1.什么是消息队列?
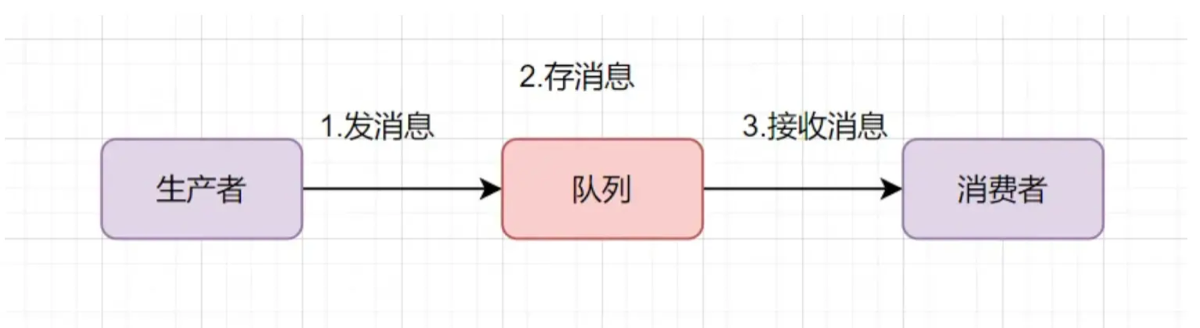 在 MQ 的世界
在 MQ 的世界
-
生产者(Producer):负责创建消息并发送到 MQ。
-
消息队列(Queue/Topic):负责存储消息。
-
消费者(Consumer):负责从 MQ 中获取并处理消息。
| 特性 | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|
| 单机吞吐量 | 万级(较低) | 十万级 | 百万级(极高) |
| 时效性 | 微秒级(极快) | 毫秒级 | 毫秒级 |
| 可靠性 | 高 | 极高(经过双11考验) | 高(有数据丢失风险) |
| 适用场景 | 小型系统、金融级可靠 | 互联网金融、电商 | 大数据量、日志采集 |
2.消息队列怎么选型?
-
数据规模优先:如果是千万/亿级的日志处理,选 Kafka。
-
业务逻辑复杂优先:如果涉及分布式事务、延时触发、精准重试,选 RocketMQ。
-
响应时效与灵活度优先:如果是微服务间的轻量通信,且要求极低延迟,选 RabbitMQ。
-
维护成本:如果公司全是 Java 大牛,选 RocketMQ 会更可控;如果是大数据背景,Kafka 是标配。
3.消息队列使用场景有哪些?
MQ 就像是系统之间的**‘缓冲垫’。在设计高性能系统时,我们通过异步化来换取响应时间**,通过解耦来换取系统灵活性,通过削峰来换取系统的稳定性。不过,引入 MQ 也会带来系统复杂度提升、数据一致性保障难、可用性降低(MQ 挂了怎么办)等副作用,所以在使用时必须做好权衡。”
1. 异步处理(Asynchronous Processing)
这是 MQ 最基础也最直观的使用场景。
-
痛点:传统的同步调用流程(如:注册 → 写入数据库 → 发邮件 → 发短信)。如果每个步骤耗时 50ms,用户需要等待 150ms 才能看到成功,体验很差。
-
MQ 方案:主流程(写入数据库)完成后,立刻发一个消息到 MQ 并给用户返回成功。发邮件和短信的操作由下游服务异步完成。
-
价值:显著缩短接口响应时间,提升用户体验和系统吞吐量。
2. 应用解耦(Decoupling)
解决系统之间强依赖的问题。
-
痛点:以电商“下单”为例。下单成功后,库存系统要扣减、物流系统要排单、营销系统要发券。如果直接调用(RPC),任何一个下游系统挂了,下单都会失败。而且每增加一个新业务(比如:大数据分析),下单系统的代码都要改一遍。
-
MQ 方案:下单系统只管发一个“订单已创建”的消息到 MQ,库存、物流、营销系统各自去订阅这个消息。
-
价值:
-
独立性:下游系统挂了不影响主流程。
-
灵活性:增加或减少下游系统,主流程代码无需任何变动。
-
3. 流量削峰(Peak Shaving)
保护脆弱的后端资源(如数据库)。
-
痛点:在秒杀或促销活动中,瞬时并发量可能达到平时的百倍。如果请求直接打到数据库,数据库会瞬间因为连接数爆满或负载过高而瘫痪。
-
MQ 方案:将海量请求先写入 MQ(MQ 的写入性能远高于数据库)。后端业务根据自己的处理能力,以平滑的速度从 MQ 中拉取请求并处理。
-
价值:起到“蓄水池”的作用,防止后端系统崩溃。这就是常说的“削峰填谷”。
_4.消息重复消费怎么解决?
什么会产生重复消费?
在 MQ 的三大环节中,每一环都可能导致重复:
-
生产者端:消息发给 Broker 成功了,但网络抖动导致生产者没收到确认(ACK),生产者以为失败了,触发重试。
-
Broker 端:消息存好了,但在同步给从节点或给生产者回执时出问题。
-
消费者端(最常见):业务逻辑处理完了,但在给 Broker 回复“消费成功”之前,消费者进程挂了或网络断了。Broker 没收到 ACK,为了保证消息不丢,会把消息再次投递给另一个消费者。
2.状态机可以结合这里理解消息重复消费
场景推演:它是如何拦截重复 MQ 消息的?
假设场景:你的 MQ 发送了一条“支付成功”的消息,但由于网络抖动,MQ 发送了两条一模一样的消息(Message A 和 Message B)。
第一条消息 (Message A) 到达:
-
查询状态:
getCurrentState查到当前数据库状态为待支付(NO_PAY)。 -
定义事件: 消息意图是
支付成功事件。该事件定义要求:源状态必须是待支付。 -
状态校验:
待支付==待支付。校验通过。 -
执行业务: 执行 Handler,更新数据库状态为
已支付(PAYED)。
第二条消息 (Message B - 重复消息) 到达:
-
查询状态:
getCurrentState查到当前数据库状态已经变成了已支付(PAYED)(因为 Message A 已经改完了)。 -
定义事件: 消息意图依然是
支付成功事件。该事件定义要求:源状态必须是待支付。 -
状态校验: 当前是
已支付,但要求是待支付。校验失败! -
结果: 代码抛出
CommonException,流程终止。后续的bean.handler业务逻辑完全不会执行,数据不会被重复修改。
这里的操作是在状态机的 changeStatus 方法中开始校验部分实现
| 方案 | 优点 | 缺点 | 适用场景 | |
|---|---|---|---|---|
| 数据库唯一索引 | 简单、绝对可靠 | 仅限于 Insert 操作 | 增加流水记录、创建订单 | |
| 去重表 | 通用性强,配合事务 | 增加一次磁盘 IO 开销 | 绝大多数核心业务 | |
| Redis SETNX | 性能极高 | 增加系统复杂度,需考虑 TTL | 非核心、高并发场景 | |
| 状态机 | 几乎无额外开销 | 业务耦合度高 | 各种审核、支付状态流转 | # |
_5.消息丢失怎么解决的?
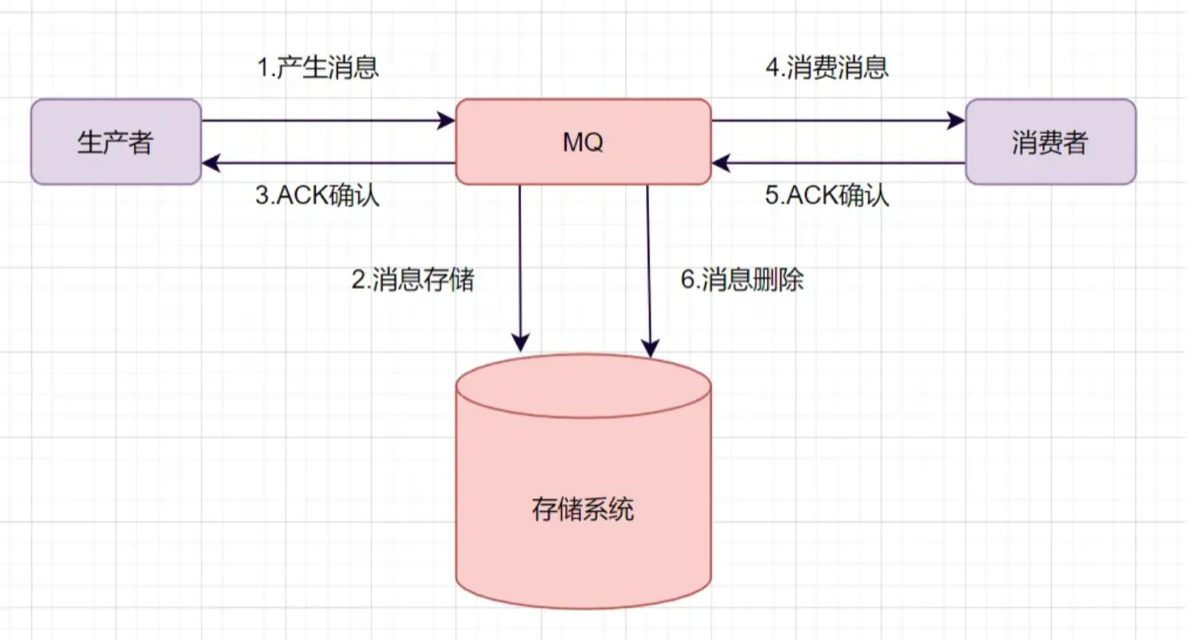
 通常,一条消息的丢失可能发生在以下三个阶段:
通常,一条消息的丢失可能发生在以下三个阶段:
-
生产者发送阶段:消息没到 Broker。
-
Broker 存储阶段:消息到了 Broker 但没存稳,或者 Broker 宕机了。
-
消费者消费阶段:消费者拿到了消息,但没处理完就挂了。
| 阶段 | 潜在风险 | 解决方案 (关键词) |
|---|---|---|
| 生产者 | 网络断了,MQ 没收到 | Publisher Confirm (发布确认) |
| Broker | 宕机、重启、断电 | 持久化 (交换机+队列+消息) + 集群镜像 |
| 消费者 | 还没处理完就挂了 | Manual ACK (手动确认) |
| 全链路 | 极端情况兜底 | 本地消息表 (定时任务补偿)(抽奖系统的 task 表) |
6.使用消息队列还应该注意哪些问题?
消息的可靠性与顺序性
7.消息队列的可靠性、顺序性怎么保证?
如何保证消息的可靠性?
可靠性意味着“不丢消息”。消息的丢失可能发生在三个阶段,我们需要针对每一环进行“加固”:
- 生产者阶段:确保消息到达 Broker
-
机制:发送确认(Confirm/ACK)。
-
做法:
-
RabbitMQ:开启
confirm模式,Broker 收到后回传 ACK。 -
Kafka:设置
acks=all,要求 Leader 和所有 Follower 都存好才算成功。 -
RocketMQ:使用同步发送或事务消息,确保本地逻辑与消息发送的原子性。
-
- Broker 存储阶段:确保消息在磁盘存稳
-
持久化:开启磁盘持久化。
-
同步刷盘:将“异步刷盘”改为“同步刷盘”(即每条消息强制落盘后才回执成功),虽然损耗性能,但最安全。
-
多副本冗余:采用同步复制。即使一台 Broker 磁盘坏了,由于数据已同步到从节点,消息依然存在。
- 消费者阶段:确保业务处理完再删消息
-
机制:手动 ACK。
-
避坑:千万不要开启自动 ACK(Auto-Ack)。只有在业务代码逻辑成功执行、数据库更新完成后,才在代码最后调用
ack。这样如果消费者执行中途挂了,消息会重新回到队列供其他消费者处理。
如何保证消息的顺序性?
在分布式系统中,我们通常不追求全局顺序(代价太大),而是追求局部顺序(如:同一个订单的增、改、删必须有序)。
第一步:生产者路由
-
生产者在发送时,必须将具有相同业务 ID(如订单号)的消息发送到同一个 Partition/Queue 中。
-
Kafka/RocketMQ:通过
Message Key进行 Hash 取模,确保同一个 Key 的数据落在同一个分区。
第二步:Broker 存储
- 消息队列内部本身是 FIFO(先进先出)的,只要进入了同一个分区,它们在 Broker 内部就是有序的。
第三步:消费者单线程处理
-
常规做法:一个 Partition 只能由一个 Consumer 实例处理。
-
进阶优化:如果消费端需要高并发,消费者内部可以使用内存队列。将拿到的消息按 ID 再次分发到内部不同的线程内存队列中,确保“同一个 ID 由同一个线程处理”。
| 阶段 | 核心组件 | 关键操作 (How) | 原理与目的 (Why) | 注意事项 (Warning) |
|---|---|---|---|---|
| 第一步 | 生产者 (Producer) | 定向路由 (Hashing) 发送时指定 Message Key (如 OrderID)。 | 目的: 确保同一笔订单的所有消息(增删改)都被分配到同一个 Partition/Queue 中。 | 如果 Key 设置错误或未设置,消息会被轮询分发,导致乱序。 |
| 第二步 | 服务端 (Broker) | FIFO 存储 利用队列先进先出的特性。 | 目的: 在同一个分区内,消息是严格按照接收顺序追加写入的。 | 只能保证 Partition 级别的有序,不能保证整个 Topic (全局) 有序。 |
| 第三步 | 消费者 (Consumer) | 单线程/分区绑定 一个 Partition 对应一个消费者实例(或线程)。 | 目的: 避免多个消费者抢同一个分区的消息,导致“后发的先处理”。 | 吞吐量受限于分区的数量。 |
| 优化版 | 消费者内部 (Advanced) | 内存队列分发 拉取消息后,再次根据 ID Hash 放入内部的 内存队列,由不同线程处理。 | 目的: 既保证了顺序,又提升了并发能力。 (同个 ID 进同个内存队列,不同 ID 并行处理)。 | 代码复杂度高,需处理内存溢出风险;如果消费者宕机,内存消息会丢失。 |
8.如何保证幂等写?
9.如何处理消息队列的消息积压问题?
1. 发现与分析:为什么会积压?
首先要明确积压的根因:
-
消费端出 Bug 了:比如消费逻辑进入死循环、数据库死锁、或者频繁 FullGC 导致处理变慢。
-
流量骤增:大促活动、突发热点导致生产者发送的消息远超消费者的处理上限。
-
下游依赖故障:比如数据库响应慢、第三方接口超时,拖慢了消费速度。
2. 紧急处理方案(面试加分项)
如果积压已经严重影响业务(如:几小时前的消息还没发出去),最快的方法是临时扩容:
-
修复消费端 Bug:如果有 Bug,必须先上线修复代码。
-
临时扩容消费者:
-
常规做法:如果是 Kafka/RocketMQ,可以通过增加 Consumer 实例来加速。但注意:Consumer 数量不能超过 Partition/Queue 的数量,否则多出来的消费者会拿不到数据。
-
终极方案(搬运法):
-
新建一个 Topic,分区数设为原来的 10 倍。
-
写一个临时的“搬运程序”,不做业务逻辑,只负责从旧 Topic 读消息,快速转发到新 Topic。
-
临时部署 10 倍数量的 Consumer 实例去消费新 Topic 里的消息。
-
积压消掉后,恢复原有架构。
-
-
10.如何保证数据一致性,事务消息如何实现?
如果不分阶段,通常只有两种写法,但都有致命 Bug:
-
写法 A(先库后 MQ): 先扣钱,再发消息。
-
风险: 钱扣了,还没来得及发消息,机器突然断电了。
-
结果: 钱没了,对方也没收到通知。(亏了)
-
-
写法 B(先 MQ 后库): 先发消息,再扣钱。
-
风险: 消息发出去了,结果扣钱的时候余额不足(报错了)。
-
结果: 钱没扣,对方却收到了“转账成功”的通知。(诈骗)
-
事务消息(Transaction Message)就是为了解决这个问题:它保证了“本地事务执行”和“消息发送”这两个动作,要么同时成功,要么同时失败。
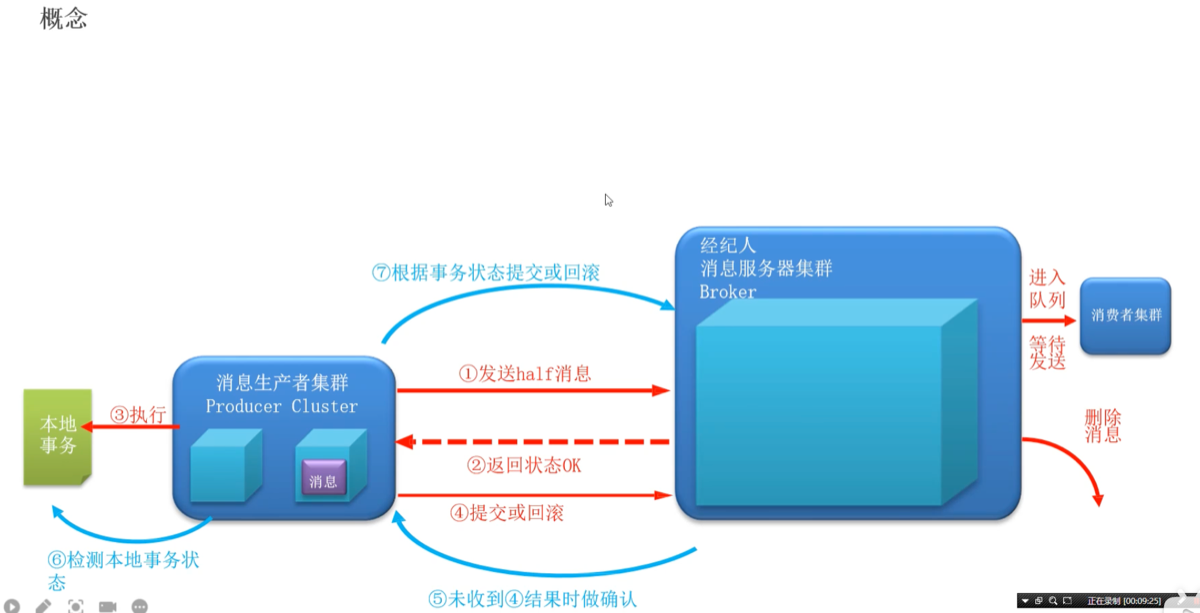
第一阶段:Half Message(半消息)
-
发送半消息:生产者先发一条消息给 MQ Server。
-
消息暂存:MQ 收到后,将消息存入一个特殊的队列,此时消费者不可见。
-
返回结果:MQ 返回 ACK 告诉生产者:“消息我收到了,你现在可以执行本地逻辑了”。
第二阶段:执行本地事务与提交
-
执行本地事务:生产者开始操作本地数据库(如:创建订单)。
-
发送最终状态:
-
如果本地成功,发送 Commit。MQ 将消息标记为“可投递”,消费者正式收到消息。
-
如果本地失败,发送 Rollback。MQ 直接删除该消息,不投递。
-
第三阶段:事务回查(补偿机制)
-
回查:如果因为网络断了或生产者宕机,MQ 迟迟没收到 Commit/Rollback,它会主动询问生产者:“刚才那条半消息,你本地事务到底成没成功?”
-
根据查询结果补发:生产者查库后告诉 MQ 最终状态。
| 阶段 | 你的动作 | MQ 的反应 | 潜台词 |
|---|---|---|---|
| 1. Half Message | 发送半消息 | 存入 Half 队列 (不可见) | “我要干坏事了,先帮我盯着点,别告诉别人。” |
| 2. Local Transaction | 执行本地 SQL | 等待指令 | “我正在干活… (扣钱中)” |
| 2.1 Commit/Rollback | 发送结果 | 投递消息 或 删除消息 | “干成了,发吧!” / “搞砸了,删了吧!” |
| 3. Check Back | (网络断了没发结果) | 主动来问你 | “喂?你人呢?刚才那事到底成没成?” |
11.消息队列是参考哪种设计模式?
1. 核心设计模式:发布-订阅模式(Pub-Sub)
这是 MQ 最灵魂的设计模式。它由发布者(Publisher)、**订阅者(Subscriber)和中间组件(Broker/Topic)**组成。
-
解耦核心:发布者和订阅者互不知道对方的存在。发布者只管把消息丢给 Broker,订阅者只管从 Broker 订阅自己感兴趣的主题。
-
对比观察者模式(Observer):
-
观察者模式:通常是同步的,且观察者与被观察者之间存在直接耦合(被观察者需要维护一个观察者列表)。
-
发布-订阅模式:是异步的,通过第三方(Broker)实现了物理和逻辑上的完全解耦。
-
2. 核心架构模型:生产者-消费者模型
如果说发布-订阅定义了“谁收消息”,那么生产者-消费者模型则定义了“消息怎么流转”。
-
缓冲区(Buffer/Queue):MQ 充当了模型中的缓冲区。它解决了生产者和消费者处理速度不匹配的问题。
-
削峰填谷:当生产者(如秒杀请求)瞬间爆发时,消息先堆积在 Queue 中,消费者按自己的节奏慢慢处理,保护后端系统不被压垮。
12.让你写一个消息队列,该如何进行架构设计?
sb?
说一遍架构,用微服务对比,然后解决各种问题,如重复消费,顺序性,丢失怎么办
13.讲一下rabbitMQ 的延迟队列和死信机制
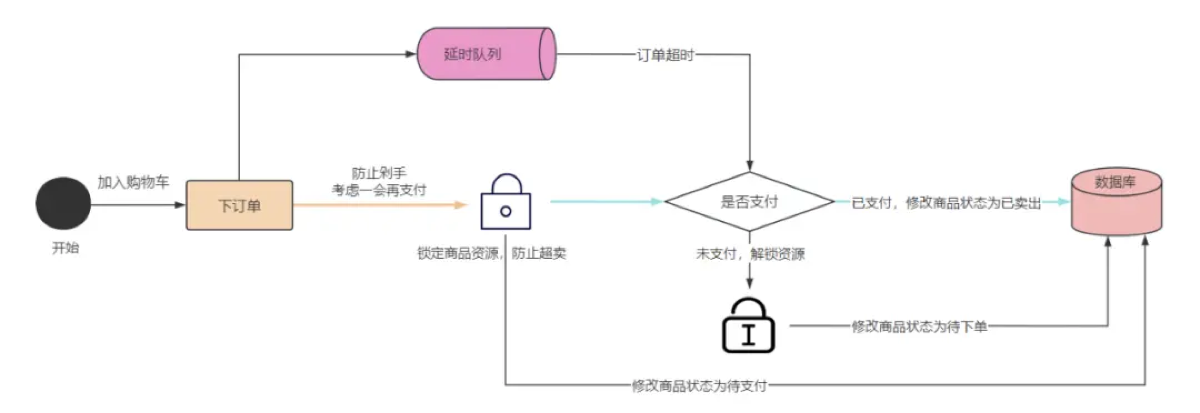
-
订单超时未支付自动取消:用户下单后发送一条延迟 30 分钟的消息,时间到后检查订单状态,若未支付则关闭。
-
异常重试逻辑:如果消费失败,不立刻重试,而是发到延迟队列,5 分钟后再试一次,防止频繁重试拖垮系统。
-
注册后提醒:用户注册后,1 小时内未上传头像,发送系统提醒。**
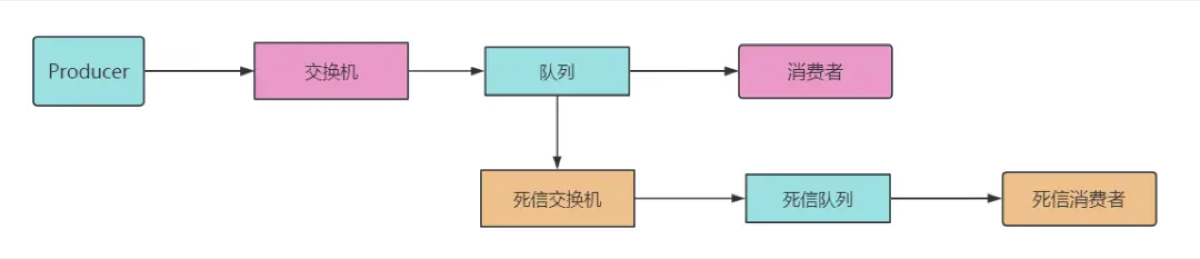
-
消息被拒绝:消费者调用
basic.reject或basic.nack,且设置requeue=false(不重新入队)。 -
消息过期:消息设置了 TTL(生存时间),到了时间还没被消费。
-
队列达到最大长度:队列满了,最早的消息会被挤出来变成死信。
“死信机制本质上是 RabbitMQ 的一种兜底策略,它让那些失败或过期的消息不至于无声无息地消失,而是可以被重新审计或处理。