1.*JVM的内存模型介绍一下
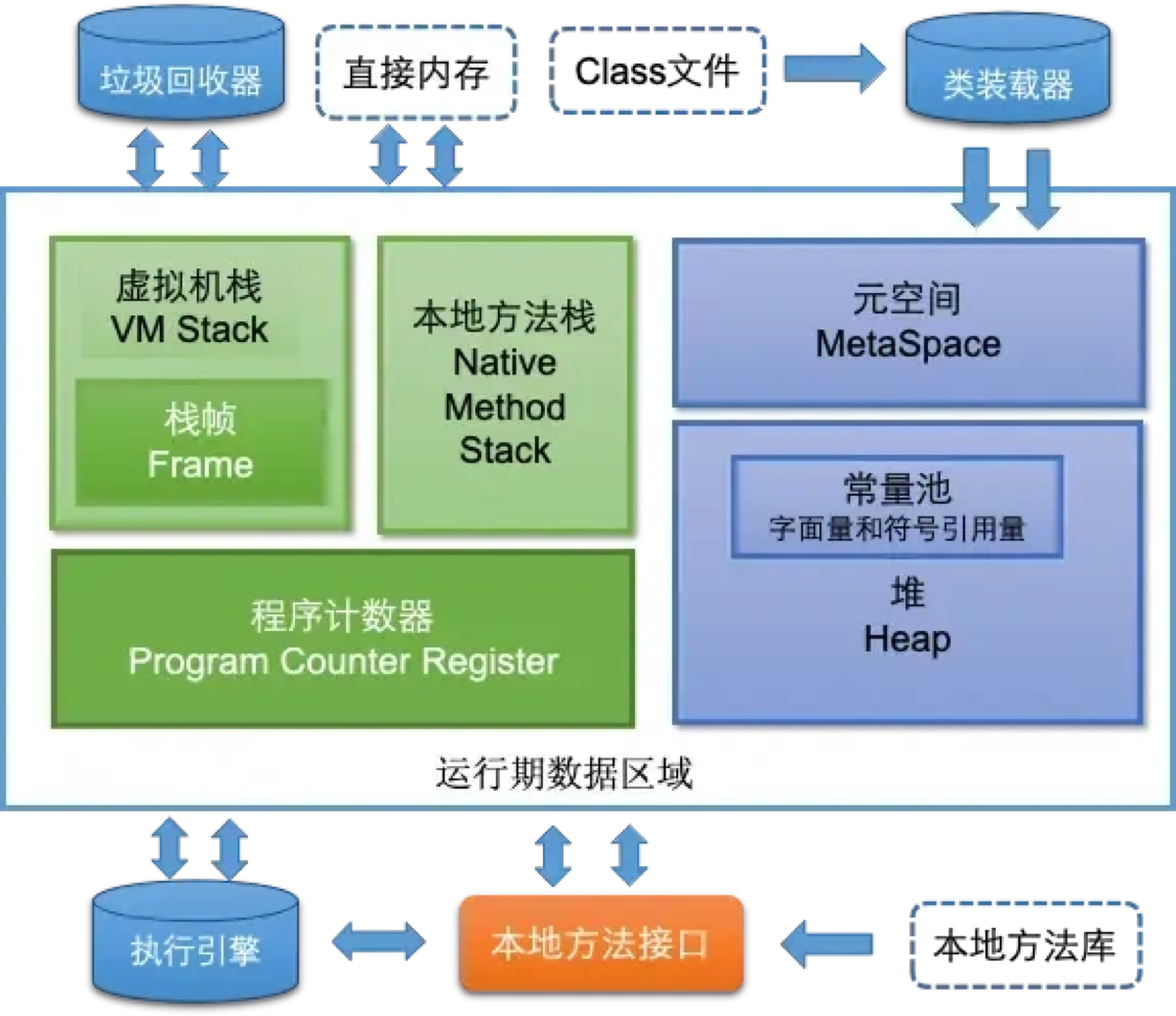
“JVM 在运行 Java 程序时,会把它管理的内存划分为若干个不同的数据区域。我习惯将它们分为 ‘两大类、五大块’:
第一类:线程私有区 (Thread-Private) 这就好比每个人的‘办公桌’,只有自己能用,随线程而生,随线程而灭,不需要垃圾回收。
-
程序计数器 (Program Counter Register):
-
作用: 记录当前线程执行到哪一行字节码了。
-
特点: 它是唯一一个在 JVM 规范中没有规定任何
OutOfMemoryError情况的区域。
-
-
虚拟机栈 (VM Stack) —— 最核心:
-
作用: 描述 Java 方法执行的内存模型。每个方法被执行的时候,都会创建一个 ‘栈帧’ (Stack Frame),用于存储局部变量表、操作数栈、动态链接、方法出口等信息。
-
异常: 如果递归太深,会爆
StackOverflowError。
-
-
本地方法栈 (Native Method Stack):
- 作用: 和虚拟机栈类似,只不过它是为
native方法(C/C++写的方法)服务的。
- 作用: 和虚拟机栈类似,只不过它是为
第二类:线程共享区 (Thread-Shared) 这就好比公司的‘会议室’或‘仓库’,所有人都能访问,是 垃圾回收 (GC) 的重点区域。
-
堆 (Heap) —— 最大的一块:
-
作用: 几乎所有的 对象实例 和 数组 都在这里分配内存。
-
特点: 它是 GC 管理的主要区域(所以也叫 GC 堆)。如果堆满了,就会抛出
OutOfMemoryError (OOM)。 -
里面有一个常量池,存储字符串常量池,静态变量
-
-
元空间
-
作用: 存储已被虚拟机加载的 类信息,类的元数据,运行时的常量池(符号引用堆里的常量)、即时编译器编译后的代码等数据。
-
演变: 在 JDK 1.8 之前叫‘永久代 (PermGen)’,JDK 1.8 及以后改名叫 ‘元空间 (Metaspace)’,并且把内存移到了本地内存 (Native Memory) 中,不再占用 JVM 堆内存。”
-
public class OrderService { // 类信息 -> 【方法区】
// static 静态变量 -> 【方法区】
public static final int TIMEOUT = 30;
public void createOrder() {
// order 是引用(指针) -> 放在【虚拟机栈】的局部变量表中
// new Orders() 是真正的对象 -> 放在【堆】中
Orders order = new Orders();
// userId 是基本数据类型 -> 放在【虚拟机栈】
int userId = 1001;
// 调用方法,会压入一个新的栈帧到【虚拟机栈】
process(order);
}
}2.JVM内存模型里的堆和栈有什么区别?
| 特性 | 栈 (Stack) | 堆 (Heap) |
|---|---|---|
| 存储内容 | 局部变量、引用指针、方法现场 | 对象实例、数组 |
| 所有权 | 线程私有 (互不干扰) | 线程共享 (此时需要锁) |
| 空间大小 | 较小 (默认 1MB 左右) | 很大 (几个 G) |
| 垃圾回收 | 无 (出栈自动释放) | 有 (频繁 GC) |
| 异常类型 | StackOverflowError | OutOfMemoryError |
| 速度 | 非常快 | 较慢 |
3.栈中存的到底是指针还是对象?
“在 Java 内存模型中,栈(虚拟机栈)主要存储的是栈帧,而栈帧里的‘局部变量表’主要存放了两类数据:
-
基本数据类型 (Primitives)
-
比如
int,boolean,double等。 -
存的是值本身。比如
int a = 10;,这个10就直接存在栈里。
-
-
对象引用 (Object References)
-
比如
User user = new User();。 -
存的是地址(指针)。栈里的
user变量只是一个引用(Reference),它里面存的是一个内存地址(或者句柄),这个地址指向了 堆(Heap) 中真正的User对象实例。
-
打个比方:
-
堆(Heap)里的对象 就像是一台 电视机。
-
栈(Stack)里的引用 就像是一个 遥控器。
-
我们是拿着手里的‘遥控器’(栈中的引用),去操作远处的‘电视机’(堆中的对象)。我们不可能把电视机塞进口袋(栈)里。”
4.*堆分为哪几部分呢?
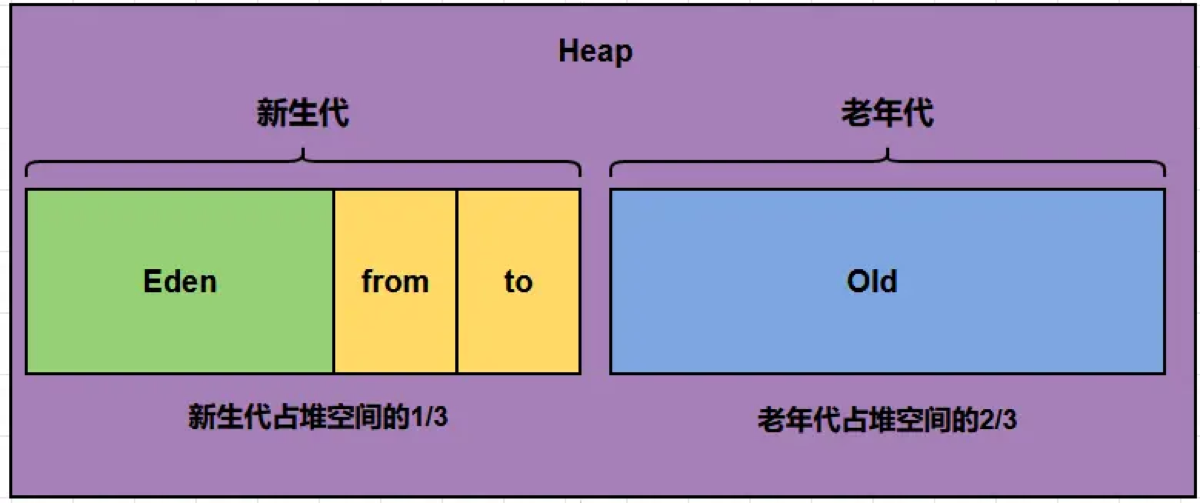
“为了支持高效的垃圾回收,JVM 将堆内存逻辑上分为 ‘新生代 (Young Generation)’ 和 ‘老年代 (Old Generation)’ 两大部分。
1. 新生代 (Young Generation)
-
占比: 默认约占堆内存的 1/3。
-
结构: 内部又细分为三个区:
-
Eden 区 (伊甸园区): 占新生代的 80%。绝大多数新对象都在这里诞生。
-
Survivor 0 区 (S0 / From 区): 占新生代的 10%。
-
Survivor 1 区 (S1 / To 区): 占新生代的 10%。
-
-
作用: 存放生命周期较短的对象。这里发生的 GC 叫 Minor GC(或 Young GC),频率非常高,速度非常快。
2. 老年代 (Old Generation)
-
占比: 默认约占堆内存的 2/3。
-
结构: 就是一个大的内存块,没有进一步细分。
-
作用: 存放生命周期很长的对象(经过多次 Minor GC 还没死的),或者超大的对象(直接进老年代)。这里发生的 GC 叫 Major GC(或 Full GC),速度比 Minor GC 慢 10 倍以上。
3. JDK 1.7 vs 1.8 的变化 (加分项)
-
在 JDK 1.7 及之前,还有一个 ‘永久代 (PermGen)’,虽然它在逻辑上常被认为是堆的一部分,但实际上它是方法区的实现。
-
在 JDK 1.8 之后,永久代被移除,取而代之的是 ‘元空间 (Metaspace)’,并且它使用的是 本地内存,不再属于堆内存。
-
注意: 从 JDK 1.7 开始,字符串常量池 已经被移到了 堆内存 中。”
| 区域 | 默认比例 | 内部划分 | 内部默认比例 |
|---|---|---|---|
| 新生代 | 1/3 | Eden : S0 : S1 | 8 : 1 : 1 |
| 老年代 | 2/3 | - | - |
5.如果有个大对象一般是在哪个区域?
“一般情况下,新对象都是在新生代的 Eden 区分配的。 但是,对于大对象,JVM 有一个专门的 ‘分配担保机制’,让它跳过新生代,直接进入老年代。
1. 为什么要这样做?(核心原因)
-
避免资源浪费: 新生代使用的是 ‘复制算法’(标记-复制)。如果大对象放在新生代,每次 Minor GC 时,都需要把这个大块头在 Eden、S0、S1 之间搬来搬去。
-
后果: 这会消耗大量的 CPU 和内存带宽(高昂的复制成本),并且容易导致 Survivor 区瞬间爆满,挤走其他本来该存活的小对象。
2. 怎么定义‘大对象’?
-
JVM 提供了一个参数:
-XX:PretenureSizeThreshold(字节数)。 -
机制: 如果对象的大小超过了这个阈值,就会直接在老年代分配。
-
典型例子: 比如一个超长的
byte[]数组或者String。
3. 注意事项 (高手细节)
-
这个参数 (
PretenureSizeThreshold) 只对 Serial 和 ParNew 这两款新生代收集器有效。 -
如果是 G1 收集器(JDK 9+ 默认),它有专门的 Humongous 区域 来存放极大对象,机制又不一样了。”
6.程序计数器的作用,为什么是私有的??
“一、程序计数器的作用 (What) 简单来说,它就是当前线程所执行的字节码的 行号指示器。 它的核心作用有两个:
-
指令导游: 字节码解释器工作时,就是通过改变这个计数器的值,来选取下一条需要执行的字节码指令。
-
流程控制: 代码中的 分支、循环、跳转、异常处理,甚至线程恢复等基础功能,全都要依赖这个计数器来完成。
- 注意: 如果当前执行的是
native方法,这个计数器的值是 Undefined (空),因为它只记录 Java 字节码的地址。
- 注意: 如果当前执行的是
二、为什么是线程私有的 (Why Private) 这主要是为了应对 CPU 的上下文切换 (Context Switching)。
-
背景: 在多线程环境下,CPU 是并发执行的。CPU 会给每个线程分配时间片,线程 A 执行一会儿,被挂起,切到线程 B 执行,然后再切回线程 A。
-
核心原因: 当线程 A ‘切回来’ 的时候,它必须知道自己刚才 ‘执行到哪一步了’。
-
结论: 为了让每个线程都能独立地恢复到正确的执行位置,每个线程必须有一个自己独立的程序计数器,互不干扰。”
7.JVM中的方法调用和字节码的执行过程?
“方法的执行过程,本质上就是 ‘执行引擎’ 根据 ‘PC 寄存器’ 的指示,去 ‘方法区(也就是元空间+堆中的元空间里的运行时的静态池引用-》堆里的静态池)’ 读取字节码指令,然后在 ‘虚拟机栈’ 中进行数据运算的过程。
这个过程可以拆解为 4 个核心步骤:
1. 寻找与加载 (Loading & Lookup)
-
当线程调用一个方法时,JVM 首先去 方法区 找这个类的元数据。
-
如果类还没加载,就先触发类加载。
-
加载后,JVM 拿到了该方法的字节码(Bytecode)。
2. 创建栈帧 (Frame Creation)
-
JVM 会在当前线程的 虚拟机栈 (VM Stack) 中压入一个新的 栈帧 (Stack Frame)。
-
这个栈帧里分配好了:局部变量表、操作数栈、动态链接(指向方法区常量池的引用)等内存空间。
3. 执行指令 (Execution Loop)
-
取指: 执行引擎根据 PC 寄存器,从 方法区 读取一条字节码指令(比如
iload,iadd)。 -
运算:
-
数据从 局部变量表 复制到 操作数栈。
-
在 操作数栈 顶进行运算(如加减乘除)。
-
结果再存回 局部变量表。
-
-
动态链接: 如果代码里调用了其他方法或访问了常量,需要通过栈帧里的‘动态链接’去 方法区 的运行时常量池里解析符号引用。
4. 方法返回 (Return)
-
方法执行完毕(遇到
return或抛异常),当前栈帧 出栈 (Pop),释放内存。 -
恢复上层方法的执行进度(PC 寄存器指向调用者的下一行)。”
8.方法区中还有哪些东西?
1. 图纸本身 (类信息)(也就是元空间)
类名,父类,接口,修饰符等,直接使用的是操作系统的本地内存,而不是虚拟机的内存。
大白话: 告诉你这个东西长什么样。 比如你要拼一个“乐高警察”。 方法区里就存着一张说明书,上面写着:
-
这个东西叫“警察” (类名)。
-
他有一个帽子、一把枪 (成员变量)。
-
他会走路、会敬礼 (方法)。
如果没有它: JVM 根本不知道“警察”是个什么东西,没法拼。
2. 公共模具 (静态变量 Static)
大白话: 所有成品共用的一份资源。 假设所有的乐高警察,胸口都要贴一个“Police”的贴纸。工厂为了省事,只做了一张超级大的母版贴纸,挂在墙上。
-
不管是第 1 个警察,还是第 10000 个警察,都指着墙上这一张贴纸说:“我和他用的是同一款”。
-
如果你把墙上这张贴纸涂黑了,所有警察胸口的标都变黑了。
如果没有它: 每个警察都要单独印一张贴纸,太浪费空间了。
3. 通讯录 (常量池)
大白话: 帮代码“找人”的。 你的说明书(代码)里可能写了一句:“警察要开 警车”。 但是,“警车”在哪?长啥样? 方法区里有个小本本(常量池),上面记着:
-
“警车”的图纸在第 3 排架子上。
-
“手枪”的图纸在第 5 排架子上。
-
数字
100、字符串"Hello"这些固定的东西,也都记在这个本本上。
如果没有它: 代码读到“警车”两个字就懵了,不知道去哪里找警车的定义。
4. 老师傅的秘籍 (JIT 编译后的代码)
大白话: 经常用的“快捷操作”。 新手看说明书(解释器)拼乐高,是看一步拼一步,很慢。 有个老师傅(JIT),他发现“拼腿”这个动作每天要做几万次。 于是他不再看说明书了,直接形成了肌肉记忆(机器码),闭着眼睛刷刷刷就能拼好。 这种**“肌肉记忆”**也存在方法区里,下次再拼腿,直接调用肌肉记忆,速度快 10 倍。
-
堆 (Heap):是成品展示区。里面堆满了真正拼好的乐高城堡、乐高小人(也就是
new出来的对象)。 -
方法区 (Method Area):是图纸存放室。
5.String保存在哪里呢?
字符串常量池被搬到了 堆内存 (Heap) 中。不同于其他对象,它的值是不可变的,且可以被多个引用共享。
new 出来的在堆里的 普通内存区。(除了常量池的堆,即新生代与老年代)
- 它本身是在堆的普通区域,只有它引用的字面量数据才是在常量池里。
如果不是 new 出来的,使用直接赋值
String s1 = "Hello";则 JVM 会先去常量池看有没有,后的话直接返回引用,没有的话直接咋常量池创建一个 Hello 对象,这么做是为了复用,即使有 100 string 赋值,内存里实际只有一个。
6.String s = new String(“abc”)执行过程中分别对应哪些内存区域?
String s1 = "abc"; // 这种写法叫“字面量”写法
-
栈 里有一个引用
s。 -
堆 里有一个常规对象(这是我们最终拿到的)。
-
常量池 里有一个字面量对象(这是底层的素材)。”
-
String s—— 【虚拟机栈 (VM Stack)】-
这是一个引用变量。
-
它存在于当前方法的 栈帧(局部变量表)中。
-
它的作用是保存 堆中那个新对象的内存地址。
-
-
new String(...)—— 【堆 (Heap)】-
new关键字强制要求 JVM 在 堆内存 中创建一个全新的 String 对象。 -
不管常量池里有没有 “abc”,这里都会产生一个新的对象。
-
-
"abc"—— 【字符串常量池 (String Pool)】-
这是字面量。
-
JVM 会先去 字符串常量池(在堆中)检查是否存在 “abc”。
-
如果没有:先在池中创建一个 “abc” 对象,然后再去堆中 create 那个
new String。 -
如果有:直接使用池中的 “abc” 作为构造参数,传递给
new String。
-
7.引用类型有哪些?有什么区别?
| 引用类型 | 比喻 | 解释 |
|---|---|---|
| 强引用 | 欠条 (法律保护) | 只要欠条在,这笔债就赖不掉(对象一直在)。除非你把欠条撕了(设为 null)。 |
| 软引用 | 朋友间的借钱 | 平时不用还。但是当你朋友破产了(内存不足),他就会来找你要钱(回收对象)。 |
弱引用(ThreadLocal 的 Key) | 写在沙滩上的字 | 海浪(GC)一来,不管有没有人看,字马上就消失了。 |
| 虚引用 | 死亡通知书 | 你见不到那个人了(get 不到对象),这张纸只是告诉你:他已经走了(对象被回收了,赶紧去处理后事)。 |
面试官: 为什么 ThreadLocal 的 Key 要设计成弱引用? | ||
| [[2.并发安全#16threadlocal作用原理具体里面存的key-value是啥会有什么问题如何解决 | 16Threadlocal作用,原理,具体里面存的key value是啥,会有什么问题,如何解决?]] |
候选人: “这是为了防止内存泄漏。
-
如果
ThreadLocalMap的 Key 是 强引用:即使外部的ThreadLocal对象被设置为 null(业务用完了),但因为 Map 里的 Key 还指着它,导致它无法被 GC 回收。这就叫内存泄漏。 -
改成 弱引用 后:外部引用一断,下次 GC 时,Map 里的 Key 就会自动被回收(变成 null)。
-
注意: 虽然 Key 解决了,但 Value 还是强引用。所以用完
ThreadLocal务必手动调用remove(),否则 Value 依然会泄漏。”
- 内存中的“两根线”
想象你在写这段代码: ThreadLocal<String> tl = new ThreadLocal<>();
在 JVM 内存里,这个 ThreadLocal 对象(我们暂且叫它“TL 对象”)其实被两根线拉扯着:
-
线 A(外部强引用): 也就是你代码里的变量
tl。它在栈上,强力拉着堆里的“TL 对象”。 -
线 B(Map 内部的 Key): 当你调用
tl.set("xxx")时,当前线程的ThreadLocalMap里会新增一个 Entry。这个 Entry 的 Key,就是这个“TL 对象”本身。
- 为什么要设计成弱引用?
假设 Key 是强引用: 即使你在代码里写了 tl = null;(断开了线 A),但当前线程如果还没结束(比如在线程池里),线 B(Map 的 Key)依然强力拉着“TL 对象”。
-
结果: GC 发现还有强引用(线 B)连着,不敢回收“TL 对象”。
-
惨状: 这个“TL 对象”明明业务上已经不用了,却一直赖在内存里不走。
改成弱引用后: 当你写了 tl = null;(断开了线 A),“TL 对象”身上就只剩下线 B 这根细细的、弱不禁风的线了。
-
结果: 下次 GC 只要一扫描到它,发现只有弱引用(线 B),就会直接把“TL 对象”回收掉。
-
变化: 此时,
ThreadLocalMap里那个 Entry 的 Key 就会自动变成null。
- 最坑的地方:Value 为什么还会泄漏?
虽然 Key 变成了 null 被回收了,但问题只解决了一半。
请注意 Entry 的结构:
static class Entry extends WeakReference<ThreadLocal<?>> {
Object value; // <--- 重点:它是强引用!
}
-
逻辑: 即使 Key 变成了
null,但Entry对象还躺在 Map 里,且Entry的value字段依然强行拉扯着你存进去的数据(比如一个几百 MB 的大对象)。 -
困局: 因为 Key 已经是
null了,你现在通过tl.get()再也找不到这个 Value 了,它成了一个**“被遗忘的孤儿”**。但只要线程不销毁,这条强引用链(Thread→ThreadLocalMap→Entry→Value)就一直存在。
8.弱引用了解吗?举例说明在哪里可以用?
场景一 为上一题 场景二:WeakHashMap
-
这是 JDK 自带的一个 Map 实现。它的键(Key)也是弱引用的。
-
作用: 适用于缓存对象的辅助信息。比如我要给一个
User对象绑定一张图片,但我不想因为这个绑定关系阻止User被回收。 -
如果是
WeakHashMap,一旦User对象在外部没了强引用,Map 里对应的这条 Key-Value 记录就会自动消失,不需要我们手动删除。
_9.内存泄漏和内存溢出的理解?
1. 内存溢出 (Memory Overflow / OOM)
-
现象: ‘求大于供’。
-
定义: 程序在申请内存时,JVM 没有足够的空间分配给它了,并且经过垃圾回收(GC)后依然不够。
-
结果: 抛出
java.lang.OutOfMemoryError(OOM)。 -
比喻: 水桶满了。你还要往里倒水,水就溢出来了。
2. 内存泄漏 (Memory Leak)
-
现象: ‘占着茅坑不拉屎’。
-
定义: 程序中某些对象已经不再使用了,但是代码中还保留着对它们的引用,导致 GC 无法回收 它们。
-
结果: 这些无用的对象越积越多,占用的内存越来越大,最终导致可用内存耗尽,从而引发内存溢出。
-
比喻: 占座。图书馆里坐满了人,其中有一半人其实是占了座去睡觉/玩手机的(不干活),但管理员(GC)看他们有人占着位子,不敢赶他们走。真正想学习的人(新对象)进来却没位子了。”
10.jvm 内存结构有哪几种内存溢出的情况?
1. 堆溢出 (Heap Overflow) —— 最常见
-
报错信息:
java.lang.OutOfMemoryError: Java heap space -
原因: 对象创建太多,且 GC 回收不过来。通常是因为内存泄漏(Memory Leak)或者堆内存设置过小(
-Xmx不够)。 -
场景:
List里一直 add 对象不清理;或者一次性查出千万级数据。
2. 栈溢出 (Stack Overflow) —— 分两种情况
-
情况 A(深度溢出):
-
报错信息:
java.lang.StackOverflowError -
原因: 线程请求的栈深度超过了虚拟机允许的深度。
-
场景: 死递归(递归没有出口)。
-
-
情况 B(内存溢出):
-
报错信息:
java.lang.OutOfMemoryError: unable to create new native thread -
原因: 虚拟机在扩展栈时无法申请到足够的内存。通常是因为线程开太多了,把操作系统的内存耗尽了。
-
3. 方法区溢出 (Method Area / Metaspace Overflow)
-
报错信息:
- JDK 1.8+:
java.lang.OutOfMemoryError: Metaspace
- JDK 1.8+:
-
原因: 加载的 类 (Class) 太多了。
-
场景: 也是最容易被忽视的。比如大量使用 CGLib 动态代理 生成代理类(Spring AOP 就在用),或者 JSP 动态生成 Class。
4. 本地直接内存溢出 (Direct Memory Overflow)
-
报错信息:
java.lang.OutOfMemoryError: Direct buffer memory -
原因: 这是 堆外内存。使用 NIO (
ByteBuffer.allocateDirect) 分配的大块内存没释放。 -
场景: Netty 等高性能网络框架使用不当。”
11.遇到过堆溢出的情况吗?如何解决?
“坦白说,因为我之前是在学校做项目和科研,确实还没有机会处理过线上真实的生产级 OOM 事故。
但是,我在做【Big Market / 你的某个项目】的时候,为了验证系统的稳定性,也为了掌握排查思路,我主动在本地模拟过类似的情况:
-
我怎么做的: 我故意把 JVM 的堆内存(
-Xmx)调得很小(比如 20MB),然后写了一个死循环往 List 里塞对象(或者模拟高并发请求)。 -
我看到了什么: 程序很快就报了
Java heap space错误,并生成了 Dump 文件。 -
我怎么分析的: 我尝试用 JVisualVM 和 MAT 打开了这个文件,确实观察到了内存占用直方图中,那个 List 占据了绝大部分空间。
-
我的收获: 虽然这是我人为模拟的,但通过这个过程,我已经熟悉了 ‘保留现场 → 导出 Dump → 工具分析 → 定位代码’ 这一整套标准流程。如果实习期间遇到类似问题,我有信心能快速上手协助排查。”
“在 Java Web 的生产环境我确实没处理过。不过我在做 Deepfake 检测算法 训练时,经常遇到内存或显存溢出(OOM)的情况,处理思路其实是相通的:
-
场景: 在加载大规模数据集或者模型参数过大时,经常会爆内存。
-
解决: 我通常会检查是不是
Batch Size设置太大了,或者是不是 DataLoader 读图片时没有及时释放内存。这和 Java 里检查‘大对象’或‘内存泄漏’的逻辑是一样的。 -
映射到 Java: 如果是在 Java 项目中,我会按照标准的 JVM 排查流程,先看日志,再拿 Dump 文件用 MAT 分析引用链,看是哪个对象占着内存不释放。”
“在通过 JVisualVM 分析了 Dump 文件后,我制定了解决步骤:
第一步:定性 —— 是‘泄漏’还是‘溢出’? 我首先检查了占用内存最大的那些对象(ConfigurationClassParser 和 AppClassLoader)。 我发现它们都是 Spring 框架启动时必须加载的元数据和类信息,这些都是有用的数据,不是垃圾,也不能被回收。 这说明代码逻辑没有 Bug(没有死循环或未关闭的流),单纯是**‘JVM 初始分配的内存太小,装不下业务必须的数据’。属于典型的内存溢出(Memory Overflow)**,而不是内存泄漏。
第二步:定量 —— 该给多少内存? 我看了一下 Dump 文件里的 Total Retained Size(总保留大小)。 虽然我当时只给了 20MB,但 Spring Boot 启动加载完所有 Bean 至少需要 40MB~60MB 左右的基础内存(根据项目体量预估)。 显然,20MB 是物理上不可能完成的任务。
第三步:实施 —— 调整 JVM 参数 于是,我修改了启动参数,将堆内存扩大。 为了防止内存抖动,我遵循了**‘最佳实践’**,将最小堆(-Xms)和最大堆(-Xmx)设置为相同的值。 我将其调整为 -Xms512m -Xmx512m(或者根据你电脑配置说 256m)。
第四步:验证 重启应用后,我再次观察了 JVisualVM 的内存曲线。 发现 Spring Boot 启动完成后,堆内存稳定在 100MB 左右,GC 频率恢复正常,应用启动成功。问题彻底解决。”
12.栈溢出的情况呢?
| 异常类型 | 关键点 | 报错关键字 | 核心原因 | 调整参数 |
|---|---|---|---|---|
| StackOverflowError | 深度 | StackOverflowError | 单个线程的方法调用太深 (死递归) | 调大 -Xss (治标不治本) |
| OutOfMemoryError | 广度 | unable to create new native thread | 线程总数太多,撑爆了物理内存 | 调小 -Xss (为了多塞几个线程) |
| 参数 | 对应概念 | 影响范围 | 经典场景 |
|---|---|---|---|
-Xms | 公司账户的余额 | 堆 (Heap) 大家公用的钱 | 决定程序启动时占用多少内存。 |
-Xss | 每个人的工位大小 | 栈 (Stack) 每个人私有的地盘 | 决定代码能递归调用多深(防爆栈),或者能开多少个线程(防 OOM)。 |
13.有具体的内存泄漏和内存溢出的例子么请举例及解决方案?
一、 内存泄漏 (Memory Leak) —— “垃圾清不掉”
这通常是由于代码逻辑问题导致的。
案例 1:ThreadLocal 使用不当 (面试必问)
这是最经典、最有深度的内存泄漏案例。
-
场景代码:
// 线程池中的线程是长期存活的 static final ThreadLocal<User> userLocal = new ThreadLocal<>(); public void doFilter() { // 1. 设置用户信息 userLocal.set(new User("Tom")); // 2. 业务逻辑... // 3. !!!忘记调用 remove() !!! } -
泄漏原理:
-
ThreadLocalMap的 Key(ThreadLocal对象)是弱引用,GC 时会被自动回收。 -
但是 Value(
User对象)是强引用。 -
如果线程不销毁(线程池核心线程),Key 回收了变成了
null,但 Value 还在。这条链条Thread -> ThreadLocalMap -> Entry(null, User)永远存在,导致User对象无法被回收。
-
-
解决方案:
- 必须在
finally块中手动调用remove()。
try { userLocal.set(new User("Tom")); // 业务逻辑 } finally { userLocal.remove(); // 斩断强引用 } - 必须在
案例 2:静态集合 (Static Collection) 只进不出
-
场景代码:
// 静态变量,生命周期和 JVM 一样长 public static List<Object> cache = new ArrayList<>(); public void processData(Object data) { cache.add(data); // 一直 add,从来不 remove } -
泄漏原理:
static变量是 GC Root。只要类不卸载,这个 List 就一直活着,List 里的所有对象也就一直活着,GC 根本动不了它们。
-
解决方案:
-
给缓存设置最大容量或过期时间(推荐用 Caffeine 或 Guava Cache)。
-
或者在业务用完后,手动调用
cache.clear()。
-
案例 3:各种连接没关闭
-
场景: 数据库连接(Connection)、网络连接(Socket)、IO 流。
-
原理: 这些底层资源如果不手动 close,系统句柄和内存都不会释放。
-
解决方案: 使用 try-with-resources(JDK 7+ 语法),让 Java 自动帮你关。
二、 内存溢出 (Memory Overflow) —— “真的装不下”
这通常是数据量太大或配置太小导致的。
案例 1:堆溢出 (Heap Space) —— 你刚刚做过的
-
错误信息:
java.lang.OutOfMemoryError: Java heap space -
场景代码:
// 比如一次性从数据库查出 100 万条数据 List<User> users = userDao.selectAll(); -
解决方案:
-
代码侧: 改为分页查询(
limit)或流式查询。 -
运维侧: 调大
-Xmx参数。
-
案例 2:栈溢出 (StackOverflow) —— 死循环
-
错误信息:
java.lang.StackOverflowError -
场景代码:
public void recursive() { recursive(); // 忘记写递归的结束条件 } -
解决方案: 检查递归逻辑,确保一定有
if (xx) return;这样的出口。
案例 3:元空间溢出 (Metaspace) —— 动态代理太多
-
错误信息:
java.lang.OutOfMemoryError: Metaspace -
场景: 使用 Spring AOP 或 CGLib 时,如果不小心在一个循环里不断生成新的动态代理类。
while(true) { Enhancer enhancer = new Enhancer(); // ... 配置 enhancer enhancer.create(); // 每次都生成一个新的 Class 加载到元空间 } -
解决方案:
-
限制动态类的生成。
-
调大
-XX:MaxMetaspaceSize。
-