1.*讲一下Redis底层的数据结构
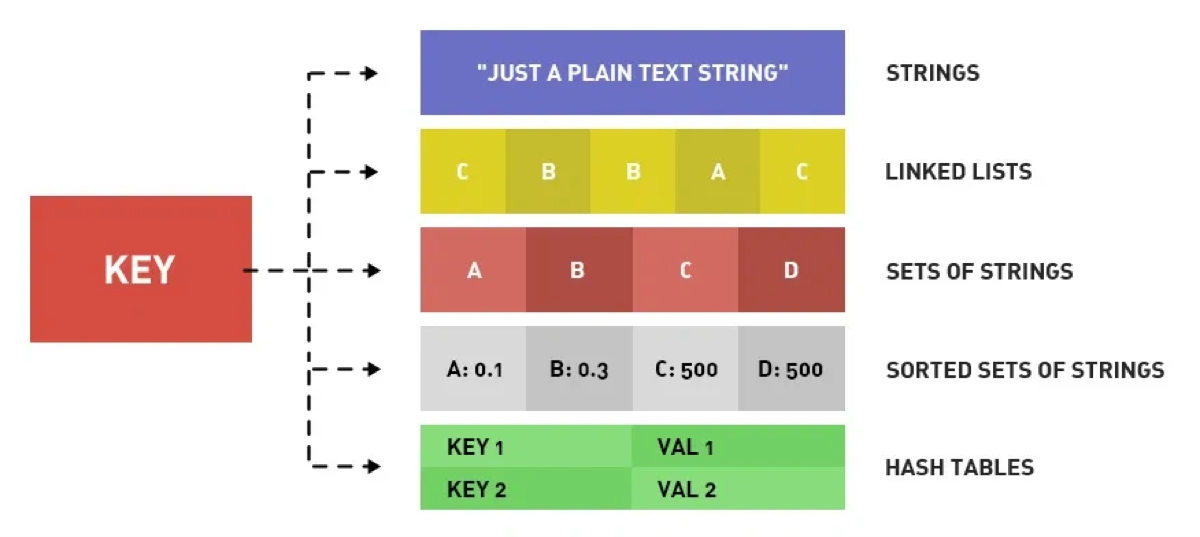
Redis 的数据结构分为“对象层”和“底层实现层”。为了平衡性能和内存,Redis 会根据数据量动态切换底层实现:
-
String(字符串):
-
底层主要使用 SDS (简单动态字符串)。
-
特点: 获取长度 O(1),二进制安全(不依赖
\0),空间预分配(减少内存重分配)。
-
-
List(列表):
-
底层使用 QuickList。
-
特点: 本质是“双向链表 + 压缩列表”的混合体(7.0 后内部节点换成了 ListPack),既保证了插入删除效率,又利用连续内存节省空间。
Redis 的 List 在新版本中通常采用 quicklist,小列表也可能直接使用 listpack。quicklist 不是 ziplist 或 listpack,而是一个双向链表;它的每个节点内部才使用紧凑存储结构,
-
Redis 6.2 及以前主要是 ziplist,Redis 7.0 起改为 listpack。
-
Hash(哈希):
-
小数据量: 使用 ZipList(7.0 后为 ListPack),内存紧凑。
-
大数据量: 升级为 HashTable,采用渐进式 Rehash 扩容。
-
-
Set(集合):
-
纯整数且少: 使用 IntSet(整数集合)。
-
其他情况: 使用 HashTable(Value 存为 null)。
-
-
ZSet(有序集合):
-
小数据量: 使用 ZipList(7.0 后为 ListPack)。
-
大数据量: 使用 SkipList (跳表) + HashTable。
-
特点: HashTable 负责 O(1) 查分值,SkipList 负责 O(logN) 排序和范围查询。选择跳表是因为相比 B+ 树,它在内存中实现更简单,且并发更新成本更低。
-
2.ZSet用过吗
“用过,主要是在‘实时排行榜’类的场景中使用(比如文章点赞排行、直播间贡献榜)。”
具体实现流程是:
-
存储与更新: 将对象 ID(如
article:id)作为 Member,将权重(如点赞数)作为 Score。使用ZINCRBY命令来实现分数的实时累加。 -
获取 Top N: 使用
ZREVRANGE命令倒序取出前几名(例如前 10 名的热门文章)。 -
获取单体排名: 如果需要展示当前用户的排名,使用
ZRANK或ZREVRANK。
至于它和 Set 的区别(关键点):
-
Set 是无序且唯一的,适合做“去重”或“交并差”聚合(如共同好友)。
-
ZSet 是有序且唯一的,它多维护了一个
Score字段,底层通过**跳表(SkipList)**或压缩列表实现,专为排序和范围查询设计。
3.Redis 中 set和zset区别是什么?
核心区别在于:是否“有序”以及是否支持“范围/排名查询”。
-
有序性与数据模型:
-
Set (无序集合): 保存唯一元素,完全无序。类似于 Java 的
HashSet。 -
ZSet (有序集合): 保存唯一元素,但每个元素绑定一个 Double 类型的分数 (Score)。数据根据 Score 从小到大排序。
-
-
功能与命令支持:
-
Set: 擅长集合运算(交集
SINTER、并集SUNION、差集SDIFF),用于去重。 -
ZSet: 擅长排序与范围操作。支持根据“排名范围”查元素 (
ZRANGE)、根据“分数范围”查元素 (ZRANGEBYSCORE)、计算排名 (ZRANK)。
-
-
应用场景:
-
Set: 共同好友(交集)、点赞用户列表(去重)、抽奖(随机弹出)。
-
ZSet: 实时排行榜(按分数排序)、带权重的消息队列、延时队列(Score 存时间戳)。
-
-
底层实现(加分项):
-
Set: IntSet (纯整数且少) 或 HashTable。
-
ZSet: ZipList/ListPack (数据少) 或 SkipList + HashTable (数据多)。
-
4.*Zset 底层是怎么实现的?
ZSet 的底层实现是动态变化的,根据数据量大小在“压缩列表”和“跳表 + 哈希表”之间切换:
-
数据量小(默认配置):
-
条件: 元素个数小于 128 个,且每个元素小于 64 字节。
-
实现: 使用 ZipList(压缩列表)。数据紧凑存储,节省内存。
-
注:Redis 7.0 之后由 ListPack 替代 ZipList。
-
-
数据量大:
-
条件: 不满足上述条件时。
-
实现: 使用 SkipList(跳表) + HashTable(哈希表) 的组合结构。
-
为什么要用“跳表 + 哈希表”组合?
-
HashTable: 存储
Member -> Score的映射,保证给定元素查分数的复杂度为 O(1)。 -
SkipList: 存储有序的节点(含 Score 和 Member),实现 O(log N) 的排序、范围查找(
ZRANGE)和排名计算。 -
数据共享: 虽然用了两个结构,但它们共享 Member 和 Score 的数据,不会造成双倍内存浪费。
5.***跳表是怎么实现的?
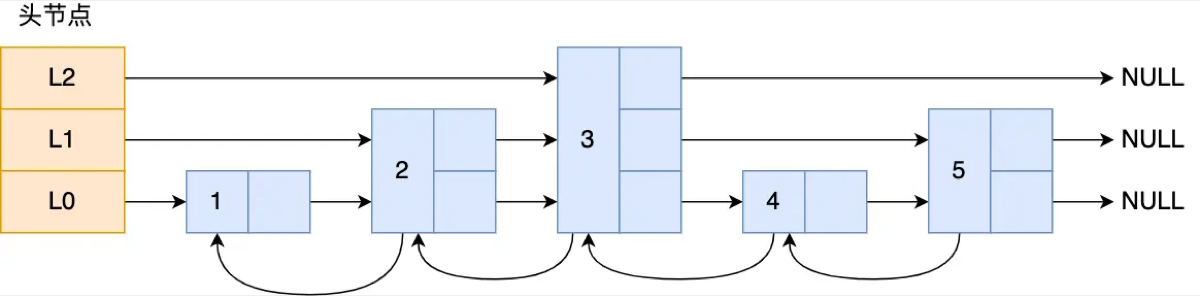

“跳表(SkipList)本质上是一个‘空间换时间’的多层有序链表,实现了 O(log N) 的高效查找。”
核心实现细节包含三点:
-
多层索引结构:
-
它在普通链表之上增加了多级索引层。
-
查找时从最高层开始,如果当前节点的值小于目标值,就向右遍历;如果大于目标值或到达链表尾,就下潜到下一层。这实现了类似“二分查找”的效果。
-
-
节点结构 (
zskiplistNode):-
Level 数组: 每个节点包含多个层级,每层保存了前向指针和跨度 (Span)。
- 关键点: 跨度是用来记录两个节点之间的距离,Redis 利用跨度的累加来快速计算元素的排名 (Rank)。
-
后退指针 (
backward): L0 层维护了双向指针,支持ZREVRANGE倒序范围查询。
-
-
随机层高生成:
-
Redis 不强制要求相邻层节点数量比例(如 2:1),而是采用随机算法。
-
新节点插入时,每增加一层的概率为 25%,最高限制 64 层。这种设计避免了平衡树复杂的旋转操作,实现更简单且并发性能更好。
-
6.Redis为什么使用跳表而不是用B+树?
核心原因:Redis 是纯内存操作,不需要 B+ 树那种为“减少磁盘 I/O”而设计的复杂结构。
具体对比维度如下:
-
设计初衷(最根本原因):
-
B+ 树:是为了磁盘存储设计的。它的层级低(扁平),目的是为了减少磁盘寻道(I/O)次数。
-
跳表:在内存中,指针跳转非常快(纳秒级),不需要为了压低层高而设计复杂的 B+ 树结构。跳表虽然层数比 B+ 树高,但在内存中这不是瓶颈。
-
-
实现复杂度:
-
跳表:实现非常简单,代码量少,不容易出错(维护成本低)。
-
B+ 树:为了维持平衡,插入删除时需要处理复杂的节点分裂、合并和重平衡,代码实现极其复杂。
-
-
写入性能:
-
跳表:插入/删除只需修改局部指针,利用随机层高保持概率上的平衡,开销小。
-
B+ 树:写操作可能引发树的全局调整(锁粒度或计算开销更大)。
-
一句话总结: 在内存场景下,跳表能提供与 B+ 树相当的查询效率 O(log N),但实现更简单且写入性能更好。
7.压缩列表是怎么实现的?
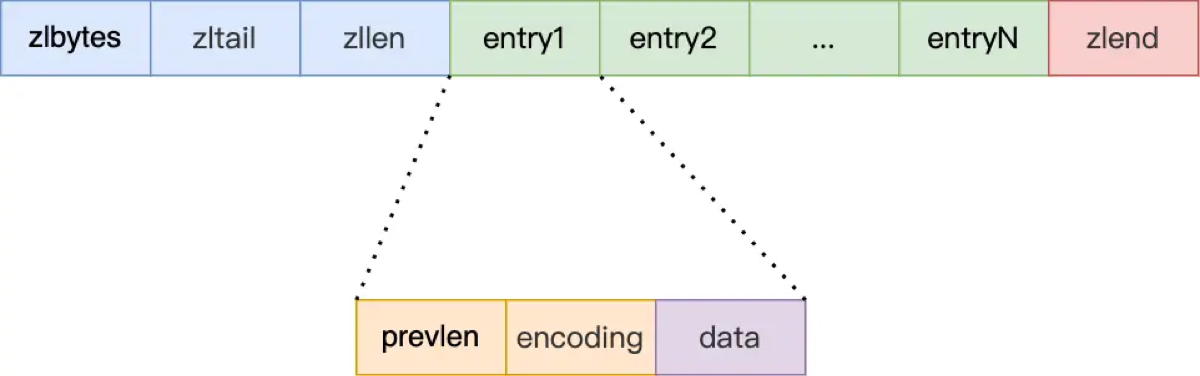
“压缩列表(ZipList)本质上是一块连续的内存空间。它类似于数组,但它允许存储不同长度的字符串或整数,是一种为了极致节约内存而设计的紧凑型数据结构。”
具体结构拆解(关键点):
-
整体宏观布局:
-
头部包含三个字段:
zlbytes(列表总字节数)、zltail(尾节点偏移量,支持 O(1) 定位尾部)、zllen(节点数量)。 -
中间是连续的数据节点(Entry)。
-
尾部是
zhend(0xFF)结束标记。
-
-
微观节点结构(Entry): 每个节点都由三部分组成,这是面试中最需要讲清楚的细节:
-
prevlen (前一个节点的长度): 这是关键。 它记录了前一个节点的长度(占用 1 或 5 字节),使得 ZipList 可以像双向链表一样从后向前遍历。
-
encoding: 记录当前节点数据的类型(字符串/整数)和长度。
-
data: 实际存储的数据。
-
致命缺陷(面试必问):连锁更新 (Cascading Update) “虽然它很省内存,但有一个设计缺陷。因为 prevlen 的长度是可变的(前节点小于 254 字节用 1 字节,否则用 5 字节)。 一旦插入或修改某个节点,导致其长度跨越了 254 字节的阈值,可能导致后续节点的 prevlen 字段也要扩容,进而像推多米诺骨牌一样引发连续的内存重分配。 这也是 Redis 7.0 引入 ListPack(去除了 prevlen)来彻底解决该问题的原因。”
8.*介绍一下 Redis 中的 listpack
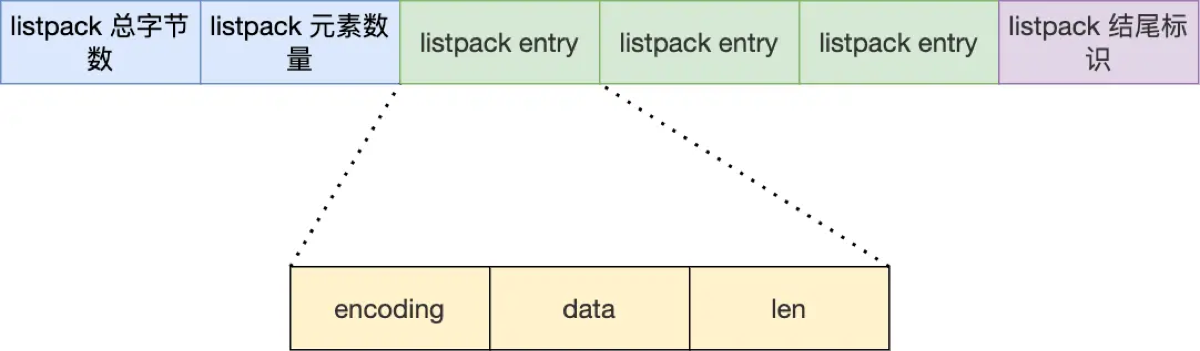
“Listpack(紧凑列表)是 Redis 7.0 引入的全新底层数据结构,设计初衷是彻底替代 ZipList(压缩列表)。它保留了 ZipList 紧凑、省内存的优点,同时完美解决了‘连锁更新’的致命缺陷。”
核心改进点(面试必考):
-
取消了
prevlen:-
ZipList 的每个节点都记录了“前一个节点的长度”,这是导致连锁更新的根源。
-
Listpack 的节点只记录当前节点的长度和编码信息。
-
-
特殊的反向遍历设计:
-
Listpack 依然支持双向遍历。它是通过在每个节点的末尾记录当前节点的长度(Backlen),从而实现从后向前反推节点位置的。
-
这种设计使得每个节点的变动只影响它自己,不会像 ZipList 那样因为长度变化而波及后续节点,从而根除了连锁更新问题。
-
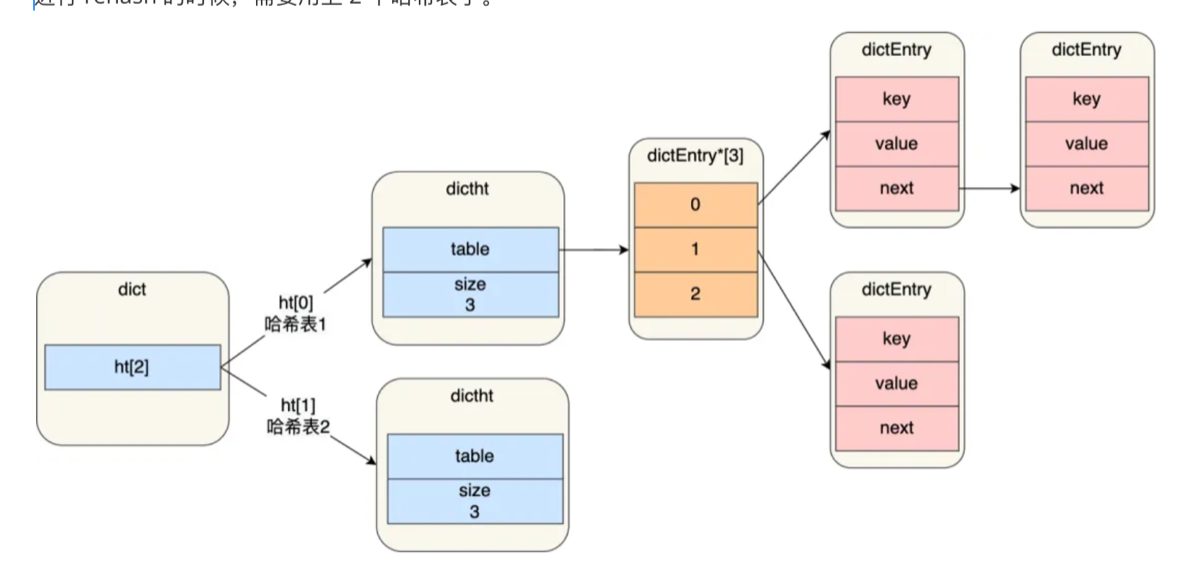
9.哈希表是怎么扩容的?
-
双重哈希表设计 (
ht[2]):-
你看最左边的
dict结构体,它包含一个数组ht[2],也就是持有两个哈希表:ht[0]和ht[1]。 -
平常状态: 只有
ht[0]存放数据,ht[1]是空的。 -
Rehash 状态:
ht[1]会被分配空间,用于扩容时的“数据搬运”。
-
-
拉链法解决冲突 (Chaining):
-
看右边的红色
dictEntry节点,它们通过next指针连在了一起。 -
这就是哈希冲突的处理方式:当多个 Key 计算出的哈希值对应同一个索引(Bucket)时,Redis 会把它们串成一个单向链表。
-
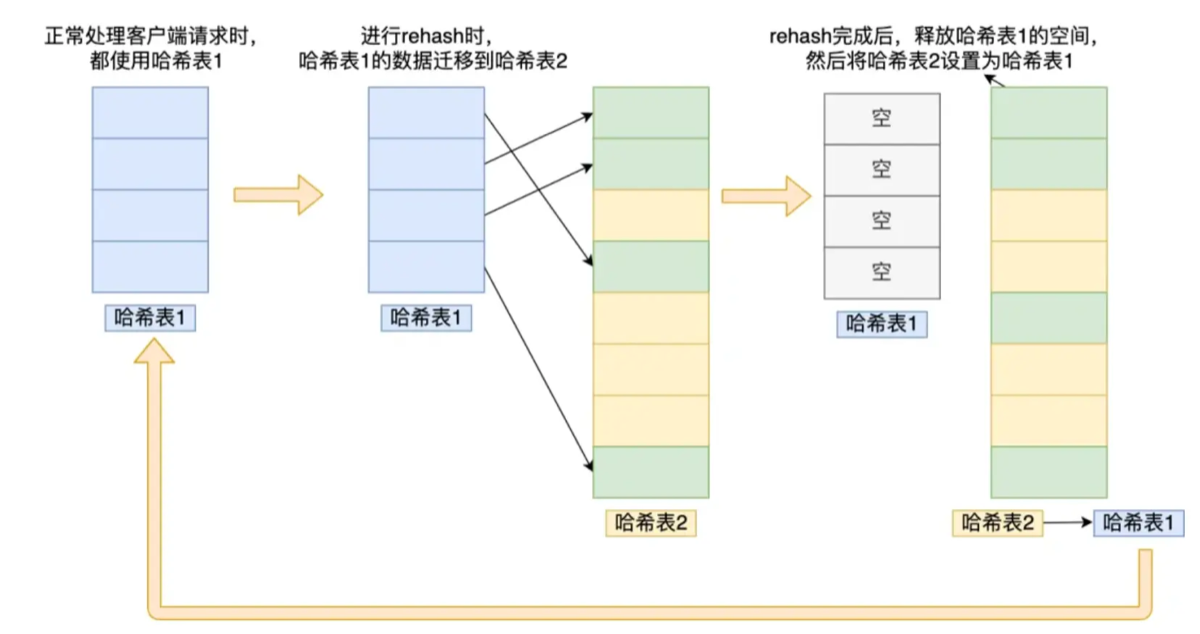
第二张图(流程图):Rehash 的宏观过程
这张图展示了当哈希表需要扩容时,数据是如何从旧表迁移到新表的生命周期。
-
阶段一:双表并存
- 当扩容开始时,Redis 会给 哈希表 2 (
ht[1]) 分配比 哈希表 1 (ht[0]) 更大的内存空间(通常是 2 倍)。此时两个表同时存在。
- 当扩容开始时,Redis 会给 哈希表 2 (
-
阶段二:渐进式迁移
- 数据不是一次性搬过去的(那样会卡死线程)。而是通过渐进式 Rehash,在后续的增删改查操作中,分批次把 哈希表 1 的数据重新计算哈希值(Rehash),搬运到 哈希表 2。
-
阶段三:指针交换 (Switch)
-
当所有数据都搬运完后,哈希表 1 变为空。
-
Redis 会释放 哈希表 1 的空间,然后把 哈希表 2 的指针“指鹿为马”变成新的 哈希表 1,并为下一次 Rehash 准备一个新的空表作为备用。
-
10.哈希表扩容的时候,有读请求怎么查?
“在 Redis 哈希表进行渐进式扩容(Rehash)期间,读请求会同时查询两个哈希表。”
具体流程如下:
-
先查旧表 (
ht[0]): 客户端请求首先会在旧的哈希表中查找目标 Key。 -
后查新表 (
ht[1]): 如果在旧表中没找到(且此时字典正处于 Rehash 状态),Redis 会立即去新的哈希表中进行第二次查找。
关键点补充(面试防坑):
-
删/改 操作: 也是同样的逻辑,“双表操作”。先试图在
ht[0]中处理,没找到再去ht[1]处理。 -
增 (Insert) 操作: “只进不出”。新增的 Key 只会写入到新表 (
ht[1]) 中,绝对不会写入旧表。这保证了旧表的数据只会越来越少,最终被清空。
总结口诀: “查删改,搜双表;新增数据,只进新表。”
11.* String 是使用什么存储的?为什么不用 c 语言中的字符串?
 “Redis 的 String 底层使用的是 SDS(Simple Dynamic String,简单动态字符串),而不是 C 语言原生的字符数组。”
“Redis 的 String 底层使用的是 SDS(Simple Dynamic String,简单动态字符串),而不是 C 语言原生的字符数组。”
为什么不用 C 语言字符串?(核心区别对比):
-
性能差异(O(1) 获取长度):
-
C 语言: 获取字符串长度需要遍历整个字符串,时间复杂度是 O(N)。
-
SDS: 头部直接维护了
len属性,获取长度的时间复杂度是 O(1),这确保了STRLEN命令在数据量大时依然极快。
-
-
二进制安全(Binary Safe):
-
C 语言: 依靠空字符
\0作为结束符,这意味着中间不能包含\0,否则会被截断。因此它只能存文本,不能存图片、音频等二进制数据。 -
SDS: 依靠
len属性判断结束,不依赖\0。这使得 Redis 可以存储任何二进制数据。
-
-
杜绝缓冲区溢出 (Buffer Overflow):
-
C 语言: 字符串拼接(如
strcat)时,如果未提前分配足够空间,会导致内存溢出覆盖相邻数据。 -
SDS: 在修改前会自动检查空间,如果不够会自动扩容。
-
加分项(内存优化策略): “SDS 还采用了空间预分配(修改时多分配一点,减少频繁扩容)和惰性空间释放(缩短时不立即回收,防止将来再次扩容)的策略来优化内存分配效率。”
12.redis的Zset,在项目里具体用法是什么?
“在我的项目中,ZSet 主要用于实现‘实时排行榜’类的功能(例如文章热度榜、直播间贡献榜)。”
具体的业务实现流程如下:
-
定义 Key 与 Member:
-
我们将排行榜命名为
user:ranking。 -
将具体的对象 ID(如文章 ID
article:1)作为 Member。 -
将热度值(如点赞数)作为 Score。
-
-
实时更新(写):
-
当用户给某篇文章点赞时,直接调用
ZINCRBY user:ranking 1 article:1。 -
这就实现了分数的原子性自增,同时 ZSet 会自动根据新的分数调整内部排序,不需要我们在应用层写任何排序逻辑。
-
-
展示 Top N(读):
-
当需要展示“最热前 3 名文章”时,使用
ZREVRANGE user:ranking 0 2 WITHSCORES。 -
这能以 $O(\log N + M)$ 的高效率直接返回按分数倒序排列的结果。
-
-
展示特定排名(读):
-
如果用户想看某篇文章的具体赞数,用
ZSCORE。 -
如果想看某个范围(比如 100 到 200 赞)的文章,用
ZRANGEBYSCORE。
-
为什么选 ZSet?
“如果用 MySQL 做排行榜,每次查询都需要全表 ORDER BY,在大数据量下会非常慢。而 Redis ZSet 在插入时就通过跳表完成了排序,查询 Top N 几乎是实时的。”