1.索引是什么?有什么好处?
类似于书籍的目录,减少查询次数,提高性能
如果没用到索引就是On 如果用到,Olog dN ,d:每个节点最多能有多少个“子节点”
2.为什么MySQL要用B+树
- 多叉结构降低高度:磁盘I/O次数少,查找更快。
- 叶子节点有序且双向链表相连:方便范围查询和排序。
- 磁盘友好:节点大小一般和页(16KB)一致,一次读入多个索引。
3.讲讲索引的分类是什么
MySQL 索引可以从 4 个维度进行分类,每个维度分别对应不同的理解角度:
① 按数据结构
| 类型 | 描述 | 是否常用 |
|---|---|---|
| B+Tree 索引 | MySQL 默认索引结构,支持范围查询与排序 | ⭐最常用 |
| Hash 索引 | 等值查询极快,不支持范围查询(Memory 引擎用得多) | 特殊场景 |
| Fulltext 全文索引 | 文本搜索(MATCH AGAINST) | 文本搜索 |
| 在创建表时,InnoDB 存储引擎会根据不同的场景选择不同的列作为索引: |
- 如果有主键,默认会使用主键作为聚簇索引的索引键(key);
- 如果没有主键,就选择第一个不包含 NULL 值的唯一列作为聚簇索引的索引键(key);
- 在上面两个都没有的情况下,InnoDB 将自动生成一个隐式自增 id 列作为聚簇索引的索引键(key);
- 其它索引都属于辅助索引(Secondary Index),也被称为二级索引或非聚簇索引。创建的主键索引和二级索引默认使用的是 B+Tree 索引。
② 按物理存储方式
| 类型 | 描述 |
|---|---|
| 聚簇索引(Clustered Index) | B+Tree 的叶子节点存实际数据。InnoDB 主键即聚簇索引。 |
| 二级索引(非聚集索引)(Secondary Index) | 叶子节点存主键值 → 需要时回表查数据 |
③ 按字段特性
| 类型 | 特点 |
|---|---|
| 主键索引(PRIMARY KEY) | 唯一、非空、一个表只能一个 |
| 唯一索引(UNIQUE) | 值唯一但允许 null |
| 普通索引(INDEX) | 最普通,不保证唯一 |
| 前缀索引 | 对字符串的前 N 个字符建索引,减少索引大小 |
| 索引类型 | 是否唯一 | 是否允许空(NULL) | 核心目的 | 物理存储 |
|---|---|---|---|---|
| 主键索引 | ✅ 唯一 | ❌ 必须有值 | 物理排序 + 唯一标识 | 聚集索引(数据本身) |
| 唯一索引 | ✅ 唯一 | ✅ 允许 (除非设为 Not Null) | 业务防重 (如手机号、身份证号) | 非聚集索引(二级索引) |
| 普通索引 | ❌ 重复 | ✅ 允许 | 提升查询速度(张三,有多个重名的人,但不 care | 非聚集索引(二级索引) |
| 前缀索引 | ❌ 重复 | ✅ 允许 | 节省空间 (针对长字符串) | 非聚集索引(存残缺值) |
④ 按字段个数
| 类型 | 描述 |
|---|---|
| 单列索引 | 一个字段 |
| 联合索引(复合索引) | 多字段组成的索引。遵循 最左匹配原则 |
| ![[Pasted image 20251118210559.png | 700]] |
4.哈希索引使用场景是什么?
哈希索引适用于:等值查询频繁、且不需要范围查询的场景。 它的核心特点:
- 查询效率极高(接近 O(1))
- 只能做 =、IN 等值匹配
- 不能做范围查询(>、<、BETWEEN)、排序、前缀匹配等
📌 典型使用场景
1)内存型场景 — Memory 引擎默认使用 Hash 索引
例如:
- 用户 Session 缓存表
- 临时映射表
- 快速根据 ID 查状态、权限 因为它 数据都在内存,追求极致读取速度,且查询模式简单(根据 Key 查 Value)。
2)等值查询远多于范围查询的场景
比如:
- 根据用户 ID 查询用户信息
- 根据 Token 查询用户
- 根据唯一 Key 做快速定位 这些场景都是“点查”,哈希索引性能比 B+Tree 更极致。
❌ 不适用的场景
- 范围查询:
WHERE id > 10 - 排序:
ORDER BY … - 前缀查询:
LIKE 'ab%' - 需要按照顺序访问数据的业务
🎯 一句话记忆
哈希索引适用于纯等值查询的 Key-Value 场景,尤其是 Memory 引擎,在不需要范围和排序的情况下,它比 B+Tree 更快。
5.MySQL聚簇索引和非聚簇索引的区别是什么?
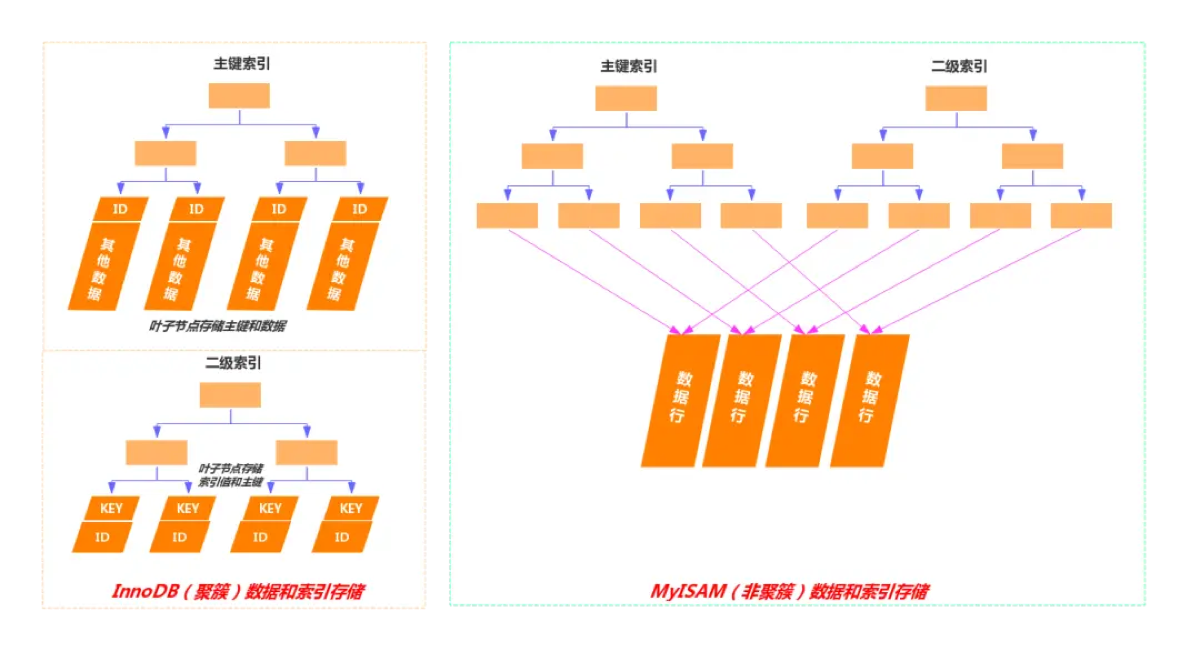
- 聚簇索引把真实数据存放在 B+Tree 的叶子节点,同一份数据在磁盘上只保存一次,所以一个表只能有一个聚簇索引,
- 而非聚簇索引(二级)的叶子节点只存主键值,需要根据主键再回到聚簇索引查真实数据,因此会有回表过程。
- 聚簇索引范围查询更快,非聚簇索引在使用覆盖索引时最优。
6.如果聚簇索引的数据更新,它的存储要不要变化?
更新普通列 → 不改变存储结构 更新主键列 → 必须调整 B+Tree,存储结构会变化
因为主键是聚簇索引的排序依据。 主键变了,就必须:
- 把原来的记录从 B+Tree 中删除
- 再按照新的主键值插入到 B+Tree 正确的位置
- 可能导致:
- 页分裂
- 页合并
- 记录位置移动 也就是说:更新主键 = 删除 + 插入一次,结构一定会变
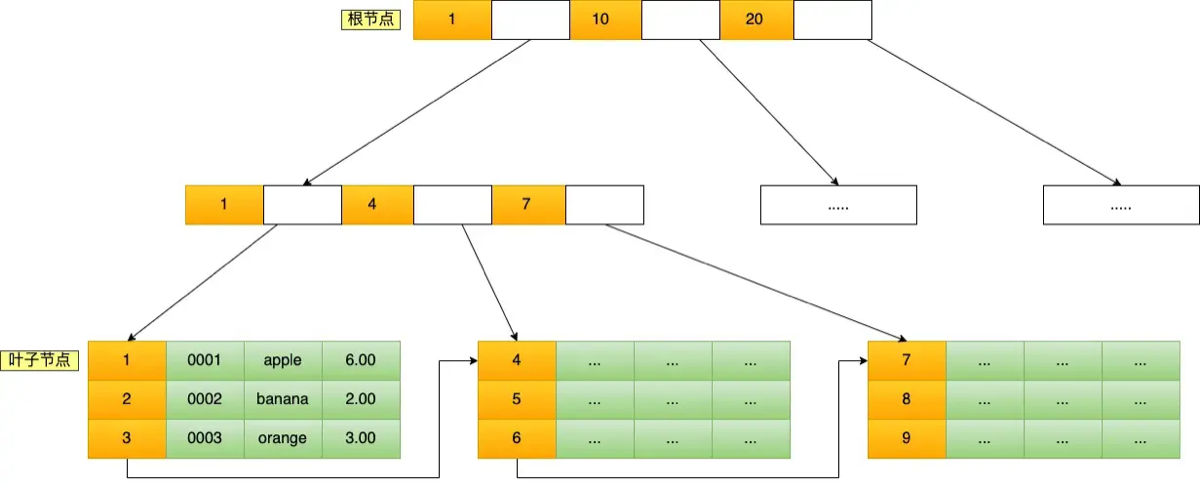
7.MySQL主键是聚簇索引吗?
8.什么字段适合当做主键?
主键应当选择:唯一 + 非空 + 有序递增 + 与业务无关的字段。 单机用自增 ID,多机用分布式 ID。业务字段不要当主键。
1. 具备唯一性、非空性(必须) 主键必须唯一且不能为 NULL。
2. 最好是“递增、有序”的字段(重点) 为什么要递增?因为 InnoDB 的主键是 聚簇索引:
- 顺序插入 → 不会页分裂、不会产生碎片
- IO 是顺序写 → 性能最高 最常用: ✔ 自增 ID(AUTO_INCREMENT)
3. 不建议使用业务字段(强烈不推荐) 例如:
- 会员卡号
- 学号
- 订单号
- 手机号 原因: ❌ 业务变化可能导致字段重复 ❌ 业务主键不一定有序 → 导致页分裂、性能变差 ❌ 改业务字段就会导致主键更新(很危险)
4. 分布式场景不要用自增 ID(单机 OK,多机不 OK) 多机器插入时,自增 ID 会冲突,因此需要: ✔ Redis 发号器 ✔ Snowflake 雪花算法 ✔ 数据库序列(部分 DB) 这些都是“分布式 ID 方案”。
9.**性别字段能加索引么?为啥?
性别字段不适合加索引,因为区分度极低,走索引会导致大量回表,成本比全表扫描更高,优化器最终会放弃索引,使其毫无意义。
10.表中十个字段,你主键用自增ID还是UUID,为什么?
用自增 ID,当主键必须是有序、短、稳定、可预测的聚簇索引键。 UUID 会导致严重的写入性能问题。
1. 自增 ID 是顺序写,非常快
InnoDB 的主键是 聚簇索引,数据按主键顺序存储。 用自增 ID → 新数据永远写在 B+Tree 的“末尾”,磁盘顺序写,开销最小。
2. 不会造成页分裂,避免大量随机 IO
UUID 无序,会把数据强行插入 B+Tree 中间 → 页分裂、记录移动、碎片产生,写入性能急剧下降。
3. 主键更短,索引也更小
- 自增 ID:4 或 8 字节
- UUID:36 字符(甚至 16 字节二进制) 主键越大,二级索引越胖,B+Tree 越高,查询越慢。
UUID以上都相反
11.什么自增ID更快一些,UUID不快吗,它在B+树里面存储是有序的吗?
自增 ID 是顺序增长 → 顺序写入 → 插入 & 查询最快。 UUID 随机 & 长 → 在 B+Tree 中乱序插入 → 页分裂 + 随机 I/O → 性能最差。
12.Mysql中的索引是怎么实现的
MySQL(InnoDB)的索引是通过 B+ 树实现的,数据按主键有序存放,叶子节点存储数据或主键值,并且叶子节点通过双向链表相连,支持高效率的点查和范围查
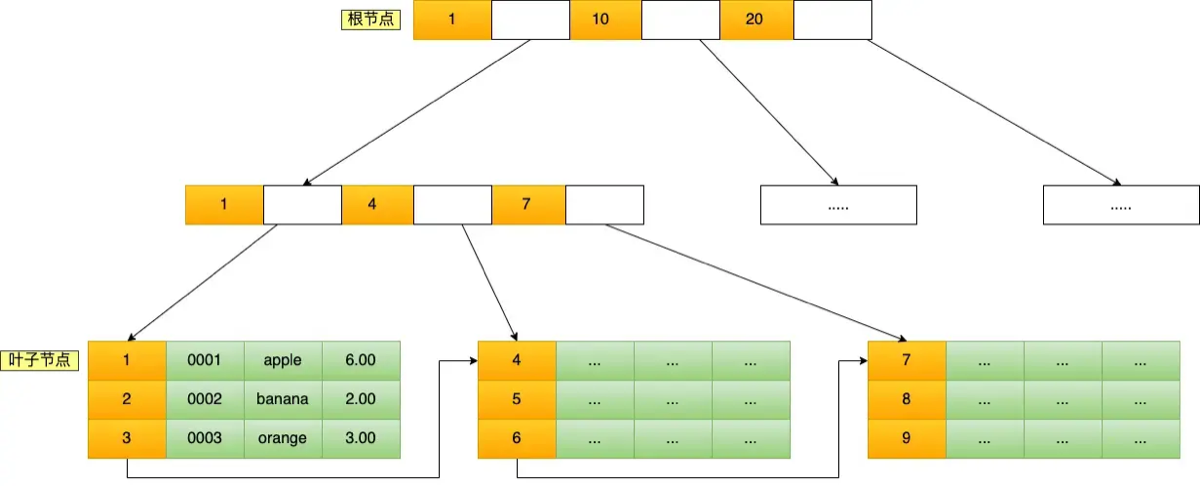
1. 索引结构:B+Tree
- InnoDB 使用 B+树 来存储索引。
- 非叶子节点:存索引(key),不存数据
- 叶子节点:存储所有 key,并且存放数据(主键索引)或主键值(二级索引)
2. 主键索引(聚簇索引)
- 叶子节点直接存放整行数据。
- 表数据按照主键顺序排布 → 物理有序。
3. 非主键索引(普通索引 / 唯一索引)
- 叶子节点存放的是 主键值(不是整行记录)。
- 查数据时需要: 1)先在二级索引找到主键 2)再去聚簇索引根据主键找整行 → 回表
4. 叶子节点组成双向链表
- 支持快速区间扫描(range query)
- 比如:
where id between 10 and 100 - B+树特别适合范围查询(比哈希好太多)
5. 查找过程:自顶向下
以 id = 5 为例:
- 根节点二分查找定位区间
- 找到下一层节点
- 到叶子节点找目标记录 → I/O 一般 3~4 次就能定位(千万数据也如此)
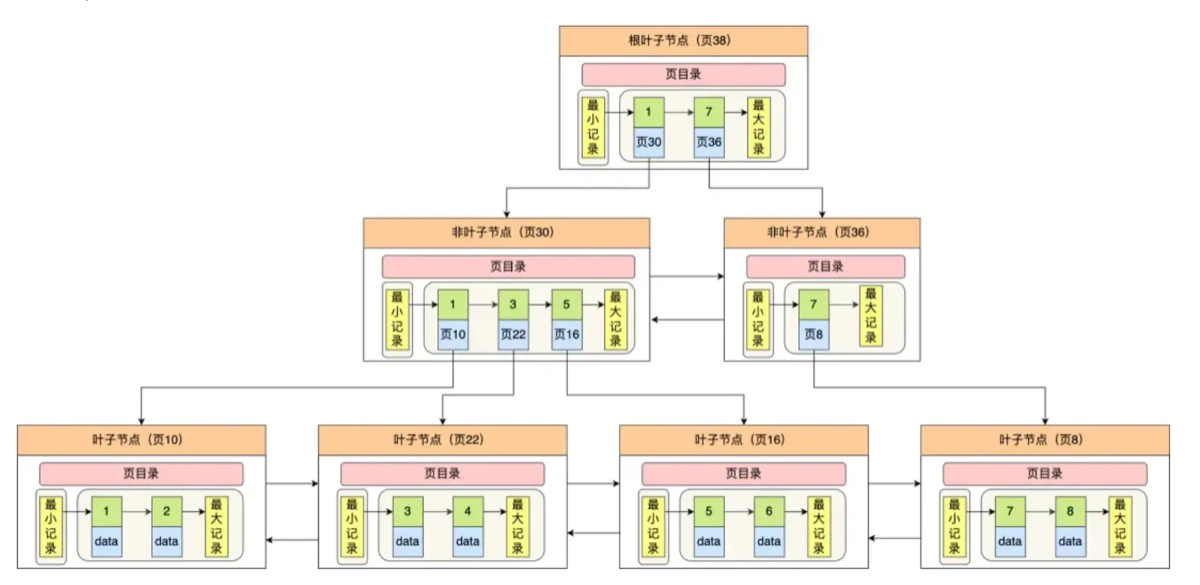
13.**查询数据时,到了B+树的叶子节点,之后的查找数据是如何做?
到达 B+ 树叶子节点后,InnoDB 不是直接顺着链表扫描,而是利用“页目录(Page Directory)”做二分查找快速定位记录,再在对应分组内顺序查找,效率很高。
- 到达 B+ 树的叶子节点后,InnoDB 会在数据页中利用“页目录”来定位记录。
- 数据页的记录会按主键顺序分组,页目录中保存每组最后一条记录的偏移量。
- 查找时先在页目录做二分查找找到对应分组,再在该分组的记录链表中做顺序查找,所以页内查找非常快,避免了全链表扫描。
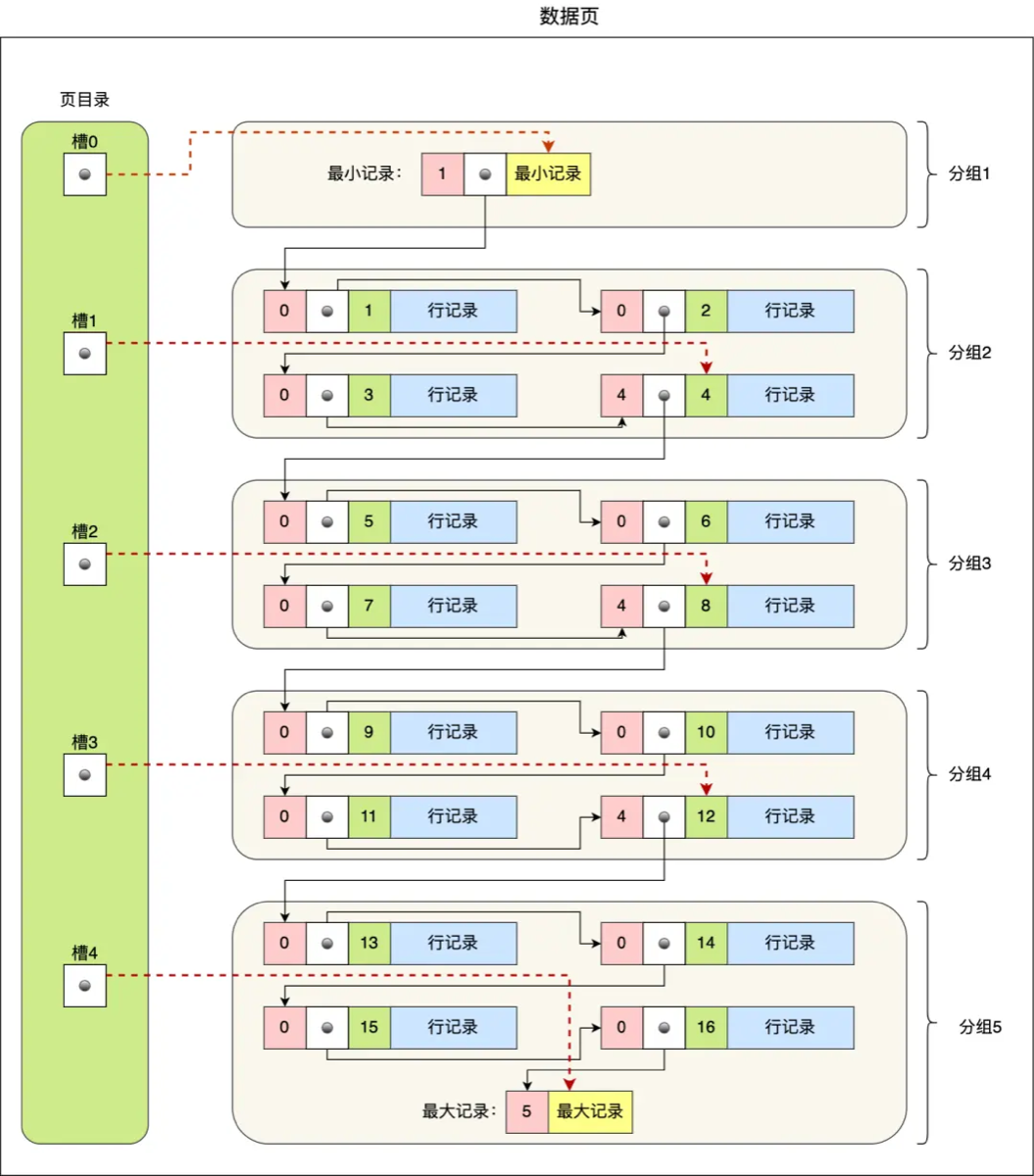
1)叶子节点 ≠ 最终定位记录,页内还要继续查找
叶子节点对应的是「数据页(Data Page)」。 数据页中所有记录按主键顺序组成单向链表(方便插入、删除),但如果要查找靠后的记录,不能从头遍历,效率太低。
2)InnoDB 为此在“页内”设计了一个目录:页目录(Page Directory)
页中的记录被分组(Group),每组记录之间是连续的。 目录中存储每组“最后一条记录”的偏移量,称为槽(slot)。 可理解为: 📘 叶子节点 = 一本书 📑 页目录 = 目录页(Chapter List) 🔍 查记录 = 先查目录,再定位章节再查内容
3)查找步骤(重点)
假设要查主键 = X 的记录:
① 在槽列表上做二分查找
从槽 0 ~ 槽 N 中查找:
- 找出「最大记录值 ≥ X」的槽
- 槽数一般很少(几十个),二分查找非常快
② 找到槽对应的分组(记录链表)
定位到该分组的最后一条记录
③ 在该组内链表顺序遍历,找到目标记录
⚡ 因为一个分组最多 8 条记录,所以遍历成本极低。
4)为什么需要页目录?
如果不用页目录:
- 页内记录数可能很多(几百~几千条)
- 按链表只能 O(n) 顺序扫描
- 效率过低 使用页目录后:
- 页内定位变成 O(log n) + O(组大小)
- 一般是 二分查找 + 最多 8 次顺序扫描 极其高效。
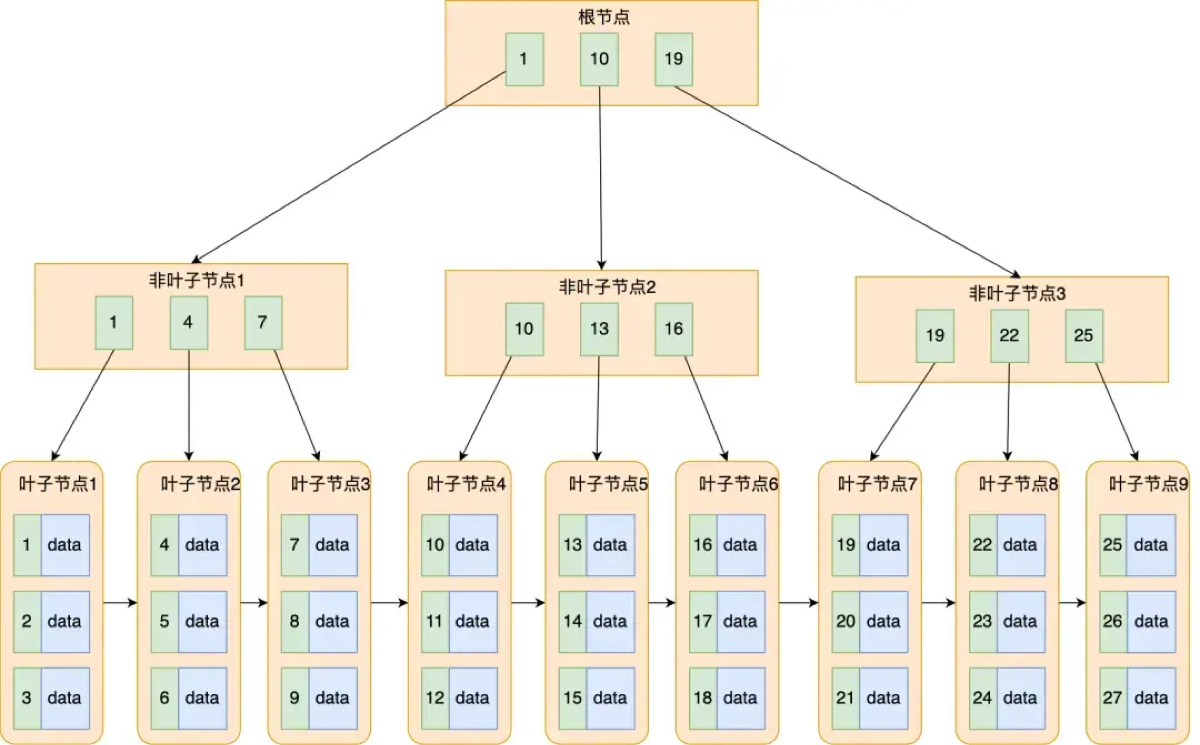
14.**B+树的特性是什么?
“B+ 树只有叶子节点存数据,叶子节点同层且用双向链表相连;非叶子节点只存索引,使树更矮、更适合集合范围查询,是 InnoDB 索引的最佳结构。”
15.说说B+树和B树的区别
1. 存储位置不同(最重要)
- **B 树:** 非叶子节点既存索引,也存“部分数据”
- **B+ 树:** 只有叶子节点存数据,非叶子节点全是索引 👉 好处:B+ 树节点更小 → 每层能放更多 key → 树更矮 → 查询更快
2. 查找路径不同
- **B 树:**可能在中间节点就找到数据 → 查找路径不稳定
- **B+ 树:**必须走到叶子节点 → 查找路径稳定、磁盘 I/O 次数稳定
3. 叶子节点结构不同
- **B 树:**叶子节点之间 没有指针
- **B+ 树:**叶子节点之间 双向链表连接 👉 好处:范围查询特别快(连续扫链表即可)
4. 数据冗余不同
- **B 树:**父子节点 key 不重复
- **B+ 树:**非叶子节点存的是叶子节点的冗余索引 👉 更适合磁盘预读(局部性强)
16.B+树的好处是什么?
B+ 树更矮、范围查询更快、所有数据在叶子节点、结构稳定,因此比 B 树更适合数据库索引。 15.说说B+树和B树的区别
17.B+树的叶子节点链表是单向还是双向?
B+树的叶子节点链表是 双向链表,用于支持正序 + 倒序遍历,提高范围查询效率。
- 双向链表可以顺着查,也能反着查 → 支持 ORDER BY xxx DESC 的倒序扫描。
- 范围查询效率更高 → 叶子节点本来就按 key 排序,再加双向链表,一扫到底。
- InnoDB 的 B+Tree 全都用双向叶子链表实现 → 不只是理论,是真实实现。
18.MySQL为什么用B+树结构?和其他结构比的优点?
MySQL 用 B+ 树是因为它能以极低的磁盘 I/O、高度稳定的查询性能、优秀的范围扫描能力来处理海量数据,这些是 B 树、Hash、二叉树都做不到的。
1)相比 B 树:更快 & 更稳
- 非叶子节点不存数据 → 单节点更小 → 单页能放更多索引 → 树更矮(IO 更少)
- 所有数据在叶子节点 → 每次查找都走到叶子 → 查询性能更稳定(不会中途命中)
- 叶子节点有双向链表 → 范围查询、排序扫描极强
2)相比 二叉树:IO 次数少到离谱
- 二叉树分支数少,每次只能分 2 路,层数高,磁盘 I/O 多
- B+ 树一个节点可放几百个 key → 3~4 层就能放千万级数据 👉 一次查询只需 3~4 次磁盘 I/O(关键优势)
3)相比 Hash:能做范围查询
- Hash 只适合 等值查询
- 无法做 >、<、BETWEEN、ORDER BY
- 不支持范围扫描、不支持排序、不支持前缀匹配 而 B+ 树有序 + 叶子链表 → 范围、排序、前缀查找都是它强项
19.为什么 MysSQL 不用 跳表?
因为跳表层数太高,在磁盘上的 IO 次数比 B+ 树更多,所以性能更差。 跳表层数多,每层链表指针零散分布,这是内存友好,但对磁盘结构不友好。
① 跳表需要多层索引 → 层级太高 → 磁盘 IO 次数多
跳表的查询复杂度虽然是 O(logN),但它是基于多层链表实现的。 为了覆盖几千万数据,跳表需要 20~25 层甚至更多。 而 B+ 树的一个节点可以存几百个 key(磁盘页 16KB),高度一般只有 3 层。 🔍 对磁盘数据库来说,IO 次数 = 性能天花板 跳表 20 次 IO VS B+ 树 3 次 IO 性能差距巨大!
② 跳表节点太小,不适合磁盘的“批量读取”模型
跳表每个节点只存一个 key + 指针。 B+ 树的一个节点能塞几百上千个 key,一次磁盘读取能读一大堆索引。 ➡ 跳表:需要大量随机磁盘读。 ➡ B+ 树:少量顺序 / 批量磁盘读。 在磁盘模型下,跳表天然吃亏。
20.**联合索引的实现原理?
3.讲讲索引的分类是什么 联合索引会把多个字段按固定顺序(如 a→b→c)组合成一个有序的 B+Tree,查询时必须从最左的字段开始匹配。
1️⃣ B+Tree 是按字段顺序依次排序的
例如联合索引 (product_no, name)
树的排序规则是:
product_no 优先排序 product_no 相同 → 再按 name 排序
所以它是一个有序的二维排序结构。
2️⃣ 为什么必须遵守“最左匹配原则”?
因为 B+Tree 的顺序是:
a 全局有序 a 相同时,b 才局部有序 b 相同时,c 才局部有序
如果跳过 a,例如 where b = 2,
→ b 在全局是无序的
→ 不能用树的二分查找
→ 索引失效。
3️⃣ 范围查询遇到范围符号后会停止匹配
例如索引 (a, b, c):
where a = 1 and b > 5 and c = 9
b 是范围 → c 无法继续走索引
但 a 和 b 仍然能用。
4️⃣ 联合索引底层仍然是双向链表的 B+Tree
叶子节点存:
(a, b) 组合的键值 然后指向下一条记录
双向链表支持:
- 顺序扫描
- 倒序扫描
- 范围查询效率极高
21.**创建联合索引时需要注意什么?
创建联合索引时,核心就是 —— 字段顺序很关键,把“区分度高”的字段放前面,遵循最左匹配原则,避免索引失效。
- 字段顺序 = 索引效果的关键
- 联合索引最左匹配原则:从左往右依次匹配
- 顺序写错 → 后面字段索引直接失效
- 区分度高的字段放最前
- 区分度 =
count(distinct col) / count(*) - 区分度高 → 过滤能力强 → 索引更容易被使用
- 性别 (0/1) 这种区分度低的,绝不能放在前面
- 区分度 =
- 避免浪费:只建立会被 where / order by / group by 用到的字段组合
- 不常被查询的字段不要放进去
- 避免因为顺序错误导致优化器不用索引
1)A=xxx AND C<xxx 走不走 (A,B,C) 联合索引? ✔ 走索引,但只用到 A;C 不参与索引匹配,只能用“索引下推”减少回表。 理由:最左匹配遇到断层(跳过 B)就停止。
2)WHERE b>xxx AND a=x 能用到 (a,b,c) 联合索引吗? ✔ 可以,a 和 b 都能使用索引。 理由:最左匹配只要求“第一个字段必须出现”,a 存在 → b、c 才能继续匹配。
3)WHERE a=2 AND c=1 能用到 (a,b,c) 吗? ✔ 能用到索引,但只有 a 真正参与索引匹配;c 不能匹配索引,只能靠索引下推。
22.索引失效有哪些?
左模糊,函数算; 列转型,最左断; OR 一边没索引,全表扫描跑断腿。
- **模糊匹配导致失效:**
LIKE '%xx'、LIKE '%xx%'—— 左模糊 / 全模糊都会失效。 - **对索引列使用函数:**
如
WHERE DATE(create_time) = ...—— 对索引做函数操作会失效。 - **对索引列进行表达式计算:**
如
WHERE age + 1 = 30—— 任何计算都会让优化器放弃索引。 - **隐式类型转换:**
如
WHERE name = 123(name 是 varchar)—— MySQL 将索引列转型 → 相当于对索引列做函数 → 失效。 - **联合索引不满足最左匹配原则:**
(a, b, c) → 必须从 a 开始用,不从最左边开始索引必失效。 - **WHERE 中有 OR,且一边无索引:**
如
WHERE a = 1 OR b = 2(b 无索引) → 整个索引失效,全表扫描。
23.什么情况下会回表查询
使用二级索引查询,但需要的字段不在二级索引里,就会回表
- 二级索引叶子节点只存主键值 → 查到主键后还要再去主键索引树取整行数据。
- 查询字段没被索引覆盖 → 比如索引是 (name),查询 SELECT name, age 时必须回表取 age。
- 覆盖索引可以避免回表 → 查询所需字段都在二级索引里 → 直接返回,不用回表。
🌰 最典型示例
索引:INDEX(name)
SQL:SELECT age FROM user WHERE name='Tom';
age 不在二级索引 → 回表
SQL:SELECT name FROM user WHERE name='Tom';
只查 name,被索引覆盖 → 不回表(覆盖索引)
24.什么是覆盖索引?
覆盖索引 = 查询所需的所有字段都在索引里,不用回表,查询只在索引层完成。
🧠 示例(最常见的面试例子)
INDEX(name, age, department) SELECT name, age FROM employees WHERE name='John';
以上查询所需字段都在索引里 ⇒ 覆盖索引成立,不回表。
25.如果一个列即使单列索引,又是联合索引,单独查它的话先走哪个?
MySQL 优化器会比较成本,选择“代价最小”的索引;通常联合索引更容易被选中,因为覆盖索引、无需回表。
26.关于建索引
1. 插入新数据后索引的变化
- 索引基于 B+ 树 实现,插入数据会:
- 更新叶子节点内容(正常插入)
- 若叶子节点 已满,则触发分裂,维持 B+ 树平衡
- MySQL 自动完成所有调整,保证索引结构正确。
2. 索引字段是不是越多越好?
- 不是。索引越多:
- 占用更多磁盘与内存空间
- 写入/更新时维护成本更高(B+树更新慢)
- 特别在写多读少场景反而降低性能。
3. status(0/1)字段适合建索引吗?
- 不适合。原因:
- 区分度极低(几乎 50/50)
- 使用索引后范围太大 → 回表次数巨大 → 比全表扫描还慢
- 优化器通常会直接忽略该索引。
4.怎么决定建立哪些索引?
高频查询字段 + 高区分度字段 + 参与 JOIN/排序/分组 的字段 → 建索引 低区分度字段 + 小表 + 高频更新字段 → 不建索引
一、什么时候应该建索引?(必须建)
✔ 1. 字段具有高“区分度”(唯一性强)
- 例:user_id、order_no、手机号、邮箱、商品编码 👉 选择性高 → 能大幅减少扫描行数 → 性能收益大
✔ 2. 经常出现在 WHERE 条件中
例如查询:
WHERE user_id = ? WHERE status = ? WHERE create_time BETWEEN ...
(告诉数据库:我用这字段过滤数据,请帮我用索引定位)
✔ 3. 经常用于排序 ORDER BY
排序能直接利用 B+tree 的有序性,避免 filesort
✔ 4. 经常用于 GROUP BY
能避免额外排序
✔ 5. JOIN 关联字段
JOIN 的 ON 字段最好都有索引
例如:
user.id ↔ order.user_id
二、什么时候不要建索引?(绝对不要建)
✖ 1. 区分度极低的字段
如:
- 性别(男/女)
- 状态字段只有 0/1
- 是否删除 0/1 区分度低 → 扫描行数接近全表 → 索引没意义,甚至更慢。
✖ 2. 表数据量太小
几百/几千行以内 全表扫描反而更快 → 索引成本 > 获益
✖ 3. 经常被更新的字段
如:
- 用户余额
- 登录时间 last_login
- 商品库存 更新会触发 B+tree 调整 → 维护成本高
✖ 4. WHERE、排序、分组中完全不会用到
没有查询价值的字段不用建索引。
27.索引优化详细讲讲
索引优化的核心目标就是 减少扫描行数 + 减少回表 + 降低写入开销。 记住三件事:覆盖索引、前缀索引、自增主键 + 防止索引失效。
1. 前缀索引(减少索引大小,提高索引页利用率)
- 适用于字符串字段很长的情况(如邮箱、URL、手机号加密字符串等)。
- 只索引前 N 个字符,节省存储空间,提高 B+Tree 单页的索引数量,提高检索效率。
- 缺点:不能做覆盖索引,只能做「等值查询」「前缀匹配」。
2. 覆盖索引(避免回表查询最重要的优化)
- 查询使用的所有字段都存在于当前索引中 → 不需要回表。
- 优点:
- 少一次回表 = 少一次 B+Tree 访问
- 大幅减少 I/O
- 常用于高 QPS 接口
- 示例:
SELECT name, age FROM user WHERE name = 'xx';如果有联合索引(name, age)→ 完全覆盖。
3. 主键自增(强烈推荐)
避免随机主键(例如 UUID)导致:
- 页分裂
- 数据不连续
- B+Tree 变高
- 大量随机写 I/O
自增主键能保证:
- 新行都插在最后
- 页利用率更高
- 插入效率极高(顺序写)
4. 防止索引失效(容易踩坑的 4 类失效)
以下情况会导致 MySQL 无法利用索引:
- LIKE 左模糊
LIKE '%xxx' -- 索引失效 LIKE 'xxx%' -- 可以走索引 - 索引列使用函数/计算
WHERE DATE(create_time) = '2024-01-01' -- 失效 WHERE create_time >= '2024-01-01' -- 正常 - 隐式类型转换
WHERE phone = 13812345678 -- phone 是 varchar,会隐式转换导致失效 - OR 条件中部分字段无索引
WHERE a = 1 OR b = 2 -- 若 b 没有索引,则全失效
5. 联合索引最左匹配原则(必须会)
索引 (a, b, c) 能用的情况:
| 查询条件 | 是否生效 | 原因 |
|---|---|---|
| a= | ✔ | 最左匹配 |
| a= AND b= | ✔ | 顺序匹配 |
| a= AND b= AND c= | ✔ | 全匹配 |
| b= | ✘ | 未从 a 开始 |
| c= | ✘ | 未从 a 开始 |
| a= AND c= | ✔ 索引用到 a,但 c 靠 index pushdown | b 没有参与匹配 |
| 注意:遇到范围查询(>、<、between、like ‘xx%‘)会停止继续匹配 |
6. 减少索引数量(不是越多越好)
索引的缺点:
- 占空间
- 写入时每个索引都要维护 B+Tree,降低写性能
- 更新频繁的字段不适合建索引(如余额、状态位等) 索引要满足一个原则:
能极大减少扫描行数的字段才值得建立索引
7. 选择性(区分度)决定一个字段是否适合建索引
区分度公式:
select count(distinct col)/count(*)
区分度低的字段(如性别、boolean)不适合建索引。
28.了解过前缀索引吗
[[4.索引#1-前缀索引减少索引大小提高索引页利用率|1. 前缀索引(减少索引大小,提高索引页利用率)]]