1.Redis主从同步中的增量和完全同步怎么实现?
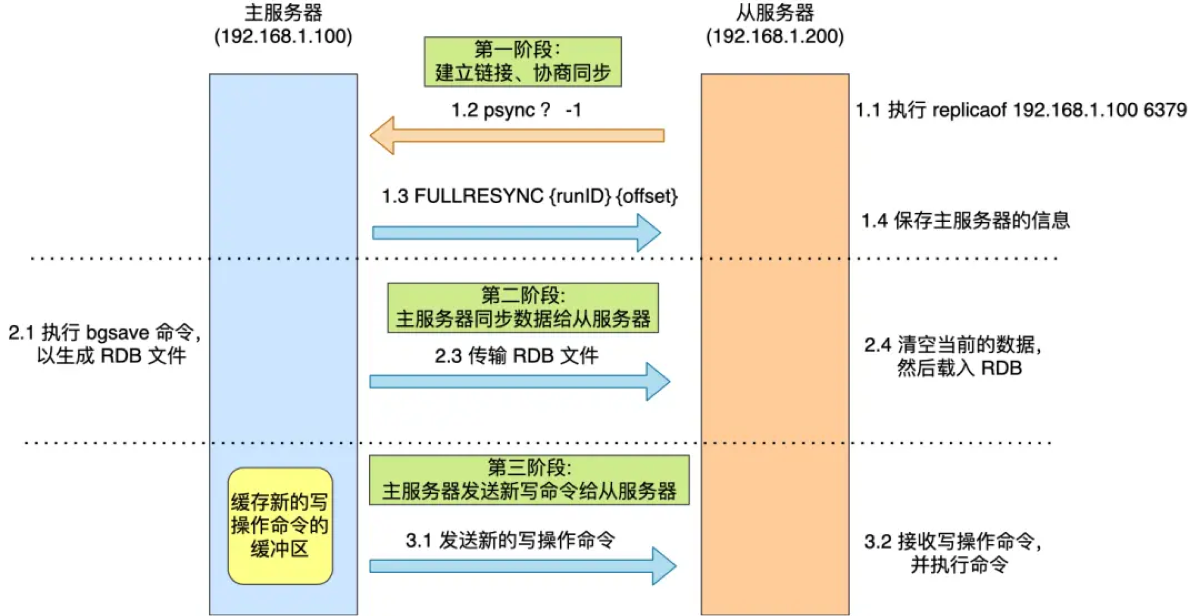
Redis 的主从同步分为两种情况:第一次连接时的“全量同步”和网络恢复后的“增量同步”。
-
全量同步 (Full Resynchronization):
-
触发时机: 从节点第一次连接主节点,或者主节点的复制积压缓冲区(repl_backlog)已满,无法进行增量同步时。
-
实现流程:
-
快照生成: 主节点执行
BGSAVE,生成 RDB 快照文件。 -
文件传输: 主节点将 RDB 文件发送给从节点,从节点清空旧数据并加载新数据。
-
缓存回放: 在生成和传输 RDB 期间,主节点会将收到的新写命令存入复制缓冲区 (Replication Buffer),最后再发送给从节点执行,以保证数据一致。
-
-
-
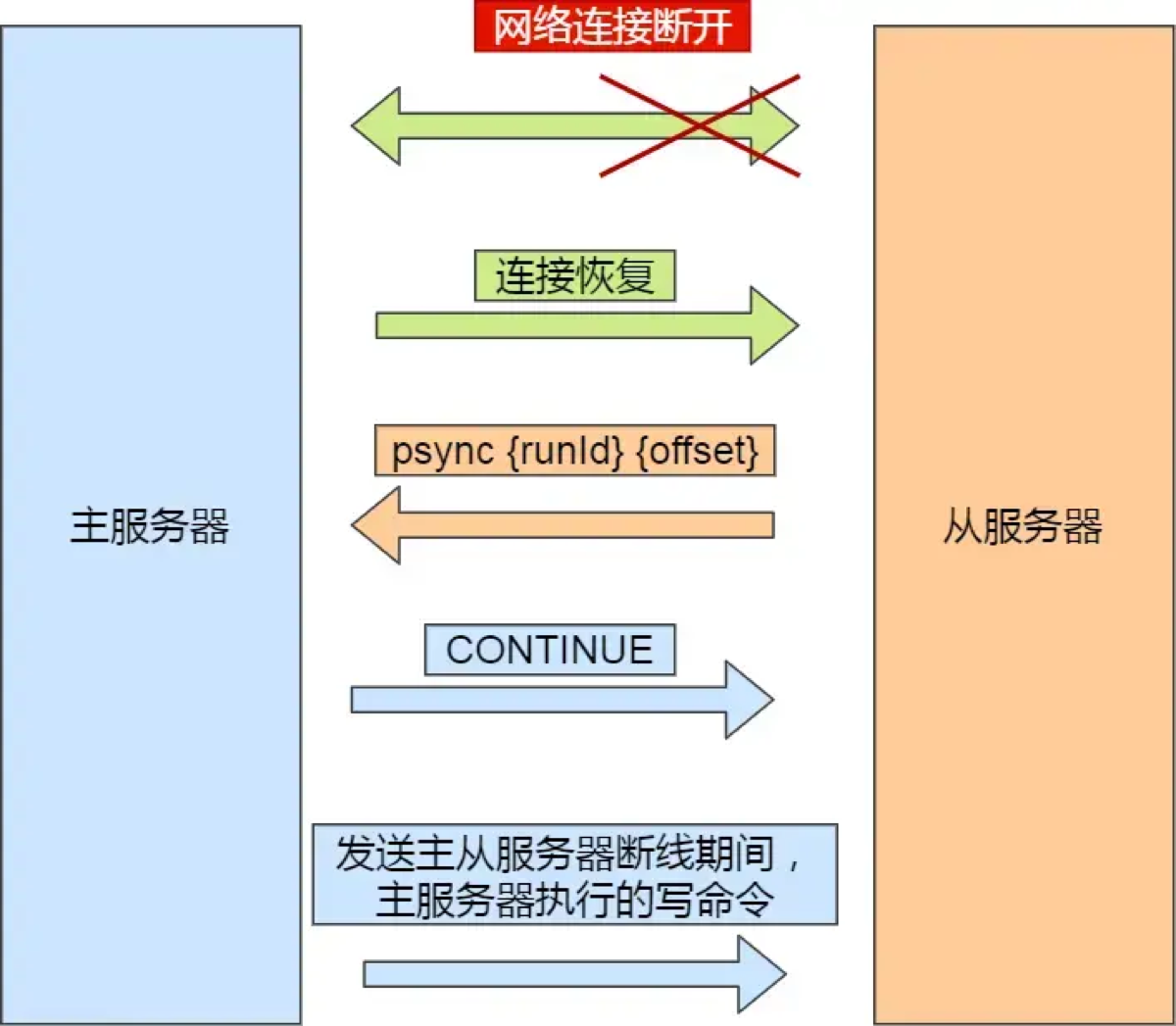
增量同步 (Partial Resynchronization):
-
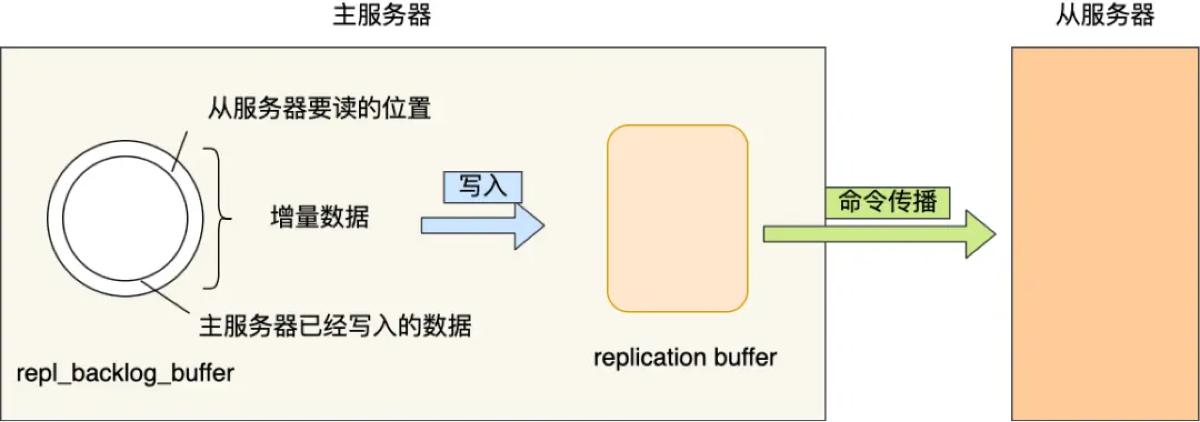
触发时机: 网络抖动导致主从断开,重连后,从节点的数据差距还在主节点的复制积压缓冲区 (repl_backlog_buffer) 覆盖范围内。
-
实现流程:
-
对比偏移量: 从节点发送自己的复制偏移量(offset)给主节点。
-
补发数据: 主节点检查该 offset 之后的数据是否还在环形缓冲区(repl_backlog)中。如果在,就只把这就部分差异数据(写命令)发送给从节点;如果不在(说明断太久了),则强制降级为全量同步。
-
-
一句话区别: “全量同步是‘传文件’(RDB),重在初始化;增量同步是‘传命令’(Command),重在断点续传。”
2.redis主从和集群可以保证数据一致性吗 ?
“不能。Redis 的主从复制是异步的,所以它只能保证最终一致性 (Eventual Consistency),无法保证强一致性。”
具体原因分析(核心痛点):
-
异步复制导致的数据丢失:
-
当客户端向主节点(Master)写入数据后,主节点会先返回 OK 给客户端,然后再异步将命令同步给从节点(Slave)。
-
风险: 如果主节点在“返回 OK”之后、“发送命令给从节点”之前的这短短一瞬间宕机了,这部分数据就永远丢失了,因为新的主节点(原来的从节点)根本不知道这笔数据的存在。
-
-
脑裂 (Network Partition) 问题:
-
当网络发生分区时,可能出现“一个集群有两个主节点”的情况(旧主节点未被隔离,新主节点已被选举)。
-
客户端如果继续向旧主节点写入数据,这部分数据在网络恢复后,会因为旧主节点降级为从节点而被覆盖(丢失)。
-
如何尽可能提高一致性?(补救措施): “虽然做不到绝对的强一致,但可以使用 WAIT 命令。它可以阻塞当前客户端,直到数据同步给指定数量的从节点后才返回,从而极大降低数据丢失的概率(牺牲了可用性)。”
3.哨兵机制原理是什么?
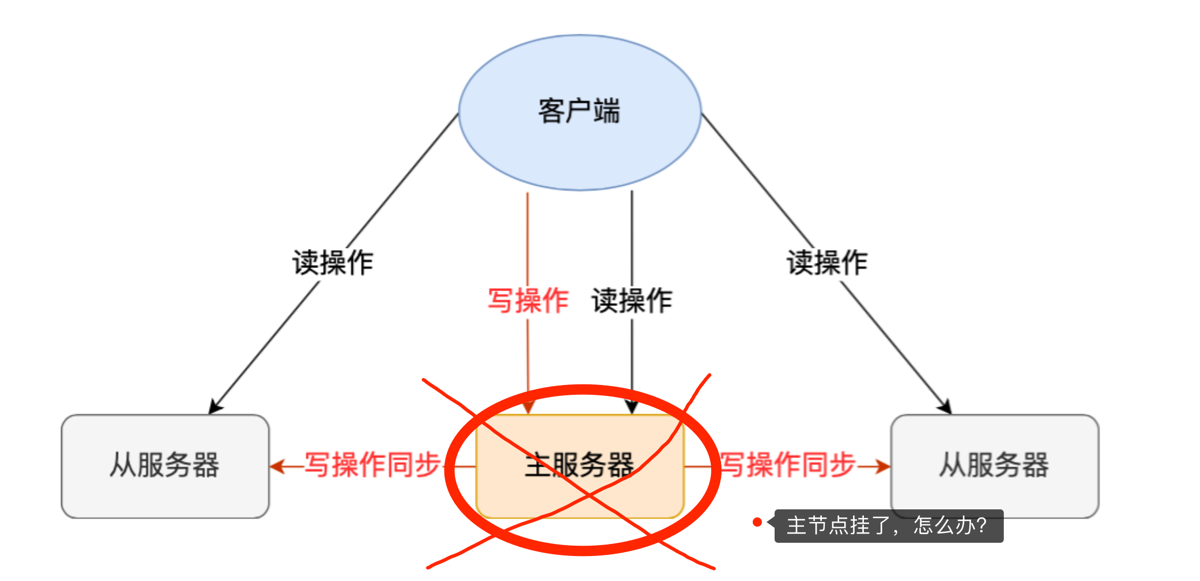
“哨兵(Sentinel)是 Redis 的高可用性(High Availability)解决方案。它由一个或多个 Sentinel 实例组成一个分布式系统,负责监控主从节点的运行状态,并在主节点挂掉时自动完成故障转移 (Failover)。”
核心工作流程(面试必考的 4 个步骤):
-
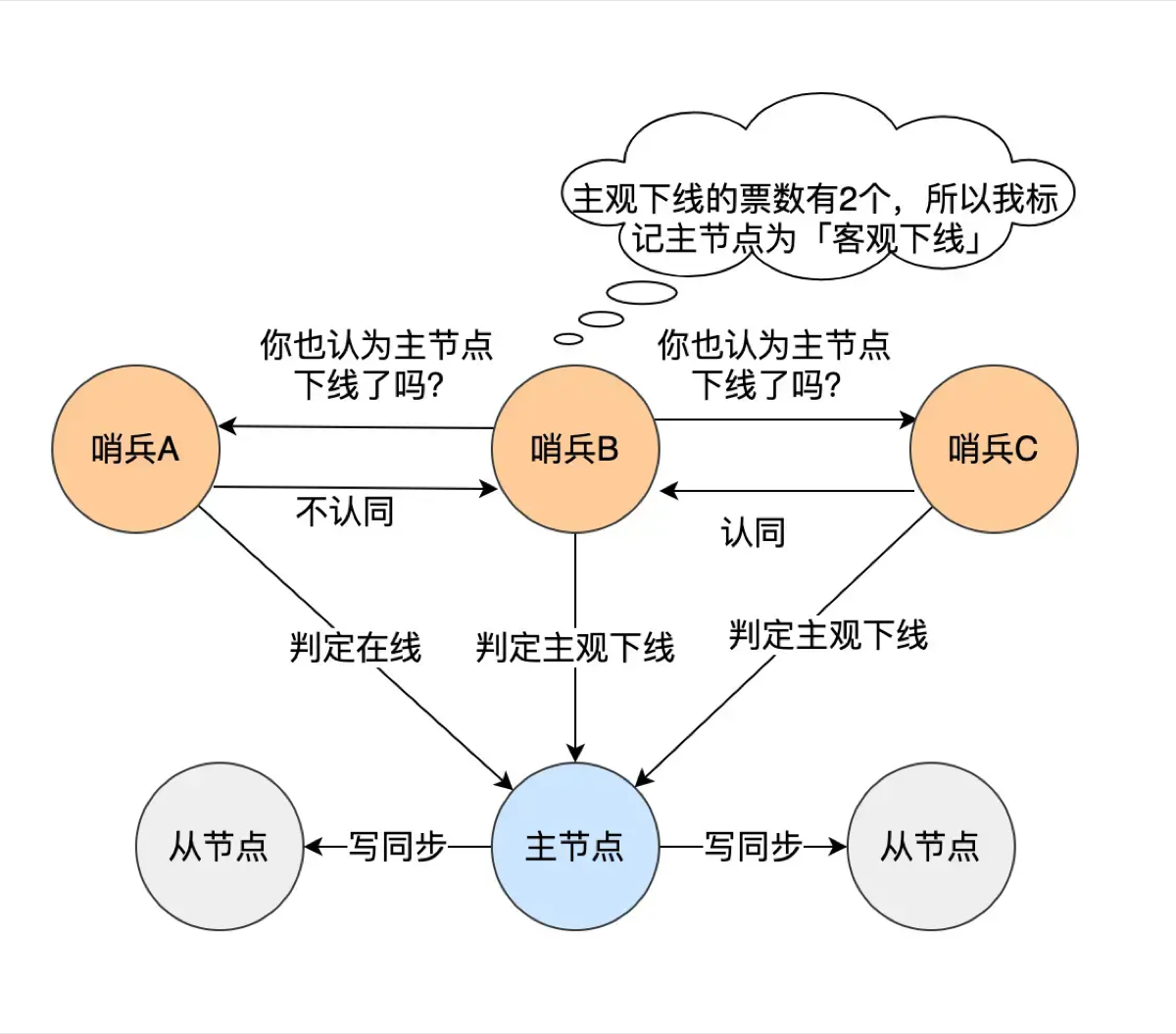
监控 (Monitoring):
-
哨兵会不断地向 Master 和 Slave 发送
PING命令。 -
主观下线 (SDOWN): 如果某个哨兵发现 Master 没响应,它认为 Master 挂了(主观)。
-
客观下线 (ODOWN): 如果超过半数(Quorum)的哨兵都认为 Master 挂了,那么 Master 就真的被判死刑了(客观)。
-
-
选主 (Leader Election):
- 在进行故障转移前,哨兵集群内部需要先通过 Raft 算法 投票选出一个**“哨兵领导者” (Leader)**,由它来全权负责后续的故障转移操作。
-
故障转移 (Failover):
-
Leader 哨兵会在剩下的 Slave 中挑选出一个状态最好的节点升级为新的 Master。
-
挑选规则: 优先级最高 → 复制偏移量最大(数据最全) → Run ID 最小。
-
-
通知 (Notification):
- 故障转移完成后,哨兵会通过发布订阅模式通知客户端(Client)新的 Master 地址,并命令其他的 Slave 去复制新的 Master。
一句话总结: “哨兵就像是 Redis 集群的**‘自动运维管理员’,它的核心作用是发现故障**、选举新主并通知客户端,从而实现无人值守的高可用。”
4.哨兵机制的选主节点的算法介绍一下
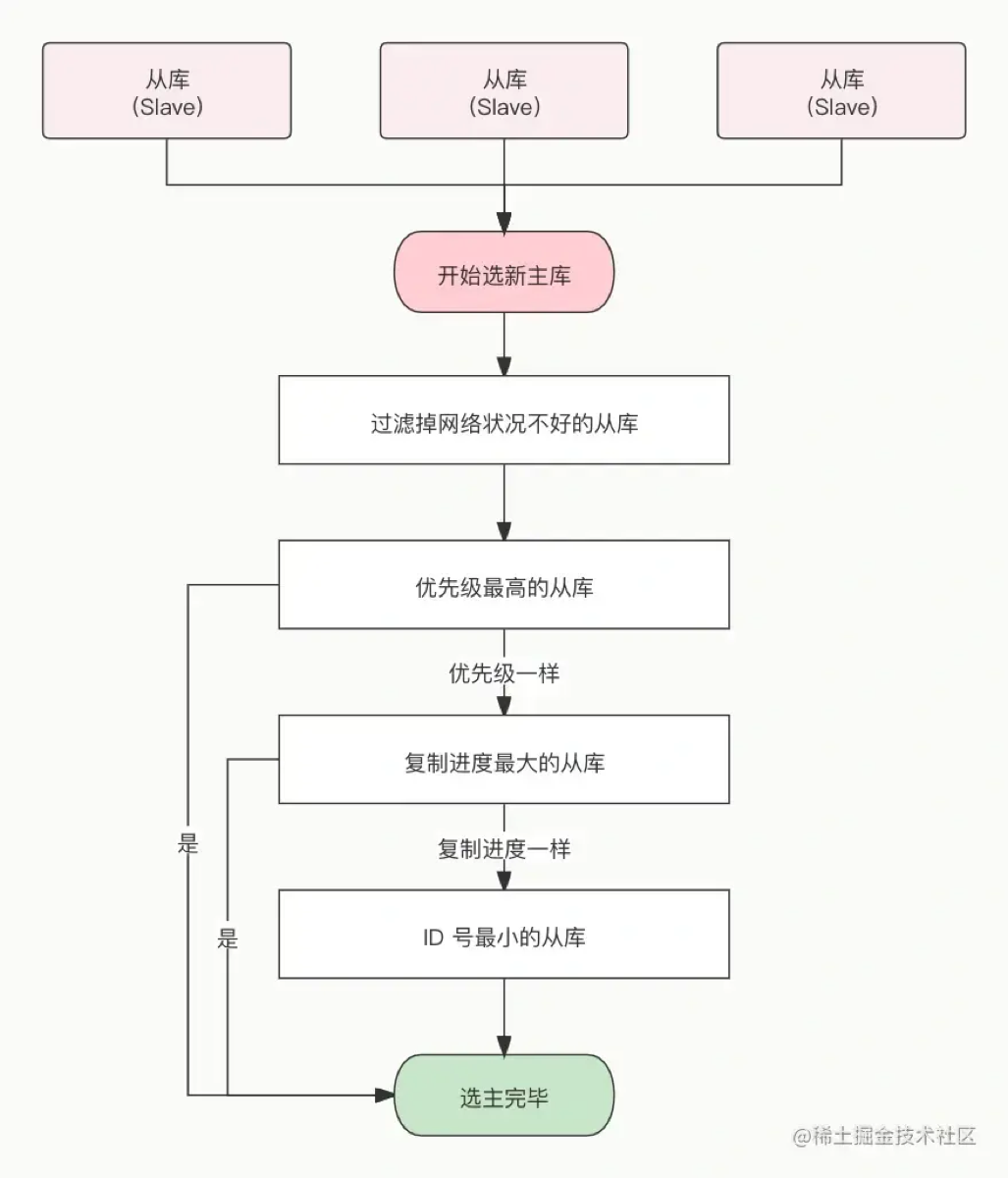
“哨兵选主的过程本质上是一个**‘层层筛选 + 三轮打分’的漏斗机制。核心目标是选出网络最健康、数据最完整**的从节点。”
具体步骤如下(面试必背的 4 步):
-
第一步:初步过滤(Filter):
-
哨兵首先会踢掉所有不符合要求的从节点:
-
已经下线的(
down)。 -
网络连接不稳定的(与主节点断连时间超过阈值的)。
-
-
目的: 确保剩下的候选者都是“健康”的。
-
-
第二步:比优先级(Priority):
-
查看从节点的
replica-priority配置项(在redis.conf中配置)。 -
数值越小,优先级越高。
-
如果数值一样,进入下一轮。(注:如果设为 0,则永远不会被选为主)。
-
-
第三步:比复制进度(Offset)—— 核心关键:
-
比较从节点的复制偏移量 (replication offset)。
-
Offset 越大,代表数据越新(越完整),优先级越高。
-
目的: 最大程度保证数据不丢失。
-
-
第四步:比 ID(Run ID):
-
如果优先级和复制进度都一样,最后比较从节点的 Run ID。
-
Run ID 越小(启动越早),胜出。
-
目的: 这是一个兜底规则,保证必定能选出一个节点,避免平票。
-
总结口诀: “先过滤坏的,再看优先级,接着比数据(谁新选谁),最后比 ID(谁小选谁)。”
5.Redis集群的模式了解吗 优缺点了解吗
Redis 的集群模式主要分为 3 种:主从复制、哨兵模式、切片集群(Cluster)。
1. 主从复制模式 (Master-Slave Replication)
这是最基础的模式,通常是一个主节点(Master)搭配一个或多个从节点(Slave)。
-
核心机制: 读写分离。主节点负责写,从节点负责读。主节点的数据会自动同步给从节点。
-
优点:
-
读写分离: 分担了主节点的读压力,适合“读多写少”的场景。
-
数据备份: 从节点保存了数据的副本,保证数据安全。
-
-
缺点:
-
无法自动故障转移 (致命伤): 如果主节点挂了,需要运维人员手动将从节点提升为主节点,服务会中断较长时间。
-
写瓶颈: 只有一个主节点处理写请求,无法扩展写能力。
-
存储瓶颈: 所有节点存的都是全量数据,单机内存有限,无法存储海量数据。
-
2. 哨兵模式 (Sentinel)
在主从复制的基础上,增加了“哨兵”组件来监控和自动切换,解决了高可用问题。
-
核心机制: 监控 + 自动选主 + 通知。哨兵集群实时监控主从节点,主节点挂了自动把从节点选为新主。
-
优点:
- 高可用 (HA): 实现了自动故障转移,不需要人工介入。
-
缺点:
-
写瓶颈依旧: 本质上还是“主从模式”,依然只有一个主节点处理写请求。
-
存储瓶颈依旧: 依然受限于单机内存大小。
-
配置复杂: 客户端需要适配哨兵协议(连接哨兵询问谁是主节点),部署和运维成本稍微高一点。
-
3. 切片集群模式 (Redis Cluster)
这是 Redis 3.0 之后推出的原生分布式方案,彻底解决了写能力和存储能力的扩展问题。
-
核心机制: 分片 (Sharding)。引入了 哈希槽 (Hash Slot) 的概念(共 16384 个槽)。数据被分散存储在多个主节点上,每个主节点负责一部分槽。
-
优点:
-
横向扩展 (Scale-out): 可以通过增加主节点来线性扩展写能力和存储容量(不再受单机内存限制)。
-
无中心架构: 节点之间互联,无需专门的 Proxy 或 Sentinel(节点自身具备故障发现和转移能力)。
-
-
缺点:
-
客户端复杂: 客户端需要支持 Smart Client 协议(缓存槽位映射关系),如果访问的 Key 不在当前节点,会收到
MOVED转向错误。 -
多 Key 操作受限: 无法简单地对跨不同节点的 Key 进行事务或集合操作(除非这些 Key 通过 Hash Tag 强制映射到同一个槽)。
-
| 模式 | 核心能力 | 写扩展性 | 存储扩展性 | 自动容灾 | 适用场景 |
|---|---|---|---|---|---|
| 主从复制 | 读写分离 | ❌ 否 | ❌ 否 | ❌ 否 | 个人学习、极小规模、数据备份 |
| 哨兵模式 | 高可用 | ❌ 否 | ❌ 否 | ✅ 是 | 读多写少、单机内存够用的生产环境 |
| Cluster | 高性能 + 高扩展 | ✅ 是 | ✅ 是 | ✅ 是 | 海量数据、高并发写、大规模分布式 |
6.cluster集群客户端是怎样知道该访问哪个分片的?
Redis Cluster 并没有使用中心化的代理(Proxy),而是采用了“客户端直连”的架构。客户端知道该访问哪个分片,主要依赖于以下 3 步机制:
-
哈希槽映射算法 (Hash Slot Calculation):
-
Redis Cluster 将所有数据划分为 16384 个哈希槽 (Hash Slots)。
-
当客户端要访问某个 Key 时,会先在本地根据公式计算该 Key 属于哪个槽:
Slot=CRC16(key) % 16384
-
-
Smart 客户端的本地缓存 (Client-side Caching):
-
大部分主流客户端(如 Jedis、Redisson)都是“聪明的”。
-
它们在启动时,会先发送
CLUSTER SLOTS命令给集群,拉取一份完整的 “槽位 → 节点”映射表 并缓存在本地。 -
这样,算出槽位后,客户端查一下本地表,就能直接把请求发给对的节点,不需要每次都去问集群。
-
-
重定向机制 (MOVED & ASK) —— 纠错兜底:
-
如果集群发生了扩容或迁移,导致客户端本地的缓存表过时了(发错人了),节点会拒绝请求并返回错误,指导客户端去正确的地方:
-
MOVED 错误(永久重定向): 节点会告诉客户端:“这个槽已经永久搬到另一个节点了,你更新一下缓存表,然后去那里找它。”
-
ASK 错误(临时重定向): 节点会告诉客户端:“这个槽正在搬家,数据可能在对面,你这次先去那边找,但不要更新缓存表。”
-
-
一句话总结: “客户端先在本地计算哈希槽,利用本地缓存的映射表找到对应节点;如果找错了,Redis 节点会通过 MOVED/ASK 错误告诉它正确的地址。”