-
Java 集合框架 (JCF) 是一个大概念,它包含了
Collection和Map两个独立的顶层体系。 -
它们虽然都是“容器”,但
Collection像是一个盒子,里面装的是一个个苹果;而Map像是一本字典,通过拼音(Key)查汉字(Value)。
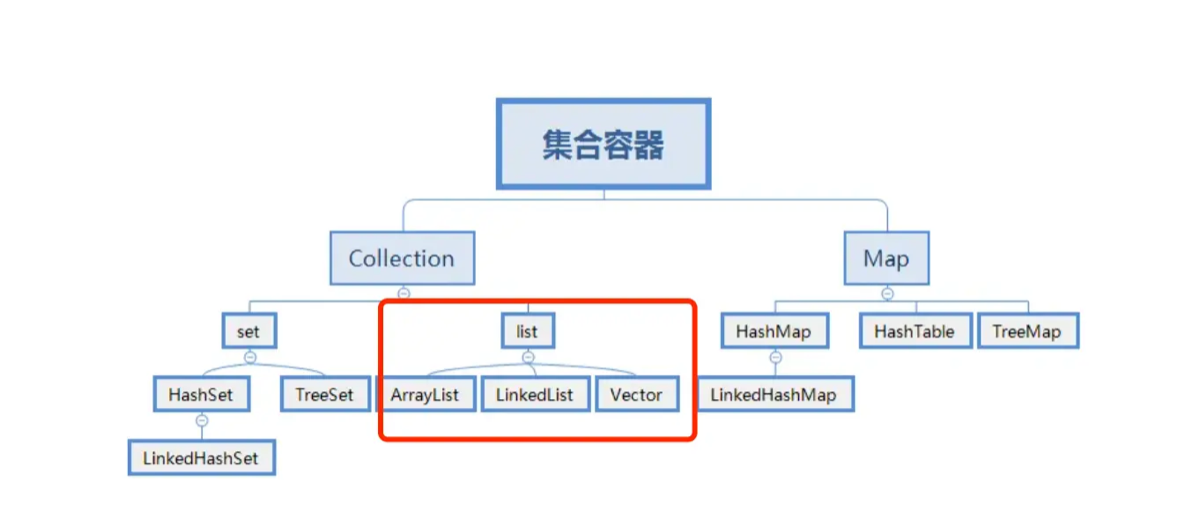
1.常见的List集合
-
首选建议: 90% 的单线程场景用
ArrayList;需要线程安全且读多写少用CopyOnWriteArrayList。 -
LinkedList 的尴尬: 实际上,在现代 CPU 架构下,由于
ArrayList内存连续性带来的 CPU 缓存命中率更高,即使是插入操作,ArrayList往往也比LinkedList快,除非是极大量的头尾操作。 -
避坑指南: 无论哪种 List,在遍历时进行
remove操作,都要注意 Fail-Fast 机制,建议使用Iterator或 Java 8 的removeIf。
2.讲一下java里面list的几种实现,几种实现有什么不同?
只有在需要频繁进行头尾操作时,我才会考虑 LinkedList。
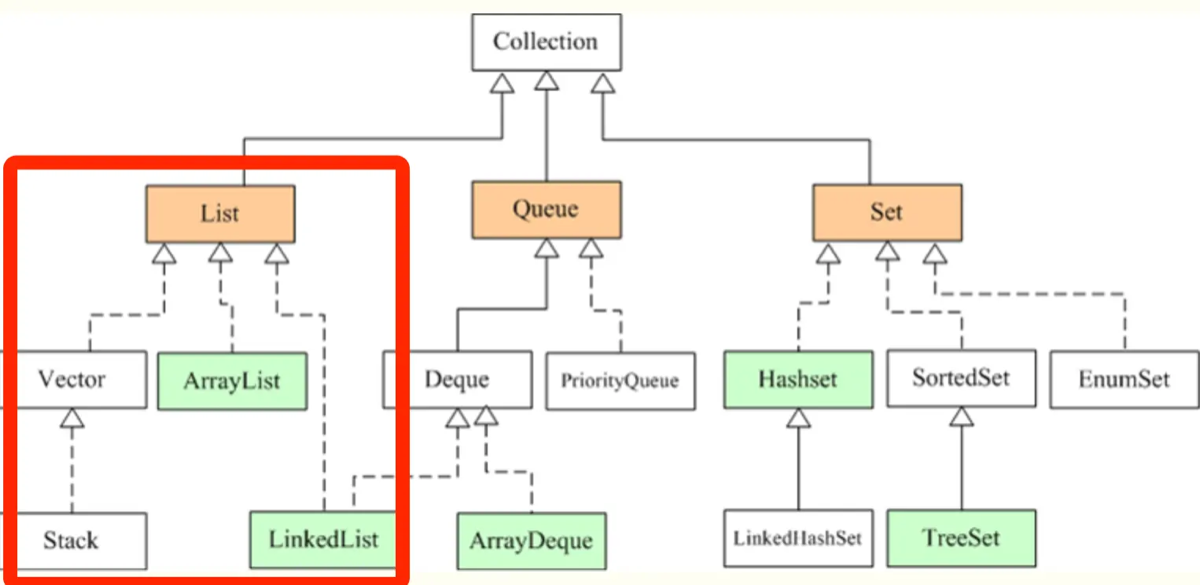
| 特性 | ArrayList | LinkedList | Vector |
|---|---|---|---|
| 底层数据结构 | 动态数组 (Object[]) | 双向链表 | 动态数组 |
| 随机访问 ($O(1)$) | 支持 (实现 RandomAccess) | 不支持 (需遍历) | 支持 |
| 增删效率 | 较低 (涉及数组拷贝/移动) | 较高 (仅需修改指针) | 较低 |
| 内存空间 | 连续空间,利用率高 | 碎片化,每个节点需额外存储指针 | 连续空间 |
| 扩容机制 | 1.5 倍 | 无需扩容 | 2 倍 |
| 线程安全 | ❌ 线程不安全 | ❌ 线程不安全 | ✅ 线程安全 |
1. ArrayList (最常用)
-
底层: 基于数组实现,默认初始容量为 10。
-
面试官喜欢的点: * 它实现了
RandomAccess标识接口,这意味着用下标访问元素是极快的。- CPU 缓存友好:由于数组内存连续,能更好地利用 CPU 缓存行(Cache Line)预取数据。
-
缺点: 中间插入或删除需要调用
System.arraycopy()移动元素,代价较高。
2. LinkedList
-
底层: 每个元素都是一个
Node对象,包含prev和next指针。 -
面试官喜欢的点: * 它不仅是
List,还实现了Deque(双端队列)接口,可以用作栈或队列。- 增删优势:在首尾进行操作时,效率极高。
-
缺点: 每次添加元素都要创建
Node对象,在大数据量下内存开销更大且容易产生内存碎片。
3.list可以一边遍历一边修改元素吗?
“在单线程环境下,如果是简单的条件删除,我会直接用 list.removeIf();如果逻辑复杂,我会使用 Iterator 手动控制。如果是高并发场景,为了保证读写不冲突且不抛出异常,我会选择 CopyOnWriteArrayList。”
-
核心结论:取决于具体的遍历方式 在遍历过程中直接调用
list.remove()或list.add()是危险的,通常会导致程序崩溃或逻辑错误。 -
特殊情况:普通 for 循环(下标遍历)
-
使用
for (int i = 0; i < list.size(); i++)这种方式删除元素不会抛出异常。 -
缺陷:由于删除后元素会整体前移,如果不手动处理
i--,会漏掉紧邻被删元素的下一个元素,产生业务 Bug。
-
4.list如何快速删除某个指定下标的元素?
| 特性 | ArrayList | LinkedList |
|---|---|---|
| 底层技术 | System.arraycopy (内存拷贝) | 指针修改 |
| 平均复杂度 | $O(n)$ | $O(n)$ (主要耗在查找上) |
| 缓存友好度 | 高 (数组内存连续,利用 CPU 缓存) | 低 (节点散落在堆中) |
| 适用场景 | 大多数场景,特别是尾部操作 | 只有在已经持有目标节点引用且需频繁增删时 |
“如果业务场景中不要求保证元素的原始顺序,最快删除 ArrayList 元素的方法是:将数组最后一个元素覆盖到待删除的下标位置,然后删除最后一个元素。这样能将 $O(n)$ 的删除操作优化为 $O(1)$。” |
5.*Arraylist和LinkedList的区别,哪个集合是线程安全的?
| 特性 | ArrayList | LinkedList |
|---|---|---|
| 底层数据结构 | 动态数组 | 双向链表 |
| 随机访问效率 | 极高 ($O(1)$),支持下标快速访问 | 较低 ($O(n)$),需要从头或尾遍历 |
| 插入/删除效率 | 较低 ($O(n)$),涉及元素移动和数组拷贝 | 较高 ($O(1)$),仅需修改前后节点指针 |
| 内存占用 | 较低。连续空间,但会有一定的预留空间浪费 | 较高。每个节点需额外存储 prev 和 next 指针 |
| CPU 缓存友好度 | 高。数组空间连续,能充分利用 CPU 缓存行 | 低。节点散落在堆内存中,缓存命中率低 |
结论:ArrayList 和 LinkedList 都不是线程安全的。
如果面试官问“如何获得线程安全的 List”,你应该给出以下分层回答:
-
早期方案(不推荐):
Vector。它的方法都加了synchronized,由于锁粒度太大,性能很差。 -
工具类包装:
Collections.synchronizedList(new ArrayList<>())。通过外部同步块实现,适合并发量极小的场景。 -
现代并发方案(大厂首选):
CopyOnWriteArrayList。它通过“写时复制”机制实现读写分离,读操作完全无锁,非常适合读多写少的并发场景。
6.Arraylist和vector 区别是什么?
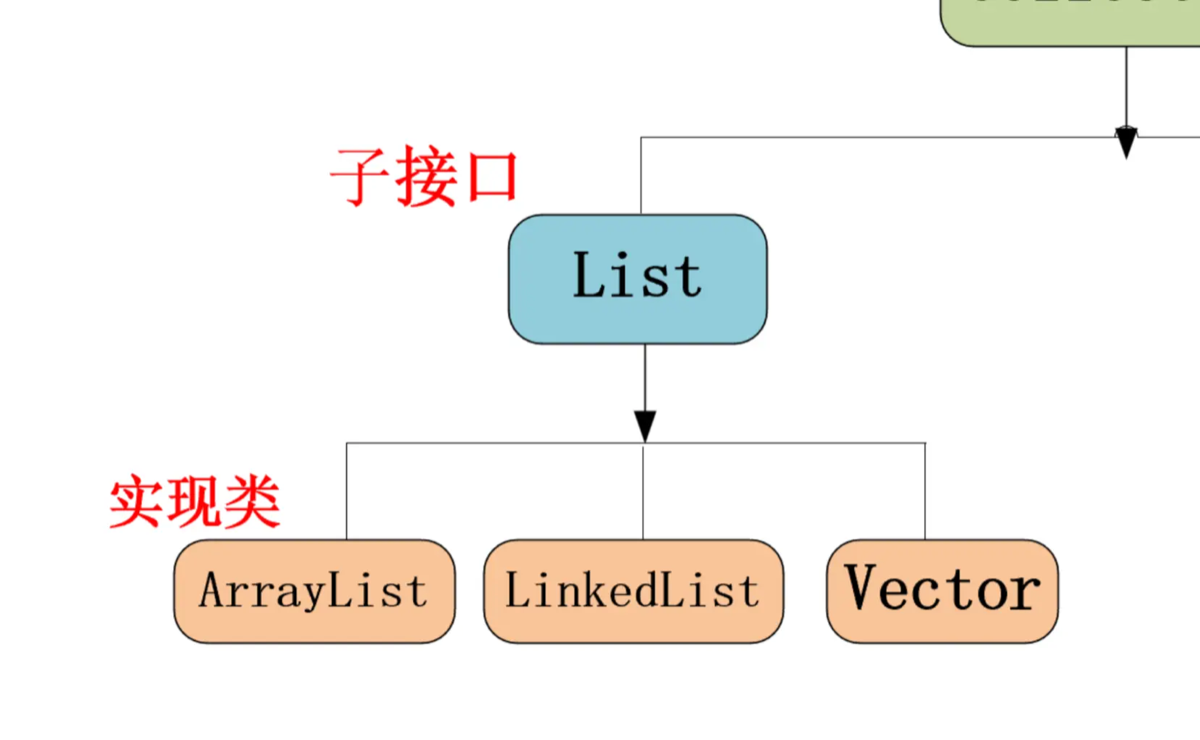
| 特性 | ArrayList | Vector |
|---|---|---|
| 线程安全性 | 非线程安全 | 线程安全(方法级 synchronized) |
| 性能 | 高(无同步开销) | 低(强制同步导致锁竞争) |
| 扩容倍数 | 1.5 倍(新容量 = 旧容量 + 旧容量 >> 1) | 2 倍(默认翻倍) |
| 底层结构 | 动态对象数组 | 动态对象数组 |
| 出现版本 | JDK 1.2(后期框架优化) | JDK 1.0(早期遗留类) |
7.ArrayList线程安全吗?把ArrayList变成线程安全有哪些方法?
不安全。
-
原因:
ArrayList的所有方法(如add()、remove())都没有同步机制(没有加锁)。 -
后果:多线程环境下执行
add()操作,可能会因为多个线程同时读取同一个size下标并尝试写入,导致数据覆盖或数组越界异常。
| 方法 | 实现机制 | 性能表现 | 面试官点评 |
|---|---|---|---|
| Vector | 方法级 synchronized | 极低。强制所有操作串行化。 | 不要用。属于 JDK 1.0 的遗留产物。 |
| Collections.synchronizedList | 内部维护一个 mutex 对象,通过同步块包装 | 较低。锁的粒度依然是整个列表对象。 | 备选方案。适合并发量极低、且必须使用标准 List 接口的场景。 |
| CopyOnWriteArrayList | 写时复制(Copy-on-Write)。写操作加锁并复制新数组,读操作完全无锁。 | 高 (读多写少)。读性能极佳,写操作内存开销大。 | 大厂首选。在高并发且读远多于写的业务场景(如配置缓存)中使用。 |
8.*为什么ArrayList不是线程安全的,具体来说是哪里不安全?
“ArrayList 的不安全主要体现在 add 等修改操作不是原子的。由于缺乏同步锁,多个线程会同时竞争修改 elementData 数组和 size 计数器,这不仅会导致数据覆盖,还可能因为扩容时的竞态条件导致数组越界异常。在高并发场景下,这种由于非原子性操作导致的状态不一致是致命的。”
9.*ArrayList的扩容机制说一下
1. 扩容的触发时机
-
当调用
add()方法添加元素时,ArrayList 会先计算所需的最小容量。 -
如果 当前 size + 1 > 底层数组长度,则会触发
grow()方法进行扩容。
2. 扩容的幅度(1.5 倍)
-
核心公式:
int newCapacity = oldCapacity + (oldCapacity >> 1);。 -
原理:利用位运算(右移 1 位相当于除以 2),将新容量设置为原容量的 1.5 倍。
-
设计用意:这是一个性能与空间的折中方案。1.5 倍既能保证扩容次数不会过于频繁,又能避免单次扩容产生过多的空间浪费。
3. 具体的执行步骤
-
计算新容量:按 1.5 倍计算,若仍不足,则直接使用所需的最小容量。
-
创建新数组:分配一个新的、容量为
newCapacity的Object[]数组。 -
数据迁移:通过
Arrays.copyOf()方法(其底层调用System.arraycopy())将原数组的数据一次性拷贝到新数组中。 -
引用切换:将
elementData指向新数组,旧数组由于失去引用会被 GC 回收。
10.线程安全的 List, CopyonWriteArraylist是如何实现线程安全的
核心实现机制:写时复制 (Copy-On-Write)
它的核心思想是:当你修改容器(添加、修改、删除)时,不直接在当前数组上操作,而是先复制出一个新数组。
写操作 (加锁 + 拷贝)
-
同步处理:当进行写操作时,会先使用
Lock锁进行同步,确保同一时间只有一个线程在修改。 -
创建副本:内部会拷贝出一份原数组的全新副本。
-
修改并指向:在新数组上完成修改操作,最后将集合内部的数组引用指向这个新数组。
读操作 (无锁)
-
直接读取:读操作不需要加锁,直接返回当前数组的结果。
-
读写分离:由于写操作是在新数组上进行的,而读操作在旧数组(或切换瞬间的旧引用)上进行,因此读写之间不会产生阻塞。
“CopyOnWriteArrayList 通过牺牲写性能和内存空间来换取极致的读性能。它利用 Lock 锁保证写的原子性,通过引用切换保证读的无锁化。在实际大厂业务中,我们通常将其用于白名单、系统配置、路由表等修改频率极低但查询量巨大的场景。”
___11.List<>里面填基本数据类型为什么会报错?
-
泛型仅支持对象类型:Java 集合(如
List<E>)使用了泛型,而泛型在底层是通过**类型擦除(Type Erasure)**实现的。 在编译后,所有的泛型参数都会被替换为Object,由于基本数据类型(如int、double)不属于Object体系,因此无法作为泛型的实际参数。 -
内存模型不同:基本数据类型直接存储在栈或对应的连续内存中,而 Java 集合存储的是对象的引用。 集合框架在设计之初就规定了元素必须是引用类型(即对象)。
“简单来说,集合只能存储对象(引用类型),不支持基本数据类型。 虽然我们可以通过
Integer等包装类配合自动装箱来解决这个问题,但这种转换会带来额外的内存开销。在高频计算或大数据量场景下,这也是为什么我们会优先考虑使用原生数组或专门针对基本类型的集合库(如 Trove 或 Fastutil)的原因。”
___12.List和数组如何互相转换?
1. List 转数组
主要使用 List 接口定义的 toArray 方法。
-
方式一:
list.toArray()-
特点:返回的是
Object[]数组。 -
缺点:获取后通常需要强制类型转换,不够优雅。
-
-
方式二:
list.toArray(T[] a)(推荐)-
特点:可以指定返回数组的类型(如
new String[0])。 -
优势:类型安全,且如果传入的数组空间足够,会直接在原数组上操作,效率更高。
-
2. 数组转 List
最常用的方法是使用 Arrays 工具类。
-
方式一:
Arrays.asList(array)-
注意点:这是最容易出坑的地方。
-
坑点 1:返回的是
java.util.Arrays$ArrayList,是Arrays的内部类,不支持 add/remove 操作,否则抛出UnsupportedOperationException。 -
坑点 2:数组和 List 共享引用。修改数组,List 也会变;反之亦然。
-
-
方式二:
new ArrayList<>(Arrays.asList(array))(推荐)-
特点:通过构造函数重新创建一个真正的
java.util.ArrayList。 -
优势:与原数组解耦,支持正常的增删改操作。
-
-
方式三:
Stream.of(array).collect(Collectors.toList())(Java 8+)- 特点:更加函数式编程风格,同样返回一个可变的 List。