1.juc包下你常用的类?
“在日常开发中,我常用的 JUC 类主要分为 4 大类: 1. 线程池相关 (Thread Pool) —— 最常用
ThreadPoolExecutor:这是最核心的类,用于自定义创建线程池,我们在生产环境一般都用它来控制线程数量,避免资源耗尽。Executors:这是个工厂类,虽然方便(比如newFixedThreadPool),但在大厂规范里通常禁止直接使用,因为它容易导致 OOM,所以我们主要用它来辅助理解,实际都手写ThreadPoolExecutor。^3daa81
2. 并发集合类 (Collections)
ConcurrentHashMap:这是高并发下替代 HashMap 的神器,通过分段锁(JDK 7)或 CAS + synchronized(JDK 8)保证了线程安全且高性能。CopyOnWriteArrayList:适合读多写少的场景(比如白名单缓存),写的时候复制新数组,读的时候不加锁。
3. 并发工具类 (Tools)
CountDownLatch:用于‘倒计时’。比如主线程等待 5 个子线程都执行完,才汇总结果。
// 1. 创建一个计数器,初始值为 5
CountDownLatch latch = new CountDownLatch(5);
for (int i = 0; i < 5; i++) {
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + " 交卷了!");
// 2. 每一个线程做完事,就让计数器减 1
latch.countDown();
}).start();
}
// 3. 主线程在这死等,直到计数器变成 0 才会继续往下走
latch.await();
System.out.println("所有人都交卷了,老师锁门回家!");CyclicBarrier:用于‘循环栅栏’。比如让一组线程互相等待,都到了集结点再一起并发执行。Semaphore:用于‘信号量’。主要用来限流,比如只允许 10 个线程同时访问数据库。
4. 原子类 (Atomic)
AtomicInteger/AtomicLong:基于 CAS(Compare-And-Swap,比较并交换) 原理实现的无锁原子更新,常用于做计数器(比 synchronized 性能高)。”
2.怎么保证多线程安全?
| 策略分类 | 核心手段 | 典型代表 | 适用场景 |
|---|---|---|---|
| 互斥同步 (锁) | 阻塞其他线程 | synchronized, ReentrantLock | 复杂的业务逻辑,临界区代码较长 |
| 非阻塞同步 | CAS 自旋 | AtomicInteger, LongAdder | 简单的数值计算,计数器 |
| 数据隔离 | 线程独享 | ThreadLocal | 数据库连接,Session 管理 |
| 不可变 | 只读 | String, final 变量 | 配置信息,常量 |
| 可见性保障 | 内存屏障 | volatile | 状态标志位,单例模式 |
BlockingQueue
-
线程 A(生产者)把数据丢进队列。
-
线程 B(消费者)从队列另一头取数据。
-
交换意义:这实现了数据的所有权转移。数据从 A 的私有空间,通过队列,正式移交给了 B。
3.Java中有哪些常用的锁,在什么场景下使用?
1. 内置锁 synchronized (最基础)
-
特点: Java 语言层面的关键字,使用最简单。它会自动加锁和释放锁。
-
升级机制: JVM 对它做了大量优化,支持偏向锁 → 轻量级锁 → 重量级锁的升级过程,性能已经很不错了。
-
场景: 绝大多数需要同步的常规业务场景,代码简洁,不易出错。
2. 显式锁 ReentrantLock (最灵活)
-
特点: JUC 包下的 API 锁。需要手动
lock()和finally中unlock()。 -
优势: 比 synchronized 强大,支持公平锁(先来后到)、可中断(等不到锁就算了)、超时获取等高级功能。
-
场景: 需要精细控制锁的逻辑,或者需要实现公平锁的场景。
3. 读写锁 ReadWriteLock / ReentrantReadWriteLock
-
特点: 把锁分成了‘读锁’和‘写锁’。
-
读锁是共享的(大家都能读)。
-
写锁是独占的(我写的时候,你们不能读也不能写)。
-
-
场景: 典型的读多写少场景,比如缓存系统、配置中心,能极大提升并发性能。
4. 乐观锁 (CAS 机制)
-
特点: 其实不是一种‘锁’,而是一种无锁算法。典型的实现是
AtomicInteger等原子类。 -
原理: 修改时不加锁,而是判断一下‘原来的值有没有被别人改过’,没改过就更新,改过就重试。
-
场景: 并发竞争不激烈的场景(比如简单的计数器)。如果竞争太激烈,会导致 CPU 空转(自旋)严重。”
4.怎么在实践中用锁的?
| 锁类型 | 核心实践规范 (Best Practice) | 后果 (如果不遵守) |
|---|---|---|
| synchronized | 缩小锁范围 (只锁核心代码) | 范围太大导致性能急剧下降 (串行化) |
| ReentrantLock | 必须在 finally 中 unlock | 业务抛异常会导致死锁 (锁永远不释放) |
| ReadWriteLock | 区分读写操作 | 用错锁会导致性能没有提升 |
5.Java 并发工具你知道哪些?
“在 java.util.concurrent 包下,我最常用的并发工具主要有三个:CountDownLatch、CyclicBarrier 和 Semaphore。
1. CountDownLatch (倒计时门闩)
-
作用: 它允许一个或多个线程等待其他线程完成操作。
-
原理: 初始化一个计数器(比如 5),每次一个任务完成就调用
countDown()减 1。主线程调用await()阻塞等待,直到计数器归零,门闩打开,主线程继续执行。 -
场景: 比如系统启动时,主线程要等待数据库连接、缓存加载、配置读取这 5 个子任务都初始化完毕,才能正式对外提供服务。
2. CyclicBarrier (循环栅栏)
-
作用: 让一组线程互相等待,直到所有人都到达某个屏障点(Barrier),再一起继续执行。
-
与 CountDownLatch 的区别: CountDownLatch 是一次性的(减法),而 CyclicBarrier 是可循环利用的(加法),且它是多线程互相等待,而不是主线程等子线程。
-
场景: 比如多线程计算,把一个大表格拆成 4 份给 4 个线程算,大家都算完了,在栅栏处汇合,再汇总结果。或者像游戏加载,10 个玩家都加载到 100% 了,才一起开始游戏。
3. Semaphore (信号量)
-
作用: 用于控制同时访问特定资源的线程数量(限流)。
-
原理: 比如有 3 个许可证,来了 10 个线程。前 3 个拿走许可证(
acquire)执行,剩下的 7 个排队。等有人归还(release)了,后面的人才能进。 -
场景: 流量控制。比如数据库连接池只有 50 个连接,为了不把数据库打挂,我们可以用 Semaphore 限制同时只有 50 个线程能访问 DB。”
-
Callable(任务制造者):-
它是一个函数式接口,类似于
Runnable。 -
核心方法是
call()。 -
特点: 有返回值(泛型 V),并且可以抛出异常。
-
-
Future(结果领取凭证):-
它是用来接收
Callable任务执行结果的‘票据’。 -
当我们把
Callable扔给线程池执行时,线程池会立刻返回一个Future对象给我们。 -
核心功能: 我们可以拿着这个
Future去检查任务是不是做完了(isDone),或者阻塞等待获取结果(get),甚至取消任务(cancel)。
-
6.CountDownLatch 是做什么的讲一讲?
“CountDownLatch(倒计时门闩)是 JUC 包下的一个同步工具类。 它的核心作用是:允许一个或多个线程等待其他线程完成操作。
我们可以把它理解为一个**‘倒计时器’**。
1. 核心工作原理
-
初始化时,我们给它设置一个计数器(比如 5)。
-
子线程执行完任务后,调用
countDown()方法,计数器减 1。 -
主线程调用
await()方法,此时主线程会被阻塞(卡在这里不动)。 -
当计数器减到 0 时,门闩打开,阻塞的主线程被唤醒,继续执行后续代码。
2. 典型应用场景 它最经典的使用场景是 ‘一等多’(One waits for Many):
-
系统初始化: 比如电商系统启动时,主线程需要等待 数据库连接池、Redis 缓存、MQ 消费者 这 3 个模块都初始化完毕,才能对外提供服务。
-
初始化
new CountDownLatch(3)。 -
3 个模块启动完分别
countDown()。 -
主线程
await()等它们都好了再放行。
-
-
多线程数据汇总: 比如做一个 Excel 报表,需要查询 5 个不同的数据库表。我们可以开 5 个线程并行去查,主线程等它们都查完了,再聚合数据。
3. 与 CyclicBarrier 的区别 (加分项)
-
CountDownLatch 是一次性的,计数器减到 0 就废了,不能复用。
-
CyclicBarrier 是可循环的,而且侧重于‘多线程互相等待’。
7.synchronized和reentrantlock及其应用场景?
| 特性 | synchronized | ReentrantLock(只能用在代码块上) |
|---|---|---|
| 层级 | JVM 关键字 | JDK API 类 |
| 释放锁 | 自动释放 | 必须手动 unlock (在 finally 中) |
| 公平性 | 非公平 | 默认非公平,可支持公平 |
| 中断响应 | 不可中断 | 可中断 |
| 条件队列 | 单个 (wait/notify) | 多个 (Condition) |
| 适用性 | 简单场景,常规业务 | 复杂并发控制,需要高级功能 |
8.除了用synchronized,还有什么方法可以实现线程同步??
“除了 JVM 层面的 synchronized 关键字外,JDK 的 JUC 包还提供了非常丰富的同步机制,主要有以下 3 类替代方案:
1. 使用显式锁 Lock 接口 (最直接的替代) 最典型的实现类是 ReentrantLock。
-
原理: 它是基于 AQS 实现的。
-
优势: 相比
synchronized,它功能更强大。-
支持公平锁(先来后到)。
-
支持非阻塞获取锁(
tryLock,拿不到就走,不傻等)。 -
支持中断等待(等得不耐烦了可以取消)。
-
-
场景: 需要灵活控制锁的获取和释放,或者需要公平锁时。
2. 使用原子类 Atomic (高性能无锁方案) 比如 AtomicInteger、AtomicReference。
-
原理: 它们不加锁,而是利用底层的 CAS (Compare-And-Swap) 机制来保证线程安全。
-
优势: 性能比加锁高,没有上下文切换的开销。
-
场景: 适用于简单的计数器、状态标记等更新操作。
3. 使用并发工具类 (协作同步) 如果不是为了互斥,而是为了线程间的协作,可以使用:
-
ReadWriteLock(读写锁): 适合读多写少的场景,读读不互斥,提升并发性能。 -
Semaphore(信号量): 控制同时访问资源的线程数量(限流)。 -
CountDownLatch/CyclicBarrier: 用于线程间的等待和协调。”
9.synchronized锁静态方法和普通方法区别?
“它们的区别主要在于**加锁的对象(锁的范围)**不同:
1. 锁的对象不同
-
普通同步方法 (Instance Method): 锁的是当前实例对象 (
this)。- 也就是说,锁是属于具体的某一个对象的。
-
静态同步方法 (Static Method): 锁的是当前类的 Class 对象 (
ClassName.class)。- 因为静态方法属于类,不属于对象,所以它锁住的是整个类(相当于全局锁)。
2. 作用范围与并发度不同
-
普通方法: 如果创建了两个不同的对象
obj1和obj2。线程 A 调用obj1的同步方法,线程 B 调用obj2的同步方法,它们互不干扰(因为锁的是不同的房子)。 -
静态方法: 无论创建了多少个对象,静态方法的锁只有一把(Class 对象只有一份)。只要有一个线程正在执行静态同步方法,所有对象的其他线程想执行静态同步方法,都必须排队。
3. 是否互斥 (关键考点)
-
它们之间不互斥!
-
如果线程 A 访问 静态同步方法(拿的是 Class 锁)。
-
此时线程 B 访问同一个类的 普通同步方法(拿的是对象锁)。
-
结果: 它们可以同时运行,不会阻塞。因为它们抢的不是同一把锁。”
-
-
普通方法 = 锁自家大门(不同实例之间不影响)。
-
静态方法 = 锁小区大门(所有人进出都得排队)。
-
两者混用 = 你锁你的小区门,我锁我的自家门,互不冲突。
10.怎么理解可重入锁?
“1. 什么是可重入锁?(核心定义) 可重入锁,也叫递归锁。 它的含义是:当一个线程已经持有了某个锁,再次请求这个锁时,无需排队,可以直接进入。
简单来说就是:‘自己家的大门,自己手里有钥匙,进了一道门之后,屋里还有一道门,依然可以用这把钥匙直接打开,不需要去重新领钥匙’。
2. 为什么需要可重入性?(解决什么问题) 主要是为了避免死锁。 如果锁不可重入,当一个线程在执行 methodA(拿了锁)时,内部调用了 methodB(也需要这把锁)。如果不可重入,线程就会在门口自己等自己释放锁,结果永远等不到,导致自己把自己锁死。
3. Java 中的代表
-
synchronized:天生就是可重入的(隐式实现)。 -
ReentrantLock:从名字就能看出是可重入的(显式实现)。
4. 底层实现原理 (ReentrantLock 视角) 它的底层通过 AQS 的 state 变量和一个 exclusiveOwnerThread 变量来实现:
-
线程来抢锁时,判断
exclusiveOwnerThread是不是自己? -
是自己: 直接允许进入,并且把
state加 1(表示重入次数)。 -
不是自己: 乖乖去排队。
-
释放锁时:
state减 1,直到减为 0 时,才真正释放锁。”
11.synchronized 支持重入吗?如何实现的?
“1. 结论 支持。 synchronized 是可重入锁。如果不可重入,子类调用父类的同步方法、或者在一个同步方法里调用另一个同步方法时,就会产生死锁,这显然是不合理的。
2. 实现原理 synchronized 的重入机制是基于 JVM 底层的 ObjectMonitor (监视器锁) 来实现的。 Monitor 对象内部维护了两个核心变量:
-
_owner:记录当前持有锁的线程。 -
_count(或_recursions):记录锁的重入次数(计数器)。
| 特性 | synchronized | ReentrantLock |
|---|---|---|
| 实现层级 | JVM 层 (ObjectMonitor) | JDK 层 (AQS) |
| 计数器位置 | C++ 对象 (_count) | Java 变量 (state) |
| 释放方式 | 编译器自动插入指令 | 必须手动代码释放 |
| 逻辑本质 | Owner 匹配 + 计数器 | Thread 匹配 + 计数器 |
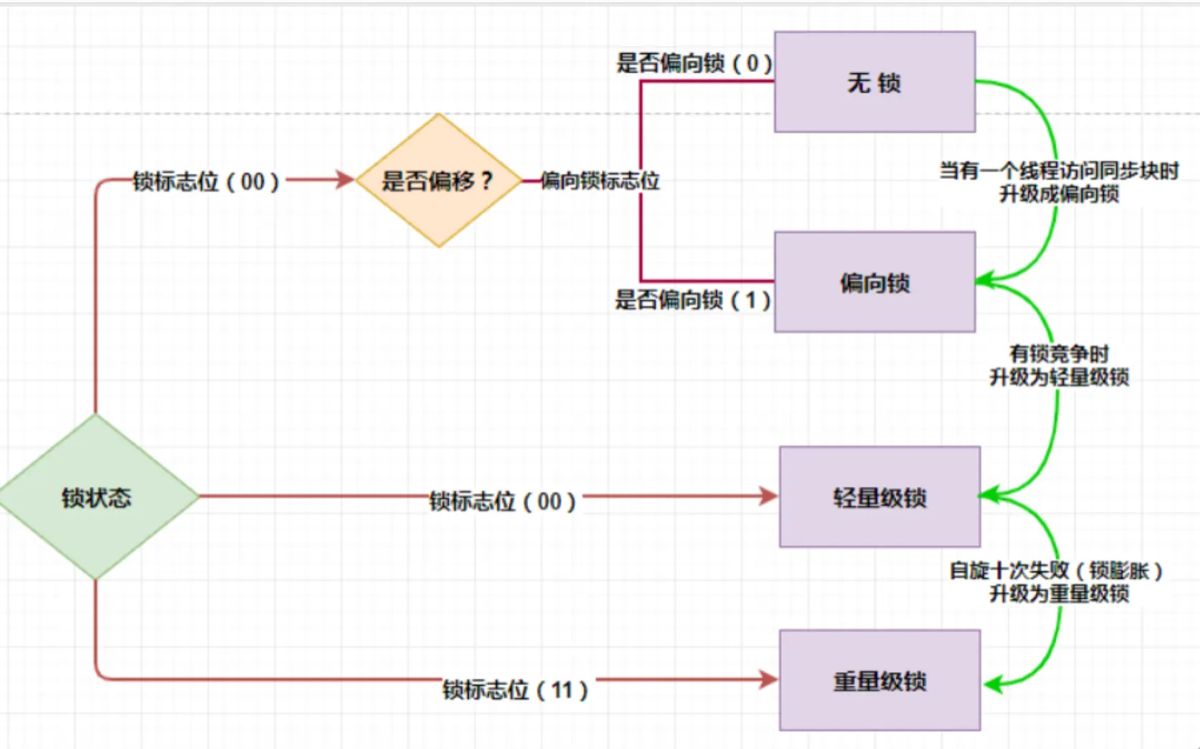
12.*syncronized锁升级的过程讲一下
“在 JDK 1.6 之前,synchronized 是重量级锁,性能较差。但在 1.6 之后,JVM 引入了锁升级机制,锁的状态会随着竞争情况逐渐升级,主要分为 4 个阶段:
1. 无锁状态 (No Lock)
- 对象刚被创建出来,没有任何线程来抢,Header 里的 Mark Word 是干净的。
2. 偏向锁 (Biased Lock) —— “一人独占”
-
场景: 只有一个线程(线程 A)在访问同步块,完全没有竞争。
-
过程: JVM 会把线程 A 的 ID 记录在对象的 Mark Word 中。
-
效果: 以后线程 A 再来,只要检查一下 ID 是自己,就直接进入,完全没有加锁解锁的开销(连 CAS 都不用做),性能极高。
3. 轻量级锁 (Lightweight Lock) —— “交替使用”
-
场景: 线程 A 还没执行完,线程 B 来了。也就是说,有竞争,但竞争不激烈(锁持有时间短,线程交替执行)。
-
过程: 偏向锁失效。JVM 会在当前线程的栈帧中创建一个 Lock Record(锁记录),然后尝试用 CAS 操作把对象的 Mark Word 替换为指向 Lock Record 的指针。
-
效果: 谁 CAS 成功谁就拿到锁。没抢到的线程不会立刻阻塞睡觉,而是会自旋(Spin,空循环)几次,看看能不能马上等到锁释放(自旋锁)。
4. 重量级锁 (Heavyweight Lock) —— “激烈竞争”
-
场景: 竞争很激烈。或者线程 B 自旋了很多次还是没抢到锁。
-
过程: 锁膨胀为重量级锁。底层的 Mark Word 指向 ObjectMonitor。
-
效果: 没抢到锁的线程会被挂起(阻塞),进入操作系统内核态等待,消耗较大的上下文切换资源。”
13.JVM对Synchornized的优化?
| 优化手段 | 核心逻辑 | 目的 |
|---|---|---|
| 锁升级 | 偏向 → 轻量 → 重量 | 匹配不同的竞争程度 |
| 锁消除 | 逃逸分析,没别人看得到 | 去掉多余的锁 |
| 锁粗化 | 循环/连续加锁 | 减少加锁频率 |
| 自适应自旋 | 参考历史成功率 | 避免 CPU 盲目空转 |
14.介绍一下AQS
AQS(抽象队列同步器)是 Java JUC 包下的一个抽象类,它是构建锁(如 ReentrantLock)和同步器(如 Semaphore、CountDownLatch)的基础框架。 它的核心思想是:如果请求的资源空闲,就将当前线程设置为工作线程;如果资源被占用,就将当前线程加入到一个队列中排队等待。
设计模式:模板方法模式 AQS 使用了模板方法模式。
-
AQS 爸爸把排队、阻塞、唤醒这些脏活累活都干了(定义在顶层逻辑里)。
-
具体的同步器(如 ReentrantLock)只需要实现
tryAcquire(尝试获取资源)和tryRelease(尝试释放资源)这两个简单的钩子方法,告诉 AQS ‘什么样的状态算获取成功’ 即可。”
15.CAS 和 AQS 有什么关系?
-
AQS (AbstractQueuedSynchronizer) 就像是 银行的排队叫号系统(框架),它规定了谁先来谁后到、谁该排队。
-
CAS (Compare-And-Swap) 就像是 取号机的出票动作(底层原子操作)。
- 不管有多少人挤在取号机前,CAS 保证了**同一张号码(state)**只能被一个人拿走,不可能两个人拿到同一个号。
AQS 的底层实现强依赖于 CAS。 AQS 是一个同步框架,而 CAS 是这个框架中用于保证并发安全修改数据的核心工具。
16.如何用 AQS 实现一个可重入的公平锁?
“要实现这样一个锁,核心是自定义一个内部类去继承 AbstractQueuedSynchronizer,并重写它的 tryAcquire 和 tryRelease 方法。具体逻辑如下:
| 特性 | 实现逻辑 | 关键 API |
|---|---|---|
| 公平性 | 抢锁前先看有没有人排队 | !hasQueuedPredecessors() |
| 可重入 | 锁被占时,检查是否是自己 | current == getExclusiveOwnerThread() |
| 原子性 | 修改状态必须用 CAS | compareAndSetState(0, 1) |
1. 定义状态 (State)
-
使用 AQS 的
state变量。 -
state = 0:表示锁空闲。 -
state > 0:表示锁被占用,数值表示重入的次数。
2. 实现获取锁 (tryAcquire) —— 核心难点 这是抢锁的逻辑,必须同时满足公平性和可重入性:
-
第一步:获取当前
state。 -
第二步:如果
state == 0(锁是空的):-
关键点 (体现公平性): 必须先判断 ‘队列里有没有人在排队’ (
hasQueuedPredecessors())。 -
只有 队列为空(没人排队)或者 我是队头 时,才允许尝试 CAS 把
state从 0 改为 1。 -
CAS 成功后,标记当前线程为
ExclusiveOwnerThread(持有锁的线程)。
-
-
第三步:如果
state > 0(锁被占了):-
关键点 (体现可重入性): 判断 ‘持有锁的线程是不是我自己’ (
current == getExclusiveOwnerThread())。 -
如果是自己,就将
state加 1 (state + acquires),表示重入成功。 -
如果不是自己,返回
false(抢锁失败,AQS 会把你扔进队列排队)。
-
3. 实现释放锁 (tryRelease)
-
获取
state并减去释放量 (state - releases)。 -
如果减完后
state == 0,说明锁完全释放了,清空持有线程 (setExclusiveOwnerThread(null))。 -
更新
state的值。”
16Threadlocal作用,原理,具体里面存的key value是啥,会有什么问题,如何解决?
6.了解的哈希冲突解决方法有哪些? 作用 → 原理 (Map) → 内存泄漏 (核心坑) → 解决方案。
ThreadLocal 的核心作用是实现线程间的数据隔离。 它能让每个线程都拥有自己独立的变量副本,互不干扰。这就好像每个线程都有自己的‘私人保险箱’,不需要加锁也能保证安全。
- 典型场景: 存储数据库连接、Session 信息、或者 Spring 事务管理中的 Connection。
| 维度 | 说明 |
|---|---|
| 存储位置 | 数据存在 Thread (线程) 里的 ThreadLocalMap 中 |
| Key | ThreadLocal 对象 (弱引用) |
| Value | 目标数据 (强引用) |
| 致命问题 | 内存泄漏 (Key没了,Value还在) |
| 解决方案 | 用完必须 remove() |
// 定义
static ThreadLocal<User> userContext = new ThreadLocal<>();
try {
// 1. 存数据
userContext.set(new User("小林"));
// 2. 业务逻辑...
} finally {
// 3. 【必须】清理数据,防止内存泄漏
userContext.remove();
}17.悲观锁和乐观锁的区别?
| 特性 | 悲观锁 (Pessimistic) | 乐观锁 (Optimistic) |
|---|---|---|
| 心态 | 总觉得有人抢 | 觉得没人抢 |
| 动作 | 先加锁,后操作 | 先操作,更新时检查 |
| 线程状态 | 阻塞 (Block) | 自旋 (Spin) / 重试 |
| 实现代表 | synchronized, ReentrantLock | Atomic 类, 版本号机制 |
| 缺点 | 性能低,上下文切换开销大 | 高并发写时 CPU 飙高 (自旋) |
| 最佳场景 | 写多读少 (高冲突) | 读多写少 (低冲突) |
18.Java中想实现一个乐观锁,都有哪些方式?
| 方式 | 核心机制 | 底层依赖 | 典型应用 |
|---|---|---|---|
| CAS 算法 | 比较并交换 + 自旋 | CPU 硬件指令 (cmpxchg) | AtomicInteger, ReentrantLock (内部状态) |
| 版本号机制 | Compare Version | 数据库 UPDATE 条件 | 库存扣减、抢票系统 |
| 整数换成了时间戳。但时间戳可能存在精度问题(比如两台机器时间不同步),所以推荐优先用版本号。” |
19.CAS 有什么问题,Java是怎么解决的?
| 问题 | 核心描述 | Java 解决方案 |
|---|---|---|
| ABA 问题 | 狸猫换太子 (A→B→A)副作用:栈顶元素变化 | AtomicStampedReference (加版本号) |
| CPU 开销大 | 很多线程一直自旋 | LongAdder (分段锁思想) 或 加锁 |
| 单变量局限 | 只能改一个值 | AtomicReference (封装成对象) |
20.voliatle关键字有什么作用?
“volatile 是 Java 虚拟机提供的轻量级同步机制,它主要有 2 个 核心作用:
1. 保证变量的可见性 (Visibility)
-
原理: 在 JMM(Java 内存模型)中,线程操作变量通常是先改自己工作内存里的副本,不一定立刻写回主内存。
-
volatile 的作用: 一旦一个变量被
volatile修饰,只要某个线程修改了它,JMM 会强制:-
立刻把新值刷新回主内存。
-
强制让其他线程工作内存中的缓存失效,下次读取时必须去主内存拿最新值。
-
-
效果: 保证了‘一个线程改了,其他线程立刻就能看见’。
2. 禁止指令重排序 (Ordering)
-
原理: 编译器和处理器为了优化性能,可能会调整代码的执行顺序(指令重排)。
-
volatile 的作用: 它通过插入 内存屏障 (Memory Barrier) 来禁止特定类型的重排序。
-
经典场景: 单例模式的 DCL(双重检查锁)。
-
instance = new Singleton()分为三步:1.分配内存 → 2.初始化 → 3.引用指向地址。 -
如果不加
volatile,可能会重排成 1→3→2。导致另一个线程拿到一个还没初始化完的半成品对象(不为 null 但没数据),从而报错。
-
3. 【重要】它不保证原子性 (Atomicity) 这是面试官最爱挖的坑。
-
volatile只能保证读/写的那一刻是原子的,但像i++这种‘读-改-写’复合操作,volatile救不了。 -
例子: 10 个线程同时对
volatile int i进行i++,结果往往小于预期。解决原子性问题必须用synchronized、Lock或Atomic类。”
21.指令重排序的原理是什么?
1. 什么是指令重排序? 指令重排序是指编译器或处理器为了优化程序性能,在不改变单线程执行结果的前提下,改变代码原有的执行顺序。 简单来说,就是:你写的代码顺序和计算机真正执行的顺序可能是不一样的。
2. 为什么要重排序?(原理/好处) 核心目的是 提高运行效率。
-
CPU 层面: 现代 CPU 都有流水线(Pipeline)技术。如果严格按顺序执行,前一条指令(比如读内存)卡住了,后面的指令哪怕和它没关系,也得干等。为了不让 CPU 闲着,处理器会把后面不依赖前者的指令提到前面先做(指令级并行)。
-
编译器层面: 编译器在生成字节码或机器码时,也会调整顺序,以便更好地利用寄存器或减少指令数。
3. 重排序的分类 主要分为三种:
-
编译器优化重排序: 编译器在编译阶段搞的。
-
指令级并行重排序: 处理器在执行阶段搞的。
-
内存系统重排序: 由于 CPU 缓存和读写缓冲区的存在,导致数据写入主内存的顺序看起来像是乱序的。
4. 带来的问题(核心考点) 在单线程环境下,重排序是安全的(As-if-serial 语义保证了结果不变)。 但在多线程环境下,重排序就是灾难。
- 例子: 线程 A 先
init = true,再context = load()(被重排了)。线程 B 看到init为 true 了,冲进去拿context,结果发现是空的,直接报错。
5. 如何禁止重排序? Java 提供了 volatile 关键字。
-
它的底层原理是插入了 内存屏障 (Memory Barrier)。
-
屏障就像一堵墙,告诉编译器和 CPU:‘这行代码上面的指令不准跑到下面去,下面的也不准跑到上面来’,从而保证了有序性。”
22.volatile可以保证线程安全吗?
举个经典例子:i++ 假设有一个 volatile int count = 0;。 当执行 count++ 时,在底层其实分为三步:
-
读: 从主内存读取 count (0)。
-
改: 在 CPU 寄存器里加 1 (变成 1)。
-
写: 把 1 写回主内存。
并发场景下:
-
线程 A 读取了 0,还没来得及加。
-
线程 B 同时也读取了 0(因为 A 还没写回,所以 B 读到的也是 0)。
-
线程 A 加完写回 1。 (两者都是在CPU寄存器中完成,而不用读主内存)
-
线程 B 加完也写回 1。
-
结果: 两个线程各加了一次,理论上应该是 2,实际上主内存里是 1。数据丢失了。
是的,必须要在 B 还没有把数据“装进口袋”(寄存器)之前,A 的写回才对 B 有效。 如果 B 已经开始算了,那就太晚了。
volatile 的作用范围:仅限于“读”的那一刻。它不负责监视后续的计算过程。
23.volatile和synchronized比较?
| 维度 | volatile | synchronized |
|---|---|---|
| 修饰目标 | 变量 | 方法、代码块 |
| 原子性 | ❌ 不保证 | ✅ 保证 |
| 可见性 | ✅ 保证 | ✅ 保证 |
| 有序性 | ✅ 保证 (禁止重排) | ✅ 保证 |
| 是否阻塞 | ❌ 非阻塞 | ✅ 阻塞 |
| 开销 | 很小 | 较大 (有上下文切换) |
24.什么是公平锁和非公平锁?
| 特性 | 公平锁 | 非公平锁 |
|---|---|---|
| 抢锁策略 | 严格排队 (FIFO) | 尝试插队,失败再排队 |
| 吞吐量 | 低 | 高 (减少了唤醒开销) |
| 饥饿问题 | 无 | 有 (可能饿死老线程) |
| 默认情况 | 无 | ReentrantLock 默认 / synchronized |
25.非公平锁吞吐量为什么比公平锁大?
总结 非公平锁相当于在‘唤醒排队者’的漫长过程中,插进去了一个动作极快的线程。 这样在相同的时间内,非公平锁多处理了一个任务,所以吞吐量更大,但代价是队列里的线程可能会饥饿。”
26.Synchronized是公平锁吗?
27.ReentrantLock是怎么实现公平锁的?
ReentrantLock 实现公平锁的核心,在于它在尝试获取锁(tryAcquire)时,增加了一个排队检查的逻辑。
核心判断逻辑 在公平锁的 tryAcquire 方法中,即使发现当前锁的状态是空闲的(state == 0),它也不会直接去抢锁(CAS)。 它会多做一个判断:调用 hasQueuedPredecessors() 方法。
-
含义: 这个方法就是问 AQS 队列:‘我看锁是空的,但我前面还有人在排队吗?’
-
结果:
-
如果有人在排队:那我不能插队,我也乖乖去队尾排队。
-
如果没人排队(或者我是队头):那我才可以尝试用 CAS 去抢锁。
-
28.什么情况会产生死锁问题?如何解决?
| 必要条件 | 描述 | 破解之道 |
|---|---|---|
| 互斥 | 资源独占 | 改用无锁/读写锁 (难完全避免) |
| 请求与保持 | 占着茅坑不拉屎 | 一次性申请所有资源 |
| 不剥夺 | 没人能抢我的锁 | 使用 tryLock 主动释放 |
| 循环等待 | A等B,B等A | 按固定顺序加锁 (最推荐) |