brew services list
brew services stop mysql 关闭mysql服务
安装时./mysql_secure_installation打开这个文件夹设置密码
- docker 安装mysqlLinux 系统安装
sudo docker pull mysql:8.4sudo docker run -d \
--name mysql8 \
-e MYSQL_ROOT_PASSWORD=你的强密码 \
-p 3306:3306 \
-v mysql_data:/var/lib/mysql \
mysql:8.4一.客户端链接
mysql -u root -p密码为强密码- mysql 自带客户端命令行
- 连接远程数据库
mysql -hIP地址 -P端口号 -uroot -p
启动进入
在docker内启动mysql后,有两种启动方式
-
不安装宿主机客户端,直接进容器登录
sudo docker exec -it mysql8 mysql -uroot -p -
在宿主机安装 MySQL 客户端后登录
sudo apt install mysql-client-core-8.0mysql -h 127.0.0.1 -P 3306 -uroot -p
这里必须带:
-h 127.0.0.1
否则 mysql 客户端可能会尝试走本地 Unix socket,而不是连接 Docker 映射出来的 TCP 端口。
二.SQL分类
- DDL (definition) 数据 定义** 语言
- DML *(manipulate) 数据==操作==语言
- DQL *(query) 数据==查询==语言
- DCL *(control) 数据==控制==语言 (不重要)
https://www.runoob.com/mysql/mysql-create-tables.html
2.1 DDL
2.1.1 数据库操作
- 使用
use 数据库名称 - 增:
create database [if not exists] 数据库名 - 删:
drop database [if exists] 数据库名 - 查:
show databases 或 select database()
2.1.2 表操作
- 增:
create table emp(
id int comment '姓名' ,
workon varchar(10) comment '工号',
-- 变长字符串
name varchar(10) comment '姓名',
gender char(1) comment '性别',
age tinyint unsigned comment '年龄',
idcard char(18) comment '身份证号',
entrydata date comment '入职时间'
) comment '员工表';- 删:
删除字段: alter table 表名 drop 字段名;
删除表: drop table [if exists] 表名;
删除指定表:truncate table 表名;
- 改
修改表名:alter table 表名 rename to 新表名;
添加字段名和类型:
alter table 表名 add 字段名 类型(长度)[comment 注释];
alter table emp add nickname varchar(20) comment '昵称';
修改数据类型:
alter table 表名 modify 字段名 新数据类型;
修改字段名和字段类型
alter table 表名 change 旧字段名 新字段名 类型 [comment 注释];
alter table emp change nickname username varchar(30) comment '用户名';- 查
show tables;--查询当前数据库的所有表
desc 表名; --查询表结构
show create table 表名; -- 查询建表语句
2.2 DML
- 给指定字段==添加==数据 insert---values
insert into 表名(字段1,字段2,。。。) values(值1,值2,。。。);
--
insert into employee(id, workon, name, gender, age, idcard, entrydata) values (1,'1','itcast','男',10,'13042920020828030','2002-08-28');
- 给全部字段==添加==数据
insert into 表名 (值1,值2,。。。);
--
insert into employee value (3,'2','李梦圆','女',18,'13042920021000332','2002-10-05'),(4,'2','段鑫','男',18,'13042920021000332','2002-10-05');- ==修改==字段数据 update---set
update 表名 字段1=值1,字段2=值2,。。。[where 条件];
--
update employee set idcard = '130429200208280333',name = '向晚' where idcard = '3042920020828030';
update employee set id = 2 where name = '小赵';update employee set name = 'ithema' where id = 1;
-- 把所有id 为1的员工名字变为小赵性别变为女
update employee set name = '小赵',gender = '女' where id = 1;
-- 将所有员工更改入职时间
update employee set entrydata = '2008-8-28';- ==删除==数据 delete---from
delete from 表名 [where 条件];
-- 删除id 为2 的员工
delete from employee where id = 2;
-- 删除所有员工
delete from employee ;2.3 DQL
2.3.1 基础查询
- 查询指定字段
select 字段1,字段2,。。。from 表名 - 查询全部字段
select * from 表名 - 设置别名
select 字段1 [as 别名1],。。。from 表名 - 去除重复记录
select distinct 字段列表 from表名
2.3.2 条件查询
-- 条件查询
-- 1.查询年领等于24的员工 (!=
select * from emp where age = 24;
-- 2.查询年龄小于20的员工信息
select * from emp where age < 20;
-- 3.查询没有身份证信息的员工 (is not
select * from emp where idcard is null;
-- 4.查询年龄在15-20岁之间的员工(包括)
select * from emp where age >= 15 && age <=20;
select * from emp where age >= 15 and age <=20;
select * from emp where age between 15 and 20;
-- 5.查询性别为女且年龄小于22的员工
select * from emp where gender = '女' and age <= 22;
-- 6.查询年龄等于18或20或27的员工
select * from emp where age = 18 or age = 10 or age = 27;
select * from emp where age in (18,10,27);
-- 7.查询姓名为两个字的员工信息
select * from emp where name like '___';
-- 8.查询地址为京的员工信息
select * from emp where workaddress like '%京';
2.3.3 聚合函数
-- 1.统计该企业的员工数量
select count(*) from emp;
-- 2.统计该企业的平均年龄
select avg(age) from emp;
-- 3.统计该企业员工的最大年龄
select max(age) from emp;
-- 4.求北京地区的员工年龄之和
select sum(age) from emp where workaddress = '北京';
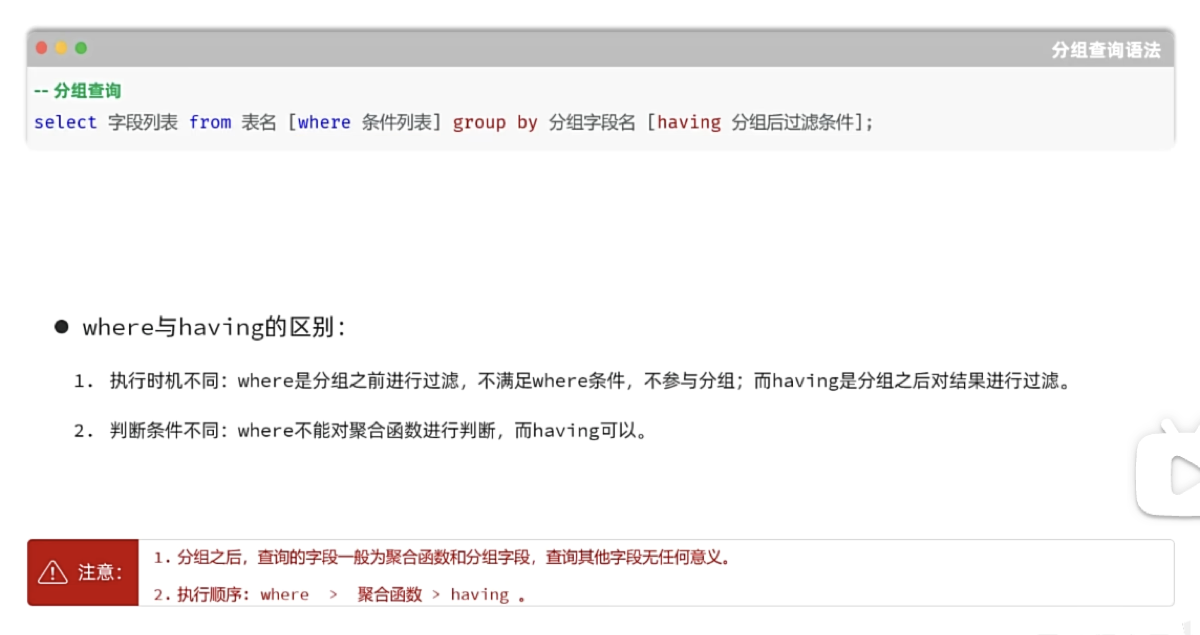
2.3.4 分组查询
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件]
-- 根据性别分组,统计男性员工和女性员工的数量
select gender,count(*) from emp group by gender;
-- 根据性别分组,统计男性员工和女性员工的平均年龄
select gender,avg(age) from emp group by gender;
-- 查询年龄大于18岁的员工,并根据工作地址分组,获取员工数量大于等于2的工作地址
select workaddress, count(*) from emp where age > 18 group by workaddress having count(*) >=2;
2.3.5 排序查询
-- 1.根据年龄对公司员工升降序
select * from emp order by age asc;
select * from emp order by age desc;
-- 2.根据年龄对公司员工升序排序,年龄相同,再根据入职时间进行降序排序
select * from emp order by age asc, entrydata desc;2.3.6 综合(分页查询)
select * from emp where gender = '男' and age<=40 and age >= 20 and name like '___';
select gender,count(*) from emp where age <= 25 group by gender;
select name , age from emp where age <= 23 order by age asc ,entrydata desc;
select * from emp where gender = '男' and age between 19 and 24 order by age asc,entrydata asc limit 5;2.4 DLC
select user();
---查看当前用户
select current_user();
--=MySQL 实际认证时使用的账号
select user, host from mysql.user;
--创建用户
create user 'test1'@'localhost' identified by '123456';
--给权限,权限列表有select ,updata等
-- `select`
-- `insert`
-- `update`
-- `delete`
-- `all privileges`
grant select on *.* to 'test1'@'localhost';
revoke select on *.* from 'testuser'@'localhost';
grant select,insert on test01.emp to 'testuser'@'localhost';
show grants for 'testuser'@'localhost';- 查询权限
show grants for '用户名'@'host主机名' - 授予权限
grant 权限列表 on 数据库名.表名 to '用户名'@'主机名' - 撤销权限
revoke 权限列表 on 数据库名.表名from ‘用户名’@‘主机名’
三.函数
3.1 字符串函数
- concat , lower , upper , lpad , rpad , trim , substring
3.2 数值函数
- ceil , floor , mod , rand , round
3.3 日期函数
- cardate , curtime , now , mounth , day , date_add , datediff
3.4 流程函数
- if , if null , case […] when …then … else ..end
3.5 实例
--
select upper("Hello");
--
select lower('Hello');
--
select concat('Hello','MySQL');
--左填充,长度,用什么填充
select lpad('01',5,'-');
--去掉首位空格
select trim(' Hello mySQL ');
--
select substring('Hello mySQL',1,5);
--向上取整
select ceil(1.1);
--向下取整
select floor('1.9');
--
select mod(3,4);
select mod(8,4);
--
select rand();
--取小数点后x位
select round(2.345,2);
--模糊匹配
like '%dd'
--
select curdate();
--
select curtime();
--
select now();
--
select year(now());
select month(now());
select day(now());
--
select date_add(now(),interval 70 day );
--
select datediff(now(),'2024-8-28');
--if(条件, 条件为真时返回什么, 条件为假时返回什么)
select if(false,'ok','error');
select ifnull(' ','Default');
select ifnull(null,'Default');
-- 将员工编号不足五位的填零补齐
update emp set workon = lpad(workon,5,'0');
-- 生成六位随机验证码
select lpad(round(rand()*1000000,0),6,'0');
-- 查询所有员工入职天数,并根据入职时间天数倒数排序
select name,datediff(curdate(),entrydata) as 'entrydays' from emp order by entrydays desc;
-- 查询emp表的员工姓名和工作地址(北京上海-》一线城市,其他二线城市)
select
name,
(case workaddress when '上海' then '一线城市' when '北京' then '一线城市' else '二线城市' end) as '工作地址'
from emp;
--修复表中的名字
select user_id,concat(upper(substring(name,1,1)),lower(substring(name,2)))
as name
from Users
order by user_id;
--筛选糖尿病人
select * from patients where conditions like 'DIAB1%' or conditions like '% DIAB1%';四.约束
4.1主键约束
- primary key aouto_incremet
4.2非空约束
- not null
4.3 唯一约束
- unique cheak
4.4 默认约束
- default ’_‘
create table user
(
id int primary key auto_increment comment '主键', -- 主键约束
name varchar(10) not null unique comment '姓名', -- 非空约束,唯一约束
age int check ( age>0 and age<=120 ) comment '年龄',
status char(1) default '1' comment '状态',
gender char(1) comment '性别'
)comment '用户表';
4.5 外键(数据连接)增删
- 增
alter table 表名 add constraint 外键名称 foreign key (外键字段名) reference 主表 (主表别名)
-- 添加外键:emp——deptid——>dept(id)
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id);
- 删
alter table 表名 drop foreign key 外键名称
-- 删除外键
alter table emp drop foreign key fk_emp_dept_id;
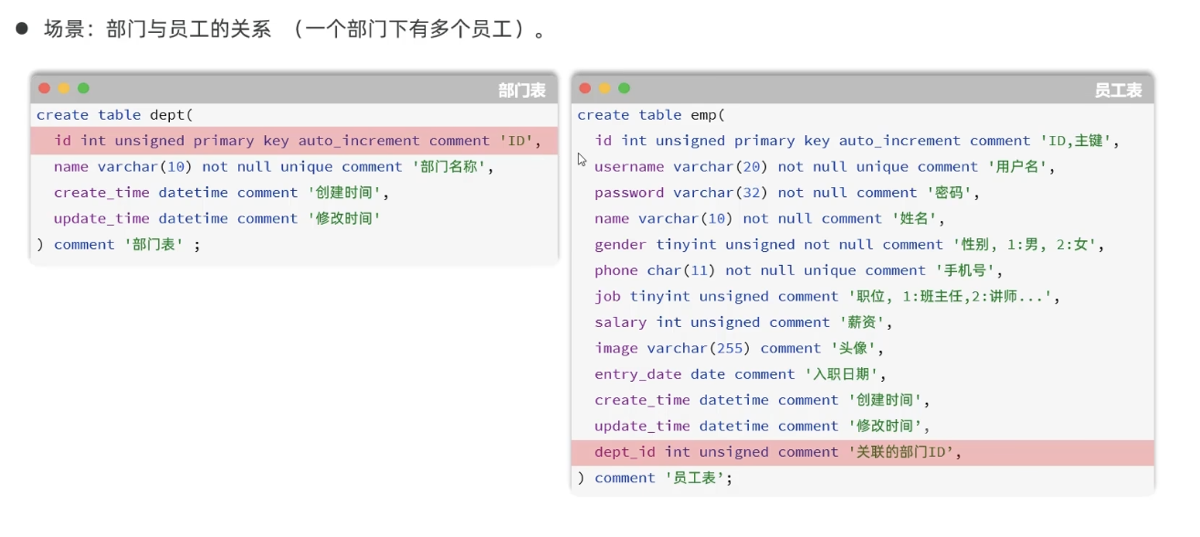
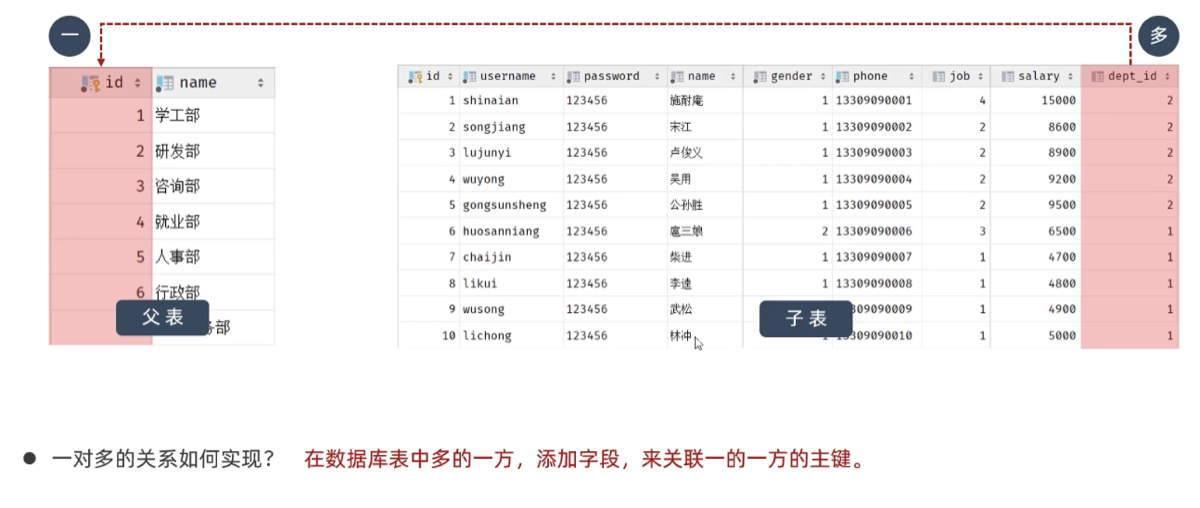
五. 多表查询
5.1 多表关系
-
一对多
-
一对一
-
多对多
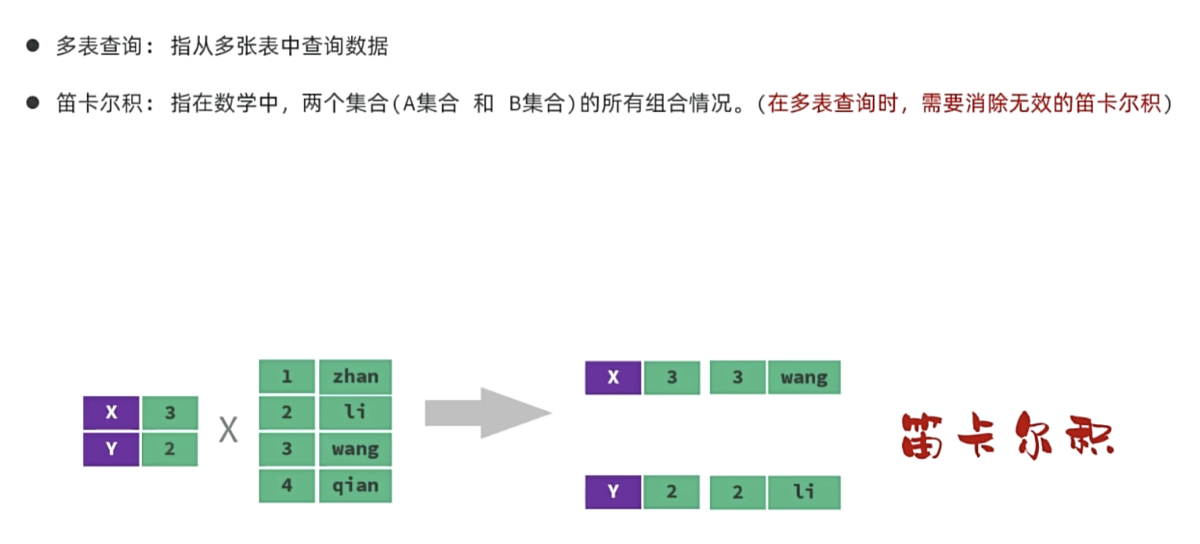
5.2 多表查询
- 笛卡尔积
5.3 内连接(交集)
- 隐式内连接(常用)
SELECT 字段列表 FROM 表1 , 表2 WHERE 条件 ... ;- 显式内连接
SELECT 字段列表 FROM 表1 [INNER] JOIN 表2 ON 连接条件 ... ;表的别名: ①. tablea as 别名1 , tableb as 别名2 ; ②. tablea 别名1 , tableb 别名2 ;
-- ============================= 内连接 ==========================-- A. 查询所有员工的ID, 姓名 , 及所属的部门名称 (隐式、显式内连接实现)
-- 隐式内连接
select emp.id, emp.name,dept.name from emp, dept where emp.dept_id =dept.id and emp.gender = 1 and emp.salary >8000;
-- 显式内连接(inner可省略)
select emp.id ,emp.name,dept.name from emp inner join dept on emp.dept_id = dept.id;
select emp.id ,emp.name,dept.name from emp join dept on emp.dept_id = dept.id;5.4 外连接
SELECT 字段列表 FROM 表1 LEFT [ OUTER ] JOIN 表2 ON 条件 ... ;5.5 自连接
- 自连接查询
SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件 ... ;
---查询所有员工 emp 及其领导的名字 emp , 如果员工没有领导, 也需要查询出来
select a.name '员工', b.name '领导' from emp a left join emp b on a.managerid = b.id;
--注意事项: 在自连接查询中,必须要为表起别名,要不然我们不清楚所指定的条件、返回的字段,到底 是哪一张表的字段。- 联合查询
SELECT 字段列表 FROM 表A ...
UNION[ ALL ]
SELECT 字段列表 FROM 表B ....;5.6 子查询
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 );5.6.1 标量查询
--查询在 "方东白" 入职之后的员工信息
select * from emp where entrydate > (select entrydate from emp where name = '方东 白');5.6.2 列子查询
--查询 "销售部" 和 "市场部" 的所有员工信息
select * from emp where dept_id in (select id from dept where name = '销售部' or name = '市场部');
--查询比 财务部 所有人工资都高的员工信息
select * from emp where salary > all ( select salary from emp where dept_id = (select id from dept where name = '财务部') );5.6.3 行子查询
--查询与 "张无忌" 的薪资及直属领导相同的员工信息 ;
select * from emp where (salary,managerid) = (select salary, managerid from emp where name = '张无忌');5.6.4 表子查询(自查询里面是一张小表)
--查询与 "鹿杖客" , "宋远桥" 的职位和薪资相同的员工信息
select * from emp where (job,salary) in ( select job, salary from emp where name = '鹿杖客' or name = '宋远桥' )
--查询入职日期是 "2006-01-01" 之后的员工信息 , 及其部门信息
select e.*, d.* from (select * from emp where entrydate > '2006-01-01') e left join dept d on e.dept_id = d.id ;六.事务
6.1 事务操作
-
查看/设置事务提交方式
- SELECT @@autocommit ;
- SET @@autocommit = 0
- begin
-
提交事务
- commit
-
回滚事务
- rollback
6.2 四大特性
- 原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
- 隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立 环境下运行。
- 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。 上述就是事务的四大特性,简称ACID。
6.3 并发事务问题
1). 查看事务隔离级别
SELECT @@TRANSACTION_ISOLATION;2). 设置事务隔离级别
SET [ SESSION | GLOBAL ] TRANSACTION ISOLATION LEVEL { READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE }进阶
一 引擎
-
InnoDB
-
MyISAM
-
Memory 内存存放
二 索引
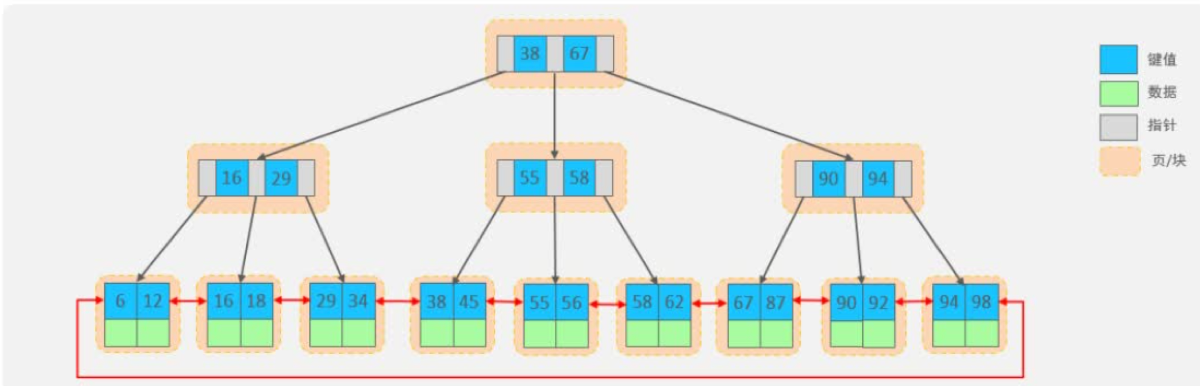
2 索引结构
B+Tree
 hash
空间索引
全文索引
hash
空间索引
全文索引
3 索引分类
主键索引 - primary 唯一索引 - unique 常规索引 全文索引 - fulltext
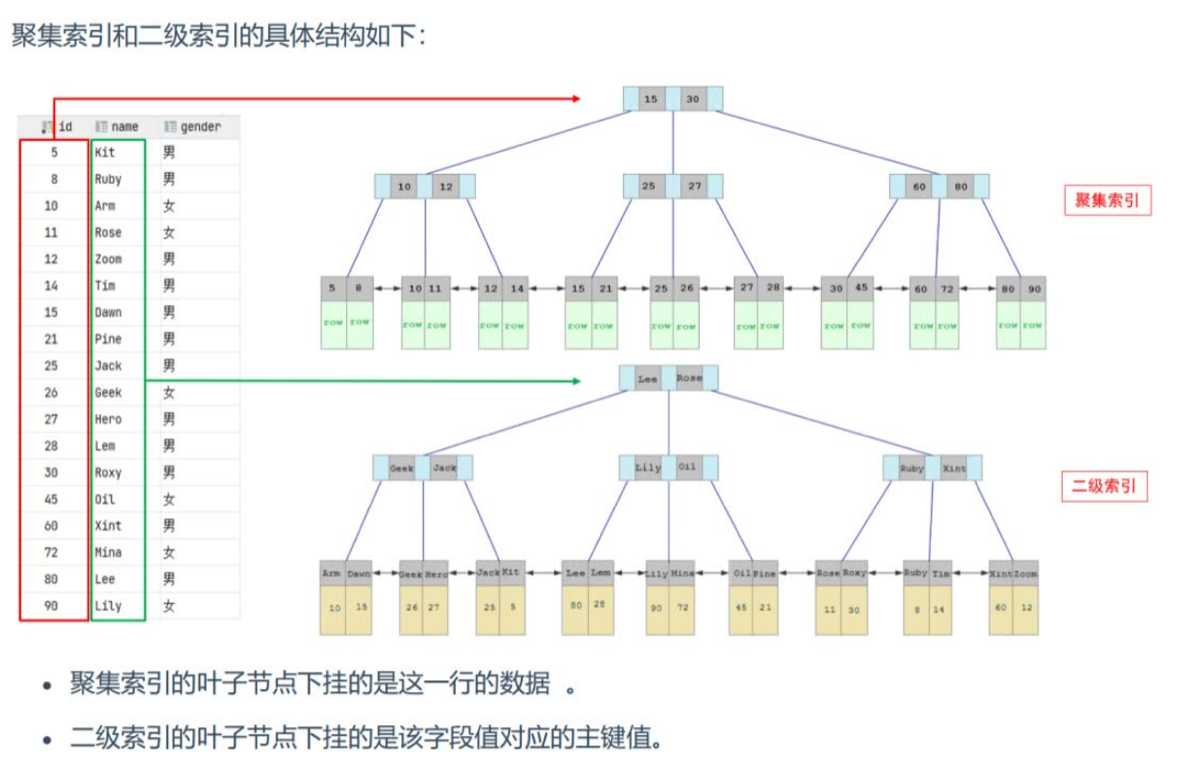
- InnoDB存储引擎:聚集索引(必须有且只有一个), 二级索引
- 聚集索引规则:
- 主键-》unique-》自动生成rowid作为隐藏的聚集索引
4 索引语法
创建索引
create [unique|fulltext] index index_name on table_name (idex_col_name,...)
- 查找索引
show index from table_name; - 删除索引
drop index index_name on table_name;
5 SQL性能分析
show global status like 'Com_______';
5.1 慢查询日志
show variables like 'slow_query_log';
5.2 profile详情
- 查看是否有
select @@have_profiling; - 查看是否开关
select @@profiling; - 开
set profiling=1; - 查看每一条sql的耗时基本情况
show profiles; - 查看sql时间花费哪里
show profile for query (id);
5.3 explain执行计划
mysql> explain select * from tb_user where id =3;

- id:select查询的序列号,select子句或操作表的顺序(id大,优先级高
- select_type:查询的类型
- type:连接类型 性能好到差排序为NULL, system, const, eq_ref, ref, range, index all
- possible_key:显示可能应用到这张表的索引一个或多个
- key:实际的数量
- rows:执行查询的行数(预估值
- filtered:表示返回结果的行数占读取行数的百分比,值越大越好
6 索引使用原则
-
最左前缀法则 如果索引了多列(联合索引),查询从索引最左列开始,并且不可以跳过索引的列(跳过部分后会失效)
-
范围查询 联合索引中,出现范围查询(>,<)右侧失效
-
索引列运算 不要在索引列上进行运算操作,索引将失效
explain select * from tb_user where substring(phone,10,2)='15'; -
or连接的条件 如果or前的条件中的列有索引,而后面的列没有索引,那么涉及的索引都不会被用到
-
数据分布影响 如果mysql评估使用索引比全表更慢,则不使用索引
-
SQL提示 在sql语句中加入人为的提示来达到优化操作的目的
use index
explain select * from tb_user use index(idx_user_pro) where profession='软件工程' ==ignore index== explain select * from tb_user ignore index(idx_user_pro) where profession=‘软件工程’
force index
`explain select * from tb_user force index(idx_user_pro) where profession=‘软件工程’
-
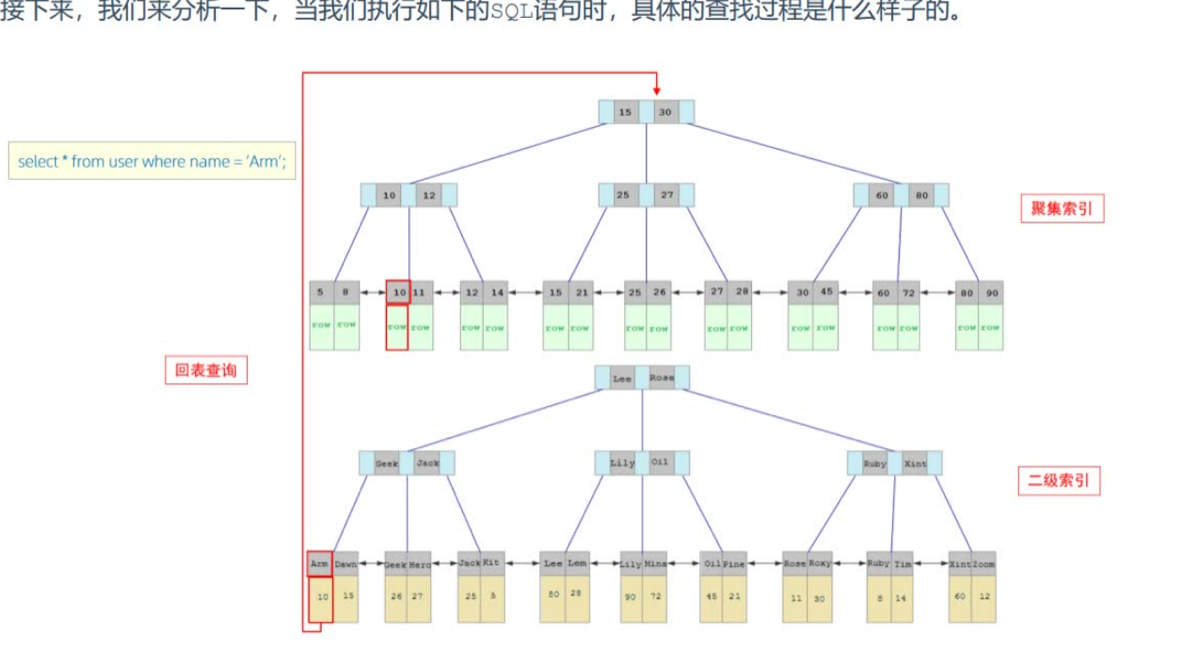
覆盖索引 using index condition:查找使用了索引,但是需要回表查询数据 应尽量不使用
select *以避免回表查询 -
前缀索引 用来解决字段类型为字符串(varchar,text等)会让索引变得很大,此时只将字符串的一部分前缀建立索引 语法
create index idx_xxx on table_name(column(N));前缀长度select count (distinct email)/count(*) from tb_user;select count (distinct substring(email,1,5))/count(*) from tb_user; -
单列索引和联合索引
7 索引设计原则
- 针对与常作为查询条件where 排序order 分组group by 操作的字段建立索引
- 尽量选择区分度高的列作为索引
- 字符串类型的字段,字段长度较长,建立前缀索引(注意区分度
- 尽量选择联合索引,避免回表查询
- 控制索引数量
- 如果索引列不能存储null值,请在创建表时使用not null约束,便于优化器发挥作用
三 SQL优化
- 插入数据
批量插入
insert into tb_test values(1,;tom'),(2,'cat'),...;
手动提交事务
start transaction;
insert...;
insert...;
insert...;
commit;主键顺序插入
...
大批量数据插入
客户端连接服务端时,加上参数 --local-infile
设置全局参数local_infile=1;
`set global local_file=1;`
执行load指令将准备好的数据加载到表结构中
`load data local infile '/home/duanx/load_user_100w_sort.sql' into table tb_user fields terminated by ',' lines terminated by '\n';`
- 主键优化
- 页分裂
- 页合并
- 主键设计原则
- 尽量降低主键长度
- 插入数据时,尽量选择顺序插入,选择使用auto_increment自增主键
- 尽量不要使用UUID做主键或其他自然主键
- 业务操作时,避免对主键的修改
-
Order by优化 创建一个降序一个升序的索引
create index idx_user_age_pho_ad on tb_user(age asc,phone desc); -
group by优化
create index idx_user_pro_age_sta on tb_user(profession,age,status); -
limit优化 下列情况需要mysql排序前2000010记录,仅返回200000-2000010的记录,其他及记录丢弃,查询排序的代价非常大
优化思路:一般分页查询时,通过创建覆盖索引能够更好的提高性能,可以通过覆盖索引加子查询形式进行优化
explain select * from tb_sku t , (select id from tb_sku order by id limit 2000000,10) a where t.id = a.id;
-
count优化 优化思路:自己计数
-
update优化 InnoDB的行锁时针对索引加的锁,不是针对记录加的锁,并且该索引不能失效 否则会从行锁变为表锁
四 视图
- 语法
-- 创建视图
create or replace view user_v_1 as select id,name from tb_user where id <=10;
-- 查询视图
show create view user_v_1;
select * from user_v_1;
-- 修改视图
create or replace view user_v_1 as select id,name,age from tb_user where id <=10;
alter view user_v_1 as select id ,name from tb_user where id<=10;
-- 删除视图
drop view if exists user_v_1;- 检查选项
---with cascaded check option;(local不会把检查选项向上传递)
检查插入时是否与创建时符合视图定义
- 更新及作用
包含一对多关系的视图不会更新; 简化操作,安全,数据独立
五 存储过程
- SQL语言层面的代码封装与重用
-- 创建过程
-- 创建
create procedure p1()
begin
select count(*) from tb_user;
end;
-- 调用
call p1();
-- 查看
select * from information_schema.ROUTINES where ROUTINE_SCHEMA = 'itcast';
show create procedure p1;
-- 删除
drop procedure if exists p1;注意:在命令行中,执行创建存储过程中的SQL时,需要通过关键字delimiter指定SQL的结束符
- 系统变量
-- 变量:系统变量
-- 查看系统变量
show session variables;
show session variables like 'auto%';
show global variables like 'auto%';
select @@global.autocommit;
select @@session.autocommit;
-- 设置系统变量
set session autocommit = 0;- 用户变量
-- 变量:用户变量
-- 赋值
set @myname ='itcast';
set @myage :=10;
-- 使用
select @myname;==注意:用户定义的变量无需对其进行声明或初始化,默认NULL值
- 局部变量
-- 变量:局部变量
-- 声明 - declare-- 赋值
create procedure p2()
begin
declare user_count int default 0;
select count(*) into user_count from tb_user;
select user_count;
end;
-- 调用
call p2();-- 根据定义的分数判断优秀是否
create procedure p3()
begin
declare score int default 97;
declare result varchar(10);
if score >=90 then
set result := '顶级';
elseif result >=60 then
set result := '及格';
else
set result := '不及格';
end if;
select result;
end;
call p3();- 各类语法
-- in/out/inout参数
create procedure p4(in score int,out result varchar(10))
begin
if score >=90 then
set result := '顶级';
elseif score >=60 then
set result := '及格';
else
set result := '不及格';
end if;
end;
call p4(97,@result);
select @result;case
while do
repeat
...
until 条件
end repeat;[begin_label:]loop
...
end loop;leave label --退出指定标记的循环体
iterate label --直接进入下一次循环- 游标
-- 游标
-- 声明游标
declare 游标名称 cursor for 查询语句;
-- 打开游标
open 游标名称;
-- 获取游标记录
fetch 游标名称 into 变量[变量];
-- 关闭游标
close 游标名称;- 条件处理程序
六 存储函数
七 触发器
-- 触发器
create table user_logs(
id int(11) not null auto_increment,
operation varchar(20) not null comment '操作类型, insert/update/delete',
operate_time datetime not null comment '操作时间',
operate_id int(11) not null comment '操作的ID',
operate_params varchar(500) comment '操作参数',
primary key(`id`)
)engine=innodb default charset=utf8;
-- 插入数据触发器
create trigger tb_user_insert_trigger
after insert on tb_user for each row
begin
insert into user_logs(id, operation, operate_time, operate_id, operate_params) values
(null,'insert',now(),new.id,concat('插入数据的内容为:id=',new.id));
end;
-- 查看
show triggers;
-- 删除
drop trigger tb_user_insert_trigger;
-- 测试
insert into tb_user(id, name, phone, email, profession, age, gender, status, createtime)
VALUES (25,'二皇子','18809091212','erhuangzi@163.com','软件工程',23,'1','1',now());八 锁
全局锁
数据逻辑备份时使用
mysql端:
flush tables with read lock;
命令行端:
mysqldump -h 192.168.200.202 -uroot -pAa20020828... db01 > D:db01.sql
mysql端:
unlock tables;
在InnodDB引擎中,在备份时加入参数--single-transaction来完成不加锁的一致性数据备份
mysqldump -h 192.168.200.202 -uroot -pAa20020828... db01 > D:db01.sql
表级锁
- 表锁
- 表共享读锁
lock tables 表名 read; - 表独占写锁
lock tables 表名 write;
- 表共享读锁
释放锁:unlock tables;
-
元数据锁 为了避免DML与DDL冲突,保持读写的正确性
-
意向锁 IS IX 规避行锁和表锁的冲突问题
行级锁
-
行锁
- 共享锁(S):允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁
- 排他锁(X):允许获取排他锁的事务更新数据,阻止其他事务获得相同数据集的共享锁和排他锁
-
间隙锁/临键锁
九 InnoDB引擎
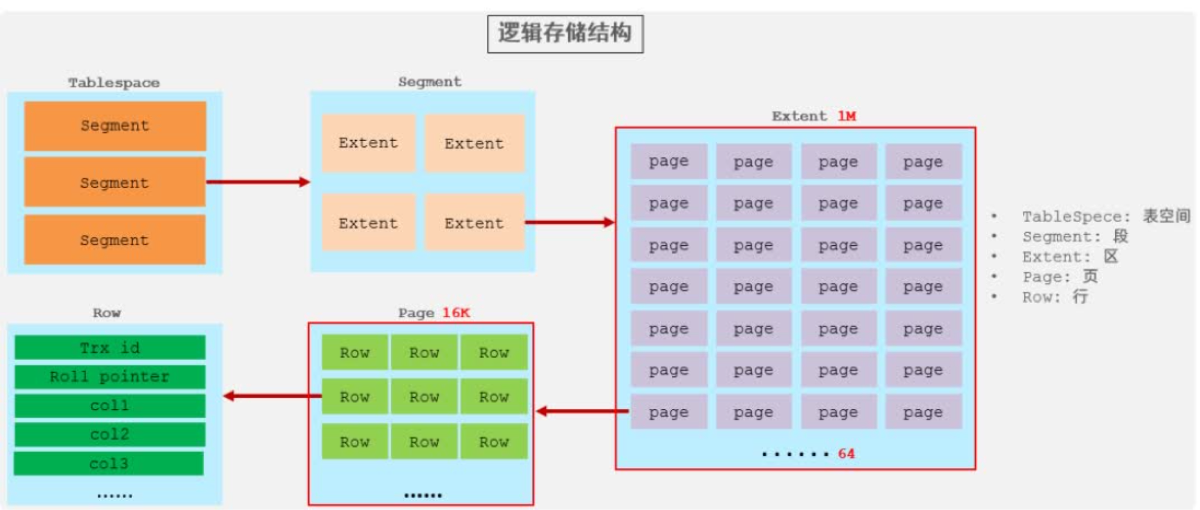
1.逻辑存储结构
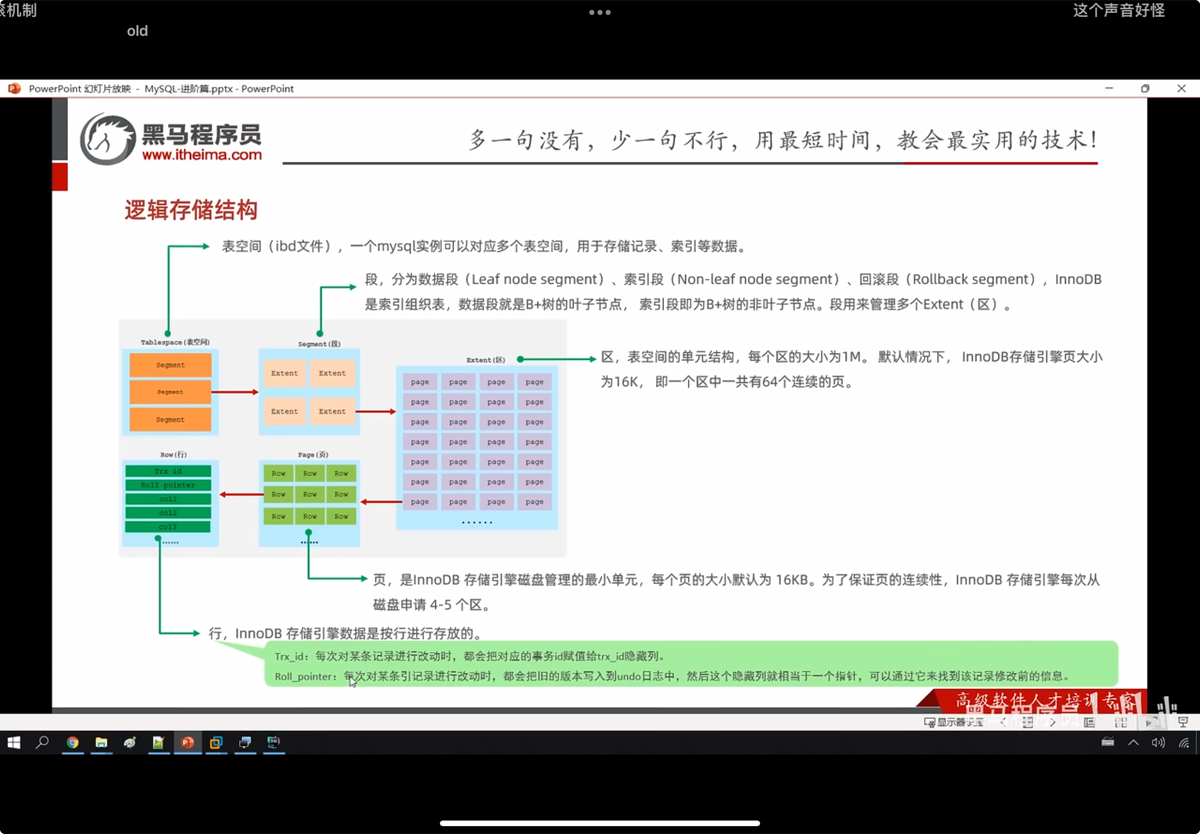
2.内存架构
3.磁盘结构
4.后台线程
5.事务原理
-
redo log 重做日志:实现持久性 记录物理日志
-
undo log 回滚日志:实现原子性 记录逻辑日志
- Undo log销毁:在事务执行时产生,事务提交时,并不会咯及删除,可能这些日志还用于MVCC
- Undo log存储:采用段的方式进行管理和记录,存放在前面介绍的rollback segment回滚中,内部包含1024个rollback segment
两者共同实现一致性
6.MVCC
- 当前读
- 快照读
- MVCC (Multi-Version Concurrency Control)多版本并发控制
- 指维护一个数据的多个版本,使得读写操作没有冲突,快照读为MySQL实现MVCC提供一个非阻塞功能。MVCC的具体实现还需依赖数据库中的三个隐式字段,undo log日志,redeView。
与锁共同实现隔离性
- 实现原理
- 查看隐藏字段
ibd2sdi tb_user.ibd - undo log 不同事务或相同事务对同一条记录进行修改,会导致该记录的undo log生成一条记录版本链表,链表的头部是最新的旧纪录,尾部是最早的旧记录
- readview 版本链数据访问规则 不同的隔离级别,生成的ReadView的时机不同 READ COMMITTIED:在事务中每一次执行快照读时生成ReadView REPEATABLE READ:仅在事务中的第一次执行快照时生成ReadView,后续复用
十 常用工具
- msql Mysql客户端工具,-e执行SQL并退出
- mysqladmin Mysql管理工具
- mysqlbinlog 二进制日志查看工具
- mysqlshow 查看数据库,表,字段的统计信息
- mysqldump 数据备份工具
- nysqlimport/source 数据导入工具