1.日志文件是分成了哪几种?
Redo 保持持久性,Undo 保证原子性,Binlog 做复制,Relay 做从库,Slow log 查性能。
| 日志类型 | 属于层级 | 作用 | 是否存储引擎相关 |
|---|---|---|---|
| Redo Log(重做日志) | InnoDB 层 | 保证事务 持久性(崩溃恢复) | ✔ InnoDB 专有 |
| Undo Log(回滚日志) | InnoDB 层 | 实现事务 原子性 / MVCC(旧版本) | ✔ InnoDB 专有 |
| Binlog(二进制日志) | Server 层 | 主从复制、数据恢复(基于语句或行) | ✘ 所有引擎通用 |
| Relay Log(中继日志) | Server 层 | 从库复制用,从库重放主库 binlog,仅在slave 从库,- 通过 IO thread 将主库 binlog 拉下来写入 relay log SQL thread 再按 relay log 内容应用到从库 | ✘ 复制机制使用 |
| Slow Query Log(慢查询日志) | Server 层 | 用于 SQL 慢查询分析 | ✘ 通用 |
2.讲一下Binlog
“Binlog(归档日志)是 MySQL Server 层生成的日志,它主要记录了数据库所有执行过的修改操作(不包含查询)。
我认为它的核心价值主要体现在两点:主从复制和数据恢复。
具体来说,我想从三个维度展开:
1. 核心作用
-
主从复制:这是最常见的场景。Master 端开启 binlog,Slave 端通过 I/O 线程读取 Master 的 binlog 并写入自己的 Relay Log(中继日志),再由 SQL 线程执行重放,从而实现数据同步。
-
数据恢复:我们可以利用 binlog 将数据库恢复到任意时刻(Point-in-Time Recovery)。比如误删数据后,可以通过
mysqlbinlog工具解析日志,回放指定时间段的操作来找回数据。
2. 日志格式(这是工程中的重点) Binlog 有三种格式,各有优劣,生产环境通常推荐 ROW 或 MIXED:
-
Statement:记录原始 SQL 语句。
-
优点:日志量小,IO 压力小。
-
缺点:存在数据不一致风险(例如使用了
UUID()、NOW()等函数时,主从执行结果可能不同)。
-
-
Row(推荐):记录每一行数据的具体变化。
-
优点:数据绝对一致,最安全。
-
缺点:如果批量 update,日志量会非常大,消耗磁盘 IO 和带宽。
-
-
Mixed:混合模式。一般语句用 Statement,遇到可能导致不一致的函数时自动切换为 Row。
3. 刷盘机制与数据一致性(进阶点)
-
写入策略:Binlog 是追加写的,不会覆盖。可以通过
sync_binlog参数控制刷盘频率。-
设置为
0:由操作系统决定何时刷盘(高性能,但宕机可能丢数据)。 -
设置为
1:每次事务提交都刷盘(最安全,也是一般大厂的核心库配置)。
-
-
与 Redo Log 的区别:这是面试常考点。Redo Log 是 InnoDB 引擎特有的物理日志,循环写,用于 crash-safe;而 Binlog 是 Server 层通用的逻辑日志,追加写。
-
两阶段提交(2PC):为了保证 Redo Log 和 Binlog 的逻辑一致性,MySQL 内部使用了两阶段提交。简单说就是:先写 Redo Log (Prepare) → 再写 Binlog → 最后提交 Redo Log (Commit)。如果中间断电,MySQL 会检查 binlog 是否完整来决定是回滚还是提交,从而确保主库和从库的数据不偏离。”
3.UndoLog日志的作用是什么?
“Undo Log(回滚日志)是 InnoDB 存储引擎层生成的日志,它的核心作用有两个:保证事务的原子性 和 实现 MVCC(多版本并发控制)。
我想从这两个核心作用展开,并补充一下它的底层实现:
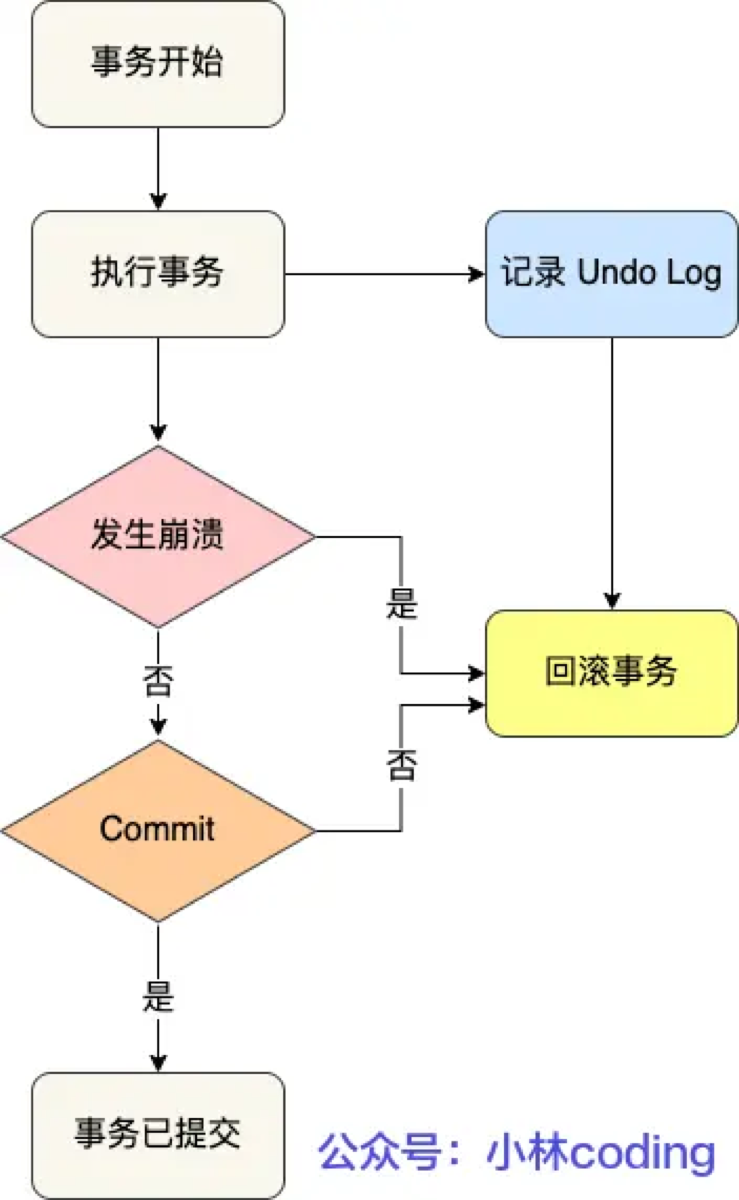
1. 保证事务的原子性(这是最基础的)
-
场景:当事务执行过程中发生异常(如宕机)或者用户显式执行
ROLLBACK语句时,需要将数据恢复到事务开始前的状态。 -
原理:Undo Log 记录的是逻辑日志,简单说就是记录了相反的操作。
-
你执行
INSERT,它就记一条DELETE。 -
你执行
DELETE,它就记一条INSERT。 -
你执行
UPDATE,它就记一条反向的UPDATE(把旧值改回去)。 通过回放这些日志,MySQL 就能完美地将数据‘回滚’。
-
2. 实现 MVCC(这是高阶考点)
-
场景:在‘可重复读’(RR)和‘读已提交’(RC)隔离级别下,实现快照读(非阻塞读)。
-
原理:Undo Log 中存储了数据的历史版本。
-
当一个事务修改数据时,InnoDB 不会直接覆盖旧数据,而是把旧数据拷贝到 Undo Log 中,并形成一个版本链(通过隐藏列
roll_pointer指针连接)。 -
当其他事务读取该数据时,通过 ReadView(读视图)规则,沿着 Undo Log 版本链找到该事务可见的历史版本。这就是‘多版本并发控制’的底层实现。
-
4.redo log怎么保证持久性的?
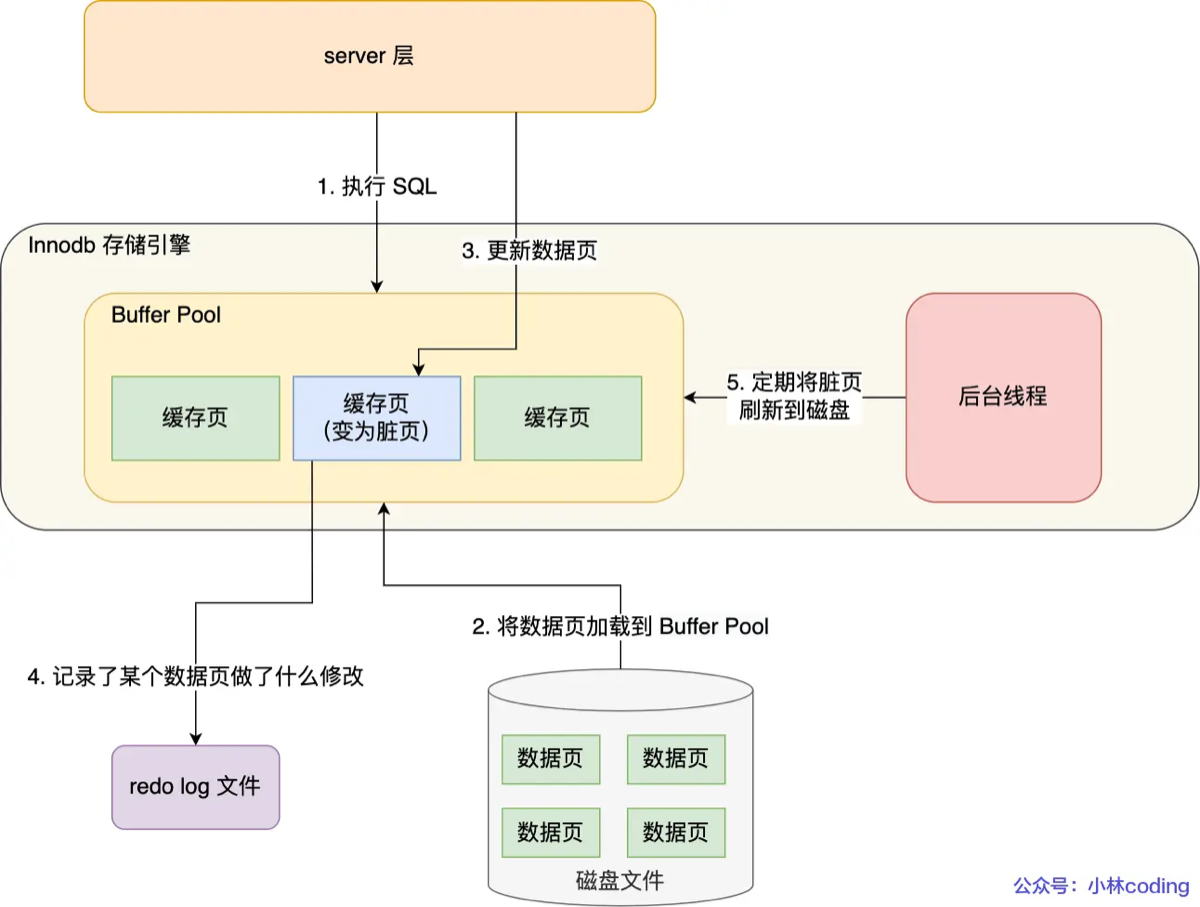
“Redo Log 保证持久性的核心技术是 WAL(Write-Ahead Logging,预写日志)。简单来说,就是先写日志,再写磁盘。只要日志安全落盘,事务就被视为已提交,哪怕数据页还在内存里没刷盘也没关系。
5.有了undolog为啥还需要redolog呢?
“虽然它们都叫‘日志’,但它们解决的是数据库 ACID 中完全不同的两个问题:Undo Log 负责‘原子性’(Atomicity),而 Redo Log 负责‘持久性’(Durability)。
我认为必须引入 Redo Log 的核心原因有两点:
1. 解决‘随机写’带来的性能瓶颈(核心原因)
-
如果没有 Redo Log:每次事务提交,InnoDB 都必须把修改后的数据页(Page) 刷到磁盘。
-
但是,数据页在磁盘上是分散的,这是随机 I/O,速度极慢。
-
而且,哪怕只改了一个字节,也要把整个 16KB 的页写回去,这是极大的写放大。
-
-
有了 Redo Log(WAL 技术):
-
事务提交时,我们只把修改记录写到 Redo Log 文件末尾。
-
这是顺序 I/O,速度非常快。
-
真正的‘落盘’(把脏页写回磁盘)可以由后台线程慢慢做。这就是 Write-Ahead Logging (WAL) 的精髓——先写日志,后写磁盘。
-
2. 保证 Crash-safe(崩溃恢复能力)
-
Undo Log 不够:Undo Log 记录的是‘怎么回滚’(逻辑日志)。但如果数据库突然断电,内存里的脏页(已修改但未写入磁盘的数据)丢失了,且 Undo Log 本身可能还没来得及持久化到磁盘,这时候光靠 Undo Log 是找不回数据的。
-
Redo Log 补位:Redo Log 是物理日志(记录‘在某个数据页上做了什么修改’)。数据库重启时,无论之前的事务是否提交,InnoDB 都会先重放 Redo Log,把内存中丢失的修改全部恢复出来(包括恢复 Undo Log 本身!)。
总结它们的关系(协作): 在系统崩溃恢复(Crash Recovery)时,两者是配合工作的:
-
先走 Redo Log:把所有数据页恢复到崩溃前的状态(此时可能包含未提交的事务)。
-
再走 Undo Log:扫描出那些‘未提交’的事务,利用 Undo Log 把它们回滚掉。
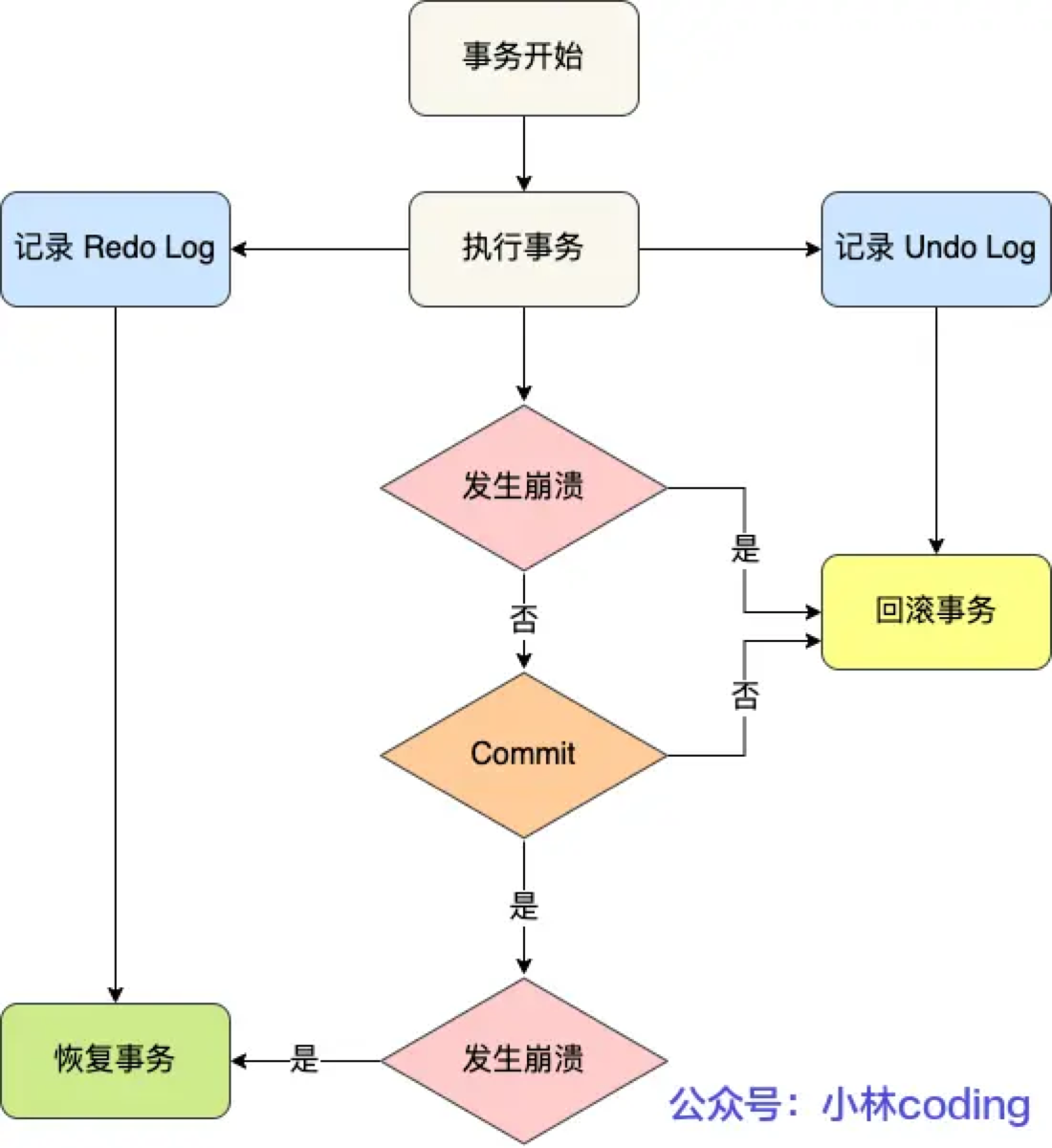
所以,Redo Log 是为了‘数据不丢’且‘写得快’,Undo Log 是为了‘写错了能悔棋’。缺一不可。”
6.能不能只用binlog不用relo log?
Binlog 的设计初衷是归档和复制(它不关心底层的数据页状态,他也不知道底层哪些脏页没被刷盘);而 Redo Log 的设计初衷就是Crash-safe和高性能写入。两者各司其职,缺了 Redo Log,InnoDB 就退化成了不支持事务且性能低下的存储系统。
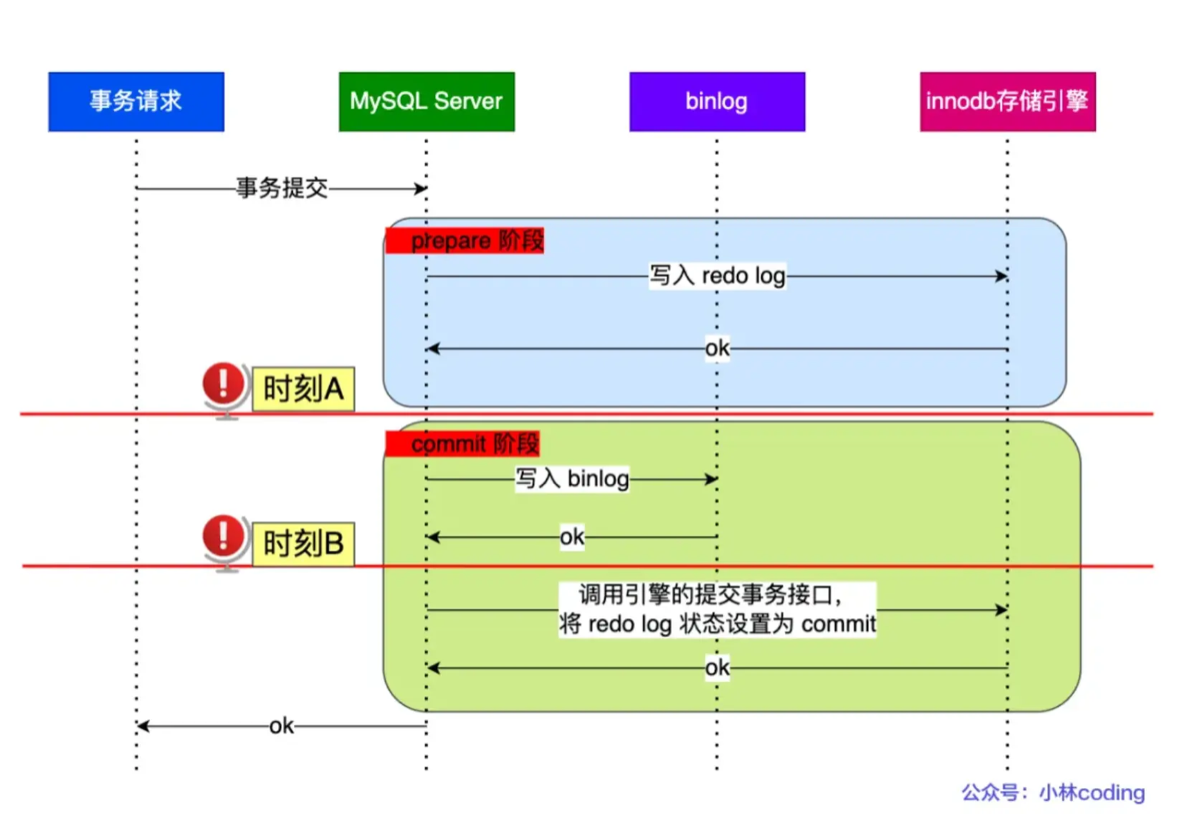
7.***binlog 两阶段提交过程是怎么样的?
“两阶段提交(2PC)的引入,是为了解决 Redo Log(存储引擎层) 和 Binlog(Server 层) 在写入时数据不一致的问题。
如果不用 2PC,要么先写 Redo Log 崩了导致‘主库有数据,从库没数据’,要么先写 Binlog 崩了导致‘主库没数据,从库多数据’。
MySQL 通过 XA 事务 将提交过程分为两个阶段:Prepare 阶段 和 Commit 阶段。
具体流程如下:
1. Prepare 阶段
-
InnoDB 将事务的更新操作写入 Redo Log,并将该事务标记为
PREPARE状态。 -
此时,数据已经在 Redo Log 里了,但对其他事务还不可见。
2. Commit 阶段
-
写 Binlog:MySQL Server 层将事务写入 Binlog 文件,并进行持久化(刷盘)。
-
写 Commit 标识:InnoDB 再次打卡,将 Redo Log 中的该事务状态更新为
COMMIT。
为什么这样能保证一致性?(这是最关键的 Crash-safe 逻辑)
数据库重启进行恢复时,会检查 Redo Log 中处于 PREPARE 状态的事务:
-
如果 Binlog 没写完(在写 Binlog 之前或写了一半时崩了):
-
MySQL 认为该事务失败,执行 回滚(Rollback)。
-
结果:主库没数据,从库也没数据(Binlog 没生成),一致。
-
-
如果 Binlog 写完了(在 Redo Log 改为 Commit 之前崩了):
-
MySQL 发现 Redo Log 虽然是
PREPARE,但 Binlog 是完整的(通过 XID 匹配)。 -
MySQL 认为该事务成功,执行 提交(Commit)。
-
结果:主库恢复数据,从库也有数据,一致。
-
一句话总结: 两阶段提交就像是‘一手交钱(Binlog),一手交货(Redo Log)’,以 Binlog 是否写入成功 作为最终成交的判断依据,从而保证了主从数据绝不偏离。”
8.update语句的具体执行过程是怎样的?

“执行一条 UPDATE 语句,本质上是 ‘先读后写’ 的过程,并且涉及 Server 层与引擎层(InnoDB)的深度交互以及**三大日志(Undo、Redo、Binlog)**的配合。
我可以把它拆解为两个大阶段:‘查找与加载’ 和 ‘修改与持久化’。
第一阶段:查找与加载(Server 层 → 引擎层)
-
连接器:建立连接。
-
分析器/优化器:解析 SQL,确定执行计划(比如决定走哪个索引)。
-
执行器:向 InnoDB 引擎索要数据。
-
Buffer Pool 命中:如果数据页已经在内存(Buffer Pool)中,直接返回。
-
缺页加载:如果不在内存,InnoDB 会先把数据页从磁盘读入 Buffer Pool。
-
行锁:在读取数据时,InnoDB 会给这行数据加排他锁(X锁),防止别人修改。
-
第二阶段:修改与持久化(引擎层核心逻辑) 拿到数据后,按照以下顺序执行(这也正是 WAL 和 两阶段提交 的具体体现):
-
写 Undo Log(存旧值):
- 在修改内存前,先将数据的旧值写入 Undo Log。这是为了万一事务失败可以回滚,或者为其他事务提供 MVCC 快照读。
-
更新内存(改新值):
- 在 Buffer Pool 中将数据更新为新值。此时内存是新的,磁盘是旧的,这页数据变成了脏页。
-
写 Redo Log(Prepare 阶段):
- 将对数据页的物理修改记录到 Redo Log Buffer,并根据策略刷盘,将事务标记为
PREPARE状态。
- 将对数据页的物理修改记录到 Redo Log Buffer,并根据策略刷盘,将事务标记为
-
写 Binlog(Server 层):
- MySQL Server 层生成逻辑日志(Binlog),并写入磁盘。
-
写 Redo Log(Commit 阶段):
- InnoDB 获取 Binlog 写入成功的信号后,将 Redo Log 中的事务标记为
COMMIT。
- InnoDB 获取 Binlog 写入成功的信号后,将 Redo Log 中的事务标记为
-
事务结束:
- 返回“更新成功”给客户端。
关键点总结(亮点): 整个过程中,真正的磁盘数据页(.ibd 文件)并没有立即更新。数据修改只发生在内存和日志里。真正的落盘操作(刷脏页)是由后台线程后续异步完成的(Checkpoint 机制),这正是 MySQL 高性能的关键。”
9.MySQL是如何保障数据不丢失的?
“保障数据不丢失(Durability),在 MySQL InnoDB 引擎中,是由 ‘日志机制’ 和 ‘页刷盘机制’ 共同构建的三道防线来实现的。
第一道防线:WAL + Redo Log(解决内存数据丢失)
-
机制:MySQL 使用 WAL(Write-Ahead Logging)技术,先写日志,再写磁盘。
-
原理:当事务提交时,我们强制将修改记录刷入 Redo Log(顺序写,速度快)。
-
作用:即使 MySQL 宕机,内存中的脏页还没来得及刷入磁盘,重启后也能通过重放 Redo Log 恢复数据,保证 Crash-safe。
第二道防线:Binlog + 两阶段提交(解决主从一致性)
-
机制:通过 2PC(Two-Phase Commit) 将 Redo Log 和 Binlog 绑定。
-
作用:保证了 Binlog(用于归档和从库)和 Redo Log(用于主库恢复)的逻辑一致性。如果 Binlog 没写成功,Redo Log 也会回滚,从而避免主库有数据而从库丢失数据的情况。
10.RedoLog是在内存里吗?
事务执行过程中,生成的 redolog 会在 redolog buffer 中,也就是在内存中,等事务提交的时候,会把 redolog 写入磁盘。
11.为什么要写RedoLog,而不是直接写到B+树里面?
写 Redo Log 的本质是利用 WAL(Write-Ahead Logging) 技术,把随即的、昂贵的磁盘写操作,转化为顺序的、廉价的日志写操作。让事务能以最快的速度提交,而真正的‘落盘’重活,留给后台线程慢慢做(Checkpoint)。”
- B+ 树的数据页是散落在磁盘的不同位置的。
- 一个事务可能修改多行数据,这些数据可能属于不同的 Page。如果要实时持久化,磁盘磁头就需要到处乱跳(寻道),这是典型的随机 I/O,性能极差(尤其是机械硬盘)。
写放大(Write Amplification)
-
直接写 B+ 树:
-
MySQL 的基本存储单位是页(Page,默认 16KB)。
-
即使你只是修改了一个整数(比如把
status从 0 改为 1,只占几个字节),为了持久化,你也必须把整个 16KB 的页完整写回磁盘。这是巨大的资源浪费。
-
-
写 Redo Log:
- Redo Log 只需要记录‘物理修改’本身(比如‘在 Page 10 的 Offset 20 处写入值 1’),日志体积非常小,写入效率极高。
11.mysql 两次写(double write buffer)了解吗?
第三道防线:Double Write Buffer(解决物理页损坏)
-
痛点:这是一个高阶细节。MySQL 的页大小是 16KB,而操作系统的文件系统页通常是 4KB。如果写到一半断电(比如只写了 4KB),就会出现 ‘页断裂’(Partial Page Write)。此时数据页本身坏了,Redo Log 是无法修复的(因为 Redo Log 记录的是‘在某页上做什么修改’,前提是页必须是完整的)。
-
机制:在把脏页写入最终的数据文件(.ibd)之前,先顺序写入到 Double Write Buffer(双写缓冲区,在系统表空间)。
-
作用:如果写数据文件时崩了,MySQL 可以从 Double Write Buffer 中找到完好的副本覆盖回去,然后再应用 Redo Log。