别关键的处理:
Java
// 这是一个入口方法
@Override
public PlaceOrderResDTO placeOrder(PlaceOrderReqDTO placeOrderReqDTO) {
Long userId = UserContext.currentUserId();
// 💥 重点在这里!
// 你没有直接写 this.placeOrder(...)
// 而是写了 owner.placeOrder(...)
return owner.placeOrder(userId, placeOrderReqDTO);
}
为什么要这么写?
假设你写的是 this.placeOrder(...):
-
this指的是谁?-
在 JDK 代理中,如果代码在原始对象里跑,
this就是原始对象自己。 -
在 CGLIB 代理中,虽然
this是代理对象,但直接调用内部方法属于“方法内部跳转”,不会触发代理逻辑(也就是不会触发切面)。
-
-
结果:
this是没有任何切面功能的“裸奔”对象。你调用它,就直接进业务代码了,根本不会经过 AOP 的拦截,锁就失效了!
所以,必须用 owner。
-
owner是 Spring 容器里经过了完整包装的代理对象(无论是 JDK 还是 CGLIB)。 -
只有捏着
owner调用,才能保证先经过那个“看门狗(Aspect)”,再加上锁。
9.动态代理和静态代理的区别
| 特性 | 静态代理 (Static) | 动态代理 (Dynamic) |
|---|---|---|
| 代码编写 | 开发者手动编写代理类 | 框架/JDK 自动生成代理类 |
| 类加载时机 | 编译期 (运行前就有 class) | 运行期 (在内存中动态生成) |
| 灵活性 | 差 (接口变,代理类必须变) | 高 (接口变,增强逻辑不用变) |
| 复用性 | 差 (代码重复多) | 高 (一个 Handler 代理所有) |
| 应用场景 | 简单的装饰器模式 | Spring AOP、RPC 框架、全局事务 |
10.能使用静态代理的方式实现AOP吗?
“可以。 事实上,AOP 界的大佬 AspectJ 就是典型的静态代理(或者更准确地说是静态织入)实现。
我们可以从两个层面来理解:
1. 理论层面的‘手动静态代理’(不推荐)
-
我可以手动为每一个业务类(Target)写一个对应的代理类(Proxy)。
-
在代理类里手动写上日志、事务逻辑,然后调用目标对象。
-
缺点: 这是‘累死程序员’模式,代码爆炸,维护地狱。
2. 工程层面的‘自动化静态代理’ —— AspectJ(推荐)
-
原理: AspectJ 不像 Spring AOP 那样在运行时生成代理对象。它是在 编译时 (Compile Time) 就动手了。
-
做法: 它使用特殊的编译器(
ajc),在把.java编译成.class的过程中,直接把切面逻辑(比如加锁、日志)写进了业务类的字节码里。 -
结果: 编译出来的
.class文件,里面已经包含了增强的代码。运行时不需要任何代理对象,直接运行就是增强过的逻辑。
3. 对比 Spring AOP (动态) vs AspectJ (静态)
-
Spring AOP: 是运行时的魔术。通过生成代理对象来拦截。
-
AspectJ: 是编译时的手术。直接修改了源代码编译后的字节码。
所以结论是: 能实现,AspectJ 就是最好的例子,而且它的性能比 Spring AOP 更好(因为没有运行时开销),功能也更强大。”
11.AOP有哪些注解
回答时,不要只是报菜名,建议按照 “开启 → 定义 → 增强(5种通知)” 的逻辑分类回答,并重点强调 @Around(因为它是最强大的,也是你刚才写分布式锁用到的那个)。
面试直答模版
面试官: AOP 实现有哪些注解?它们分别在什么时候执行?
候选人:
“在 Spring AOP 中,核心注解主要分为三类:开启注解、定义注解 和 通知注解(5种)。
1. 开启与定义 (Activation & Definition)
-
@EnableAspectJAutoProxy:开关。放在配置类上,表示开启 Spring 对 AOP 的支持(Spring Boot 通常通过配置自动开启,但要知道这个注解的存在)。 -
@Aspect:身份牌。用来标记一个类是‘切面类’。 -
@Pointcut:定位器。用来定义‘切点’(即哪些方法需要被拦截),通常提取出来是为了复用表达式。
- 五大通知注解 (Advice - 核心)
这决定了切面逻辑在目标方法的什么时机执行:
-
@Before(前置通知):在目标方法执行之前运行。 -
@After(后置/最终通知):在目标方法执行之后运行。不管方法是成功还是抛异常,它都会执行(类似于try-catch-finally中的finally块)。 -
@AfterReturning(返回通知):只有在目标方法成功返回(没抛异常)后运行。它可以获取方法的返回值。 -
@AfterThrowing(异常通知):只有在目标方法抛出异常时运行。它可以获取异常信息。 -
@Around(环绕通知) —— 最强大:-
它包裹了目标方法,可以在方法执行前后自定义逻辑,甚至决定是否执行目标方法。
-
关键点: 它的参数必须是
ProceedingJoinPoint,需要手动调用.proceed()来让目标方法往下走。我们刚才写的 Redis 分布式锁 就是用的这个。
-
- 执行顺序 (Spring 5.2.7+ 版本)
正常情况下的执行顺序是:
@Around (前) → @Before → 目标方法 → @AfterReturning → @After → @Around (后)。”
详细对比表格 (面试小抄)
| 注解 | 英文名 | 作用时机 | 能否阻止目标方法 | 核心参数 |
|---|---|---|---|---|
| @Before | Pre | 方法前 | 否 (除非抛异常) | JoinPoint |
| @AfterReturning | Post-Success | 成功返回后 | 否 | JoinPoint, Object returning |
| @AfterThrowing | Post-Exception | 抛异常后 | 否 | JoinPoint, Exception ex |
| @After | Finally | 方法结束后 (无论成败) | 否 | JoinPoint |
| @Around | Around | 完全掌控 (前后都能) | 能 | ProceedingJoinPoint |
结合你的代码复习
回头看你刚才写的 Redis 锁代码,加深理解:
Java
// 1. 使用了 @Around,因为你需要在方法执行“前”加锁,执行“后”解锁
// 而且如果加锁失败,你直接 throw 异常,根本不让目标方法执行(阻止目标方法)
@Around("@annotation(lock)")
public Object handleLock(ProceedingJoinPoint pjp, Lock lock) throws Throwable {
// ... 加锁逻辑 (Before 的事它干了) ...
try {
return pjp.proceed(); // --- 执行目标方法 ---
} finally {
// ... 解锁逻辑 (After 的事它也干了) ...
}
}为什么这里不用 @Before?
因为 @Before 没法在方法执行后去解锁(它管不了后面)。虽然可以用 @After 解锁,但这就需要两个方法配合,不如 @Around 在一个方法里写 try-finally 方便,而且 @Around 还能在拿不到锁时直接拦截不让跑。
12.什么是反射?有哪些使用场景?
“1. 什么是反射 (What) 反射(Reflection)是 Java 的一种在运行期 (Runtime) 检查和修改类、接口、字段和方法的能力。
-
正常情况: 我们写代码时必须知道类名,编译时就确定了对象类型(如
User user = new User())。 -
反射情况: 代码在写的时候不知道要操作哪个类,只有在运行的时候,通过读取配置或传参,才动态地加载类、创建对象、调用方法。
-
核心机制: 它是通过获取 JVM 中的
Class对象(类的字节码对象)来实现的,就像是拿到了一张“房屋图纸”,根据图纸可以随意改造房子。
2. 核心 API 反射主要涉及 4 个核心类:
-
Class:代表类的实体(核心入口)。 -
Field:代表类的成员变量(可以访问私有属性)。 -
Method:代表类的方法。 -
Constructor:代表类的构造方法。
3. 有哪些使用场景 (Where) 我们在写业务代码时很少直接用,但对于框架开发来说,反射是灵魂:
-
Spring/SpringBoot 框架:
-
IoC: Spring 读取 XML 或注解,利用反射实例化 Bean (
Class.forName().newInstance())。 -
AOP: 动态代理底层全是反射,用来拦截方法调用。
-
-
ORM 框架 (MyBatis/Hibernate):
- 查询数据库后,利用反射将结果集(ResultSet)自动映射封装到 Java Pojo 对象中。
-
JDBC 连接:
Class.forName("com.mysql.cj.jdbc.Driver")加载数据库驱动。
-
注解处理:
- 比如你刚才用的分布式锁
@Lock,AOP 切面必须通过反射才能读取到方法上有没有挂这个注解,以及注解里的参数是多少。”
- 比如你刚才用的分布式锁
// 【正常方式】(编译时必须知道是 User 类)
User user = new User();
user.sayHello();
// 【反射方式】(编译时可以是 String 字符串,运行时才变成对象)
String className = "com.example.User"; // 这个字符串可以从配置文件读
Class<?> clz = Class.forName(className);
// 1. 动态创建对象
Object obj = clz.getDeclaredConstructor().newInstance();
// 2. 动态获取方法
Method method = clz.getMethod("sayHello");
// 3. 动态调用方法
method.invoke(obj);13.** spring是如何解决循环依赖的?
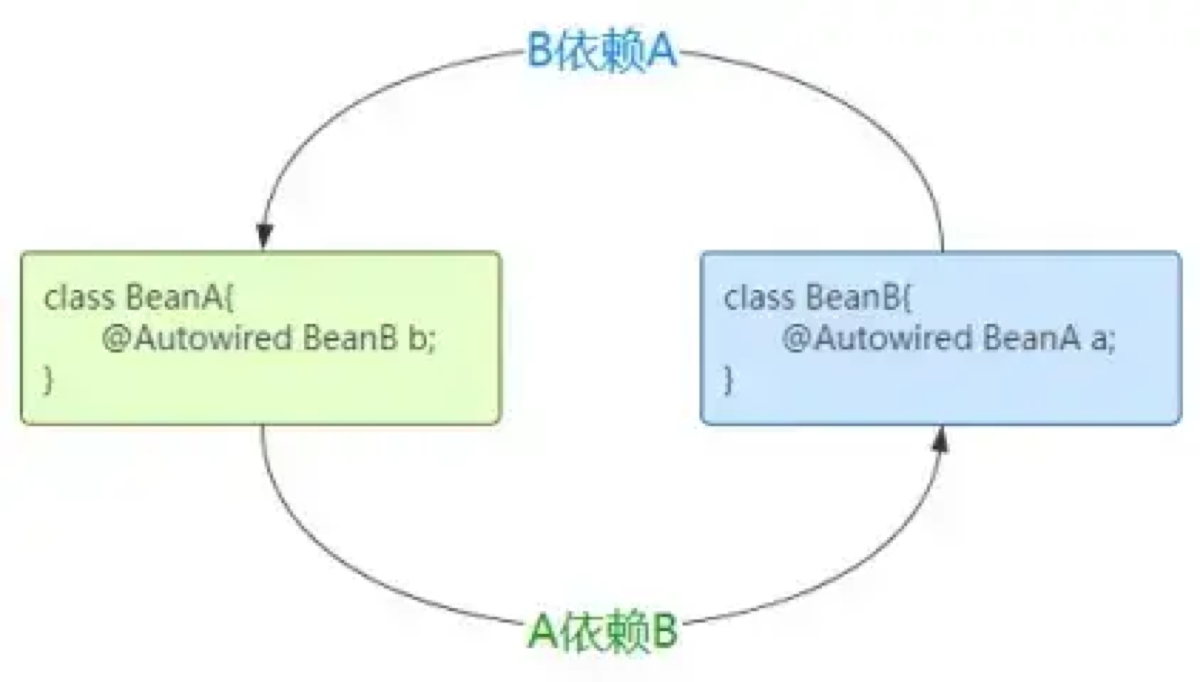
Spring 解决循环依赖的核心机制是 三级缓存,本质上是利用了 ‘中间态’ 的概念。
首先,必须要明确,Spring 只能解决 ‘单例模式 (Singleton)’ 下的 ‘Setter 注入’(或字段注入)造成的循环依赖。对于 ‘构造器注入’ 或 ‘多例模式’,Spring 也是无能为力的。
| 缓存级别 | Map 名称 | 存放内容 | 作用 |
|---|---|---|---|
| 一级缓存 | singletonObjects | 成品对象 | 经历了完整生命周期,可以直接使用的 Bean。 |
| 二级缓存 | earlySingletonObjects | 半成品对象 | 已经被实例化,但还没填充属性。主要用于防止 AOP 代理对象被重复创建。(这里好像是把三级缓存的 AOP 代理对象(如果有的话)迁移到二级缓存,最后迁移到一级缓存) |
| 三级缓存 | singletonFactories | 对象工厂 (Lambda) | 存的是一个 函数接口。它可以在需要的时候,生产出 Bean 的原始对象,或者 AOP 代理对象(一次性的,为了防止被 B,C 创建多个,引入二级缓存)。 |
三级缓存:对象工厂。把 AOP 对象的预习先暴露出来到,之后给到二级缓存。如果没有 AOP 二级缓存足以。
14.Spring为什么用3级缓存解决循环依赖问题?用2级缓存不行吗?
1. 核心矛盾:什么是“循环依赖”的死结?
假设你要创建 A,A 里面需要 B;而创建 B 时,B 里面又需要 A。
传统流程(死锁):
-
造 A: 刚把 A 的地基打好,准备往里填家具(注入属性)。发现需要家具 B。
-
停下来造 B: 去造 B,刚把 B 地基打好,准备填家具。发现需要家具 A。
-
死结: B 想要一个“装修好的 A”,但 A还在等 B 做完才能装修好。谁也动不了。
A 依赖 A(你代码中的情况)也是同理:
-
造
OrdersCreateServiceImpl(简称 O),发现 O 里面有个属性owner也是 O。 -
O 说:“我要先把
owner填好,我才算造完。” -
但是
owner必须是一个造好的 O。 -
结果:我自己等我自己,死循环。
2. Spring 的解法:半成品(提前曝光)
Spring 的核心思想是:把“实例化”(买地基/造空壳)和“初始化”(装修/填属性)分开。
它告诉 A:“虽然你还没装修好(没初始化),但你的地址(内存引用)已经确定了。你可以先把你的地址给 B,让 B 先拿着用,反正你迟早会装修好的。”
这里的“半成品”怎么理解?
在 Java 堆内存中,当 new OrdersCreateServiceImpl() 执行完的那一瞬间,这个对象就已经存在了(有地址了),只不过里面的属性(比如 owner、serveApi)还是空的。这个状态就是“半成品”。
3. 图解“三级缓存”的工作流程
文档里提到的缓存,你可以理解为三个不同阶段的“仓库”:
-
第 1 级(singletonObjects):【成品库】 放的是完全装修好、可以随时入住的房子。
-
第 2 级(earlySingletonObjects):【半成品库】 放的是虽然没装修,但是已经领了房产证(有地址)的毛坯房。
-
还原 A 依赖 B,B 依赖 A 的成功流程:
-
创建 A(Step 1):
-
Spring
new A()。 -
关键动作: Spring 赶紧把 A 的引用(地址)放到 【半成品库】 里。(心里想:万一后面有人要用 A,先来这拿)。
-
-
填充 A(Step 2):
- Spring 发现 A 需要 B。去创建 B。
-
创建 B(Step 3):
-
Spring
new B()。 -
关键动作: 把 B 的引用也放到 【半成品库】。
-
-
填充 B(Step 4):
-
Spring 发现 B 需要 A。
-
去哪里找 A? 去【成品库】找,没找到。去【半成品库】找,找到了!(就是 Step 1 里放进去的那个 A)。
-
B 顺利拿到了 A 的地址,完成了 B 的初始化。
-
B 完工,从【半成品库】移到【成品库】。
-
-
回到 A(Step 5):
-
A 拿到了完整的 B。
-
A 也完成了初始化。
-
A 完工,从【半成品库】移到【成品库】。
-
结果: 大家都拿到引用了,虽然拿到的时候对方可能还没装修完,但最终都会装修完的。
4. 回到你的代码:自己注入自己
你的 OrdersCreateServiceImpl 是怎么解决的?
-
Spring 开始创建
OrdersCreateServiceImpl。 -
实例化: 调用构造函数,生成一个**“原始对象”**。
-
放入缓存: Spring 马上把这个“原始对象”的引用(或者它的代理工厂)暴露到缓存里。
-
注入属性: 扫描到
@Resource private IOrdersCreateService owner;。 -
寻找依赖: Spring 去缓存里找
IOrdersCreateService。 -
找到自己: 即使现在的自己还没初始化完,但能找到刚才第 3 步暴露出去的引用。
-
注入成功: 把那个引用赋值给
owner。 -
初始化完成。
这样,owner 指向的就是当前这个 Bean(经过 AOP 代理后的对象),实现了自己调用自己的代理方法,从而让事务生效。
总结
文档里那段话的核心含义是:
不要等到 Bean 全部做好了再给别人用,只要把“壳子”做出来,就先把“壳子”给别人,这样大家都能先把引用连上,后面再慢慢填充内容。 这就是“延迟初始化”和“三级缓存”的精髓。
__14.5.那为什么要搞三级缓存
“够用。如果只是普通对象,我们只需要把‘半成品’放到二级缓存,B 直接拿去用就行了。”
那为什么要搞第三级? 候选人: “是为了适配 AOP (动态代理)。
-
原则: Spring 的设计原则是,Bean 的代理对象通常是在生命周期的最后一步(
BeanPostProcessor)才创建的。 -
冲突: 如果 A 涉及到 AOP,B 在中间想要 A 的时候,不能给 A 的原始对象,必须给 A 的代理对象。
-
解决: 第三级缓存里存的是一个
ObjectFactory。-
如果 B 只要原始对象,工厂就返回原始对象。
-
如果 A 需要 AOP,这个工厂会提前执行 AOP 逻辑,生成代理对象给 B,从而打破了‘最后一步才创建代理’的常规流程。
-
结论: 第三级缓存是为了在‘循环依赖’和‘AOP 代理’并存的复杂场景下,依然保证单例对象的唯一性。”
-
15.单例模式和多例模式?
| 特性 | 单例 (Singleton) | 多例 (Prototype) |
|---|---|---|
| 实例数量 | 1 个 (全局唯一) | N 个 (无限) |
| 创建时机 | 容器启动时 (通常) | 每次请求/注入时 |
| 销毁时机 | 容器关闭时 | 容器不管 (GC 自动回收) |
| 线程安全 | 不安全 (需开发人员保证无状态) | 安全 (每个线程独享一个) |
| 性能 | 高 (复用对象) | 低 (频繁创建对象) |
| 典型应用 | Service, DAO, Component | Action, Stateful Entity |
| 结合你之前的代码理解 |
回头看你之前提供的 分布式锁切面 (LockAspect) 和 工厂 (DefaultTreeFactory):
-
LockAspect(切面类)-
它是单例的。
-
Spring 容器启动时,只创建了一个
LockAspect对象。 -
所有用户的下单请求,都会经过这同一个切面对象。
-
思考: 为什么它里面没有成员变量?因为它必须是无状态的,否则张三的锁逻辑可能会干扰李四。
-
-
DefaultTreeFactory(规则树工厂)-
它是单例的。 (
@Service) -
里面的
Map<String, ILogicTreeNode> logicTreeNodeGroup是在构造函数里初始化一次就不变了。 -
不管多少个线程来调用
openLogicTree,用的都是同一份 Map 数据。
-
-
DecisionTreeEngine(执行引擎)-
注意看工厂里的这句代码:
Java
public IDecisionTreeEngine openLogicTree(RuleTreeVO ruleTreeVO) { // 这里用了 new! return new DecisionTreeEngine(logicTreeNodeGroup, ruleTreeVO); } -
它是多例的(虽然不是 Spring 管理的)。
-
每次做一个新的决策,都
new一个新的引擎。为什么?因为每个引擎需要绑定具体的ruleTreeVO(数据),这是有状态的,不能混用。
-
16.spring框架中都用到了哪些设计模式
| 模式 | Spring 典型类 | 一句话解释 |
|---|---|---|
| 工厂 | BeanFactory | “别自己 new,找我要” |
| 单例 | Singleton Scope | “全家只有这一个” |
| 代理 | AOP | “我是中介,找房东先过我这关” |
| 模板 | JdbcTemplate | “完形填空,脏活累活我做” |
| 适配器 | HandlerAdapter | “万能转接头” |
| 观察者 | ApplicationListener | “大喇叭广播,谁关心谁听” |
| 策略 | Resource | “条条大路通罗马,看你选哪条” |
| “Spring 框架应用了非常多的设计模式,最经典的可以归纳为以下 7 种: |
1. 工厂模式 (Factory Pattern) —— 最核心
-
体现:
BeanFactory和ApplicationContext。 -
作用: 实现了 IOC(控制反转)。Spring 容器本质上就是一个超级大工厂,我们将 Bean 的创建权交给工厂,调用者只需要
getBean(),解耦了对象的创建和使用。
2. 单例模式 (Singleton Pattern) —— 最常用
-
体现: Spring Bean 的默认作用域(Scope)就是 Singleton。
-
作用: 保证一个 Bean 在容器中只有一个实例。这也是为了性能考虑(减少创建销毁开销),并通过
DefaultSingletonBeanRegistry中的 Map 来管理。
3. 代理模式 (Proxy Pattern) —— AOP 基石
-
体现: Spring AOP 的底层实现。
-
作用: 如我们在事务或日志场景中,Spring 通过
JDK 动态代理或CGLIB生成代理对象,在不修改原有代码的情况下增强功能。
4. 模板方法模式 (Template Method Pattern) —— 解决重复代码
-
体现:
JdbcTemplate、RestTemplate、RedisTemplate。 -
作用: Spring 把那些繁琐的、固定的步骤(如:打开连接、关闭连接、处理异常)封装在父类/模板类里,只留出核心业务逻辑(SQL 语句、参数)让开发者去实现。
5. 适配器模式 (Adapter Pattern) —— MVC 的润滑剂
-
体现: Spring MVC 中的
HandlerAdapter。 -
作用: 我们写的 Controller 方法五花八门(有的带注解、有的不带)。
DispatcherServlet不能直接调用它们,于是通过适配器(HandlerAdapter)来标准化调用流程,让不同的 Controller 都能被统一执行。
6. 观察者模式 (Observer Pattern) —— 事件驱动
-
体现: Spring 的 Event 机制(
ApplicationEvent,ApplicationListener)。 -
作用: 实现了发布-订阅功能。比如容器启动完成后发布
ContextRefreshedEvent,监听器收到后执行初始化操作。
7. 策略模式 (Strategy Pattern) —— 灵活切换
-
体现: 资源的加载(
Resource接口有ClassPathResource,FileSystemResource等实现)或者 Bean 的实例化策略(InstantiationStrategy)。 -
作用: 就像我之前代码里的
DefaultTreeFactory,定义一个接口,有多种实现,运行时根据情况选择用哪一种。”
17.spring 常用注解有什么?
你说得非常对!这段代码是 教科书级别 的 @Bean 使用案例,完美印证了我们刚才讨论的 “如何将第三方库组件纳入 Spring 管理”。
这不是“重写(Rewrite)”了第三方库的源码(你没改 Redisson 的代码),而是 “自定义配置并注册(Customize & Register)” 了第三方库的对象。
我来帮你深度拆解这段代码的 核心作用 和 设计思想:
- 它的核心作用:“翻译”与“入职”
RedissonClient 是 Redisson 这个第三方 jar 包里的核心接口。Spring Boot 默认认识 Redis(通过 RedisTemplate),但它不一定默认帮你配好 Redisson(尤其是复杂的集群或哨兵模式)。
这段代码做了两件事:
-
翻译(配置转换):
-
Spring 的配置文件 (
application.yml) 里写的是通用的spring.redis.host等参数。 -
Redisson 需要的是它自己特定的
Config对象(比如config.useSingleServer().setAddress(...))。 -
这段代码就是个翻译官:把 Spring 的通用属性 (
RedisProperties) 读取出来,塞到 Redisson 专属的Config对象里。
-
-
入职(注册 Bean):
-
通过
@Bean,把创建好的redissonClient对象交给 Spring 容器管理。 -
后果: 以后你在项目的任何地方(比如你的分布式锁切面
LockAspect里),只要写@Autowired RedissonClient client,Spring 就会把这里创建的对象送过去。
-
- 代码细节逐行解读
A. 为什么用 @Configuration 和 @Bean?
因为 RedissonClient 是别人写的代码(第三方库),你不能跑去 Redisson 的源码里,在 Redisson 类头上加 @Component。 所以你必须用“工厂模式”: 自己写个配置类,用 @Bean 方法 new 一个出来返回给 Spring。
B. @ConditionalOnMissingBean 是什么意思?(高阶知识点)
@Bean
@ConditionalOnMissingBean // <--- 这个注解很关键
public RedissonClient redissonClient(RedisProperties properties) { ... }这个注解的意思是:“如果容器里还没有 RedissonClient,那就用我这个;如果已经被别人定义过了,我就不生效了。”
- 作用: 这是一种**“兜底策略”**。它允许你在其他地方(比如专门的测试配置类里)手动定义一个特殊的 RedissonClient。如果没有特殊定义,Spring 就会使用你这个默认的配置。这是编写通用组件或 Starter 时的标准写法。
C. 复杂的 if-else 逻辑
if (cluster != null) { ... } // 集群模式
else if (sentinel != null) { ... } // 哨兵模式
else { ... } // 单机模式-
这说明你的项目考虑得很周全,为了适配不同的生产环境。
-
开发环境可能是单机(Single)。
-
生产环境可能是集群(Cluster)或哨兵(Sentinel)。
-
这段代码让你只需要改
application.yml,不需要动 Java 代码,就能自动适配不同的 Redis 架构。
- 和你之前代码的联动
你之前展示的分布式锁切面中有一行代码:
Java
// LockAspect.java
// 这里的 redissonClient 是哪里来的?
// 就是你现在这段 RedissonConfiguration 代码 new 出来并交给 Spring 的!
RLock rLock = redissonClient.getLock(redisKey);
如果没有这段 RedissonConfiguration 代码: Spring 启动时会报错:Field redissonClient in ...LockAspect required a bean of type 'org.redisson.api.RedissonClient' that could not be found.(找不到 Bean)。
总结
-
是重写吗? 不是重写源码,是 “手动装配”。
-
什么用?
-
读取配置文件中的 Redis 地址、密码。
-
创建 Redisson 的连接配置对象。
-
实例化
RedissonClient并放入 Spring 容器(IOC)。
-
-
地位: 它是整个分布式锁功能的 “基础设施”。没有它,你的锁切面就拿不到客户端,也就无法加锁。
18.Spring的事务什么情况下会失效?
| 场景 | 核心原因 | 解决方案 |
|---|---|---|
同一个类内部调用 (this) | 绕过了代理对象 | 注入自己 (owner) 或 AopContext |
方法是 private,final | 代理类无法增强 | 改为 public |
try-catch 捕获了异常 | 切面捕获不到异常信号 | 手动 throw 或设置 rollbackOnly |
| 抛出 Checked 异常 | 默认只回滚 RuntimeException | 加 rollbackFor = Exception.class |
| 数据库不支持 | 底层硬件不支持 | 换 InnoDB 引擎 |
19.Bean的生命周期说一下?
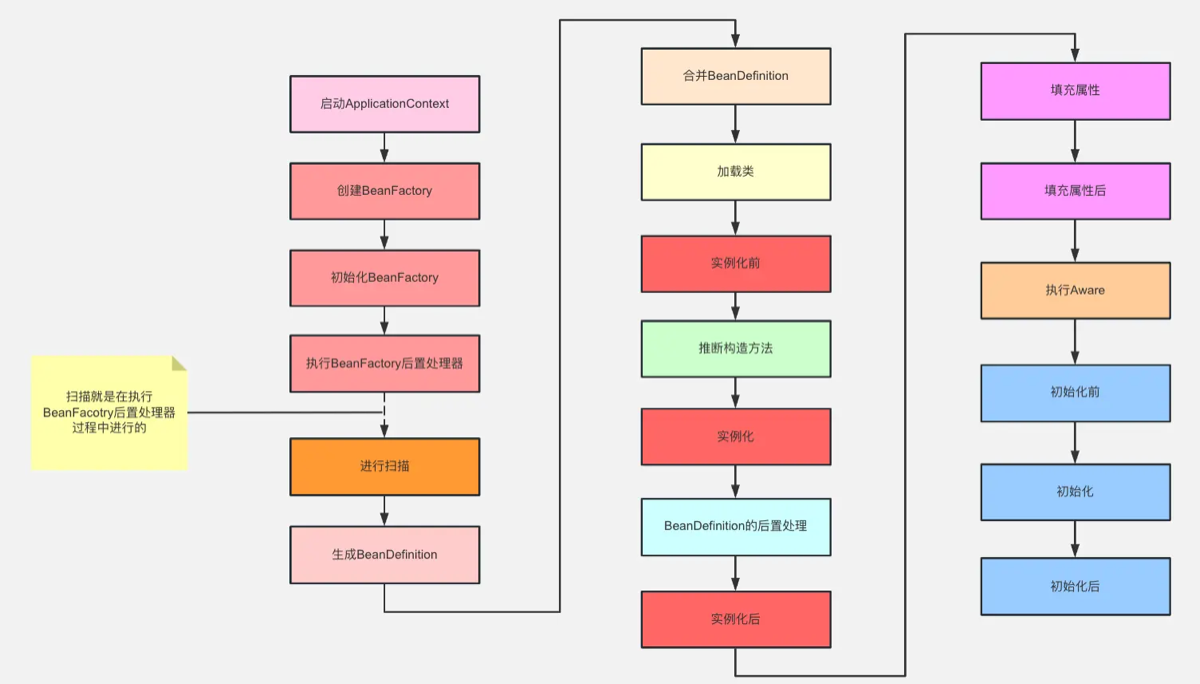
“Spring Bean 的生命周期非常复杂,但宏观上可以分为四个大阶段:实例化 → 属性赋值 → 初始化 → 销毁。
在这个过程中,Spring 提供了很多扩展点(Extension Points),让我们可以插手 Bean 的创建过程。具体流程如下:
第一阶段:实例化 (Instantiation) —— “招聘入职”
-
Spring 容器通过反射(
Constructor)把对象new出来。 -
此时: 对象只是个空壳子,属性都是 null。
第二阶段:属性赋值 (Populate) —— “发装备”
-
Spring 检查对象里的
@Autowired或@Value注解,把依赖的其他 Bean 或配置值注入进去。 -
此时: 对象有血有肉了,但还不能干活(没初始化)。
第三阶段:初始化 (Initialization) —— “岗前培训” (最复杂)
这里是扩展点最密集的地方,顺序如下:
-
检查 Aware 接口: 如果 Bean 实现了
BeanNameAware或ApplicationContextAware,Spring 会把 Bean 的名字或容器本身传给它。(告诉它:你是谁,你属于哪个公司)。 -
BeanPostProcessor (前置处理): 执行
postProcessBeforeInitialization。这是程序员对 Bean 进行修改的第一个机会。 -
执行初始化方法:
-
先执行
@PostConstruct注解的方法。 -
再执行
InitializingBean接口的afterPropertiesSet方法。 -
最后执行 XML 中定义的
init-method。
-
-
BeanPostProcessor (后置处理) —— AOP 的发生地: 执行
postProcessAfterInitialization。- 关键点: 如果这个 Bean 需要 AOP 增强(比如你的
OrderService需要加分布式锁),Spring 会在这里把原始对象替换成 代理对象。
- 关键点: 如果这个 Bean 需要 AOP 增强(比如你的
第四阶段:销毁 (Destruction) —— “离职走人”
- 当容器关闭时,执行
@PreDestroy或DisposableBean接口的方法,释放资源(比如关闭线程池、断开 Redis 连接)。”
核心记忆图谱 (一张表搞定)
面试时如果背不下来所有细节,记住粗体字部分:
| 步骤 | 阶段 | 动作 | 比喻 |
|---|---|---|---|
| 1 | 实例化 | createBeanInstance() | 生孩子 (先把它生出来) |
| 2 | 属性赋值 | populateBean() | 起名字 (给它填资料、注依赖) |
| 3 | Aware 接口 | invokeAwareMethods() | 发身份证 (让它知道自己是谁) |
| 4 | BPP 前置 | postProcessBeforeInitialization | 化妆前 (微调一下) |
| 5 | 初始化 | @PostConstruct / init-method | 上学 (学习技能,准备干活) |
| 6 | BPP 后置 | postProcessAfterInitialization | 整容/变身 (AOP) (变成了代理对象) |
| 7 | 使用中 | (业务调用) | 打工 (干活) |
| 8 | 销毁 | @PreDestroy / destroy-method | 退休 (清理资源) |
结合你的代码实战
AOP 代理的产生 (BPP 后置处理) 你的 OrderService 被加上了 @Lock 注解。
-
在 第三阶段(初始化) 的最后一步(BPP 后置处理)中,Spring 发现这个 Bean 需要切面增强。
-
于是,放入容器的不再是原始的
OrderService,而是经过 CGLIB 生成的代理对象。
20.Bean是否单例?
“默认情况下,是单例的 (Singleton)。
但这取决于我们如何配置它的作用域 (Scope)。Spring 主要提供了以下几种作用域:
1. singleton (默认)
-
含义: 在整个 Spring 容器(ApplicationContext)中,该 Bean 只有一个实例。
-
创建时机: 容器启动时(如果是懒加载
@Lazy,则是第一次使用时)。 -
场景: 绝大多数 Controller、Service、DAO 都是单例的。
2. prototype (多例)
-
含义: 每次从容器获取(
getBean或注入)时,都会创建一个全新的实例。 -
场景:
Struts2的 Action(因为它要把请求参数绑定在成员变量上),或者一些非线程安全的状态对象。
3. Web 相关的作用域 (request / session)
-
request: 每个 HTTP 请求创建一个新 Bean。
-
session: 每个 HTTP Session 创建一个新 Bean。
但是(划重点)! 既然绝大多数 Bean 都是单例的,这就引入了一个核心问题:线程安全问题。 Spring 的单例 Bean 并不是天生线程安全的。
-
如果 Bean 是无状态的(Stateless,比如 Service 里面只有方法,没有成员变量),那就是线程安全的。
-
如果 Bean 是有状态的(Stateful,比如在 Controller 里定义了一个
count变量),那在并发环境下就是不安全的。”
21.Bean的单例和非单例,生命周期是否一样
“不一样。简单来说:Spring 对单例 Bean 负责到底,对多例 Bean 则是‘管生不管养’。
1. 相同点:创建过程是一样的 无论是单例还是多例,它们都要经历完整的初始化阶段:
-
实例化 (Instantiation)
-
属性赋值 (Populate)
-
初始化前置处理 (BeanPostProcessor Before)
-
初始化方法 (
@PostConstruct,init-method) -
初始化后置处理 (BeanPostProcessor After)
2. 不同点:销毁过程完全不同
-
单例 Bean (Singleton):
-
它一直驻留在 Spring 容器中。
-
当容器关闭时,Spring 会负责触发销毁回调(如
@PreDestroy,DisposableBean的destroy方法),帮我们清理资源。 -
总结: 从生到死,Spring 全程包办。
-
-
多例 Bean (Prototype):
-
Spring 把这个 Bean 创建好并交给调用者(User)之后,就不再管理它了。
-
Spring 不会调用多例 Bean 的销毁方法。
-
这个 Bean 什么时候死、怎么死,完全取决于 Java 的垃圾回收机制 (GC),或者由客户端代码手动清理。
-
总结: Spring 只负责把它生出来,之后就‘失联’了。”
-
22.Spring bean的作用域有哪些?
“Spring 容器中的 Bean 作用域主要分为 两大类,共 5 种常用类型:
1. 核心作用域 (所有 Spring 应用通用)
-
singleton (单例) —— 【默认值】
-
机制: 在整个 Spring 容器中,该 Bean 只有一个实例。
-
特性: 无论获取多少次,拿到的都是同一个对象。
-
场景: 绝大多数无状态的 Service、DAO、Controller 都是单例的。
-
注意: 单例 Bean 必须关注线程安全问题。
-
-
prototype (多例/原型)
-
机制: 每次通过
getBean()或依赖注入时,容器都会创建一个全新的实例。 -
特性: Spring 只负责创建,不负责销毁(管生不管养)。
-
场景: 那些非线程安全的、或者需要保存临时状态的对象(如 Struts2 的 Action)。
-
2. Web 作用域 (仅在 Web 环境下生效) 这部分需要配合 Spring MVC 使用。
-
request:
-
机制: 每次 HTTP 请求 都会创建一个新的 Bean。请求结束,Bean 销毁。
-
场景: 比如用来存放本次请求特有的用户数据。
-
-
session:
-
机制: 同一个 HTTP Session 共享同一个 Bean。Session 过期,Bean 销毁。
-
场景: 比如用户的购物车信息、登录信息。
-
-
application (全局):
-
机制: 在整个 ServletContext 生命周期内有效。
-
场景: 类似于 Web 应用的全局变量。
-
总结: 最常用的就是 singleton 和 prototype,Web 相关的在现代前后端分离架构中用得比较少了。”
| 作用域 | 范围 | 创建频率 | 销毁机制 | 典型场景 |
|---|---|---|---|---|
| singleton | 容器级 | 容器启动只创建 1 次 | 容器关闭时自动销毁 | Service, Controller |
| prototype | 调用级 | 每次请求都创建 N 次 | Spring 不管 (靠GC) | 状态对象 |
| request | 请求级 | 每个请求 1 次 | 请求结束销毁 | 用户追踪 |
| session | 会话级 | 每个会话 1 次 | 会话过期销毁 | 购物车 |
22.Spring容器里存的是什么?
“Spring 容器底层其实非常复杂,但核心存储主要分为 两大部分:
1. 存‘图纸’:BeanDefinition (Bean 定义信息)
-
存放位置:
beanDefinitionMap(一个ConcurrentHashMap)。 -
存的是什么: 在 Bean 被实例化之前,Spring 必须要知道这个 Bean 的类名是什么、Scope 是单例还是多例、是否延迟加载、依赖了谁。这些元数据被封装成
BeanDefinition对象存起来。 -
时机: 容器启动时,先扫描类文件,生成 BeanDefinition,存入这个 Map。
2. 存‘成品’:SingletonObjects (单例池)
-
存放位置:
singletonObjects(也就是我们常说的一级缓存,也是一个ConcurrentHashMap)。 -
存的是什么: 经历了完整的生命周期(实例化 → 填充属性 → 初始化)后,最终生成的可用的单例对象。
-
时机: 在第一次
getBean或者容器非懒加载启动时,根据BeanDefinition把对象造出来,存入这个 Map。
总结: Spring 容器 = BeanDefinition Map (配方) + Singleton Objects Map (成品菜)。”
23.在Spring中,在bean加载/销毁前后,如果想实现某些逻辑,可以怎么做
“这取决于我们是想对某一个特定的 Bean 定制逻辑,还是想对所有的 Bean 进行全局干预。
一、针对单个 Bean 的定制逻辑 (最常用) Spring 提供了三种方式,按照执行优先级的顺序如下:
-
使用注解 (推荐)
-
加载后: 在方法上加
@PostConstruct。 -
销毁前: 在方法上加
@PreDestroy。 -
优点: 符合 Java 标准 (JSR-250),使用最简单。
-
-
实现接口 (不推荐)
-
加载后: 实现
InitializingBean接口,重写afterPropertiesSet()方法。 -
销毁前: 实现
DisposableBean接口,重写destroy()方法。 -
缺点: 代码和 Spring 框架强耦合。
-
-
配置定义 (第三方库常用)
-
加载后: 在
@Bean注解中指定initMethod(如@Bean(initMethod = "init"))。 -
销毁前: 在
@Bean注解中指定destroyMethod。 -
优点: 适用于我们无法修改源码的第三方类(如 Redis 客户端)。
-
二、针对所有 Bean 的全局逻辑 (AOP 的基础) 如果我想在每一个 Bean 初始化之前和之后都打印一行日志,就需要用到 BeanPostProcessor (后置处理器)。 它有两个核心方法:
-
postProcessBeforeInitialization:在 Bean 实例化、依赖注入之后,但在调用初始化方法(如@PostConstruct)之前执行。 -
postProcessAfterInitialization:在调用初始化方法之后执行。”
核心执行顺序图 (必考)
面试官经常会让排序,记住这个 “三明治” 结构:
-
构造方法 (Constructor)
-
依赖注入 (Dependency Injection)
-
BeanPostProcessor (
Before) —— 【拦截点 1】 -
@PostConstruct -
InitializingBean -
init-method -
BeanPostProcessor (
After) —— 【拦截点 2】 (AOP 代理就在这生成) -
… 业务使用 …
-
@PreDestroy -
DisposableBean -
destroy-method
24.Spring给我们提供了很多扩展点,这些有了解吗?
“Spring 的扩展点非常丰富,正是因为这些扩展点,Spring 才能从一个简单的 IOC 容器发展成现在的全能生态。
在面试中,我通常把最核心的扩展点总结为 ‘两类处理器 + 一个监听器 + 一个接口’:
1. BeanPostProcessor (BPP) —— 【对象级】扩展
-
作用: 它是干预 Bean 初始化 过程的钩子。
-
时机: 在 Bean 实例化之后,初始化(
init-method)的前后执行。 -
核心应用: AOP 动态代理 就是在这里实现的。Spring 在
postProcessAfterInitialization里偷梁换柱,把原始对象换成了代理对象。还有处理@Autowired注解也是靠它。
2. BeanFactoryPostProcessor (BFPP) —— 【类定义级】扩展
-
作用: 它是干预 BeanDefinition(图纸) 加载过程的钩子。
-
时机: 在容器启动时,Bean 被实例化之前。
-
核心应用: 修改配置信息。比如处理配置文件中的占位符
${jdbc.url},就是在这一步替换成真实的数据库地址的。
3. ApplicationListener —— 【事件级】扩展
-
作用: 监听容器发布的事件。
-
时机: 贯穿整个容器生命周期。
-
核心应用: 比如监听
ContextRefreshedEvent(容器刷新完成事件),可以在系统启动完成后,立即执行一些数据预热(Warm-up)或缓存加载的操作。
4. FactoryBean —— 【构造级】扩展
-
作用: 个性化地‘造’对象。
-
应用: 当创建一个对象的过程非常复杂(比如 MyBatis 的
SqlSessionFactory),XML 配置写不出来时,就实现这个接口,在 Java 代码里自己写复杂的创建逻辑。
一句话总结:
BFPP 修改图纸,FactoryBean 定制制造,BPP 修改成品,Listener 监听动态。”
深度辨析:BPP vs BFPP (面试必考)
很多同学分不清这两个名字很像的接口,这里有个形象的比喻:
| 特性 | BeanFactoryPostProcessor (BFPP) | BeanPostProcessor (BPP) |
|---|---|---|
| 操作对象 | BeanDefinition (图纸) | Bean Instance (具体的对象) |
| 执行时机 | 很早 (房子还没盖,改蓝图) | 较晚 (房子盖好了,装修/验收) |
| 典型场景 | 解析 ${...} 占位符、扫描 @Configuration | AOP 代理、@Autowired 注入 |
| 比喻 | 建筑设计师 (修改设计图) | 质检员 (检查并包装产品) |