Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库
通过分库和分表进行数据的拆分来使得各个表的数据量保持在阈值以下,以及对流量进行疏导应对高访问量
分库
- 设计前进行分库分表 简单来说,分库是将原本的单库拆分为多个库,分表是将原来的单表拆分为多个表。
垂直分片
1)垂直分片
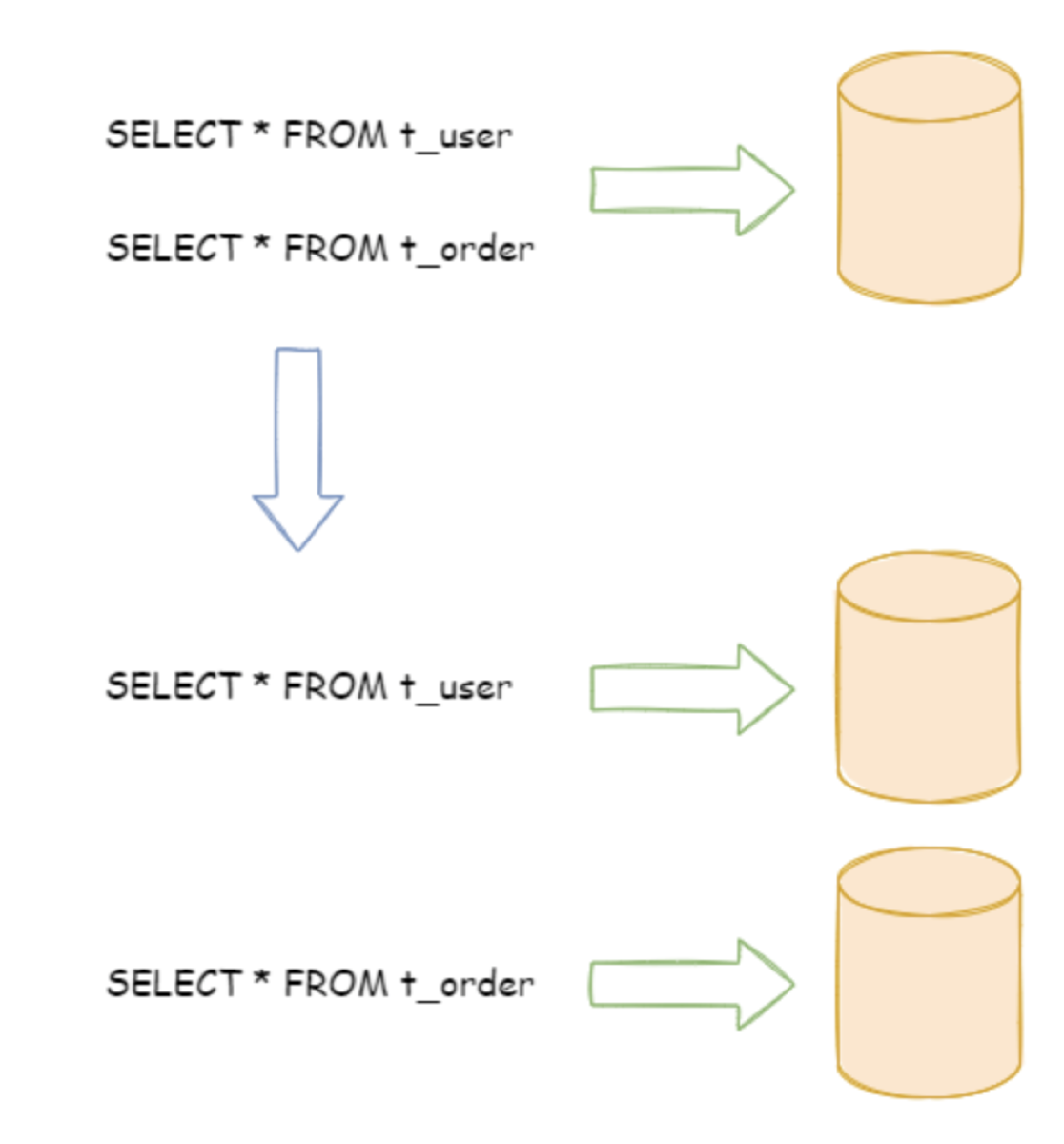
比如:电商库 mall_db,业务拆分后就是 user_db、order_db、pay_db…
按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用。在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库。
- 优点:
- 针对不同业务场景优化数据库,提高性能
- 提高并发能力
- 缺点:(多事儿)
- 增加系统复杂度
- 需要处理分布式事务问题
水平分片
2)水平分片
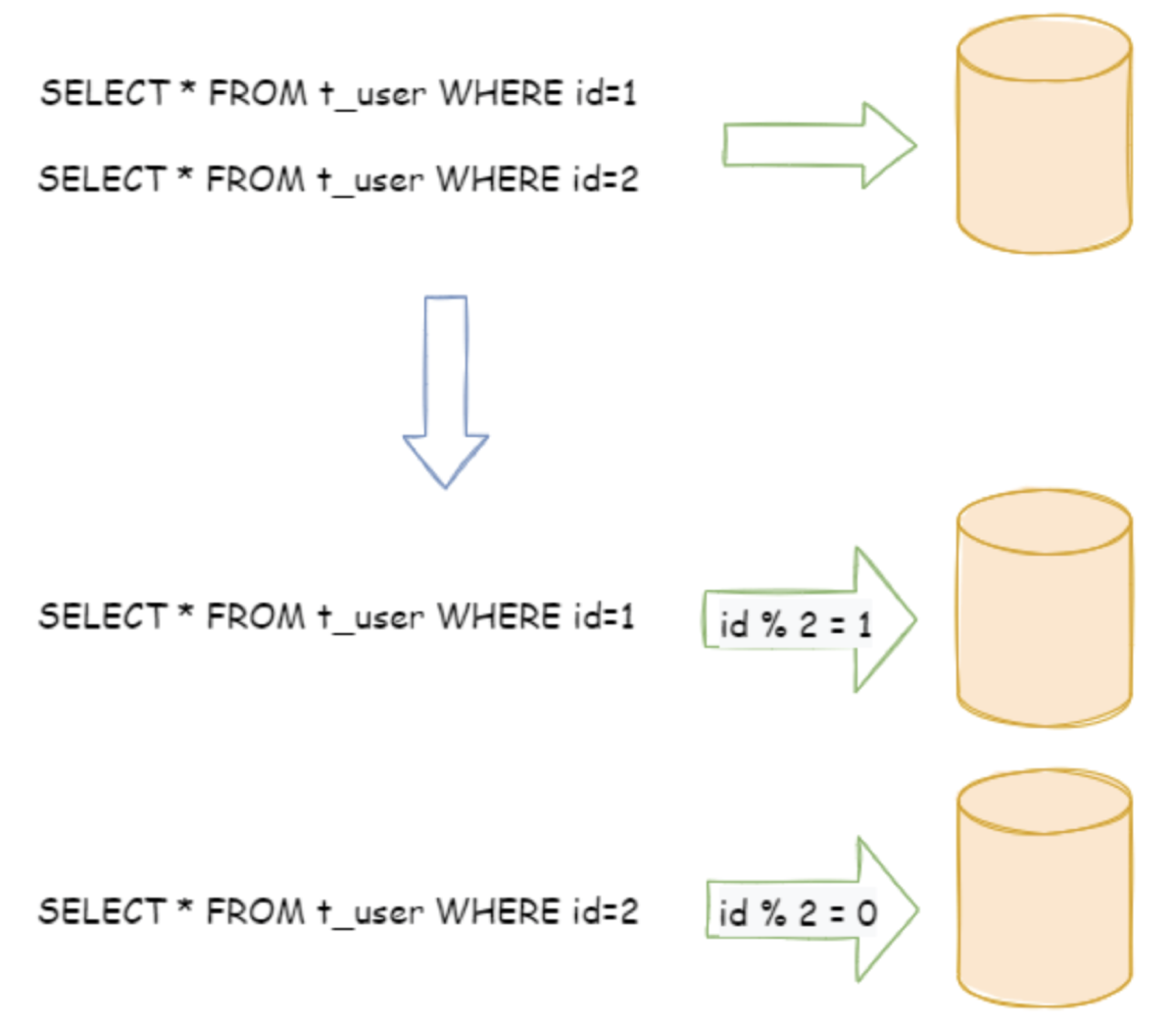
比如:用户库 user_db,分片库后就是 user_db_0、user_db_1、user_db_xx。
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 例如:根据主键分片,偶数主键的记录放入 0 库(或表),奇数主键的记录放入 1 库(或表),如下图所示。
- 优点
- 提高单库读写性能,降低单库数据量
- 库可以分开放在不同物理服务器,提高查询效率
- 缺点(多事儿)
- 需跨库处理
- 设计需谨慎,避免热点数据集中
分表
1)垂直分片
比如:订单表 order_table,拆分后就是 order_table 以及 order_ext_table。
同分库的概念,只不过将数据库维度降低为数据库表维度。
优点:
- 拆分后每个表的数据量变小,查询时涉及的磁盘 I/O 次数相对减少,提高了查询效率。
- 每个小表的并发写入操作相对较少,减少了数据库锁的竞争,提高了并发能力。
缺点:
- 需要在应用层面处理跨表查询的逻辑,增加了开发的复杂性。
- 如果一个事务涉及多个小表,可能需要在应用层面进行事务管理,增加了代码的复杂性。
- 需要额外的措施来保证拆分后的小表之间的数据一致性。
2)水平分片
比如:订单表 order_table,拆分后就是 order_table_0、 order_table_1、order_table_xxx。
同分库的概念,只不过将数据库维度降低为数据库表维度。
优点:
-
可以根据数据量的增长动态地增加分表,从而扩展数据库的存储能力。
-
每个小表的数据量减少,可以提高查询速度,尤其是在频繁查询的场景下。
-
拆分后,每个小表的并发写入操作相对减少,降低了数据库锁的竞争,提高了并发性能。
缺点:
- 对业务存在一定限制,如果没有按照分片键查询,会造成读扩散问题。
- 对分表规则的设计需要谨慎,避免热点数据集中在某个表中。
分库分表场景
2.1 什么场景分表?
Q:多少数据量进行分表?
A:单表 1000w 是否要分表?回答不够标准。假设一个表里 15 个字段,没有特别大的值(不包含 text 或其它超长度的列)数据量超过 5000 万了,依然很丝滑,因为走索引。
真正需要考虑的是:业务的增长量以及历史数量。
2.2 什么场景分库?
当数据库的连接不够客户端使用时,可以考虑分库或读写分离。
如果说当数据库的 QPS 越来越高以及数据量越来越大的时候,就需要考虑分库分表。
Q:为什么说连接不够用?
A:假设 MySQL Server 能支持 4000 个数据库连接。我们有 10 个服务,40 个节点,一个节点呢数据库连接池最多 10 个。这样就把一个 MySQL Server 的连接数压榨干净了。
当 MySQL 连接不够用时,可能会报错 “Too many connections” 或者类似的错误。这是因为 MySQL 服务器同时可以处理的连接数量是有限制的,当连接数达到这个限制时,服务器就会拒绝新的连接请求,并返回这个错误消息
什么场景分库分表
- 高并发写入
- 数据量巨大
yaml配置文件
# 数据源集合
dataSources:
# 逻辑数据源名称
ds_0:
# 数据源类型
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
# 数据库驱动
driverClassName: com.mysql.cj.jdbc.Driver
# 数据库连接
jdbcUrl: jdbc:mysql://127.0.0.1:3306/user_0?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
# 用户名,如果本地数据库与这个不一致,需要修改
username: root
# 密码,如果本地数据库与这个不一致,需要修改
password: root
# ShardingSphere 规则配置,包含:数据分片、数据加密、读写分离等
rules:
- !SHARDING
# 需要数据分片的表集合
tables:
# 逻辑表名
t_user:
# 真实存在数据库的物理表集合
actualDataNodes: ds_0.t_user_${0..1}
# 分表策略
tableStrategy:
# 单分片键分表
standard:
# 自定义分片字段
shardingColumn: id
# 自定义分片算法名称,对应 {rules[0].shardingAlgorithms.user_table_hash_mod}
shardingAlgorithmName: user_table_hash_mod
# 数据分片算法定义集合
shardingAlgorithms:
# 自定义分片算法名称
user_table_hash_mod:
# 分片方式,HASH_MODE,按照 HASH 的方式对分片键进行操作,获取真实的物理表索引
type: HASH_MOD
props:
# 物理表分片数量
sharding-count: 2
props:
# 是否打印逻辑SQL和真实SQL,开发测试环境建议开放,生产环境建议关闭
sql-show: true数据分片核心概念
1. 表
表是透明化数据分片的关键概念。 Apache ShardingSphere 通过提供多样化的表类型,适配不同场景下的数据分片需求。
1.2 逻辑表
相同结构的水平拆分数据库(表)的逻辑名称,是 SQL 中表的逻辑标识。 例:订单数据根据主键尾数拆分为 10 张表,分别是 t_order_0 到 t_order_9,他们的逻辑表名为 t_order。
1.3 真实表
在水平拆分的数据库中真实存在的物理表。 即上个示例中的 t_order_0 到 t_order_9。
1.4 绑定表
指分片规则一致的一组分片表。 使用绑定表进行多表关联查询时,必须使用分片键进行关联,否则会出现笛卡尔积关联或跨库关联,从而影响查询效率。 例如:t_order 表和 t_order_item 表,均按照 order_id 分片,并且使用 order_id 进行关联,则此两张表互为绑定表关系。 绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。 举例说明,如果 SQL 为:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在不配置绑定表关系时,假设分片键 order_id 将数值 10 路由至第 0 片,将数值 11 路由至第 1 片,那么路由后的 SQL 应该为 4 条,它们呈现为笛卡尔积:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在配置绑定表关系,并且使用 order_id 进行关联后,路由的 SQL 应该为 2 条:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
1.5 广播表
指所有的数据源中都存在的表,表结构及其数据在每个数据库中均完全一致。 适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
1.6 单表
指所有的分片数据源中仅唯一存在的表。 适用于数据量不大且无需分片的表。
注意:符合以下条件的单表会被自动加载:
- 数据加密、数据脱敏等规则中显示配置的单表
- 用户通过 ShardingSphere 执行 DDL 语句创建的单表
其余不符合上述条件的单表,ShardingSphere 不会自动加载,用户可根据需要配置单表规则进行管理