1.什么是Java里的垃圾回收?如何触发垃圾回收?
1. 什么是垃圾回收 (What is GC)? 垃圾回收(GC)是 JVM 的一种自动内存管理机制。 它的核心职责就是:识别并回收那些在堆内存(Heap)中不再被使用的对象(即‘垃圾’),从而释放内存空间,防止内存泄漏和溢出。
- 谁是垃圾? 通过‘可达性分析’算法判断,如果一个对象没有任何引用链能连接到 GC Roots,它就是垃圾。
2. 如何触发垃圾回收 (How to trigger)? GC 的触发主要分为 ‘被动触发(系统自动)’ 和 ‘主动触发(人工干预)’ 两种情况,绝大多数时候都是系统自动触发的。
-
情况 A:系统自动触发(主要方式)
-
Minor GC (Young GC): 当新对象创建时,如果 Eden 区空间不足(Allocation Failure),JVM 就会自动触发 Minor GC,清理年轻代。
-
Major GC / Full GC:
-
当 老年代 (Old Gen) 空间不足 时(比如大对象直接进入老年代,或者年轻代晋升的对象太多)。
-
当 元空间 (Metaspace) 达到阈值 时。
-
或者是为了应对担保失败(Handle Promotion Failure)时。
-
-
-
情况 B:人工主动触发(不推荐)
-
在代码中调用
System.gc()或Runtime.getRuntime().gc()。 -
注意: 这行代码只是给 JVM 发送一个**‘建议’**,告诉它‘现在的内存可能有点脏,建议你洗一洗’。但 JVM 不一定会立刻执行,它有自己的调度权。”
-
2.判断垃圾的方法有哪些?
“在垃圾回收领域,主要有两种算法来判断对象是否存活:
1. 引用计数法 (Reference Counting) —— Java 不用
-
原理: 给每个对象加一个计数器。每当有一个地方引用它,计数器加 1;引用失效时,计数器减 1。当计数器为 0 时,判定为垃圾。
-
优点: 简单,效率高。
-
缺点(致命伤): 无法解决‘循环引用’的问题。比如 A 引用 B,B 又引用 A,它俩的计数器永远是 1,永远不会被回收,导致内存泄漏。所以主流的 Java 虚拟机(如 HotSpot)都没有采用这种算法。
2. 可达性分析法 (Reachability Analysis) —— Java 正在用
-
原理: 以一系列被称为 ‘GC Roots’ 的对象作为起点,向下搜索。
-
判定: 如果一个对象到 GC Roots 之间没有任何引用链相连(即不可达),则证明此对象是无用的,会被判定为垃圾。
-
核心: 只要你跟 GC Roots 没关系,不管你们内部怎么互相引用(哪怕是 A 和 B 循环引用),统统都要被回收。”
形象比喻:葡萄串
为了解释 “可达性分析”,你可以用 “提葡萄” 来打比方:
-
GC Roots = 你的手。
-
对象 = 葡萄。
-
引用 = 葡萄梗。
过程: 你用手(GC Roots)抓住葡萄梗的主干,把整串葡萄提起来。
-
活对象: 凡是跟着手连在一起被提起来的葡萄,都是活的。
-
垃圾对象: 凡是掉在地上的散落葡萄(哪怕地上有两颗葡萄死死连在一起,属于循环引用),因为跟手断开了联系,所以统统是垃圾,会被扫地阿姨(GC)扫走。
3.深度考点:谁可以做 GC Roots?
面试官百分之百会追问:“那你刚才说的 GC Roots 具体包含哪些对象?”
候选人: “在 Java 中,可以作为 GC Roots 的对象主要有 4 种(记重点):
-
虚拟机栈(栈帧中的本地变量表)中引用的对象
- 大白话: 你当前方法里
new出来的那个局部变量(比如User u = new User();里的u)。只要方法没运行完,这个u指向的对象就是活的。
- 大白话: 你当前方法里
-
方法区中类静态属性引用的对象(静态变量)
- 大白话:
static修饰的变量(比如public static User user;)。它属于类,在这个类被卸载前,它引用的对象一直都是活的。
- 大白话:
-
方法区中常量引用的对象(常量)
- 大白话:
static final修饰的常量(比如字符串常量池里的引用)。
- 大白话:
-
本地方法栈中 JNI(即一般说的 Native 方法)引用的对象
- 大白话: C/C++ 代码里引用的 Java 对象。”
4.*垃圾回收算法是什么,是为了解决了什么问题?
面试官问这个问题,核心逻辑是:没有完美的算法,只有最适合的算法。
“在 JVM 中,为了解决不同的内存管理问题,主要演化出了 3 种核心算法。它们并不是谁替代谁的关系,而是分别适用于不同的场景(分代收集理论):
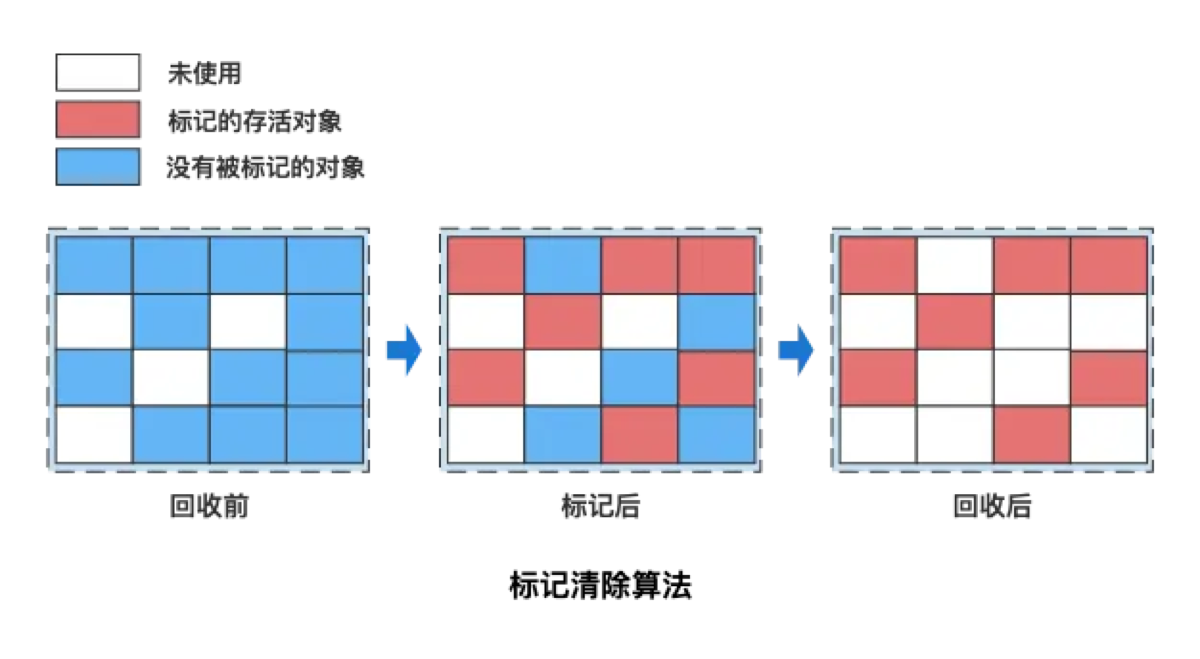
1. 标记-清除算法 (Mark-Sweep) —— 最基础
-
原理: 分为‘标记’和‘清除’两个阶段。先标记出所有需要回收的对象,然后统一清除掉。
-
-
解决了什么问题: 解决了最基本的‘自动化内存回收’问题。
-
带来了什么新问题: 内存碎片化。
- 回收后的内存像‘奶酪’一样坑坑洼洼,如果有大对象要分配,虽然总空闲内存够,但没有一块连续的区域能放下,导致提前触发 GC。
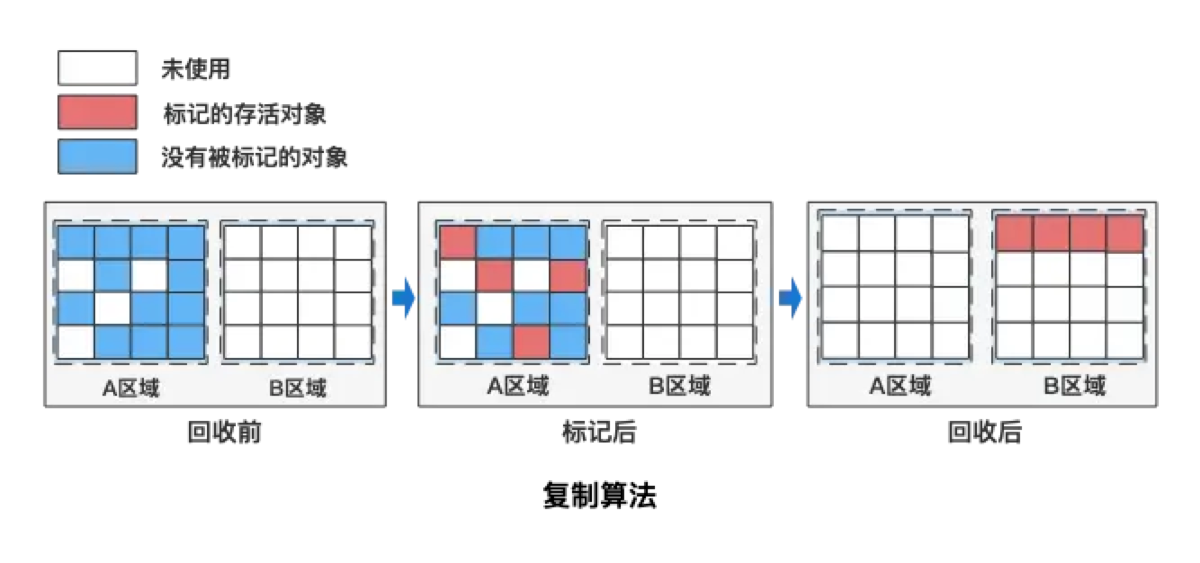
2. 标记-复制算法 (Copying) —— 解决碎片问题
-
原理: 把内存一分为二。每次只用其中一半。当这一半满了,就把活着的对象整齐地复制到另一半去,然后把这一半彻底清空。
-
-
解决了什么问题: 彻底解决了内存碎片问题(因为是顺序分配,只需移动堆顶指针)。
-
带来了什么新问题: 空间浪费。
- 你得牺牲一半的内存空间作为‘备用区’,利用率只有 50%。
-
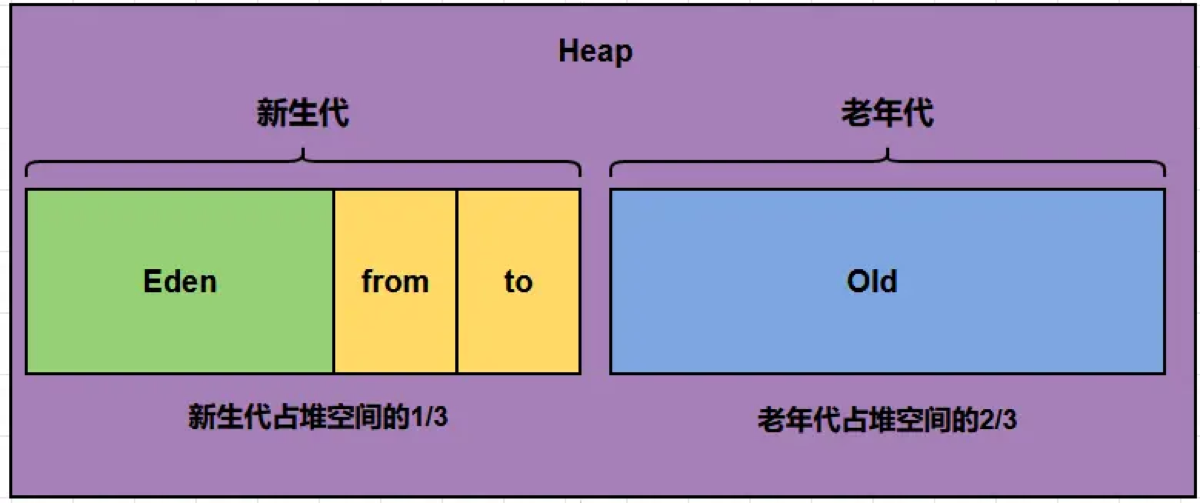
适用场景: 年轻代 (Young Gen)。因为年轻代对象 98% 都是‘朝生夕死’的,存活的很少,复制成本低,也不需要 1:1 的空间划分(通常是 Eden:Survivor = 8:1)。
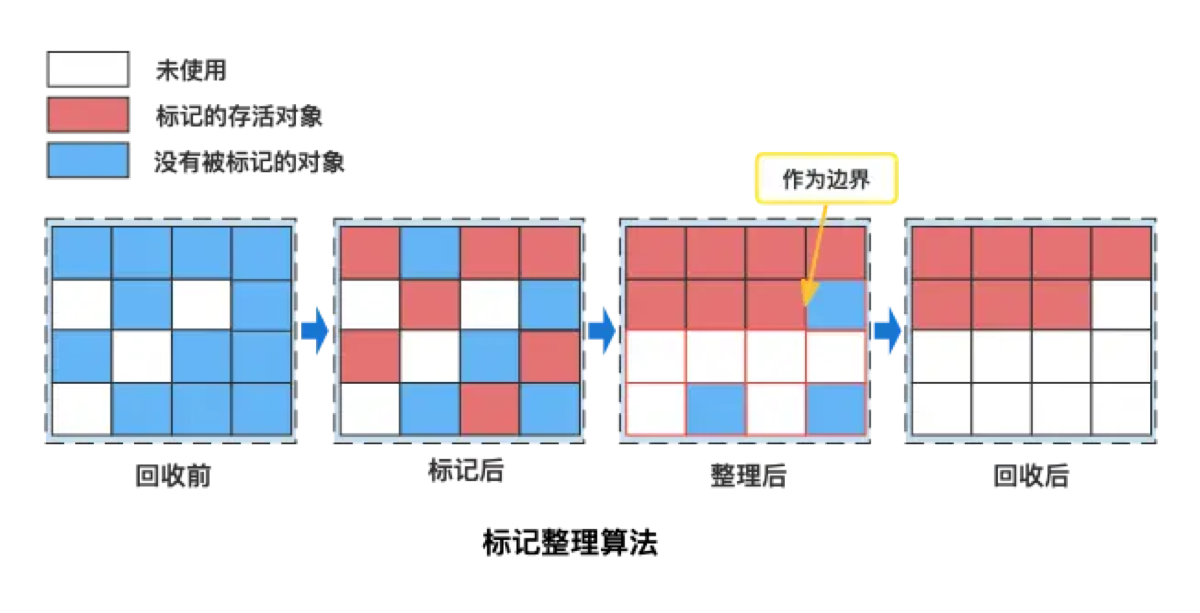
3. 标记-整理算法 (Mark-Compact) —— 解决空间浪费
-
原理: 标记过程和‘标记-清除’一样,但清除时不直接清理,而是把所有存活对象向内存的一端移动 (Compact),然后直接清理掉边界以外的内存。
-
-
解决了什么问题: 既解决了碎片问题,又解决了复制算法的空间浪费问题(不需要备用区)。
-
带来了什么新问题: 效率变低 (STW)。
- 移动对象是一个非常重的操作,且必须暂停用户线程(Stop The World),导致延迟增加。
-
适用场景: 老年代 (Old Gen)。因为老年代对象存活率高,不适合复制;且我们希望空间利用率高,不在乎稍微长一点的停顿。
总结:
JVM 采用了 ‘分代收集理论’,博采众长:
-
年轻代用复制算法(效率高,无碎片)。
-
老年代用标记-整理或标记-清除(省空间)。”
5.深度考点:CMS 为什么用“标记-清除”?
面试官可能会问一个刁钻的问题:
“既然标记-清除有碎片问题,为什么著名的 CMS 垃圾收集器(老年代)还要用它?”
回答:
“这是为了 ‘低延迟’。
-
标记-整理需要移动对象,移动对象就必须暂停整个程序(STW),这会导致用户感觉到卡顿。
-
CMS 的设计目标是让用户尽量感觉不到卡顿,所以它宁愿忍受内存碎片,也不愿去移动对象。
-
(补充): 当碎片实在太多导致大对象放不下时,CMS 会无奈地触发一次 Full GC(带整理功能的),这时的卡顿就会非常长。”
| 算法 | 关键点 | 适用区域 | 核心优势 | 核心劣势 |
|---|---|---|---|---|
| 标记-清除 | 标记+清除 | 老年代 (CMS) | 简单,不需要移动对象 | 碎片化 |
| 标记-复制 | Copy 到另一半 | 年轻代 | 无碎片,分配快 | 浪费空间 (存活率高时效率低) |
| 标记-整理 | 移动 + 整理 | 老年代 (G1/Parallel) | 无碎片且不浪费空间 | 移动对象慢 (STW) |
| [[1.内存模型#4堆分为哪几部分呢 | 4.堆分为哪几部分呢?]] |
6.垃圾回收器有哪些?
| 回收器 | 比喻 | 解释 |
|---|---|---|
| Serial单线程 GC | 单人扫把 | 只有一个阿姨打扫,她打扫时所有员工必须停止工作,出去罚站(STW)。 |
| Parallel 多线程 GC JAVA8 默认 | 多入扫把 | 请了一队阿姨进来,虽然还是要员工出去罚站,但因为人多,打扫得快(吞吐量高)。 |
| CMS 跟单线程 GC 一样,落伍被 G1 取代 | 吸尘器 | 阿姨可以在员工工作的时候,悄悄在脚边吸尘(并发)。虽然偶尔也要员工抬一下脚(短暂 STW),但大家基本不用停工。 |
| G1 | 网格化管理 | 把公司划分为很多个小工位(Region)。阿姨拿着小本本记下来哪个工位最脏,优先打扫脏的。而且老板规定:“每次只能扫 10 分钟”,阿姨就只扫最脏的那几块(可预测停顿)。 |
7.垃圾回收算法哪些阶段会stop the world?
“对于传统的串行(Serial)和并行(Parallel)收集器,它们在进行垃圾回收的整个过程都会触发 Stop The World。
但对于 CMS 和 G1 这类并发收集器,它们把复杂的 GC 过程拆分成了多个阶段,只有特定的几个阶段会 STW:
1. CMS 收集器 (老年代) CMS 的 4 个阶段中,有 2 个阶段 会 STW:
-
① 初始标记 (Initial Mark) —— [STW]
-
做什么: 只是标记一下 GC Roots 能直接关联到的对象。
-
耗时: 速度极快。
-
-
② 并发标记 (Concurrent Mark): 和用户线程一起跑,不 STW。
-
③ 重新标记 (Remark) —— [STW]
-
做什么: 修正并发标记期间,因为用户程序继续运行而导致标记产生变动的那一部分对象。
-
耗时: 比初始标记稍长,但远比并发标记短。
-
-
④ 并发清除 (Concurrent Sweep): 和用户线程一起跑,不 STW。
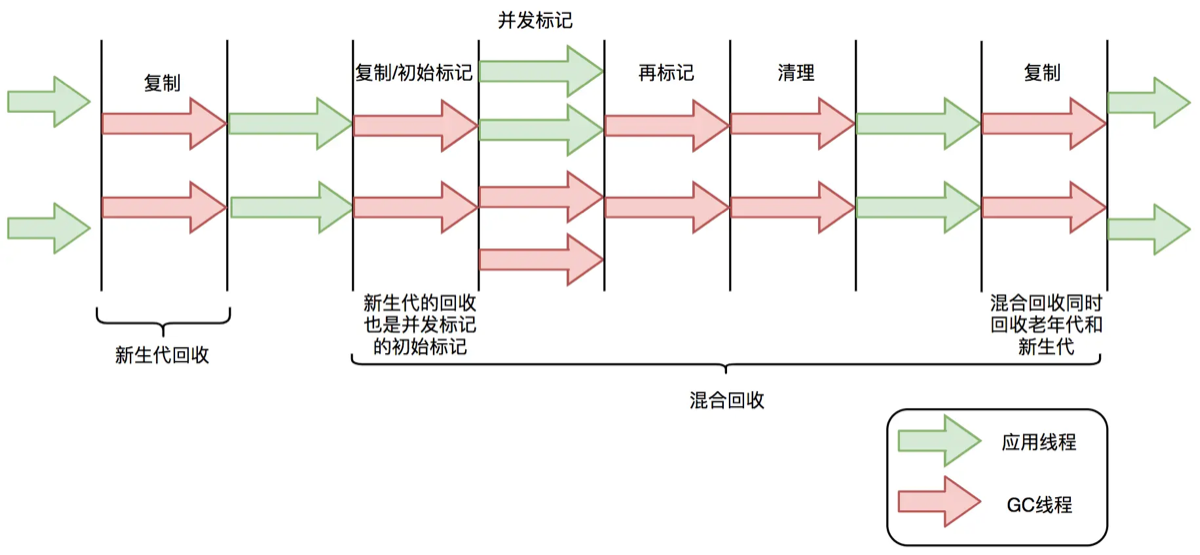
2. G1 收集器 G1 的运作主要分为 Young GC 和 Mixed GC。
-
Young GC: [全程 STW]。因为年轻代存活对象少,复制成本低,停顿时间短且可控。
-
Mixed GC (混合回收) 的并发标记周期: 类似 CMS,有 3 个阶段 会 STW:
-
① 初始标记 (Initial Mark) —— [STW]:标记 GC Roots,通常是搭 Young GC 的顺风车一起做的。
-
② 最终标记 (Remark) —— [STW]:处理并发阶段遗留的 SATB 记录(修正标记)。
-
③ 筛选回收 (Cleanup/Evacuation) —— [STW]:
-
G1 在最后挑选回收价值最高的 Region 进行对象复制和清理时,必须暂停用户线程(因为要移动对象,对象的地址变了,必须停下来改引用)。(瓶颈)
-
注:这与 CMS 不同,CMS 的清除阶段是并发的,因为 CMS 不移动对象(标记-清除),而 G1 移动对象(复制/整理)。”
-
-
8.minorGC、majorGC、fullGC的区别,什么场景触发full GC
“一、 三者的区别 (Definitions)
-
Minor GC (也叫 Young GC)
-
清理区域: 仅回收 年轻代 (Young Gen)。
-
特点: 触发非常频繁,速度非常快。
-
触发条件: 当年轻代的 Eden 区 满了,无法给新对象分配内存时触发。
-
-
Major GC (也叫 Old GC)
-
清理区域: 仅回收 老年代 (Old Gen)。
-
特点: 速度通常比 Minor GC 慢 10 倍以上。
-
注意: 只有 CMS 收集器 会有单独的 Major GC。对于其他收集器(如 Parallel Scavenge),通常说到 Major GC 时,指的其实就是 Full GC。
-
-
Full GC
-
清理区域: 整堆回收。清理 年轻代 + 老年代 + 方法区 (Metaspace)。
-
特点: 最慢,停顿时间(STW)最长,是生产环境的‘杀手’。我们要极力避免的也就是它。
-
二、 什么场景触发 Full GC? (Triggers) 除开代码显示调用 System.gc() 这种低级操作,触发 Full GC 的核心原因通常有 4 种:
-
老年代空间不足 (Old Gen Full) —— 最常见
-
大对象直接进入: 代码里
new了一个巨大的数组或 List,年轻代放不下,直接丢进老年代,结果老年代也放不下。 -
长期存活对象晋升: 年轻代的对象熬过了 15 次 GC,晋升到老年代,导致老年代满了。
-
-
元空间不足 (Metaspace Full)
-
原因: 系统加载了太多的类(Class),导致方法区爆满。
-
场景: 比如使用了大量的动态代理(CGLib、反射),或者 JSP 频繁生成新的类。
-
-
CMS 的‘并发模式失败’ (Concurrent Mode Failure)
-
场景: 使用 CMS 收集器时,垃圾还没清理完,用户线程又产生了大量的垃圾塞进老年代,或者产生了内存碎片导致大对象放不下。
-
后果: CMS 撑不住了,JVM 强制触发 Full GC(退化成 Serial Old),暂停所有线程进行单线程清理。
-
-
空间分配担保失败 (Handle Promotion Failure)
-
场景: 在准备触发 Minor GC 之前,JVM 检查发现:‘老年代剩余空间 < 年轻代所有存活对象总和’。
-
结果: 既然担不起这个风险,干脆直接触发 Full GC,把老年代腾一腾。”
-
9.垃圾回收器 CMS 和 G1的区别?
| 维度 | CMS (Concurrent Mark Sweep) | G1 (Garbage-First) |
|---|---|---|
| 作用区域 | 老年代 (需配合 ParNew) | 全堆 (年轻代 + 老年代) |
| 内存结构 | 传统的连续分代 | Region 分区 (物理不连续) |
| 核心算法 | 标记-清除 (有碎片) | 标记-整理 / 复制 (无碎片) |
| STW 控制 | 追求低延迟,但不可控 | 可建立预测模型 (软实时) |
| Full GC 风险 | 高 (碎片导致 Promotion Failed) | 低 (只有在内存极度紧张时) |
| 适用场景 | JDK 8 及以前的 Web 服务 | JDK 9+ 默认,大内存应用 (6GB+) |
“CMS 和 G1 是两个不同时代的并发收集器,它们的核心区别主要体现在 使用范围、内存布局 和 回收算法 上:
1. 使用范围不同
-
CMS: 是 老年代 (Old Gen) 专用的收集器。它必须配合年轻代的
ParNew或Serial收集器一起使用。 -
G1: 是 全堆 收集器。它不需要搭配其他收集器,自己就能搞定年轻代和老年代的回收。
2. 内存布局不同 (最直观的区别)
-
CMS: 依然遵循传统的 分代物理隔离。堆内存被死板地划分为连续的年轻代和连续的老年代。
-
G1: 引入了 Region (分区) 概念。它把堆内存切分成很多个大小相等的独立区域(Region)。虽然逻辑上还保留了年轻代和老年代的概念,但它们在物理上 不需要连续 了。
3. 回收算法不同 (致命伤)
-
CMS: 基于 标记-清除 (Mark-Sweep) 算法。
- 缺点: 会产生大量的 内存碎片。当碎片太多导致大对象无法分配时,会强制触发 Full GC(退化成单线程整理),这是 CMS 最大的痛点。
-
G1: 整体上看是基于 标记-整理 (Mark-Compact),局部(两个 Region 之间)看是基于 复制 (Copying) 算法。
- 优点: 没有任何内存碎片。它在回收时,是把一个 Region 里的存活对象‘复制’到另一个空 Region 里,清理得非常干净。
4. 停顿模型不同 (G1 的杀手锏)
-
CMS: 目标是 ‘尽可能缩短 STW’,但它无法控制停顿的具体时长。
-
G1: 支持 ‘可预测停顿 (Predictable Pause)’。你可以设置一个期望值(比如
-XX:MaxGCPauseMillis=200),G1 会根据这个目标,自动选择回收收益最高的几个 Region,只回收一部分垃圾,从而把停顿时间控制在你想要的范围内。”
10.什么情况下使用CMS,什么情况使用G1?
先看 JDK 版本
-
JDK 9+ ? → 默认 G1 (别折腾了)
-
JDK 8 ? → 接着看内存
-
内存 > 6GB ? → 选 G1 (大内存神器)
-
内存 < 4GB ? → 选 CMS (小巧轻便)
-
4GB ~ 6GB ? → 看疗效 (压测一下,谁好用谁
-
对停顿时间有极严格要求 (Predictable Pause):
-
场景: 比如金融交易系统、即时竞价广告,要求 GC 停顿必须控制在 200ms 以内。
-
原因: CMS 只能尽力做到低延迟,但无法保证具体时间。G1 可以设置
-XX:MaxGCPauseMillis,它会尽最大努力在指定时间内完成回收。
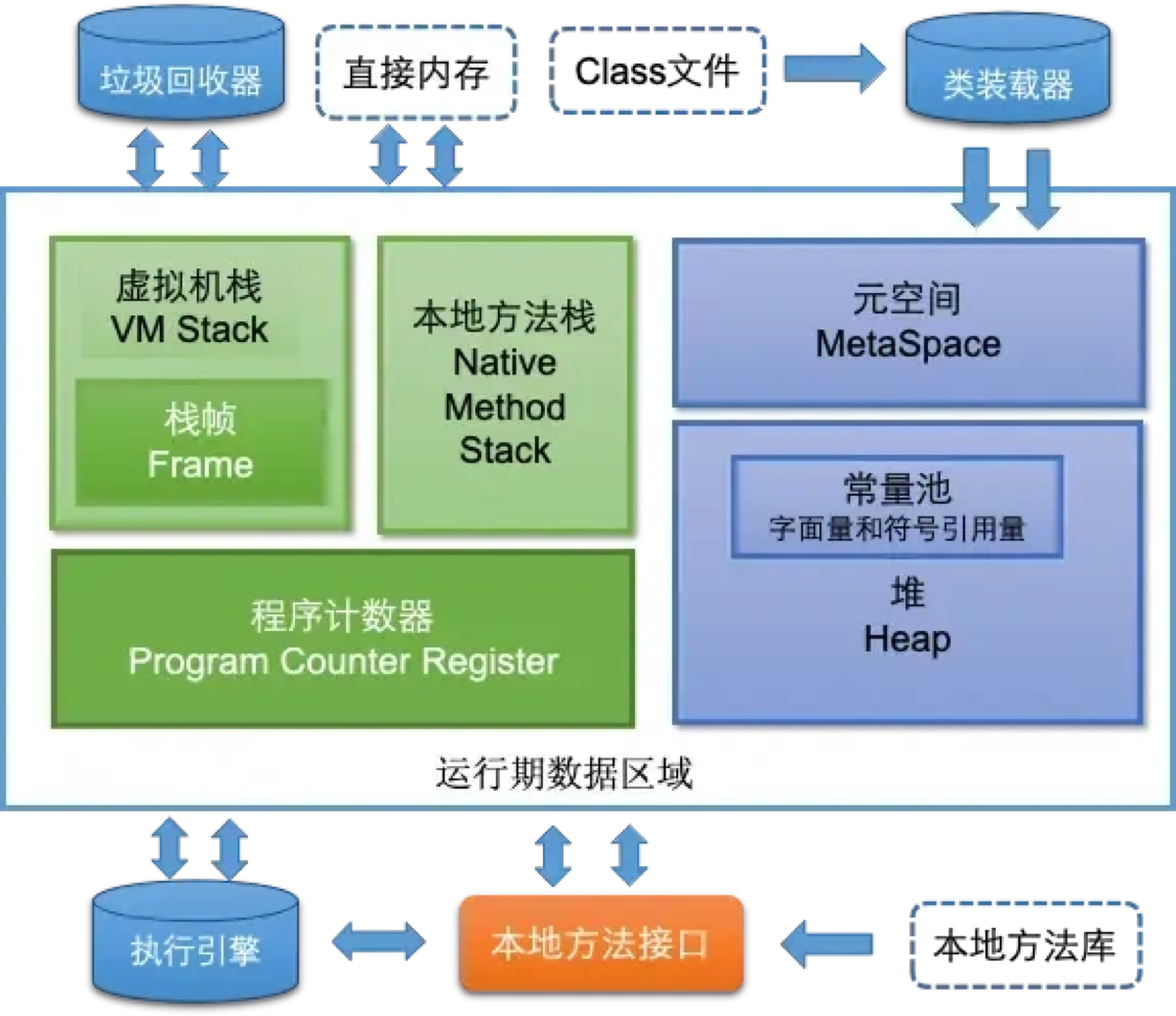
11.GC只会对堆进行GC吗?
“不是的。 虽然堆(Heap)是垃圾回收的主要战场(99% 的垃圾都在这),但 方法区 (Method Area) 也是垃圾回收的一部分。
我们可以把 JVM 的内存区域分为 ‘回收区’ 和 ‘不回收区’:
1. 垃圾回收的“主战场” —— 堆 (Heap)
-
这里存放着几乎所有的对象实例。
-
无论是 Minor GC 还是 Full GC,这里都是清理的重点。
2. 垃圾回收的“副战场” —— 方法区 (Method Area)
-
在 JDK 8 之后叫 元空间 (Metaspace),JDK 7 及之前叫 永久代 (PermGen)。
-
这里也会发生 GC(通常伴随着 Full GC),主要回收两类内容:
-
废弃的常量: 比如常量池里有一个字符串 “abc”,没有任何 String 对象引用它,它就会被清理。
-
不再使用的类 (Class Unloading): 这是难点。当一个类满足‘3 个严苛条件’时,它的 Class 对象和元数据才会被卸载。
-
3. 不需要 GC 的“禁区” —— 线程私有区域
-
包括 虚拟机栈 (VM Stack)、本地方法栈、程序计数器。
-
原因: 这些区域的生命周期是跟线程绑定的。线程开始,它们生成;线程结束,它们自动销毁。栈帧的出栈和入栈是非常确定的,内存会自动释放,所以根本不需要垃圾回收器来操心。”