1.介绍一下cap理论(分布式理论)
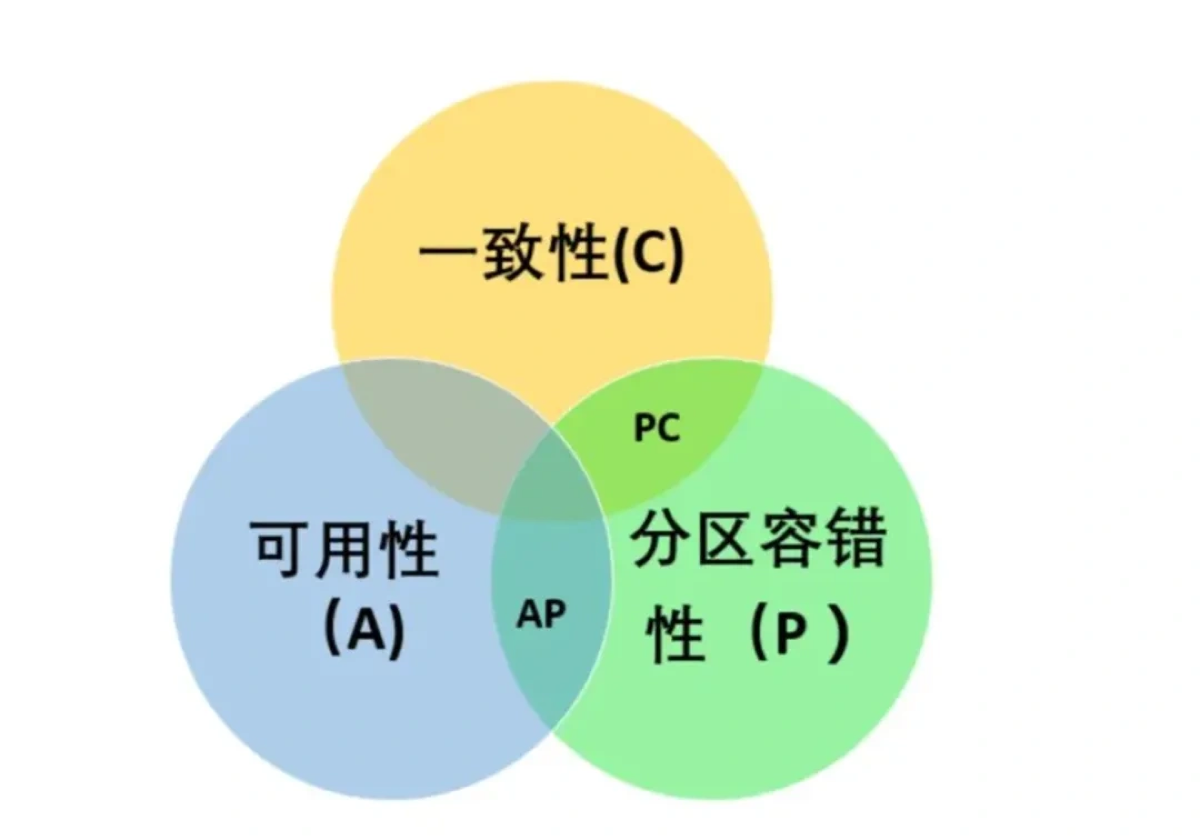
CAP 不是非黑即白,而是根据业务场景做取舍。
-
涉及到钱、库存、交易等核心数据,必须选 CP(宁可停机也不能算错)。
-
涉及到服务发现、新闻资讯、点赞数等非敏感数据,通常选 AP(用户体验优先,允许短暂的数据延迟)。”
2.用redis怎么实现分布式?
“在 Redis 中实现分布式锁,最基础的命令是 SETNX(Set if Not Exists)。但要写出一个生产环境可用的锁,必须满足互斥性、防死锁、原子性和误删保护。
我把实现分为三个阶段:
1. 基础版(面试入门):SET NX PX
-
命令:
SET lock_key unique_value NX PX 10000-
NX:保证互斥性(只有 key 不存在才能设置成功)。 -
PX 10000:设置 10 秒过期时间,保证防死锁(即使客户端崩了,锁也会自动释放)。 -
unique_value:客户端生成的唯一 ID(如 UUID),用于防误删(解锁时校验是不是自己的锁)。
-
-
解锁:必须使用 Lua 脚本。
- 原因:解锁需要两步(get 判断 value 是否是自己 → del 删除锁)。如果在 get 之后 del 之前发生 GC 停顿或锁过期被别人拿走了,就会误删别人的锁。Lua 脚本能保证这两步操作的原子性。
-- 解锁的 Lua 脚本
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end2. 进阶版(面试核心):Redisson 看门狗 (Watch Dog)
-
痛点:基础版有个大问题——锁过期时间不好设置。
-
设短了:业务还没跑完锁就过期了,出现并发安全问题。
-
设长了:业务崩了锁很久才释放,影响性能。
-
-
解决方案:使用开源框架 Redisson。
-
它有一个后台线程(看门狗),在锁即使过期前(默认 30s 的 1/3,即 10s),如果业务还没跑完,它会自动给锁续期。
-
这样既保证了业务能跑完,又保证了客户端宕机后锁最终能自动释放(因为看门狗线程也没了,不会再续期)。
-
3. 高阶版(大厂加分项):Redlock 算法
-
痛点:前面两种都是基于单点 Redis 的。如果 Master 节点挂了,锁还没同步到 Slave,主从切换后,新 Master 上没有这个锁,导致锁丢失(多个客户端同时拿到锁)。
-
解决方案:Redlock。
-
原理:搞 5 个独立的 Redis Master 节点。客户端尝试依次向这 5 个节点申请锁。
-
规则:只要能从**半数以上(N/2 + 1,即 3 个)**节点拿到锁,且总耗时小于锁的有效期,才算加锁成功。
-
注意:Redlock 实现复杂且性能有损耗,实际工程中,如果对锁的可靠性要求极高(如金融场景),通常建议直接用 Zookeeper 实现分布式锁,而不是死磕 Redis。
-
总结: 一般业务用 Redisson(SET NX + 看门狗) 就足够了,既简单又稳健。”
3.分布式事务的解决方案你知道哪些?
-
核心资金链(强一致、高并发):选 TCC。
-
周边通知类(解耦、高吞吐):选 RocketMQ 事务消息。
-
普通业务(快速开发):选 Seata AT 模式。”
4.阿里的seata框架了解过吗
Seata 的本质是**‘用 undo log 换取开发效率,用全局锁(Global Lock)换取数据隔离’**。 在绝大多数中小型业务中,我们直接使用 AT 模式,因为它能让我们像写本地事务一样写分布式事务,极大地降低了开发成本。”
AT 模式(Auto Transaction) 这是 Seata 最主推、使用最广泛的模式,因为它是对业务无侵入的(不需要像 TCC 那样写三个方法)。 它的核心原理是基于两阶段提交的改进:
-
第一阶段(执行并记录):
-
业务 SQL 执行。
-
关键点:Seata 会拦截 SQL,自动生成 Undo Log(回滚日志)。它会记录数据修改前的值(Before Image)和修改后的值(After Image)。
-
提交本地事务:不同于传统 XA 协议一直锁住资源,AT 模式在第一阶段就直接提交了本地数据库事务,释放了本地锁(这也是它性能高的原因)。
-
-
第二阶段(异步决议):
-
如果全局提交:TC 通知 RM,RM 只需要异步删除掉刚才记的 Undo Log 即可(极快)。
-
如果全局回滚:TC 通知 RM,RM 利用 Undo Log 中的 Before Image,生成反向 SQL 并执行,将数据恢复原状。
-
5.RPC的概念是什么?
“RPC(Remote Procedure Call)即远程过程调用。它的核心设计理念是:让调用远程服务就像调用本地函数一样简单,程序员不需要关心底层的网络通信、序列化、协议等复杂细节。
我认为理解 RPC 可以从以下三个维度展开:
1. 核心目标:透明化 在单体应用时代,我们直接通过 service.getUser() 调用本地方法。在微服务时代,UserService 可能在另一台服务器上。RPC 的作用就是把网络请求的‘苦力活’(建立连接、发送字节流、等待响应)封装起来,实现位置透明性。
2. 核心组件(RPC 的五脏六腑) 一个完整的 RPC 框架通常包含以下角色:
-
Client Stub (客户端存根):接收本地调用,负责将方法名和参数序列化成二进制数据。
-
Transport Layer (传输层):通常基于 TCP 或 HTTP/2,负责把二进制数据发给服务器。
-
Server Skeleton (服务端骨架):接收网络请求,将数据反序列化,并调用服务端真实的本地业务逻辑。
-
Registry (注册中心):如 Zookeeper 或 Nacos,告诉客户端‘远程服务在哪台机器上’。
3. 完整的调用流程 当我调用一个远程方法时,后台经历了这些步骤:
-
寻址:客户端去注册中心查询服务地址。
-
序列化:客户端存根将参数转为字节流(如 Protobuf、JSON)。
-
发送:通过网络发送请求。
-
解码执行:服务端解码后,根据方法名反射调用本地服务。
-
返回:结果原路返回并反序列化回本地对象。
4. 进阶对比:RPC vs HTTP (REST) 面试官经常会追问:‘既然有 HTTP 了,为什么还要 RPC?’
-
性能更好:RPC(如 gRPC, Dubbo)通常使用 Protobuf 或自定义二进制序列化,比 JSON 小得多;传输层常用 HTTP/2(多路复用)或自定义 TCP 协议,延迟更低。
-
强类型约束:RPC 通常有接口定义文件(如 IDL, Proto文件),代码生成后自带强类型校验,不像 REST 那样容易写错参数名。
-
服务治理更强:成熟的 RPC 框架(如 Dubbo)自带负载均衡、熔断、限流、重试等功能,更适合微服务集群。
总结: RPC 的本质是**‘封箱’和‘开箱’**。它在架构中解决了微服务之间通信的效率和复杂度问题。在 Java 生态中,我常用的实现是 gRPC (高性能/跨语言) 和 Dubbo (国内大厂主流/服务治理强)。”
5.和Feign 有什么不同
Feign 就是一种 RPC 的实现,它通过动态代理和注解,实现了‘调用远程方法像调用本地方法’的透明感。
| 特性 | 传统的 RPC (如 Dubbo / gRPC) | Spring Cloud Feign |
|---|---|---|
| 传输协议 | 通常基于 TCP 或 HTTP/2,追求极致性能。 | 基于 HTTP/1.1(底层通常是 HttpClient 或 OkHttp)。 |
| 序列化 | 二进制序列化(Protobuf / Hessian),体积小、解析快。 | 文本序列化(通常是 JSON),易读但体积大、效率相对低。 |
| 耦合度 | 强耦合。通常需要 Server 和 Client 共享同一个 IDL 文件或接口 Jar 包。 | 弱耦合。只要 URL 匹配、参数对得上就能调通。 |
| 适用场景 | 内部高并发、低延迟的服务间通信。 | 跨语言、标准 RESTful 风格的互联网通用调用。 |
6.zookeeper拿来做什么?核心的原理是什么?
不知道