⚠ Switch to EXCALIDRAW VIEW in the MORE OPTIONS menu of this document. ⚠ You can decompress Drawing data with the command palette: ‘Decompress current Excalidraw file’. For more info check in plugin settings under ‘Saving’
Excalidraw Data
Text Elements
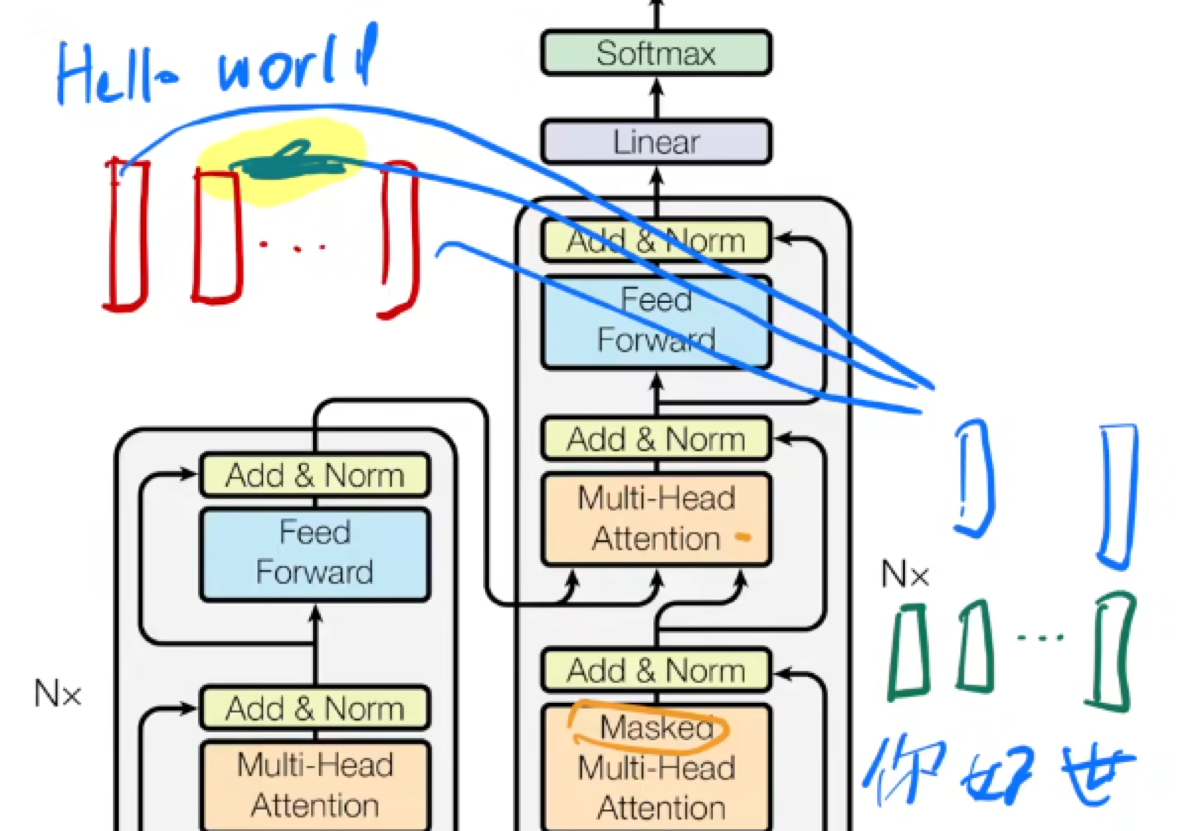
一个一个字输出
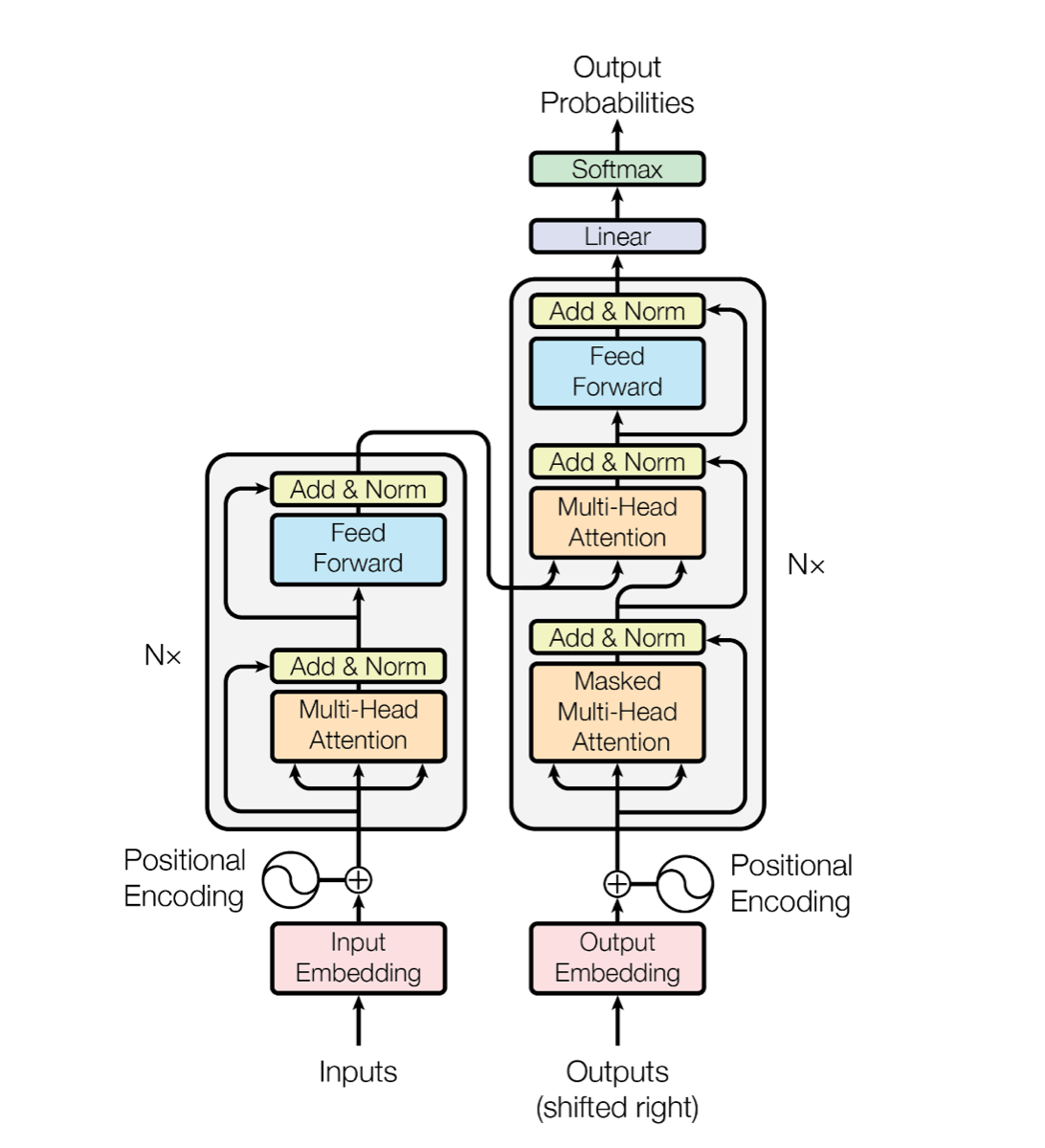
attention is all you need
嵌入层:将输入转换为向量
N个这样的层,可以认为是transformer块
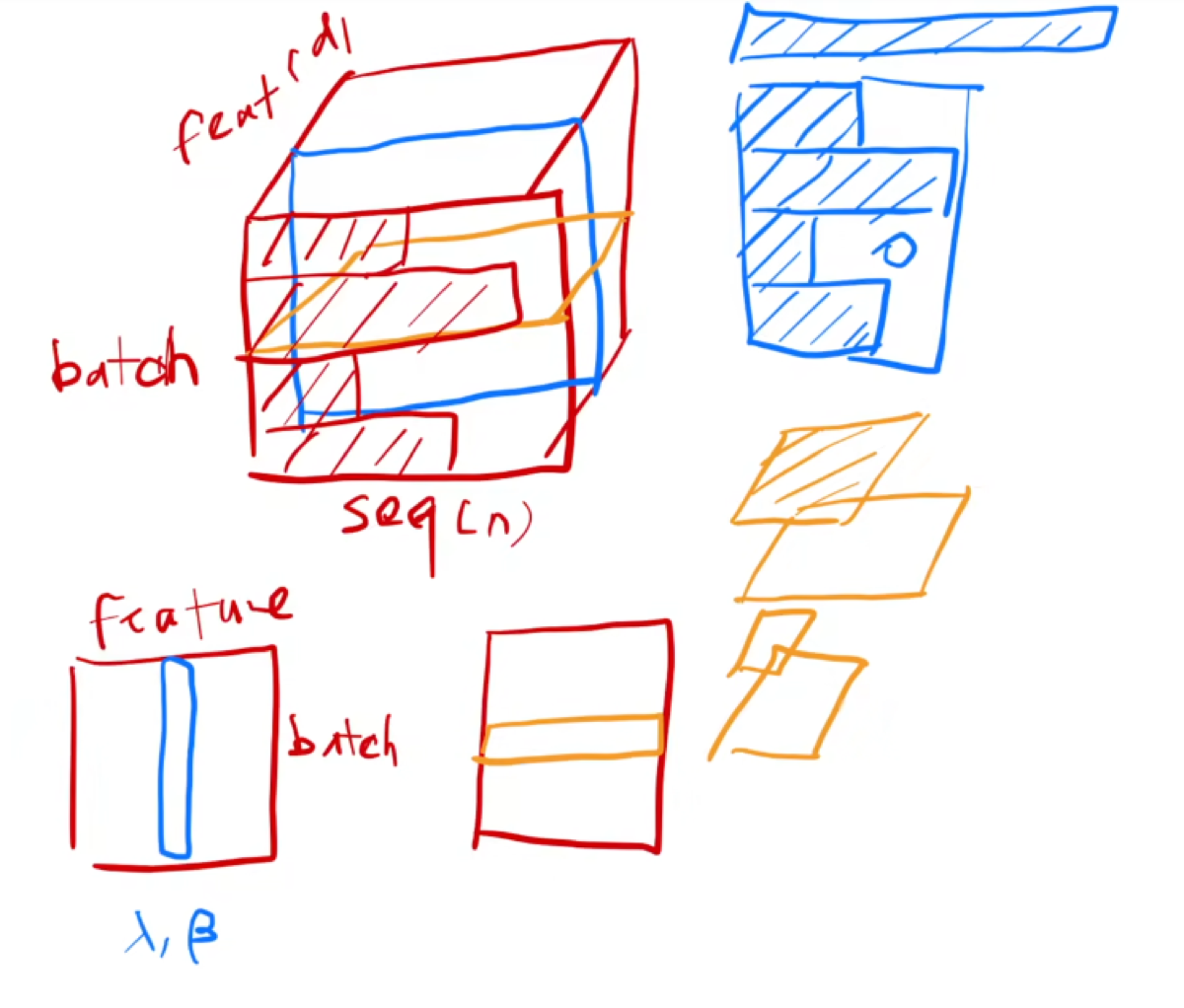
layerNormalize
batchNomalize
相对来说更有效
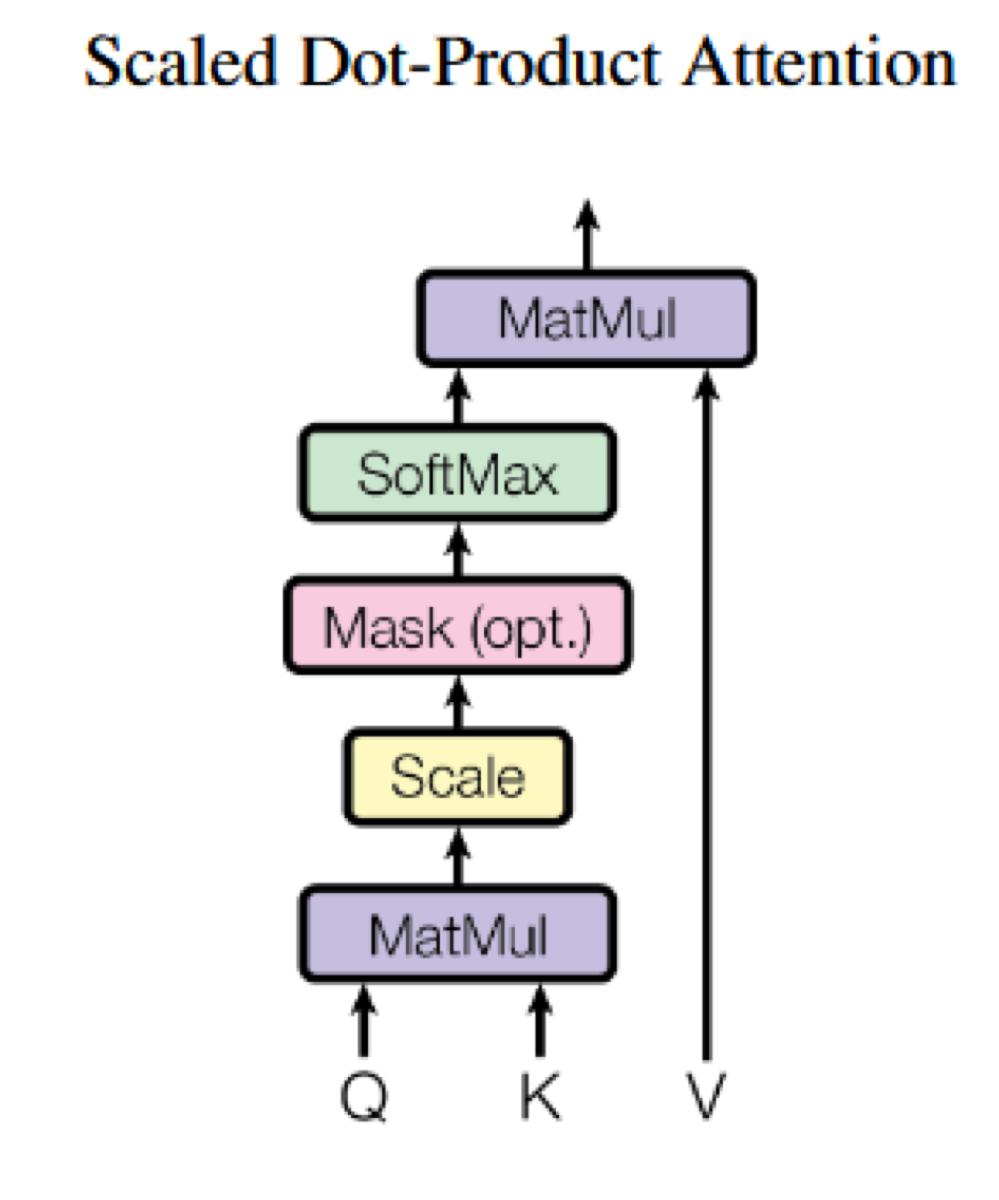
注意力机制
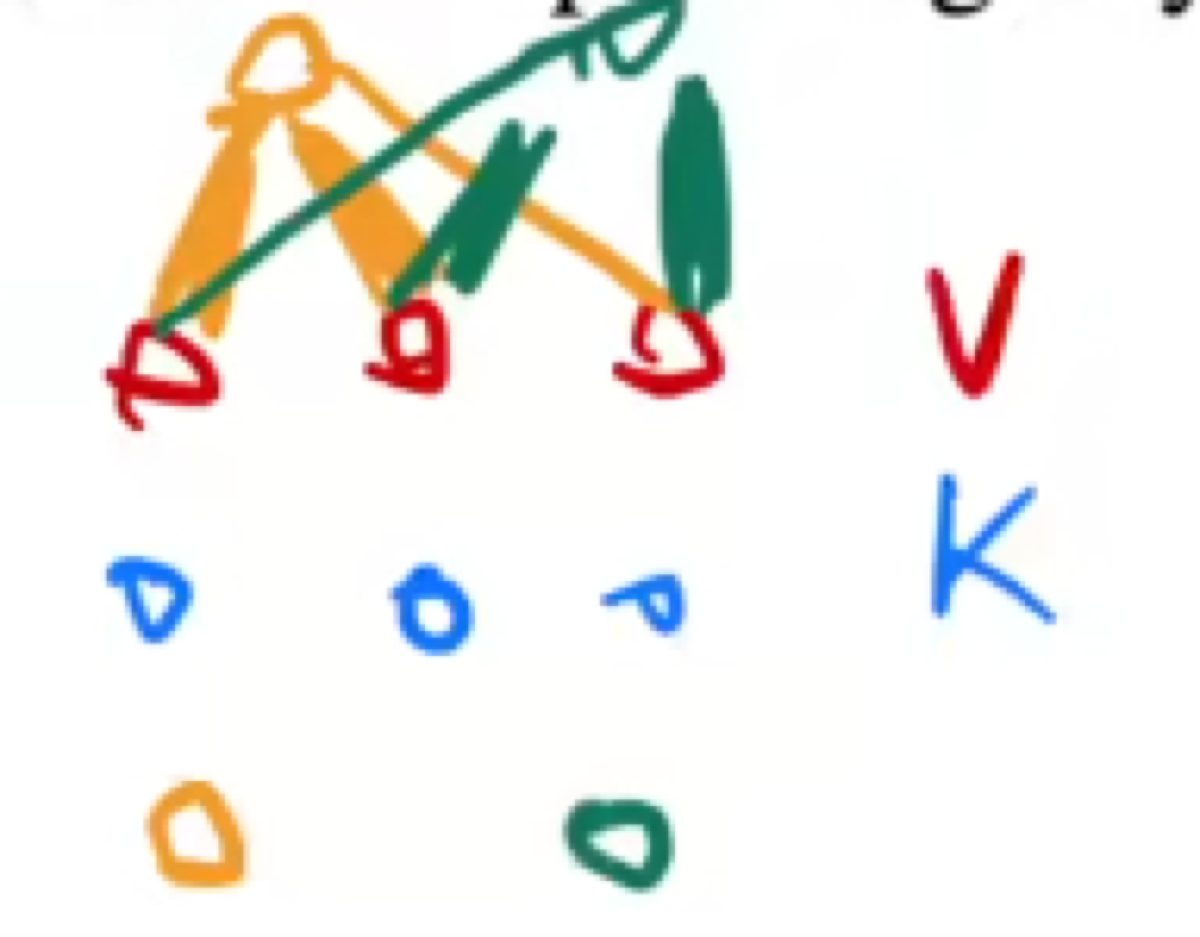
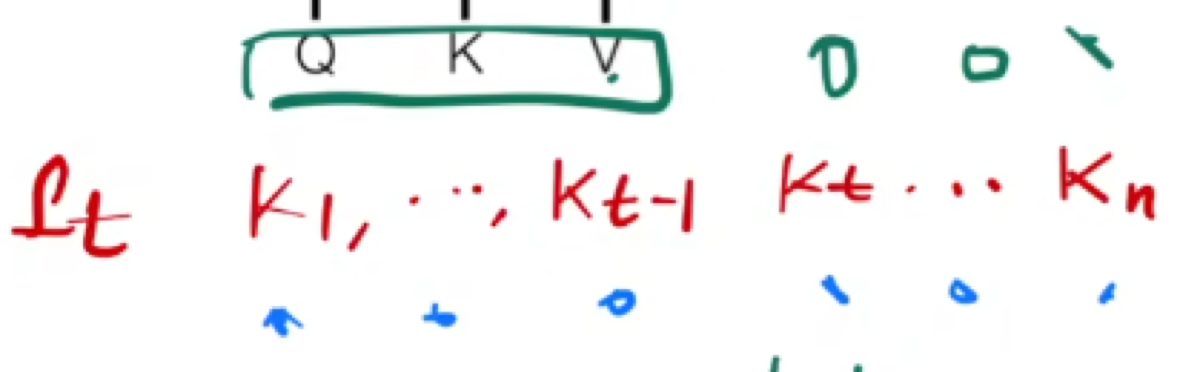
根据输入的query不同,v,和k的加权权重会不同
注意:q,v,k都是向量
矩阵向量点乘
矩阵向量点乘
除于dk,在进行softmax
mask:将t时刻后面的key全变为负大数
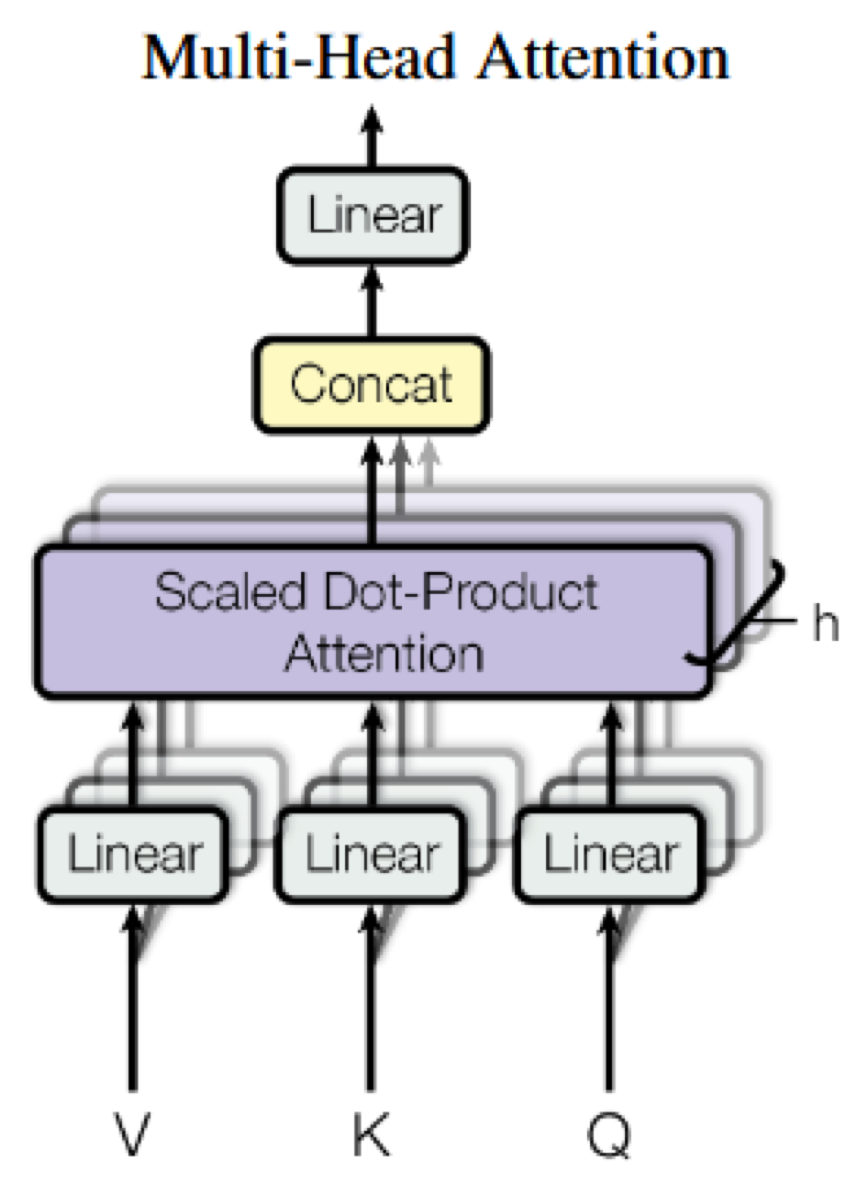
多头注意力机制
具体公式实现
假设h=8,就有8次机会改进投影时的参数
投影的维度+输出的维度/h,也就是vkq在分别投影时,需除以h
q
k
v
其实这里的qkv都是来自一个刚开始的输入 但经过多头注意力后,qkv会线性变换为不同的向量
如果vk与query越接近,其权重就会越大
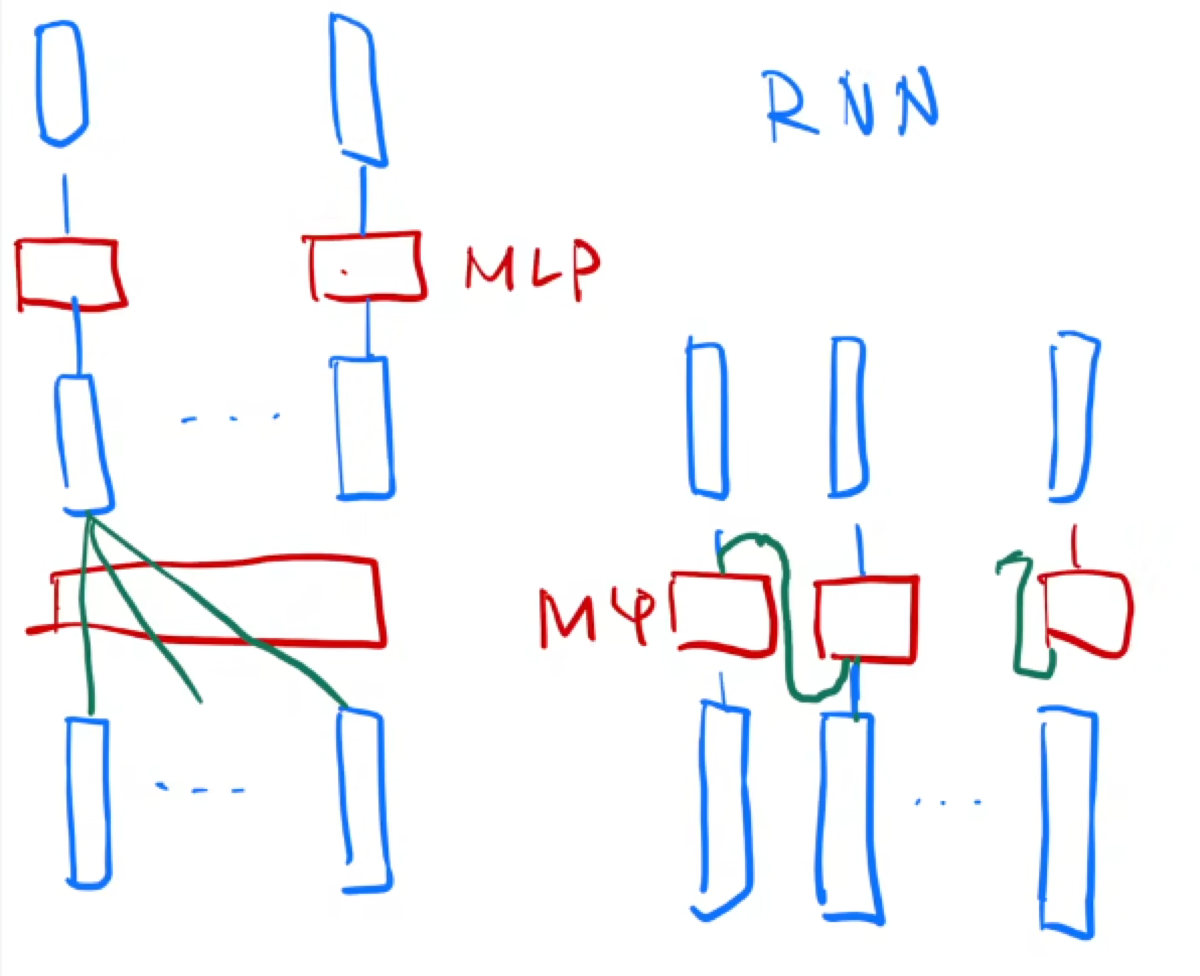
transformer与RNN对比
attention
通过positional Econding将时序信息与Embeding层相加以达到加入输入信息的目的
Embedded Files
5cd223e4af894477844f1c3f065a07a7dac93220: transformer.png
{kind=link}
7b5d161284aebe516758ba23d5bba865dbaea7e2: Pasted Image 20250513151345_661.png
{kind=link}
e5f1a2d1308a18c579276935b46406c438e20c47: Pasted Image 20250513152621_763.png
{kind=link}
d09847b3c146e7efea6d61cb310c3a324574eebb: Pasted Image 20250513154355_624.png
{kind=link}
9cd6fa5424f377c7a4c4e02fba732d2f87ef49a6: Pasted Image 20250513155439_137.png
{kind=link}
cc7881d2b9b5423f677e7c9605830116cbd5eef6: Pasted Image 20250513155851_709.png
{kind=link}
6004674d714e466f164703ff19c4347fb7949c15: Pasted Image 20250513160339_539.png
{kind=link}
59b12b0a8350653ee0b7984bc7eecb462c21d345: Pasted Image 20250513160604_621.png
{kind=link}
92076ffba4bccd57182b1a9a2ae4e570b28e0d49: Pasted Image 20250513162226_606.png
{kind=link}
8849c336eb5eea9b704a3e9fd76bbfa2e99c186c: Pasted Image 20250513164747_187.png
{kind=link}