1.NoSQL与SQL区别
- 一个关系型,一个非关系型MongoDB,Redis
- 关系型数据库存储结构化数据。这些数据逻辑上以行列二维表的形式存在,每一列代表数据的一种属性,每一行代表一个数据实体。
- 而非关系型,一般为json,哈希
怎么选呢
需不需要ACID 原子性一致性隔离性持久性,比如银行需要,社交软件就不需要
可扩展性 比如redis,主从复制哨兵模式切片集群,但关系型数据之间有关联,需要解决跨服务器,分布式事务等问题
2.三大范式是什么
第一范式(1NF):要求数据库表的每一列都是不可分割的原子数据项
反面教材: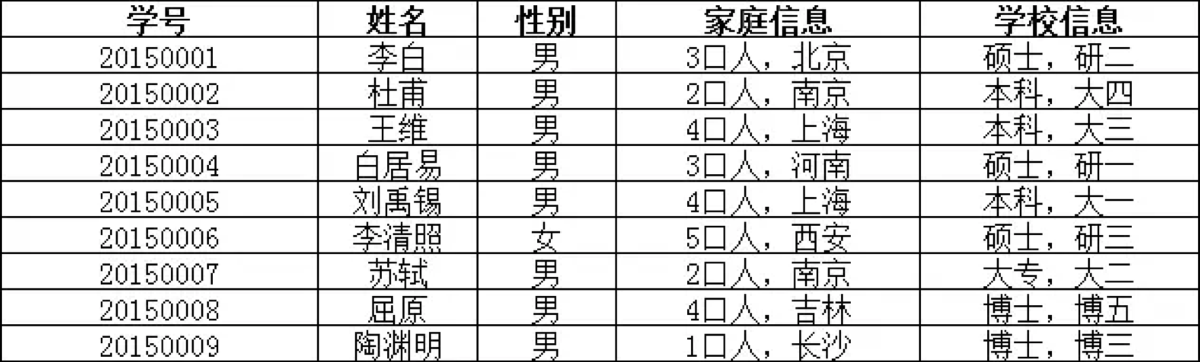
第二范式(2NF):非主键字段必须完全依赖于主键,而不是依赖主键的一部分。 👉 通俗理解: 如果主键是由两列组成(联合主键), 那其他字段必须依赖“这两列一起”,不能只依赖其中一个。 比如:主键不能是(订单号 + 产品号)
第三范式(3NF):非主键字段不能依赖于其他非主键字段(消除传递依赖)。
反面教材: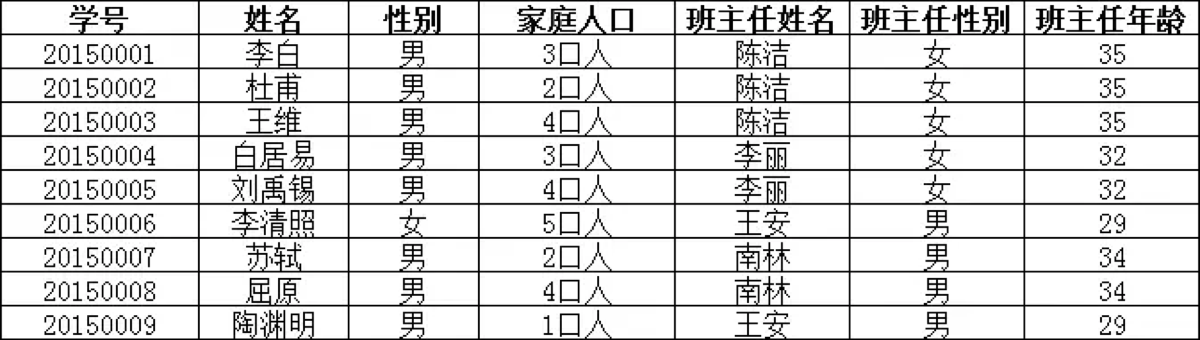
3.MySQL怎么连表查询
- 内,全外,左外,右外
- 5.3 内连接(交集)
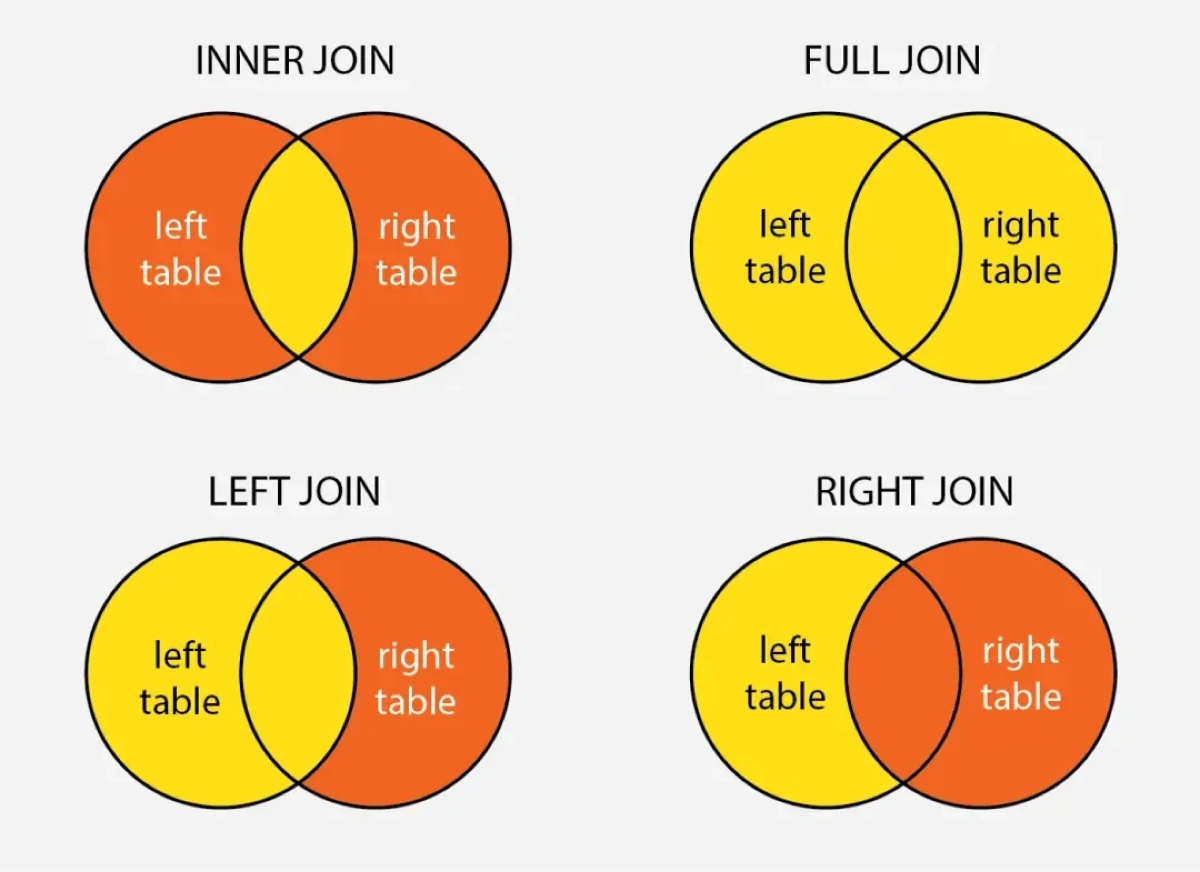
MySQL不支持全外连接,使用union解决
4. MySQL如何避免重复插入数据?
如果需要保证全局唯一性,使用UNIQUE约束是最佳做法。
如果需要插入和更新结合可以使用ON DUPLICATE KEY UPDATE。
对于快速忽略重复插入,INSERT IGNORE是合适的选择
5.char和varchar有什么区别
- 固定的长度的字符串类型,定义时就必须指明,未占满就用空格占满,对固定的短字符更佳
- 边唱的字符串类型,适合不确定的情况,比如用户的备注,输入的文本,但刚开始也须指明最大长度
6.VARCHAR(n) 中的数字代表什么?
VARCHAR(n)中的 n 表示“最大字符数”,不是字节数。 也就是说:
-
它限制的是你能存多少个“字符(Character)”,
-
而不是多少个“字节(Byte)”。
-
ASCII字符集:一个字符=一个字节‘
-
UTF-8:一个字符1~4个字节(中文和emoji多)
7.INT(1) 和 INT(10) 在 MySQL 里到底有什么区别?
存的数据大小完全一样,区别只在于‘显示宽度’
有ZEROFILL属性时才有用,用于显示多少位,少了用0补
8.TEXT可以无限大吗
text:64kb mediumtext:16Mb longtext:4Gb
9.IP地址如何在数据库里存储?
- 32位二进制数,点分十进制127.1.1.1
- 字符串,易懂方便,但性能差,不能范围查询
- 整数类型:转换为32位无符号整数存储,增加难度
易懂方便,但性能差,不能范围查询
10.讲一下外键约束
维护表与表的关系,确保数据完成性和一致性,比如建立一个课程id,课程表外键约束学生选课表,以免学生选到一个不存在的课,或者删除一个课程但学生不知道
11.MySQL的关键字in和exist
都是子查询的的关键字
- 只关心左边是否存在与右边的列表或者查询结果中
- 只关心能否返回至少一个结果,(没有左边)
性能上,右边胜,只要找到一个立马返回 使用场景上,子查询结果集小,就in,更直观,否则就exist null值判断上,in会正确处理,但exist只关心能不能找到至少一行结果!!
12.mysql中的一些基本函数,你知道哪些?
- 字符串函数
| 函数 | 作用 | 示例 |
|---|---|---|
CONCAT(str1, str2, …) | 拼接字符串 | CONCAT('Hello', ' ', 'World') → 'Hello World' |
LENGTH(str) | 返回字符串长度 | LENGTH('Hello') → 5 |
SUBSTRING(str, pos, len) | 截取子字符串 | SUBSTRING('HelloWorld', 1, 5) → 'Hello' |
REPLACE(str, from_str, to_str) | 替换字符串中的部分内容 | REPLACE('Hello World', 'World', 'MySQL') → 'Hello MySQL' |
- 数值函数
| 函数 | 作用 | 示例 |
|---|---|---|
ABS(num) | 取绝对值 | ABS(-10) → 10 |
POWER(num, exponent) | 幂运算(num 的 exponent 次方) | POWER(2, 3) → 8 |
- 日期和时间函数
| 函数 | 作用 | 示例 |
|---|---|---|
NOW() | 当前日期+时间 | 2025-11-17 22:00:00 |
CURDATE() | 当前日期(不含时间) | 2025-11-17 |
- 聚合函数 在groupBy最为常见
| 函数 | 作用 | 示例 |
|---|---|---|
COUNT(column) | 统计行数(非 NULL) | COUNT(*) → 总行数 |
SUM(column) | 求和 | SUM(price) → 总价 |
AVG(column) | 平均值 | AVG(score) → 平均分 |
MAX(column) | 最大值 | MAX(age) → 最大年龄 |
MIN(column) | 最小值 | MIN(age) → 最小年龄 |
13.SQL查询语句的执行顺序是怎么样的?
SELECT ...
FROM ...
JOIN ...
WHERE ...
GROUP BY ...
HAVING ...
ORDER BY ...
LIMIT ...
- 执行时以以下为优先级
| 执行步骤 | 关键字 | 作用 |
|---|---|---|
| ① | FROM | 找到要查询的表 |
| ② | ON | 连接条件(用于 JOIN) |
| ③ | JOIN | 联表(产生中间结果) |
| ④ | WHERE | 过滤行数据 |
| ⑤ | GROUP BY | 按字段分组 |
| ⑥ | AGG_FUNC | 执行聚合函数(SUM、AVG、COUNT 等) |
| ⑦ | HAVING | 对分组结果再过滤 |
| ⑧ | SELECT | 选择要输出的列 |
| ⑨ | DISTINCT | 去重 |
| ⑩ | ORDER BY | 排序 |
| ⑪ | LIMIT | 限制返回的行数 |
| 🔁 可以理解成:MySQL 会“先确定数据来源,再逐步过滤、分组、聚合、排序,最后才输出结果” |
📘 “从哪来(FROM)—先筛行(WHERE)—再分组(GROUP)—挑组(HAVING)—选列(SELECT)—排队(ORDER)—限量(LIMIT)”